 Změnit jazyk
Změnit jazykPřidávání oblíbených webových stránek se zprávami¶
Calibre má výkonné, pružné a snadno použitelné rozhraní pro stahování zpráv z internetu a jejich převodu do e-knihy. Následující vám za pomoci příkladů ukáže, jak získat zprávy z různých webových stránek.
K pochopení, jak používat rozhraní, následujte příklady ve vypsaném pořadí níže:
Úplně automatické načítání¶
Pokud je váš zdroj zpráv dostatečně jednoduchý, Calibre může být schopné získat ho úplně automaticky, potřebujete jen zadat URL. Calibre shromáždí všechny informace potřebné ke stažení zdroje zpráv do předpisu. Abyste řekli Calibre o zdroji zpráv, musíte pro to vytvořit předpis. Pojďme se podívat na nějaké příklady:
Blog Calibre¶
Blog Calibre je blog příspěvků, které popisují mnoho užitečných funkcí Calibre jednoduchým a přístupným způsobem pro nové uživatele Calibre. Pro stažení tohoto blogu do e-knihy spoléháme na informační kanál RSS blogu:
http://blog.calibre-ebook.com/feeds/posts/default
URL RSS jsem získal podíváním se pod „Subscribe to“ dole na stránce blogu a výběrem Posts → Atom. Aby Calibre stáhlo informační kanály a převedlo je na e-knihu, měli byste kliknout pravým tlačítkem myši na tlačítko Načíst zprávy a pak na položku nabídky Přidat vlastní zdroj zpráv a pak na tlačítko :guilabel:`Nový předpis. Mělo by se otevřít dialogové okno podobné tomu níže zobrazenému.
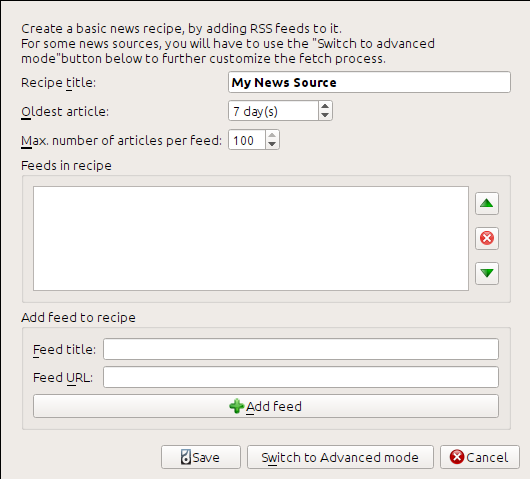
Nejdříve zadejte Blog Calibre do pole Název předpisu. To bude název e-knihy, která bude vytvořena z článků ve výše uvedených informačních kanálech.
Další dvě pole (Nejstarší článek a Max. počet článků) vám umožní kontrolu nad tím, kolik článků by mělo být staženo z každého informačního kanálu, a jsou docela sebevysvětlující.
Pro přidání informačních kanálů do předpisu zadejte název a URL informačního kanálu a klikněte na tlačítko Přidat informační kanál. Jakmile jste přidali informační kanál, jednoduše klikněte na tlačítko Uložit a máte hotovo! Zavřete dialogové okno.
Pro otestování nového předpisu klikněte na tlačítko Načíst zprávy a v podnabídce Vlastní zdroje zpráv klikněte na Blog Calibre. Po několika minutách se nově stažená e-kniha příspěvků blogu zobrazí v hlavním zobrazení knihovny (pokud máte připojenou čtečku, bude umístěna do čtečky namísto do knihovny). Vyberte ji a stiskněte tlačítko Zobrazit pro čtení!
