 Zmień język
Zmień językDodawanie ulubionej strony z wiadomościami¶
calibre zawiera potężne, elastyczne i łatwe w użyciu narzędzie, służące do pobierania wiadomości z internetu i przekształcaniu ich w ebook. Poniżej pokażemy na przykładach, jak pobrać wiadomości z różnych witryn.
Do zrozumienia, w jaki sposób korzystać z tego narzędzia posłużą kolejno następujące przykłady:
Całkowicie automatyczne pobieranie¶
Jeśli pobierane wiadomości mają dostatecznie prostą strukturę, calibre może sobie z nimi poradzić całkowicie automatycznie, a wszystko, co musisz zrobić to podać adres witryny. calibre, zgromadziwszy wszystkie informacje, potrzebne do pobrania wiadomości, umieści je w źródle. Aby poinformować calibre o wiadomościach do pobrania, musisz stworzyć dla nich źródło. Oto kilka przykładów:
Blog calibre¶
Blog calibre zawiera wiele przydatnych informacji o funkcjach programu, podanych w przejrzysty i przystępny sposób. Aby pobrać wiadomości z tego bloga można użyć kanału RSS:
http://blog.calibre-ebook.com/feeds/posts/default
Adres kanału RSS można znaleźć na dole strony poniżej „Subscribe to”, należy wybrać Posts → Atom. Aby calibre pobrał wiadomości i przekształcił je w ebook, musisz kliknąć prawym klawiszem myszy przycisk Pobierz wiadomości i wybrać Dodaj własne źródło wiadomości, a następnie przycisk Nowe źródło. Pojawi się okno podobne do pokazanego poniżej.
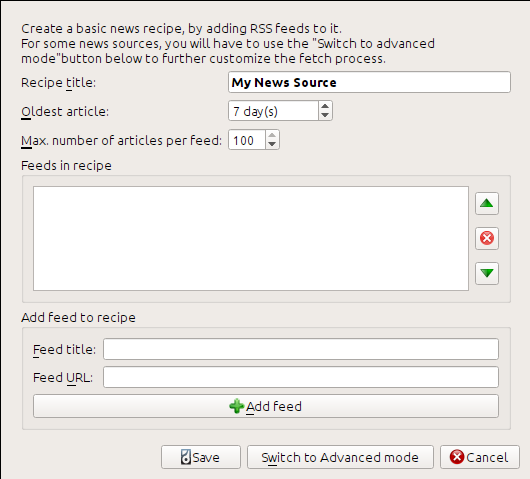
Najpierw wprowadź „Calibre Blog” w polu: guilabel: „Tytuł przepisu”. Będzie to tytuł e-booka, który zostanie utworzony z artykułów w powyższych kanałach.
Następne dwa pola (Najstarszy artykuł może być sprzed i Maksymalna liczba artykułów na strumień) dają pewną kontrolę na tym jakie artykuły zostaną pobrane i raczej nie wymagają objaśnienia.
Aby dodać strumienie (odpowiadające kanałom RSS), podaj nazwę strumienia, kanał RSS, z którego będą pobierane artykuły i kliknij przycisk Dodaj strumień. Po dodaniu strumienia po prostu kliknij przycisk Zapisz i gotowe! Można zamknąć okno.
Aby przetestować nowe źródło, kliknij przycisk Pobierz wiadomości, a następnie w podmenu Własne kliknij Blog calibre. Po kilku minutach nowy ebook, powstały z artykułów z bloga, pojawi się na liście książek biblioteki (jeśli jest podłączony czytnik to książka pojawi się na czytniku, a nie w bibliotece). Zaznacz go, kliknij przycisk Wyświetl i już możesz czytać!
Działa to tak dobrze przy tak małym nakładzie pracy, gdyż jest to kanał full-content, co oznacza, że cała treść artykułu jest w nim osadzona. W przypadku większości kanałów tego typu nie potrzeba nic więcej by przekształcić je w książki. Teraz przyjrzyjmy się źródłu wiadomości, które nie zawiera pełnego tekstu artykułów. W takim przypadku artykuł jest stroną w internecie, a źródło dostarcza jedynie odsyłacza do niego z krótkim podsumowaniem.
bbc.co.uk¶
Wypróbujmy następujące dwa źródła z The BBC:
Strona główna wiadomości: https://newsrss.bbc.co.uk/rss/newsonline_world_edition/front_page/rss.xml
Nauka/Natura: https://newsrss.bbc.co.uk/rss/newsonline_world_edition/science/nature/rss.xml
Wykonaj kroki opisane w powyższej procedurze, by zbudować źródło dla The BBC (przy użyciu podanych wyżej adresów). Otworzywszy pobraną książkę zobaczysz, że calibre wykonał kawał dobrej roboty, wydobywając zawartość każdego artykułu z witryny. Jednak proces ten nie jest doskonały. Czasem pozostają niepożądane fragmenty, takie jak menu i elementy nawigacji albo są usuwane części, które są potrzebne, np. nagłówki. Aby uzyskać doskonale wyodrębniony tekst artykułów trzeba dopracować proces pobierania, o czym traktuje następna część.
