 Ändra språk
Ändra språkLägga till din favoritnyhetswebbplats¶
calibre har ett kraftfullt, flexibelt och lättanvänt ramverk för att hämta nyheter från Internet och konvertera dem till en e-bok. Följande kommer att visa dig, med hjälp av exempel, hur du får nyheter från olika webbplatser.
För att få en förståelse för hur man använder ramverket, följ exemplen i den ordning som anges nedan:
Helt automatisk hämtning¶
Om din nyhetskälla är enkel nog, skulle calibre mycket väl kunna hämta den helt automatiskt, allt du behöver göra att ge URL:en. calibre samlar all information som behövs för att hämtar en nyhetskälla i ett recept. För att berätta för calibre om en nyhetskälla, måste du skapa ett recept för det. Låt oss se några exempel:
calibre-bloggen¶
calibre-bloggen är en blogg med inlägg som beskriver många användbara calibre-funktioner på ett enkelt och lättillgängligt sätt för nya calibre-användare. För att hämtar den här bloggen till en e-bok förlitar vi oss på RSS flödet av bloggen:
http://blog.calibre-ebook.com/feeds/posts/default
Jag fick RSS-URL:en genom att titta under ”Prenumerera” längst ner på bloggsidan och välja Posts → Atom. För att få calibre att hämtar flöden och konvertera dem till en e-bok, bör du högerklicka på knappen Hämta nyheter och sedan på menyalternativet Lägg till en anpassad nyhetskälla och sedan knappen Nytt recept. En dialogruta liknande den som visas nedan bör öppnas.
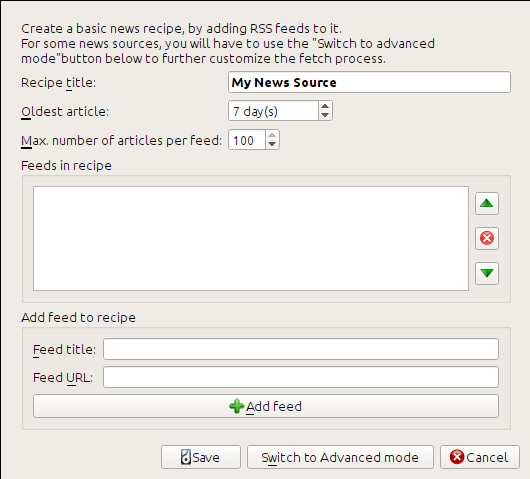
Ange först Calibre Blog i fältet Recepttitel. Detta kommer att vara titeln på e-boken som kommer att skapas från artiklarna i ovanstående flöden.
De nästa två fälten (Äldsta artikel och Högst antal artiklar) tillåter dig viss kontroll över hur många artiklar som ska hämtats från varje flöde, och de är ganska självförklarande.
För att lägga till flöden till receptet, mata in flödestitel och flödes-URL:en och klicka på knappen Lägg till flöde. När du har lagt till flödet klickar du på knappen Spara och du är klar! Stäng dialogrutan.
Så här testar du nya recept klicka på knappen Hämta nyheter och i undermenyn Anpassad nyhetskälla klicka på calibre Blog. Efter ett par minuter, kommer den nyligen hämtade e-boken av blogginlägg visas i huvudbiblioteksvyn (om du har din läsenhet ansluten kommer den att läggas till på läsenheten istället för i biblioteket). Välj det och tryck på knappen Visa för att läsa!
Anledningen till att detta fungerat så bra, med så liten ansträngning är att bloggen ger fullt innehåll RSS flöden, det vill säga, artikelns innehåll är inbäddat i själva flödet. För de flesta nyhetskällor som tillhandahåller nyheter på detta sätt, med fullt innehåll flöden, du behöver inte någon mer ansträngning för att konvertera dem till e-böcker. Nu ska vi titta på en nyhetskälla som inte ger fullständigt innehållsflöde. I sådana flöden är hela artikeln en webbplats och flödet innehåller bara en länk till webbplatsen med en kort sammanfattning av artikeln.
bbc.co.uk¶
Låt oss testa följande två flöden från BBC:
Följ proceduren som beskrivs i calibre-bloggen ovan för att skapa ett recept på BBC (med hjälp av flöde ovan). Om man tittar på den hämtade e-boken, ser vi att claibre har gjort ett förtjänstfullt arbete för att utvinna bara innehållet som du bryr dig om från varje artikel webbplats. Emellertid är extraktionsprocessen inte perfekt. Ibland lämnar oönskade innehåll som menyer och navigeringshjälpmedel, eller det tar bort innehåll som borde lämnas i fred, som artikelrubriker. För att få perfekt innehållsutvinning, måste vi anpassa hämta processen, som beskrivs i nästa avsnitt.
