 Dil değiştir
Dil değiştirSık kullandığınız haber sitesini ekleme¶
calibre has a powerful, flexible and easy-to-use framework for downloading news from the Internet and converting it into an e-book. The following will show you, by means of examples, how to get news from various websites.
Uygulama çatısını nasıl kullanacağınızı anlamak için, örnekleri aşağıda listelenen sırada takip edin:
Tamamı otomatik alınıyor¶
Haber kaynağınız yeterince basitse, calibre tamamen otomatik olarak getirebilir olabilir, tek yapmanız gereken URL’yi sağlamaktır. calibre haber kaynağını bir recipe ye indirmek için gerekli tüm bilgiyi toparlar. calibre’ye bir haber kaynağından bahsetmek için bu haber kaynağı için bir recipe oluşturmalısınız. Biraz örnek görelim:
Calibre blog¶
The calibre blog is a blog of posts that describe many useful calibre features in a simple and accessible way for new calibre users. In order to download this blog into an e-book, we rely on the RSS feed of the blog:
http://blog.calibre-ebook.com/feeds/posts/default
I got the RSS URL by looking under “Subscribe to” at the bottom of the blog page and choosing Posts → Atom. To make calibre download the feeds and convert them into an e-book, you should right click the Fetch news button and then the Add a custom news source menu item and then the New Recipe button. A dialog similar to that shown below should open up.
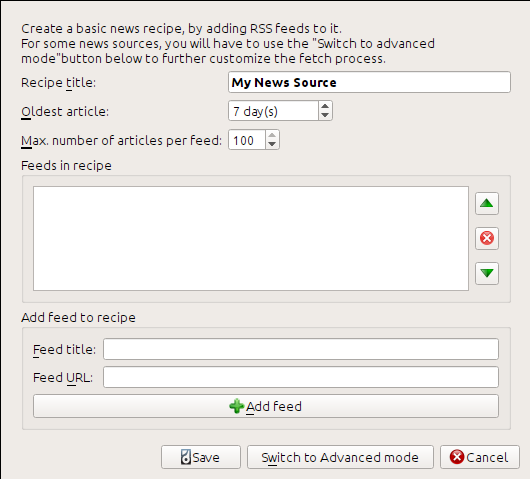
First enter Calibre Blog into the Recipe title field. This will be the title of the e-book that will be created from the articles in the above feeds.
Sonraki iki alan (En eski makale ve :guilabel:`Azami makale sayısı `) her beslemeden kaç makale indirileceği konusunu kontrol etmenize izin verir, zaten ne oldukları epey açık.
Beslemeleri reçeteye eklemek için, besleme başlığı ve besleme URL’sini girin ve Besleme ekle düğmesine tıklayın. Besleme eklendikten sonra basitçe Kaydet düğmesine tıklayın, hepsi bu kadar. İletişim penceresini kapatın.
To test your new recipe, click the Fetch news button and in the Custom news sources sub-menu click calibre Blog. After a couple of minutes, the newly downloaded e-book of blog posts will appear in the main library view (if you have your reader connected, it will be put onto the reader instead of into the library). Select it and hit the View button to read!
The reason this worked so well, with so little effort is that the blog provides full-content RSS feeds, i.e., the article content is embedded in the feed itself. For most news sources that provide news in this fashion, with full-content feeds, you don’t need any more effort to convert them to e-books. Now we will look at a news source that does not provide full content feeds. In such feeds, the full article is a webpage and the feed only contains a link to the webpage with a short summary of the article.
bbc.co.uk¶
Let’s try the following two feeds from The BBC:
Follow the procedure outlined in Calibre blog above to create a recipe for The BBC (using the feeds above). Looking at the downloaded e-book, we see that calibre has done a creditable job of extracting only the content you care about from each article’s webpage. However, the extraction process is not perfect. Sometimes it leaves in undesirable content like menus and navigation aids or it removes content that should have been left alone, like article headings. In order, to have perfect content extraction, we will need to customize the fetch process, as described in the next section.
Getirme işleminin özelleştirilmesi¶
İndirme işlemini mükemmelleştirmeye, ya da karmaşık bir siteden içerik indirmeye çalışırken reçete yazılım çatısının tüm güç ve esnekliğini kullanabilirsiniz. Bunun için Özel haber kaynağı ekle iletişim penceresinde Gelişmiş Kipe geç düğmesine tıklamanız yeterli.