Dostrajanie procesu pobierania¶
Jeśli chcesz udoskonalić proces wyodrębniania tekstu albo pobrać artykuły ze szczególnie skomplikowanej witryny, możesz wykorzystać możliwości i elastyczność narzędzi źródeł. W tym celu, w oknie Dodaj własne źródło wiadomości, kliknij przycisk Przełącz na tryb zaawansowany.
Najprostszym i zwykle najbardziej efektywnym sposobem jest użycie wersji do druku pobieranych artykułów. Taka wersja zawiera zazwyczaj znacznie mniej dodatków i łatwiej ją dostosować do potrzeb e-booka. Użyjmy więc takiej wersji artykułów z The BBC.
Używanie wersji do druku witryny bbc.co.uk¶
Pierwszym krokiem jest sprawdzenie ebooka, pobranego uprzednio z bbc.co.uk. Na końcu każdego artykułu jest mała notka, informująca, skąd został pobrany artykuł. Skopiuj ten adres do przeglądarki. Następnie, na stronie z artykułem poszukaj odsyłacza „Printable version”. Kliknij go, by zobaczyć wersję do druku. Jest znacznie bardziej przejrzysta. Teraz porównaj oba adresy. U mnie były następujące:
Aby otrzymać wersję do druku, adres każdego artykułu musi zaczynać się od:
newsvote.bbc.co.uk/mpapps/pagetools/print/
Now in the Advanced mode of the Custom news sources dialog, you should see something like (remember to select The BBC recipe before switching to advanced mode):
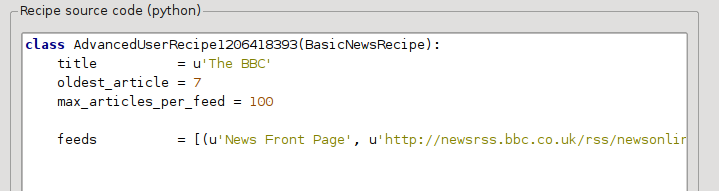
Zauważysz, że pola z okna w trybie podstawowym zostały przetłumaczone wprost na kod pythona. Teraz trzeba zmienić ten kod tak, by używał wersji do druku przy pobieraniu artykułów. Wszystko, czego potrzeba to dodać dwie linie:
def print_version(self, url):
return url.replace('https://', 'https://newsvote.bbc.co.uk/mpapps/pagetools/print/')
To python, więc wcięcia są bardzo ważne. Po dodaniu tych dwóch linii powinno to wyglądać tak:
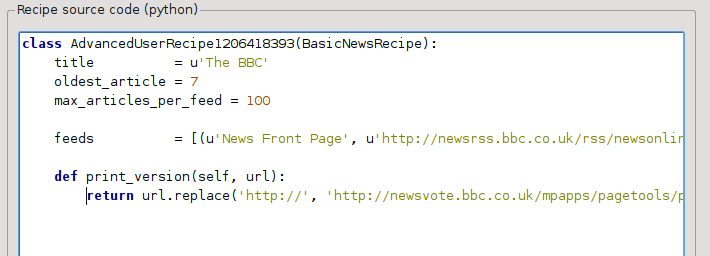
In the above, def print_version(self, url) defines a method that is called by calibre for every article. url is the URL of the original article. What print_version does is take that url and replace it with the new URL that points to the print version of the article. To learn about Python see the tutorial.
Now, click the Add/update recipe button and your changes will be saved. Re-download the e-book. You should have a much improved e-book. One of the problems with the new version is that the fonts on the print version webpage are too small. This is automatically fixed when converting to an e-book, but even after the fixing process, the font size of the menus and navigation bar become too large relative to the article text. To fix this, we will do some more customization, in the next section.