Anpassa hämtningsprocessen¶
När du vill finslipa hämtningsprocessen, eller hämtar innehåll från en särskilt komplex webbplats, kan du utnyttja all kraft och flexibilitet i recipe-ramverket. För att göra det, klicka helt enkelt på knappen Växla till avancerat läge i dialogrutan Lägg till anpassade nyhetskällor.
Den enklaste och ofta produktivaste anpassningen är att använda utskriftsversioner av artiklar på nätet. Utskriftsversionen har vanligtvis mycket mindre skräp och översätter mycket smidigare till en e-bok. Låt oss försöka använda utskriftsversionen av artiklarna från BBC.
Använda den tryckta versionen av bbc.co.uk¶
Det första steget är att titta på e-boken som vi hämtat tidigare från bbc.co.uk. Vid slutet av varje artikel, i e-boken finns en liten baksidetext som talar om när artikeln hämtats från. Kopiera och klistra in denna URL:en i en webbläsare. Nu på artikelwebbplatsen leta efter en länk som hänvisar till ”Utskriftbar version”. Klicka på den för att se den tryckta versionen av artikeln. Det ser mycket snyggare! Jämför nu de två URL:er. För mig var de:
För att det ska se ut som att få den tryckta versionen, måste vi prefixa varje artikel-URL med:
newsvote.bbc.co.uk/mpapps/pagetools/print/
Nu i Avancerat läge i dialogrutan Anpassade nyhetskällor ska du se något liknande (kom ihåg att välja BBC-receptet innan du växlar till avancerat läge):
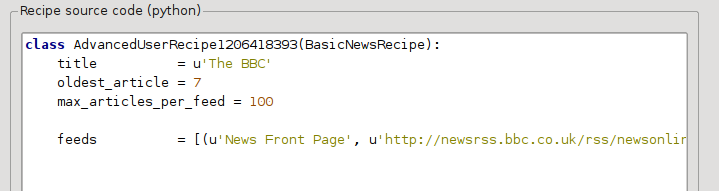
Du kan se att fälten från Grundläge har omräknats med Python-kod på ett enkelt sätt. Vi måste lägga till instruktioner för att detta recept för att använda den tryckta versionen av artiklarna. Allt som behövs är att lägga till följande två rader:
def print_version(self, url):
return url.replace('https://', 'https://newsvote.bbc.co.uk/mpapps/pagetools/print/')
Detta är Python, så indrag är viktigt. När du har lagt till raderna ska det se ut som:
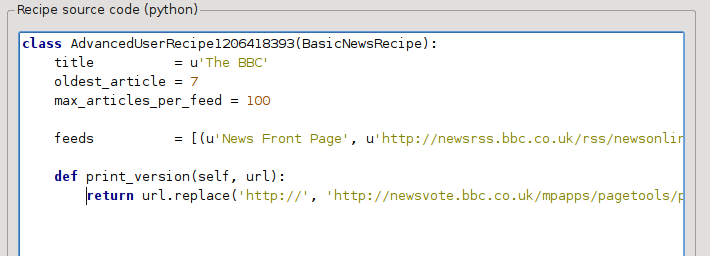
I ovanstående, def print_version(self, url) definieras en metod som anropas av calibre för varje artikel. url är webbadressen till den ursprungliga artikeln. Vad print_version gör är att den tar webbadressen och ersätter den med den nya webbadressen som hänvisar till den tryckta versionen av artikeln. Om du vill veta om Python se tutorial.
Nu klickar du på knappen Lägg till/uppdatera recept och dina ändringar sparas. Hämta e-boken igen. Du borde nu ha en mycket förbättrad e-bok. Ett av problemen med den nya versionen är att teckensnitten på utskriftsversionens webbplats är för små. Det här är automatiskt åtgärdat vid konvertering till en e-bok, men även efter justeringsprocessen blir teckensnittsstorleken på menyer och navigeringsfältet för stor i förhållande till artikeltexten. För att åtgärda det här, kommer vi att göra lite mer anpassning, i nästa avsnitt.