Důvod, proč toto fungovalo tak dobře s tak málo úsilím, je ten, že blog poskytuje informační kanály RSS s úplným obsahem, t.j. obsah článku je vložen do samotného informačního kanálu. Pro většinu zdrojů zpráv, které poskytují zprávy tímto způsobem s informačními kanály s úplným obsahem, nepotřebujete žádné další úsilí, abyste je převedli na e-knihy. Nyní se podíváme na zdroje zpráv, které neposkytují informační kanály s úplným obsahem. V takových informačních kanálech je celý článek webová stránka a informační kanál obsahuje pouze odkaz na webovou stránku s krátkým souhrnem článku.
bbc.co.uk¶
Zkusme následující dva informační kanály z BBC:
Titulní sránka zpráv: https://newsrss.bbc.co.uk/rss/newsonline_world_edition/front_page/rss.xml
Věda a příroda: https://newsrss.bbc.co.uk/rss/newsonline_world_edition/science/nature/rss.xml
Postupujte podle pokynů navržených ve výše uvedeném Blog Calibre pro vytvoření předpisu pro BBC (pomocí výše uvedených informačních kanálů). Při pohledu na staženou e-knihu vidíme, že Calibre udělalo slušnou práci vyextrahováním pouze obsahu, na kterém vám záleží, z každé webové stránky článku. Proces extrakce však není dokonalý. Někdy ponechá nežádoucí obsah, jako jsou nabídky a navigační pomůcky, nebo odebere obsah, který by měl být ponechán, jako jsou záhlaví článku. Abychom dosáhli dokonalé extrakce obsahu, budeme muset přizpůsobit proces načtení, jak je popsáno v následujícím oddíle.
Přizpůsobení procesu načítání¶
Pokud chcete zdokonalit proces stahování, nebo stáhnout obsah z obzvláště složité webové stránky, můžete využít celou sílu a pružnost rozhraní předpisů. Za tímto účelem v dialogovém okně Přidat vlastní zdroje zpráv jednoduše klikněte na tlačítko Přepnout do rozšířeného režimu.
Nejjednodušší a často nejproduktivnější přizpůsobení je použít tiskovou verzi online článků. Tisková verze má obvykle mnohem méně nadbytečných dat a překládá se mnohem plynuleji do e-knihy. Zkusme použít tiskovou verzi článků z BBC.
Použití tiskové verze bbc.co.uk¶
Prvním krokem je podívat se na e-knihu, kterou jsme dříve stáhli z bbc.co.uk. Na konci každého článku v e-knize je malá záložka oznamující, odkud byl článek stažen z. Zkopírujte a vložte tuto URL do prohlížeče. Nyní na webové stránce článku najděte odkaz, který odkazuje na „Tisknutelnou verzi“. Klikněte na něj pro zobrazení tiskové verze článku. Vypadá to mnohem čistěji! Nyní porovnejte obě URL. Pro mě byly:
Takže to vypadá, že pro získání tiskové verze musíme přidat ke každé URL článku předponu:
newsvote.bbc.co.uk/mpapps/pagetools/print/
Nyní byste měli v Pokročilém režimu dialogového okna Vlastní zdroje zpráv vidět něco podobného (nezapomeňte vybrat předpis BBC před přepnutím do pokročilého režimu):
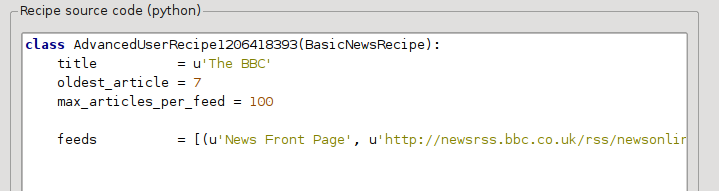
Můžete vidět, že pole ze Základního režimu byla přeložena do kódu Pythonu přímočarým způsobem. Potřebujeme přidat pokyny k tomuto předpisu, aby použil tiskovou verzi článků. Vše, co je potřeba, je přidat následující dva řádky:
def print_version(self, url):
return url.replace('https://', 'https://newsvote.bbc.co.uk/mpapps/pagetools/print/')
Toto je Python, takže odsazení je důležité. Poté, co jste přidali řádky, mělo by to vypadat takto:
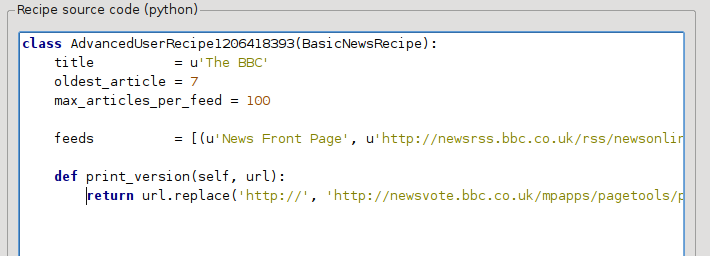
Ve výše uvedeném def print_version(self, url) definuje metodu, která je volána Calibre pro každý článek. url je URL původního článku. print_version dělá to, že vezme tuto URL a nahradí ji novou URL, která odkazuje na tiskovou verzi článku. Abyste se naučili více o Pythonu, podívejte se na kurz.