The easiest and often most productive customization is to use the print version of the online articles. The print version typically has much less cruft and translates much more smoothly to an e-book. Let’s try to use the print version of the articles from The BBC.
bbc.co.uk nin yazdırma sürümünün kullanılması¶
The first step is to look at the e-book we downloaded previously from bbc.co.uk. At the end of each article, in the e-book is a little blurb telling you where the article was downloaded from. Copy and paste that URL into a browser. Now on the article webpage look for a link that points to the “Printable version”. Click it to see the print version of the article. It looks much neater! Now compare the two URLs. For me they were:
Öyle görünüyor ki yazdırma sürümünü almak için her makale URL’sine şu ön ek gelmeli:
newsvote.bbc.co.uk/mpapps/pagetools/print/
Now in the Advanced mode of the Custom news sources dialog, you should see something like (remember to select The BBC recipe before switching to advanced mode):
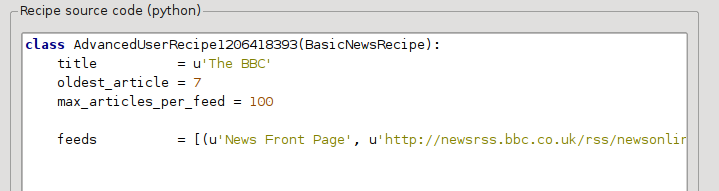
You can see that the fields from the Basic mode have been translated to Python code in a straightforward manner. We need to add instructions to this recipe to use the print version of the articles. All that’s needed is to add the following two lines:
def print_version(self, url):
return url.replace('https://', 'https://newsvote.bbc.co.uk/mpapps/pagetools/print/')
This is Python, so indentation is important. After you’ve added the lines, it should look like:
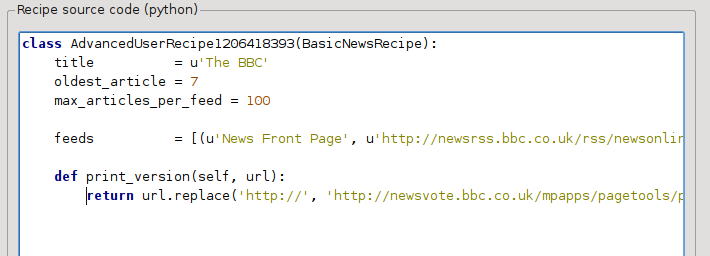
In the above, def print_version(self, url) defines a method that is called by calibre for every article. url is the URL of the original article. What print_version does is take that url and replace it with the new URL that points to the print version of the article. To learn about Python see the tutorial.
Now, click the Add/update recipe button and your changes will be saved. Re-download the e-book. You should have a much improved e-book. One of the problems with the new version is that the fonts on the print version webpage are too small. This is automatically fixed when converting to an e-book, but even after the fixing process, the font size of the menus and navigation bar become too large relative to the article text. To fix this, we will do some more customization, in the next section.
Makale biçemlerinin değiştirilmesi¶
Önce bölümde, The BBC nin yazdırılabilir sürümündeki yazı tipi boyutunun çok küçük olduğunu gördük. Bir çok web sitesinde, The BBC dahil, bu yazı tipi CSS stil sayfaları ile ayarlanır. Şu satırı ekleyerek bu gibi stil sayfalarının getirilmesini engelleyebiliriz:
no_stylesheets = True
Tarifi şimdi gibi görünüyor:
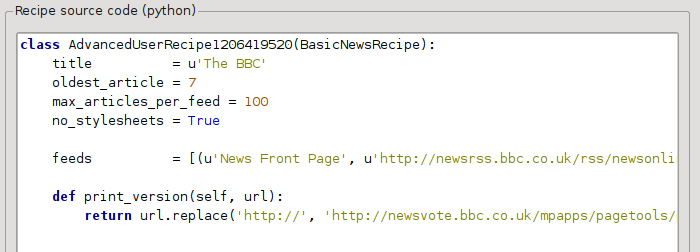
Yeni sürüm oldukça iyi görünüyor. Mükemmelliyetçiyseniz, sonraki kısmı da okumak isteyeceksiniz, bu bölüm asıl indirilen içeriğin değiştirilmesiyle ilgilenir.