Ersätta artikelformat¶
I föregående avsnitt såg vi att teckensnittsstorleken efter artiklar från den tryckta versionen av BBC var för liten. I de flesta webbplatser, ingår BBC, denna teckensnittsstorlek är inställd med hjälp av CSS-formatmallar. Vi kan inaktivera hämtning av sådana formatmallar genom att lägga till raden:
no_stylesheets = True
Receptet ser nu ut så här:
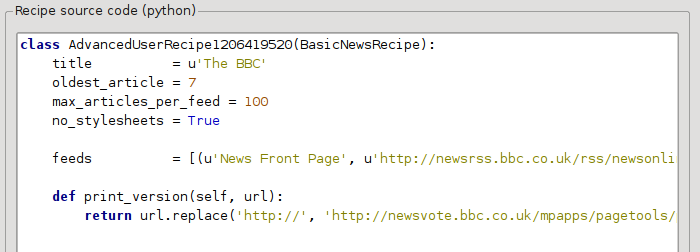
Den nya versionen ser ganska bra ut. Om du är en perfektionist, vill du nog läsa nästa avsnitt, som handlar faktiskt om att modifiera hämtat material.
Skivning och styckning i tärningar¶
calibre innehåller mycket kraftfulla och flexibla förmågor när det gäller att manipulera hämtat innehåll. För att visa upp ett par av dessa, låt oss titta på vår gamle vän receptet BBC igen. Om man tittar på källkoden (HTML) i ett par artiklar (utskriftsversion) ser vi att de har en sidfot som inte innehåller någon användbar information, som finns i
<div class="footer">
...
</div>
Detta kan tas bort genom att lägga till:
remove_tags = [dict(name='div', attrs={'class':'footer'})]
till receptet. Låt oss slutligen ersätta en del av CSS som vi inaktiverade tidigare med vår egen CSS som är lämplig för konvertering till en e-bok:
extra_css = '.headline {font-size: x-large;} \n .fact { padding-top: 10pt }'
Med dessa tillägg har vårt recept blivit ”produktionskvalitet”.
Detta recept utforskar bara toppen av isberget när det kommer till makten av calibre. För att utforska mer av förmågan hos calibre så undersöker vi en mer komplex verkliga livet exempel i nästa avsnitt.
Exempel i verkligheten¶
Ett tämligen komplicerat exempel från verkligheten som exponerar mer av API för BasicNewsRecipe är detta recept för New York Times
import string, re
from calibre import strftime
from calibre.web.feeds.recipes import BasicNewsRecipe
from calibre.ebooks.BeautifulSoup import BeautifulSoup
class NYTimes(BasicNewsRecipe):
title = 'The New York Times'
__author__ = 'Kovid Goyal'
description = 'Daily news from the New York Times'
timefmt = ' [%a, %d %b, %Y]'
needs_subscription = True
remove_tags_before = dict(id='article')
remove_tags_after = dict(id='article')
remove_tags = [dict(attrs={'class':['articleTools', 'post-tools', 'side_tool', 'nextArticleLink clearfix']}),
dict(id=['footer', 'toolsRight', 'articleInline', 'navigation', 'archive', 'side_search', 'blog_sidebar', 'side_tool', 'side_index']),
dict(name=['script', 'noscript', 'style'])]
encoding = 'cp1252'
no_stylesheets = True
extra_css = 'h1 {font: sans-serif large;}\n.byline {font:monospace;}'
def get_browser(self):
br = BasicNewsRecipe.get_browser(self)
if self.username is not None and self.password is not None:
br.open('https://www.nytimes.com/auth/login')
br.select_form(name='login')
br['USERID'] = self.username
br['PASSWORD'] = self.password
br.submit()
return br
def parse_index(self):
soup = self.index_to_soup('https://www.nytimes.com/pages/todayspaper/index.html')
def feed_title(div):
return ''.join(div.findAll(text=True, recursive=False)).strip()
articles = {}
key = None
ans = []
for div in soup.findAll(True,
attrs={'class':['section-headline', 'story', 'story headline']}):
if ''.join(div['class']) == 'section-headline':
key = string.capwords(feed_title(div))
articles[key] = []
ans.append(key)
elif ''.join(div['class']) in ['story', 'story headline']:
a = div.find('a', href=True)
if not a:
continue
url = re.sub(r'\?.*', '', a['href'])
url += '?pagewanted=all'
title = self.tag_to_string(a, use_alt=True).strip()
description = ''
pubdate = strftime('%a, %d %b')
summary = div.find(True, attrs={'class':'summary'})
if summary:
description = self.tag_to_string(summary, use_alt=False)
feed = key if key is not None else 'Uncategorized'
if feed not in articles:
articles[feed] = []
if not 'podcasts' in url:
articles[feed].append(
dict(title=title, url=url, date=pubdate,
description=description,
content=''))
ans = self.sort_index_by(ans, {'The Front Page':-1, 'Dining In, Dining Out':1, 'Obituaries':2})
ans = [(key, articles[key]) for key in ans if key in articles]
return ans
def preprocess_html(self, soup):
refresh = soup.find('meta', {'http-equiv':'refresh'})
if refresh is None:
return soup
content = refresh.get('content').partition('=')[2]
raw = self.browser.open('https://www.nytimes.com'+content).read()
return BeautifulSoup(raw.decode('cp1252', 'replace'))
Vi ser flera nya funktioner i detta recept. Först har vi:
timefmt = ' [%a, %d %b, %Y]'
Detta ställer den visade tiden på förstasidan av den skapade e-boken att vara i formatet, Dag, Dag_Nummer Månad, År. Se timefmt.