Nyní klikněte na tlačítko Přidat nebo aktualizovat předpis a vaše změny budou uloženy. Znovu stáhněte e-knihu. Měli byste mít mnohem lepší e-knihu. Jeden z problémů s novou verzí je, že písma na tiskové verzi webové stránky jsou příliš malá. To je automaticky opraveno při převodu na e-knihu, ale i po procesu opravy bude velikost písma nabídek a navigačního panelu příliš velká vzhledem k textu článku. Abychom to opravili, provedeme nějaká další přizpůsobení v dalším oddíle.
Nahrazování stylů článku¶
V předchozím oddíle jsme viděli, že velikost písma pro články z tiskové verze BBC byla příliš malá. Ve většině webových stránek, včetně BBC, je tato velikost písma nastavena pomocí šablon stylů CSS. Můžeme zakázat načítání těchto šablon stylů přidáním řádku:
no_stylesheets = True
Předpis nyní vypadá takto:
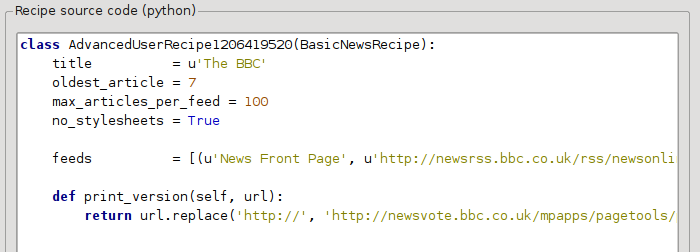
Nová verze vypadá docela dobře. Pokud jste perfekcionista, budete si chtít přečíst další oddíl, který se zabývá skutečnou úpravou staženého obsahu.
Krájení a sekání¶
Calibre obsahuje velice výkonné a pružné možnosti, pokud jde o zacházení se staženým obsahem. Abychom vám pár z nich ukázali, pojďme se znovu podívat na našeho starého přítele, na předpis BBC. Při pohledu na zdrojový kód (HTML) pár článků (tisková verze) vidíme, že mají patičku, která neobsahuje žádné užitečné informace, obsažené v
<div class="footer">
...
</div>
Toto může být odebráno přidáním:
remove_tags = [dict(name='div', attrs={'class':'footer'})]
do receptu. Nakonec nahraďme část CSS, které jsme dříve zakázali, vlastním CSS vhodným pro převod do e-knihy:
extra_css = '.headline {font-size: x-large;} \n .fact { padding-top: 10pt }'
S těmito dodatky se náš předpis stal „kvalitou výroby“.
Tento předpis prozkoumá pouze špičku ledovce, pokud jde o sílu Calibre. Abychom prozkoumali více možností Calibre, prohlédneme si v dalším oddíle složitější příklad ze skutečného života.