Parçalama¶
calibre indirilen içerikte oynama yapmaya gelince bir çok güçlü ve esnek yetenek içerir. Bunlardan bir kaçını göstermek için, eski dostumuz The BBC reçetesine tekrar bakalım. Bir kaç makalenin (yazdırılabilir sürüm) kayna koduna (HTML) baktığımızda işe yarar bir içeriği olmayan alt bilgileri olduğunu görürüz
<div class="footer">
...
</div>
Bunu kaldırmak için şu eklenebilir:
remove_tags = [dict(name='div', attrs={'class':'footer'})]
to the recipe. Finally, let’s replace some of the CSS that we disabled earlier, with our own CSS that is suitable for conversion to an e-book:
extra_css = '.headline {font-size: x-large;} \n .fact { padding-top: 10pt }'
With these additions, our recipe has become “production quality”.
Bu reçete calibre’nin gücüyle ilgili buz dağının yalnızca görünen kısmını keşfediyor. Calibre’nin yeteneklerinin daha fazlasını keşfetmek için sonraki kısımda daha karmaşık bir gerçek dünyadan örneğe göz atacağız.
Gerçek dünya örneği¶
BasicNewsRecipe :term:`API`sini daha çok keşfeden nispeten karmaşık bir gerçek dünya örneği The New York Times :term:`reçete`sidir
import string, re
from calibre import strftime
from calibre.web.feeds.recipes import BasicNewsRecipe
from calibre.ebooks.BeautifulSoup import BeautifulSoup
class NYTimes(BasicNewsRecipe):
title = 'The New York Times'
__author__ = 'Kovid Goyal'
description = 'Daily news from the New York Times'
timefmt = ' [%a, %d %b, %Y]'
needs_subscription = True
remove_tags_before = dict(id='article')
remove_tags_after = dict(id='article')
remove_tags = [dict(attrs={'class':['articleTools', 'post-tools', 'side_tool', 'nextArticleLink clearfix']}),
dict(id=['footer', 'toolsRight', 'articleInline', 'navigation', 'archive', 'side_search', 'blog_sidebar', 'side_tool', 'side_index']),
dict(name=['script', 'noscript', 'style'])]
encoding = 'cp1252'
no_stylesheets = True
extra_css = 'h1 {font: sans-serif large;}\n.byline {font:monospace;}'
def get_browser(self):
br = BasicNewsRecipe.get_browser(self)
if self.username is not None and self.password is not None:
br.open('https://www.nytimes.com/auth/login')
br.select_form(name='login')
br['USERID'] = self.username
br['PASSWORD'] = self.password
br.submit()
return br
def parse_index(self):
soup = self.index_to_soup('https://www.nytimes.com/pages/todayspaper/index.html')
def feed_title(div):
return ''.join(div.findAll(text=True, recursive=False)).strip()
articles = {}
key = None
ans = []
for div in soup.findAll(True,
attrs={'class':['section-headline', 'story', 'story headline']}):
if ''.join(div['class']) == 'section-headline':
key = string.capwords(feed_title(div))
articles[key] = []
ans.append(key)
elif ''.join(div['class']) in ['story', 'story headline']:
a = div.find('a', href=True)
if not a:
continue
url = re.sub(r'\?.*', '', a['href'])
url += '?pagewanted=all'
title = self.tag_to_string(a, use_alt=True).strip()
description = ''
pubdate = strftime('%a, %d %b')
summary = div.find(True, attrs={'class':'summary'})
if summary:
description = self.tag_to_string(summary, use_alt=False)
feed = key if key is not None else 'Uncategorized'
if feed not in articles:
articles[feed] = []
if not 'podcasts' in url:
articles[feed].append(
dict(title=title, url=url, date=pubdate,
description=description,
content=''))
ans = self.sort_index_by(ans, {'The Front Page':-1, 'Dining In, Dining Out':1, 'Obituaries':2})
ans = [(key, articles[key]) for key in ans if key in articles]
return ans
def preprocess_html(self, soup):
refresh = soup.find('meta', {'http-equiv':'refresh'})
if refresh is None:
return soup
content = refresh.get('content').partition('=')[2]
raw = self.browser.open('https://www.nytimes.com'+content).read()
return BeautifulSoup(raw.decode('cp1252', 'replace'))
Bu yeni :term:`reçete`de bir çok yeni özellik görüyoruz. Öncelikle:
timefmt = ' [%a, %d %b, %Y]'
This sets the displayed time on the front page of the created e-book to be in the format,
Day, Day_Number Month, Year. See timefmt.