Zamiana stylów¶
W poprzedniej części okazało się, że czcionka w artykułach, pobranych z The BBC w wersji do druku. Jak w wielu innych witrynach, tak i w The BBC wielkość czcionki jest ustawiana za pomocą arkusza stylów CSS. Można zablokować pobieranie takich arkuszy dodając linię:
no_stylesheets = True
Teraz kod wygląda następująco:
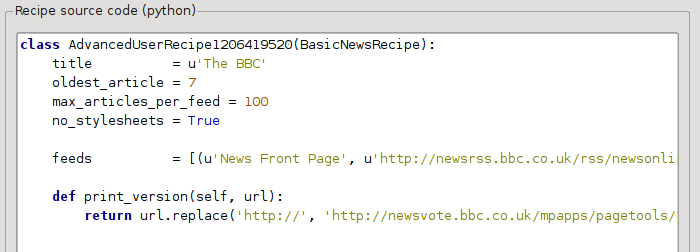
Nowa wersja wygląda nieźle. Jeśli jesteś perfekcjonistą możesz przeczytać kolejną część, która traktuje o modyfikowaniu pobieranej treści.
Szatkowanie wiadomości¶
calibre może na wiele sposobów manipulować pobieraną treścią. Aby pokazać niektóre z nich, przyjrzyjmy się ponownie naszemu, znanemu już źródłu The BBC. Przyjrzawszy się kodowi źródłowemu (:term:``HTML`) kilku artykułów (w wersji do druku) zauważymy, że mają one stopkę, która nie zawiera żadnych użytecznych informacji
<div class="footer">
...
</div>
Można ją usunąć, dodając:
remove_tags = [dict(name='div', attrs={'class':'footer'})]
to the recipe. Finally, let’s replace some of the CSS that we disabled earlier, with our own CSS that is suitable for conversion to an e-book:
extra_css = '.headline {font-size: x-large;} \n .fact { padding-top: 10pt }'
Dzięki tym dodatkom nasza receptura stała się „jakością produkcji”.
to źródło dotyka jedynie czubka góry lodowej jeśli chodzi o możliwości calibre. Aby poznać je bliżej, w następnej części przyjrzymy się bliżej bardziej skomplikowanemu, autentycznemu przykładowi.
Przykład z życia wzięty.¶
Nieco bardziej skomplikowany przykład, wzięty z życia, który pokazuje dokładniej API BasicNewsRecipe to źródło The new York Times
import string, re
from calibre import strftime
from calibre.web.feeds.recipes import BasicNewsRecipe
from calibre.ebooks.BeautifulSoup import BeautifulSoup
class NYTimes(BasicNewsRecipe):
title = 'The New York Times'
__author__ = 'Kovid Goyal'
description = 'Daily news from the New York Times'
timefmt = ' [%a, %d %b, %Y]'
needs_subscription = True
remove_tags_before = dict(id='article')
remove_tags_after = dict(id='article')
remove_tags = [dict(attrs={'class':['articleTools', 'post-tools', 'side_tool', 'nextArticleLink clearfix']}),
dict(id=['footer', 'toolsRight', 'articleInline', 'navigation', 'archive', 'side_search', 'blog_sidebar', 'side_tool', 'side_index']),
dict(name=['script', 'noscript', 'style'])]
encoding = 'cp1252'
no_stylesheets = True
extra_css = 'h1 {font: sans-serif large;}\n.byline {font:monospace;}'
def get_browser(self):
br = BasicNewsRecipe.get_browser(self)
if self.username is not None and self.password is not None:
br.open('https://www.nytimes.com/auth/login')
br.select_form(name='login')
br['USERID'] = self.username
br['PASSWORD'] = self.password
br.submit()
return br
def parse_index(self):
soup = self.index_to_soup('https://www.nytimes.com/pages/todayspaper/index.html')
def feed_title(div):
return ''.join(div.findAll(text=True, recursive=False)).strip()
articles = {}
key = None
ans = []
for div in soup.findAll(True,
attrs={'class':['section-headline', 'story', 'story headline']}):
if ''.join(div['class']) == 'section-headline':
key = string.capwords(feed_title(div))
articles[key] = []
ans.append(key)
elif ''.join(div['class']) in ['story', 'story headline']:
a = div.find('a', href=True)
if not a:
continue
url = re.sub(r'\?.*', '', a['href'])
url += '?pagewanted=all'
title = self.tag_to_string(a, use_alt=True).strip()
description = ''
pubdate = strftime('%a, %d %b')
summary = div.find(True, attrs={'class':'summary'})
if summary:
description = self.tag_to_string(summary, use_alt=False)
feed = key if key is not None else 'Uncategorized'
if feed not in articles:
articles[feed] = []
if not 'podcasts' in url:
articles[feed].append(
dict(title=title, url=url, date=pubdate,
description=description,
content=''))
ans = self.sort_index_by(ans, {'The Front Page':-1, 'Dining In, Dining Out':1, 'Obituaries':2})
ans = [(key, articles[key]) for key in ans if key in articles]
return ans
def preprocess_html(self, soup):
refresh = soup.find('meta', {'http-equiv':'refresh'})
if refresh is None:
return soup
content = refresh.get('content').partition('=')[2]
raw = self.browser.open('https://www.nytimes.com'+content).read()
return BeautifulSoup(raw.decode('cp1252', 'replace'))
Przedstawione tu zostaną nowe funkcje. Po pierwsze:
timefmt = ' [%a, %d %b, %Y]'
Pozwala to ustawić format czasu na okładce tworzonego ebooka na: Dzień, Numer_dnia Miesiąc, Rok. Więcej o timefmt.