Příklad ze skutečného života¶
Přiměřeně složitý příklad ze skutečného života, který odhaluje více z API BasicNewsRecipe, je předpis pro The New York Times
import string, re
from calibre import strftime
from calibre.web.feeds.recipes import BasicNewsRecipe
from calibre.ebooks.BeautifulSoup import BeautifulSoup
class NYTimes(BasicNewsRecipe):
title = 'The New York Times'
__author__ = 'Kovid Goyal'
description = 'Daily news from the New York Times'
timefmt = ' [%a, %d %b, %Y]'
needs_subscription = True
remove_tags_before = dict(id='article')
remove_tags_after = dict(id='article')
remove_tags = [dict(attrs={'class':['articleTools', 'post-tools', 'side_tool', 'nextArticleLink clearfix']}),
dict(id=['footer', 'toolsRight', 'articleInline', 'navigation', 'archive', 'side_search', 'blog_sidebar', 'side_tool', 'side_index']),
dict(name=['script', 'noscript', 'style'])]
encoding = 'cp1252'
no_stylesheets = True
extra_css = 'h1 {font: sans-serif large;}\n.byline {font:monospace;}'
def get_browser(self):
br = BasicNewsRecipe.get_browser(self)
if self.username is not None and self.password is not None:
br.open('https://www.nytimes.com/auth/login')
br.select_form(name='login')
br['USERID'] = self.username
br['PASSWORD'] = self.password
br.submit()
return br
def parse_index(self):
soup = self.index_to_soup('https://www.nytimes.com/pages/todayspaper/index.html')
def feed_title(div):
return ''.join(div.findAll(text=True, recursive=False)).strip()
articles = {}
key = None
ans = []
for div in soup.findAll(True,
attrs={'class':['section-headline', 'story', 'story headline']}):
if ''.join(div['class']) == 'section-headline':
key = string.capwords(feed_title(div))
articles[key] = []
ans.append(key)
elif ''.join(div['class']) in ['story', 'story headline']:
a = div.find('a', href=True)
if not a:
continue
url = re.sub(r'\?.*', '', a['href'])
url += '?pagewanted=all'
title = self.tag_to_string(a, use_alt=True).strip()
description = ''
pubdate = strftime('%a, %d %b')
summary = div.find(True, attrs={'class':'summary'})
if summary:
description = self.tag_to_string(summary, use_alt=False)
feed = key if key is not None else 'Uncategorized'
if feed not in articles:
articles[feed] = []
if not 'podcasts' in url:
articles[feed].append(
dict(title=title, url=url, date=pubdate,
description=description,
content=''))
ans = self.sort_index_by(ans, {'The Front Page':-1, 'Dining In, Dining Out':1, 'Obituaries':2})
ans = [(key, articles[key]) for key in ans if key in articles]
return ans
def preprocess_html(self, soup):
refresh = soup.find('meta', {'http-equiv':'refresh'})
if refresh is None:
return soup
content = refresh.get('content').partition('=')[2]
raw = self.browser.open('https://www.nytimes.com'+content).read()
return BeautifulSoup(raw.decode('cp1252', 'replace'))
V tomto předpisu vidíme několik nových funkcí. Nejdříve máme:
timefmt = ' [%a, %d %b, %Y]'
To nastaví zobrazený čas na úvodní stránce vytvořené e-knihy, aby byl ve formátu Day, Day_Number Month, Year. Podívejte se na timefmt.
Pak vidíme skupinu směrnic pro vyčištění staženého HTML:
remove_tags_before = dict(name='h1')
remove_tags_after = dict(id='footer')
remove_tags = ...
Tyto odeberou vše před první značkou <h1> a vše za první značkou, jejíž identifikátor je footer. Podívejte se na remove_tags, remove_tags_before, remove_tags_after.
Další zajímavá funkce je:
needs_subscription = True
...
def get_browser(self):
...
needs_subscription = True říká Calibre, že tento předpis potřebuje uživatelské jméno a heslo pro přístup k obsahu. To způsobí, že Calibre požádá o uživatelské jméno a heslo, kdykoliv se pokusíte použít tento předpis. Kód v calibre.web.feeds.news.BasicNewsRecipe.get_browser() skutečně provede přihlášení na webovou stránku NYT. Jakmile se přihlásíte, Calibre použije stejnou, přihlášenou instance prohlížeče k načtení celého obsahu. Podívejte se na automatizace k porozumění kódu v get_browser.