Sonra indirilen :term:`HTML`in temizlenmesi için bir grup yönerge görüyoruz:
remove_tags_before = dict(name='h1')
remove_tags_after = dict(id='footer')
remove_tags = ...
Bunlar ilk <h1> etiketinden önceki herşeyi ve footer id’li ilk etiketten sonraki herşeyi kaldırır. Ayrıca bakınız remove_tags, remove_tags_before, remove_tags_after.
Sonraki dikkat çekici özellik:
needs_subscription = True
...
def get_browser(self):
...
needs_subscription = True tells calibre that this recipe needs a username and password in order to access the content. This causes, calibre to ask for a username and password whenever you try to use this recipe. The code in calibre.web.feeds.news.BasicNewsRecipe.get_browser() actually does the login into the NYT website. Once logged in, calibre will use the same, logged in, browser instance to fetch all content. See mechanize to understand the code in get_browser.
The next new feature is the
calibre.web.feeds.news.BasicNewsRecipe.parse_index() method. Its job is
to go to https://www.nytimes.com/pages/todayspaper/index.html and fetch the list
of articles that appear in today’s paper. While more complex than simply using
RSS, the recipe creates an e-book that corresponds very closely to the
day’s paper. parse_index makes heavy use of BeautifulSoup to parse
the daily paper webpage. You can also use other, more modern parsers if you
dislike BeautifulSoup. calibre comes with lxml and
html5lib, which are the
recommended parsers. To use them, replace the call to index_to_soup() with
the following:
raw = self.index_to_soup(url, raw=True)
# For html5lib
import html5lib
root = html5lib.parse(raw, namespaceHTMLElements=False, treebuilder='lxml')
# For the lxml html 4 parser
from lxml import html
root = html.fromstring(raw)
Son yeni özellik calibre.web.feeds.news.BasicNewsRecipe.preprocess_html() metodudur. İndirilen her HTML sayfasında keyfi dönüştürmeler yapmak için kullanılabilir. Burada nytimes’ın her makaleden önce gösterdiği reklamları geçmek için kullanılıyor.
Yeni reçeteler geliştirmek için ipuçları¶
The best way to develop new recipes is to use the command line interface. Create the recipe using your favorite Python editor and save it to a file say myrecipe.recipe. The .recipe extension is required. You can download content using this recipe with the command:
ebook-convert myrecipe.recipe .epub --test -vv --debug-pipeline debug
The command ebook-convert will download all the webpages and save
them to the EPUB file myrecipe.epub. The -vv option makes
ebook-convert spit out a lot of information about what it is doing. The
ebook-convert-recipe-input --test option makes it download only a couple of articles from at most two
feeds. In addition, ebook-convert will put the downloaded HTML into the
debug/input folder, where debug is the folder you specified in
the ebook-convert --debug-pipeline option.
Once the download is complete, you can look at the downloaded HTML by opening the file debug/input/index.html in a browser. Once you’re satisfied that the download and preprocessing is happening correctly, you can generate e-books in different formats as shown below:
ebook-convert myrecipe.recipe myrecipe.epub
ebook-convert myrecipe.recipe myrecipe.mobi
...
If you’re satisfied with your recipe, and you feel there is enough demand to justify its inclusion into the set of built-in recipes, post your recipe in the calibre recipes forum to share it with other calibre users.
Not
MacOS’ta komut satırı araçları calibre paketinin içindedir; örneğin, calibre’yi /Applications dizinine yüklediyseniz komut satırı araçları /Applications/calibre.app/Contents/MacOS/ konumundadır .
Ayrıca bakınız
- ebook-convert
The command line interface for all e-book conversion.