Då ser vi en grupp direktiv för att rensa hämtad HTML:
remove_tags_before = dict(name='h1')
remove_tags_after = dict(id='footer')
remove_tags = ...
Dessa tar bort allt innan den första <h1>-taggen och allt efter den första taggen vars id är footer. Se remove_tags, remove_tags_before, remove_tags_after.
Nästa intressanta funktion är:
needs_subscription = True
...
def get_browser(self):
...
needs_subscription = True berättar för calibre att detta recept behöver användarnamn och lösenord för att komma åt innehållet. Detta medför att calibre frågar efter användarnamn och lösenord när du försöker använda det här receptet. Koden i calibre.web.feeds.news.BasicNewsRecipe.get_browser() loggar faktiskt in på NYT-webbplatsen. När du loggat in kommer calibre att använda samma webbläsarinstans för att hämta allt innehåll. Se mechanize för att förstå koden i get_browser.
Nästa nya funktion är metoden calibre.web.feeds.news.BasicNewsRecipe.parse_index(). Dess uppgift är att gå till https://www.nytimes.com/pages/todayspaper/index.html och hämta listan över artiklar som visas i dagens tidning. Även om det är mer komplext än att bara använda RSS, skapar receptet en e-bok som motsvarar dagens tidning mycket nära. parse_index använder flitigt BeautifulSoup för att analysera dagstidningens webbsida. Du kan också använda andra, mer moderna parsers om du ogillar BeautifulSoup. calibre levereras med lxml och html5lib, vilka är de rekommenderade parserna. För att använda dem, ersätt anropet till index_to_soup() med följande:
raw = self.index_to_soup(url, raw=True)
# For html5lib
import html5lib
root = html5lib.parse(raw, namespaceHTMLElements=False, treebuilder='lxml')
# For the lxml html 4 parser
from lxml import html
root = html.fromstring(raw)
Den sista nya funktionen är metoden calibre.web.feeds.news.BasicNewsRecipe.preprocess_html(). Den kan användas för att utföra godtyckliga omvandlingar på varje hämtad HTML-sida. Här används den för att kringgå de annonser som de nytimes visar dig före varje artikel.
Tips för att utveckla nya recept¶
Det bästa sättet att utveckla nya recept är att använda kommandoradsgränssnittet. Skapa receptet med din favorit Python-redigerare och spara det i en fil, t.ex. myrecipe.recipe. Filändelsen .recipe krävs. Du kan hämtar innehållet med det här receptet med kommandot:
ebook-convert myrecipe.recipe .epub --test -vv --debug-pipeline debug
Kommandot ebook-convert kommer att hämta alla webbplatser och spara dem i EPUB-filen myrecipe.epub. Flaggan -vv får ebook-convert att mata ut mycket information om vad den gör. Flaggan ebook-convert-recipe-input --test begränsar hämtningen till bara ett par artiklar från högst två flöden. Dessutom placerar ebook-convert HTML-filen i mappen debug/input, där debug är mappen du angav i flaggan ebook-convert --debug-pipeline.
När hämtningen är klar kan du titta på hämtad HTML genom att öppna filen debug/input/index.html i en webbläsare. När du är nöjd med att hämtningen och förbehandling sker korrekt kan du skapa e-böcker i olika format enligt nedan:
ebook-convert myrecipe.recipe myrecipe.epub
ebook-convert myrecipe.recipe myrecipe.mobi
...
Om du är nöjd med ditt recept och du känner att det finns tillräcklig efterfrågan för att motivera dess införande i uppsättningen av inbyggda recept, lägg upp ditt recept i calibres receptforum för att dela med andra calibre-användare.
Anteckning
I macOS finns kommandoradsverktygen inuti calibre paketet, till exempel om du installerade calibre i /Applications kommandoradsverktygen finns i /Applications/calibre.app/Contents/MacOS/.