Další novou funkcí je metoda calibre.web.feeds.news.BasicNewsRecipe.parse_index(). Jejím úkolem je přejít na https://www.nytimes.com/pages/todayspaper/index.html a načíst seznam článků, které se objevují v dnešních novinách. I když je to složitější než prosté použití RSS, recept vytvoří e-knihu, která velmi přesně odpovídá dennímu vydání novin. parse_index intenzivně používá BeautifulSoup k parsování webové stránky denního vydání. Pokud vám BeautifulSoup nevyhovuje, můžete použít i jiné, modernější parsery. Součástí calibre jsou lxml a html5lib, což jsou doporučené parsery. Chcete-li je použít, nahraďte volání index_to_soup() následujícím:
raw = self.index_to_soup(url, raw=True)
# For html5lib
import html5lib
root = html5lib.parse(raw, namespaceHTMLElements=False, treebuilder='lxml')
# For the lxml html 4 parser
from lxml import html
root = html.fromstring(raw)
Poslední novou funkcí je metoda calibre.web.feeds.news.BasicNewsRecipe.preprocess_html(). Může být použita k provedení libovolných transformací na každé stažené stránce HTML. Zde je použita k obejití reklam, které NYT zobrazuje před každým článkem.
Tipy pro vývoj nových předpisů¶
Nejlepším způsobem vývoje nových předpisů je použít rozhraní příkazového řádku. Vytvořte předpis pomocí svého oblíbeného editoru Pythonu a uložte ho do souboru myrecipe.recipe. Přípona .recipe je vyžadována. Pomocí tohoto předpisu můžete stáhnout obsah příkazem:
ebook-convert myrecipe.recipe .epub --test -vv --debug-pipeline debug
Příkaz ebook-convert stáhne celé webové stránky a uloží je do souboru EPUB myrecipe.epub. Volba -vv způsobí, že ebook-convert vyplivne spoustu informací o tom, co dělá. Volba ebook-convert-recipe-input --test umožní stáhnout pouze pár článků z nejvýše dvou informačních kanálů. Kromě toho ebook-convert umístí stažené HTML do složky debug/input, kde debug je složka, kterou jste zadali ve volbě ebook-convert --debug-pipeline.
Jakmile je stahování dokončeno, můžete se podívat na stažené HTML otevřením souboru debug/input/index.html v prohlížeči. Jakmile jste spokojeni se správností stahování a předzpracování, můžete generovat e-knihy v různých formátech, jak je zobrazeno níže:
ebook-convert myrecipe.recipe myrecipe.epub
ebook-convert myrecipe.recipe myrecipe.mobi
...
Pokud jste se svým předpisem spokojeni a máte pocit, že je o něj dostatečný zájem, aby mohl být zařazen mezi vestavěné předpisy, zveřejněte svůj předpis na fóru předpisů calibre a sdílejte ho s ostatními uživateli calibre.
Poznámka
Na macOS jsou nástroje příkazového řádku uvnitř sady Calibre, například pokud jste nainstalovali Calibre do /Applications, nástroje příkazového řádku jsou v /Applications/calibre.app/Contents/MacOS/.
Viz také
- ebook-convert
Rozhraní příkazového řádku pro všechny převody e-knih.
Další čtení¶
Abyste se dozvěděli více o psaní pokročilých předpisů pomocí některého z vybavení dostupného v BasicNewsRecipe, měli byste si pročíst následující zdroje:
- Dokumentace API
Dokumentace třídy
BasicNewsRecipea všechny její důležité metody a pole.- BasicNewsRecipe
Zdrojový kód
BasicNewsRecipe- Vestavěné předpisy
Zdrojový kód vestavěných předpisů dodávaných s calibre
- Fórum předpisů calibre
Na tomto fóru se pohybuje mnoho zkušených autorů předpisů pro calibre.