Znajduje się tu również grupa poleceń, służących do oczyszczenia pobranego HTMLa:
remove_tags_before = dict(name='h1')
remove_tags_after = dict(id='footer')
remove_tags = ...
Usuwają one wszystko przez pierwszym znacznikiem <h1> i wszystko po pierwszym znaczniku, który ma id footer. Więcej informacji na ten temat remove_tags, remove_tags_before, remove_tags_after.
Następna ciekawostka:
needs_subscription = True
...
def get_browser(self):
...
needs_subscription = True tells calibre that this recipe needs a username and password in order to access the content. This causes, calibre to ask for a username and password whenever you try to use this recipe. The code in calibre.web.feeds.news.BasicNewsRecipe.get_browser() actually does the login into the NYT website. Once logged in, calibre will use the same, logged in, browser instance to fetch all content. See mechanize to understand the code in get_browser.
The next new feature is the
calibre.web.feeds.news.BasicNewsRecipe.parse_index() method. Its job is
to go to https://www.nytimes.com/pages/todayspaper/index.html and fetch the list
of articles that appear in today’s paper. While more complex than simply using
RSS, the recipe creates an e-book that corresponds very closely to the
day’s paper. parse_index makes heavy use of BeautifulSoup to parse
the daily paper webpage. You can also use other, more modern parsers if you
dislike BeautifulSoup. calibre comes with lxml and
html5lib, which are the
recommended parsers. To use them, replace the call to index_to_soup() with
the following:
raw = self.index_to_soup(url, raw=True)
# For html5lib
import html5lib
root = html5lib.parse(raw, namespaceHTMLElements=False, treebuilder='lxml')
# For the lxml html 4 parser
from lxml import html
root = html.fromstring(raw)
Na koniec jeszcze jedna nowa funkcja - calibre.web.feeds.news.BasicNewsRecipe.preprocess_html(). Jest ona używana do wprowadzania zmian w każdej pobranej stronie HTML. Tu została użyta do pominięcia reklam, które witryna wyświetla przed każdym artykułem.
Wskazówki przydatne przy tworzeniu nowych źródeł¶
The best way to develop new recipes is to use the command line interface. Create the recipe using your favorite Python editor and save it to a file say myrecipe.recipe. The .recipe extension is required. You can download content using this recipe with the command:
ebook-convert myrecipe.recipe .epub --test -vv --debug-pipeline debug
The command ebook-convert will download all the webpages and save
them to the EPUB file myrecipe.epub. The -vv option makes
ebook-convert spit out a lot of information about what it is doing. The
ebook-convert-recipe-input --test option makes it download only a couple of articles from at most two
feeds. In addition, ebook-convert will put the downloaded HTML into the
debug/input folder, where debug is the folder you specified in
the ebook-convert --debug-pipeline option.
Once the download is complete, you can look at the downloaded HTML by opening the file debug/input/index.html in a browser. Once you’re satisfied that the download and preprocessing is happening correctly, you can generate e-books in different formats as shown below:
ebook-convert myrecipe.recipe myrecipe.epub
ebook-convert myrecipe.recipe myrecipe.mobi
...
If you’re satisfied with your recipe, and you feel there is enough demand to justify its inclusion into the set of built-in recipes, post your recipe in the calibre recipes forum to share it with other calibre users.
Informacja
W systemie macOS narzędzia wiersza poleceń znajdują się w pakiecie kalibru, na przykład, jeśli zainstalowałeś calibre w /Applications, narzędzia wiersza poleceń znajdują się w :file:`/Applications/calibre.app/Contents/MacOS/ ` .
Zobacz także
- ebook-convert
Interfejs wiersza poleceń do wszystkich konwersji e-booków.