Se även
- ebook-convert
Kommandoradsgränssnittet för all e-bokkonvertering.
Ytterligare läsning¶
Om du vill veta mer om att skriva avancerade recept med några av faciliteterna som finns i BasicNewsRecipe bör du konsultera följande källor:
- API-dokumentation
Dokumentation av
BasicNewsRecipe-klassen och alla dess viktiga metoder och fält.- BasicNewsRecipe
Källkoden för
BasicNewsRecipe- Inbyggda recept
Källkoden för de inbyggda recept som kommer med calibre
- calibre-receptforumet
Här finns massor av kunniga receptförfattare för calibre.
API-dokumentation¶
- API-dokumentation för recept
BasicNewsRecipeBasicNewsRecipe.adeify_images()BasicNewsRecipe.image_url_processor()BasicNewsRecipe.print_version()BasicNewsRecipe.tag_to_string()BasicNewsRecipe.abort_article()BasicNewsRecipe.abort_recipe_processing()BasicNewsRecipe.add_toc_thumbnail()BasicNewsRecipe.canonicalize_internal_url()BasicNewsRecipe.cleanup()BasicNewsRecipe.clone_browser()BasicNewsRecipe.default_cover()BasicNewsRecipe.download()BasicNewsRecipe.extract_readable_article()BasicNewsRecipe.get_article_url()BasicNewsRecipe.get_browser()BasicNewsRecipe.get_cover_url()BasicNewsRecipe.get_extra_css()BasicNewsRecipe.get_feeds()BasicNewsRecipe.get_masthead_title()BasicNewsRecipe.get_masthead_url()BasicNewsRecipe.get_obfuscated_article()BasicNewsRecipe.get_url_specific_delay()BasicNewsRecipe.index_to_soup()BasicNewsRecipe.is_link_wanted()BasicNewsRecipe.parse_feeds()BasicNewsRecipe.parse_index()BasicNewsRecipe.populate_article_metadata()BasicNewsRecipe.postprocess_book()BasicNewsRecipe.postprocess_html()BasicNewsRecipe.preprocess_html()BasicNewsRecipe.preprocess_image()BasicNewsRecipe.preprocess_raw_html()BasicNewsRecipe.publication_date()BasicNewsRecipe.skip_ad_pages()BasicNewsRecipe.sort_index_by()BasicNewsRecipe.articles_are_obfuscatedBasicNewsRecipe.auto_cleanupBasicNewsRecipe.auto_cleanup_keepBasicNewsRecipe.browser_typeBasicNewsRecipe.center_navbarBasicNewsRecipe.compress_news_imagesBasicNewsRecipe.compress_news_images_auto_sizeBasicNewsRecipe.compress_news_images_max_sizeBasicNewsRecipe.conversion_optionsBasicNewsRecipe.cover_marginsBasicNewsRecipe.delayBasicNewsRecipe.descriptionBasicNewsRecipe.encodingBasicNewsRecipe.extra_cssBasicNewsRecipe.feedsBasicNewsRecipe.filter_regexpsBasicNewsRecipe.handle_gzipBasicNewsRecipe.ignore_duplicate_articlesBasicNewsRecipe.keep_only_tagsBasicNewsRecipe.languageBasicNewsRecipe.masthead_urlBasicNewsRecipe.match_regexpsBasicNewsRecipe.max_articles_per_feedBasicNewsRecipe.needs_subscriptionBasicNewsRecipe.no_stylesheetsBasicNewsRecipe.oldest_articleBasicNewsRecipe.preprocess_regexpsBasicNewsRecipe.publication_typeBasicNewsRecipe.recipe_disabledBasicNewsRecipe.recipe_specific_optionsBasicNewsRecipe.recursionsBasicNewsRecipe.remove_attributesBasicNewsRecipe.remove_empty_feedsBasicNewsRecipe.remove_javascriptBasicNewsRecipe.remove_tagsBasicNewsRecipe.remove_tags_afterBasicNewsRecipe.remove_tags_beforeBasicNewsRecipe.requires_versionBasicNewsRecipe.resolve_internal_linksBasicNewsRecipe.reverse_article_orderBasicNewsRecipe.scale_news_imagesBasicNewsRecipe.scale_news_images_to_deviceBasicNewsRecipe.simultaneous_downloadsBasicNewsRecipe.summary_lengthBasicNewsRecipe.template_cssBasicNewsRecipe.timefmtBasicNewsRecipe.timeoutBasicNewsRecipe.titleBasicNewsRecipe.use_embedded_content