Dokumentace API¶
- Dokumentace API pro předpisy
BasicNewsRecipeBasicNewsRecipe.adeify_images()BasicNewsRecipe.image_url_processor()BasicNewsRecipe.print_version()BasicNewsRecipe.tag_to_string()BasicNewsRecipe.abort_article()BasicNewsRecipe.abort_recipe_processing()BasicNewsRecipe.add_toc_thumbnail()BasicNewsRecipe.canonicalize_internal_url()BasicNewsRecipe.cleanup()BasicNewsRecipe.clone_browser()BasicNewsRecipe.default_cover()BasicNewsRecipe.download()BasicNewsRecipe.extract_readable_article()BasicNewsRecipe.get_article_url()BasicNewsRecipe.get_browser()BasicNewsRecipe.get_cover_url()BasicNewsRecipe.get_extra_css()BasicNewsRecipe.get_feeds()BasicNewsRecipe.get_masthead_title()BasicNewsRecipe.get_masthead_url()BasicNewsRecipe.get_obfuscated_article()BasicNewsRecipe.get_url_specific_delay()BasicNewsRecipe.index_to_soup()BasicNewsRecipe.is_link_wanted()BasicNewsRecipe.parse_feeds()BasicNewsRecipe.parse_index()BasicNewsRecipe.populate_article_metadata()BasicNewsRecipe.postprocess_book()BasicNewsRecipe.postprocess_html()BasicNewsRecipe.preprocess_html()BasicNewsRecipe.preprocess_image()BasicNewsRecipe.preprocess_raw_html()BasicNewsRecipe.publication_date()BasicNewsRecipe.skip_ad_pages()BasicNewsRecipe.sort_index_by()BasicNewsRecipe.articles_are_obfuscatedBasicNewsRecipe.auto_cleanupBasicNewsRecipe.auto_cleanup_keepBasicNewsRecipe.browser_typeBasicNewsRecipe.center_navbarBasicNewsRecipe.compress_news_imagesBasicNewsRecipe.compress_news_images_auto_sizeBasicNewsRecipe.compress_news_images_max_sizeBasicNewsRecipe.conversion_optionsBasicNewsRecipe.cover_marginsBasicNewsRecipe.delayBasicNewsRecipe.descriptionBasicNewsRecipe.encodingBasicNewsRecipe.extra_cssBasicNewsRecipe.feedsBasicNewsRecipe.filter_regexpsBasicNewsRecipe.handle_gzipBasicNewsRecipe.ignore_duplicate_articlesBasicNewsRecipe.keep_only_tagsBasicNewsRecipe.languageBasicNewsRecipe.masthead_urlBasicNewsRecipe.match_regexpsBasicNewsRecipe.max_articles_per_feedBasicNewsRecipe.needs_subscriptionBasicNewsRecipe.no_stylesheetsBasicNewsRecipe.oldest_articleBasicNewsRecipe.preprocess_regexpsBasicNewsRecipe.publication_typeBasicNewsRecipe.recipe_disabledBasicNewsRecipe.recipe_specific_optionsBasicNewsRecipe.recursionsBasicNewsRecipe.remove_attributesBasicNewsRecipe.remove_empty_feedsBasicNewsRecipe.remove_javascriptBasicNewsRecipe.remove_tagsBasicNewsRecipe.remove_tags_afterBasicNewsRecipe.remove_tags_beforeBasicNewsRecipe.requires_versionBasicNewsRecipe.resolve_internal_linksBasicNewsRecipe.reverse_article_orderBasicNewsRecipe.scale_news_imagesBasicNewsRecipe.scale_news_images_to_deviceBasicNewsRecipe.simultaneous_downloadsBasicNewsRecipe.summary_lengthBasicNewsRecipe.template_cssBasicNewsRecipe.timefmtBasicNewsRecipe.timeoutBasicNewsRecipe.titleBasicNewsRecipe.use_embedded_content