İleri okuma¶
BasicNewsRecipe ile kullanılabilir olan olanakları kullanarak gelişmiş reçeteler yazmakla ilgili daha fazla şey öğrenmek istiyorsanız aşağıdaki kaynaklara başvurabilirsiniz:
- API documentation
BasicNewsRecipesınıfı ve tüm önemli metod ve alanlarının belgeleri.- BasicNewsRecipe
BasicNewsRecipekaynak kodu- Yerleşik reçeteler
Calibre ile gelen yerleşik reçetelerin kaynak kodları
- The calibre recipes forum
Bir çok bilgili calibre reçete geliştiricisi orada takılır.
API belgelendirmesi¶
- API documentation for recipes
BasicNewsRecipeBasicNewsRecipe.adeify_images()BasicNewsRecipe.image_url_processor()BasicNewsRecipe.print_version()BasicNewsRecipe.tag_to_string()BasicNewsRecipe.abort_article()BasicNewsRecipe.abort_recipe_processing()BasicNewsRecipe.add_toc_thumbnail()BasicNewsRecipe.canonicalize_internal_url()BasicNewsRecipe.cleanup()BasicNewsRecipe.clone_browser()BasicNewsRecipe.default_cover()BasicNewsRecipe.download()BasicNewsRecipe.extract_readable_article()BasicNewsRecipe.get_article_url()BasicNewsRecipe.get_browser()BasicNewsRecipe.get_cover_url()BasicNewsRecipe.get_extra_css()BasicNewsRecipe.get_feeds()BasicNewsRecipe.get_masthead_title()BasicNewsRecipe.get_masthead_url()BasicNewsRecipe.get_obfuscated_article()BasicNewsRecipe.get_url_specific_delay()BasicNewsRecipe.index_to_soup()BasicNewsRecipe.is_link_wanted()BasicNewsRecipe.parse_feeds()BasicNewsRecipe.parse_index()BasicNewsRecipe.populate_article_metadata()BasicNewsRecipe.postprocess_book()BasicNewsRecipe.postprocess_html()BasicNewsRecipe.preprocess_html()BasicNewsRecipe.preprocess_image()BasicNewsRecipe.preprocess_raw_html()BasicNewsRecipe.publication_date()BasicNewsRecipe.skip_ad_pages()BasicNewsRecipe.sort_index_by()BasicNewsRecipe.articles_are_obfuscatedBasicNewsRecipe.auto_cleanupBasicNewsRecipe.auto_cleanup_keepBasicNewsRecipe.browser_typeBasicNewsRecipe.center_navbarBasicNewsRecipe.compress_news_imagesBasicNewsRecipe.compress_news_images_auto_sizeBasicNewsRecipe.compress_news_images_max_sizeBasicNewsRecipe.conversion_optionsBasicNewsRecipe.cover_marginsBasicNewsRecipe.delayBasicNewsRecipe.descriptionBasicNewsRecipe.encodingBasicNewsRecipe.extra_cssBasicNewsRecipe.feedsBasicNewsRecipe.filter_regexpsBasicNewsRecipe.handle_gzipBasicNewsRecipe.ignore_duplicate_articlesBasicNewsRecipe.keep_only_tagsBasicNewsRecipe.languageBasicNewsRecipe.masthead_urlBasicNewsRecipe.match_regexpsBasicNewsRecipe.max_articles_per_feedBasicNewsRecipe.needs_subscriptionBasicNewsRecipe.no_stylesheetsBasicNewsRecipe.oldest_articleBasicNewsRecipe.preprocess_regexpsBasicNewsRecipe.publication_typeBasicNewsRecipe.recipe_disabledBasicNewsRecipe.recipe_specific_optionsBasicNewsRecipe.recursionsBasicNewsRecipe.remove_attributesBasicNewsRecipe.remove_empty_feedsBasicNewsRecipe.remove_javascriptBasicNewsRecipe.remove_tagsBasicNewsRecipe.remove_tags_afterBasicNewsRecipe.remove_tags_beforeBasicNewsRecipe.requires_versionBasicNewsRecipe.resolve_internal_linksBasicNewsRecipe.reverse_article_orderBasicNewsRecipe.scale_news_imagesBasicNewsRecipe.scale_news_images_to_deviceBasicNewsRecipe.simultaneous_downloadsBasicNewsRecipe.summary_lengthBasicNewsRecipe.template_cssBasicNewsRecipe.timefmtBasicNewsRecipe.timeoutBasicNewsRecipe.titleBasicNewsRecipe.use_embedded_content