Dalsza lektura¶
Aby dowiedzieć się więcej o pisaniu zaawansowanych źródeł przy użyciu narzędzi, dostępnych w BasicNewsRecipe, możesz skorzystać z poniższych źródeł:
- API documentation
Dokumentacja klasy
BasicNewsRecipei wszystkich najważniejszych metod i właściwości.- BasicNewsRecipe
Kod źródłowy
BasicNewsRecipe- Wbudowane źródła
Kod źródeł dostarczanych z calibre
- The calibre recipes forum
Tu znajdziesz wiele osób, które wiedzą bardzo dużo o tworzeniu źródeł.
Dokumentacja API¶
- API documentation for recipes
BasicNewsRecipeBasicNewsRecipe.adeify_images()BasicNewsRecipe.image_url_processor()BasicNewsRecipe.print_version()BasicNewsRecipe.tag_to_string()BasicNewsRecipe.abort_article()BasicNewsRecipe.abort_recipe_processing()BasicNewsRecipe.add_toc_thumbnail()BasicNewsRecipe.canonicalize_internal_url()BasicNewsRecipe.cleanup()BasicNewsRecipe.clone_browser()BasicNewsRecipe.default_cover()BasicNewsRecipe.download()BasicNewsRecipe.extract_readable_article()BasicNewsRecipe.get_article_url()BasicNewsRecipe.get_browser()BasicNewsRecipe.get_cover_url()BasicNewsRecipe.get_extra_css()BasicNewsRecipe.get_feeds()BasicNewsRecipe.get_masthead_title()BasicNewsRecipe.get_masthead_url()BasicNewsRecipe.get_obfuscated_article()BasicNewsRecipe.get_url_specific_delay()BasicNewsRecipe.index_to_soup()BasicNewsRecipe.is_link_wanted()BasicNewsRecipe.parse_feeds()BasicNewsRecipe.parse_index()BasicNewsRecipe.populate_article_metadata()BasicNewsRecipe.postprocess_book()BasicNewsRecipe.postprocess_html()BasicNewsRecipe.preprocess_html()BasicNewsRecipe.preprocess_image()BasicNewsRecipe.preprocess_raw_html()BasicNewsRecipe.publication_date()BasicNewsRecipe.skip_ad_pages()BasicNewsRecipe.sort_index_by()BasicNewsRecipe.articles_are_obfuscatedBasicNewsRecipe.auto_cleanupBasicNewsRecipe.auto_cleanup_keepBasicNewsRecipe.browser_typeBasicNewsRecipe.center_navbarBasicNewsRecipe.compress_news_imagesBasicNewsRecipe.compress_news_images_auto_sizeBasicNewsRecipe.compress_news_images_max_sizeBasicNewsRecipe.conversion_optionsBasicNewsRecipe.cover_marginsBasicNewsRecipe.delayBasicNewsRecipe.descriptionBasicNewsRecipe.encodingBasicNewsRecipe.extra_cssBasicNewsRecipe.feedsBasicNewsRecipe.filter_regexpsBasicNewsRecipe.handle_gzipBasicNewsRecipe.ignore_duplicate_articlesBasicNewsRecipe.keep_only_tagsBasicNewsRecipe.languageBasicNewsRecipe.masthead_urlBasicNewsRecipe.match_regexpsBasicNewsRecipe.max_articles_per_feedBasicNewsRecipe.needs_subscriptionBasicNewsRecipe.no_stylesheetsBasicNewsRecipe.oldest_articleBasicNewsRecipe.preprocess_regexpsBasicNewsRecipe.publication_typeBasicNewsRecipe.recipe_disabledBasicNewsRecipe.recipe_specific_optionsBasicNewsRecipe.recursionsBasicNewsRecipe.remove_attributesBasicNewsRecipe.remove_empty_feedsBasicNewsRecipe.remove_javascriptBasicNewsRecipe.remove_tagsBasicNewsRecipe.remove_tags_afterBasicNewsRecipe.remove_tags_beforeBasicNewsRecipe.requires_versionBasicNewsRecipe.resolve_internal_linksBasicNewsRecipe.reverse_article_orderBasicNewsRecipe.scale_news_imagesBasicNewsRecipe.scale_news_images_to_deviceBasicNewsRecipe.simultaneous_downloadsBasicNewsRecipe.summary_lengthBasicNewsRecipe.template_cssBasicNewsRecipe.timefmtBasicNewsRecipe.timeoutBasicNewsRecipe.titleBasicNewsRecipe.use_embedded_content