 Change language
Change languageAdding your favorite news website¶
calibre has a powerful, flexible and easy-to-use framework for downloading news from the Internet and converting it into an e-book. The following will show you, by means of examples, how to get news from various websites.
To gain an understanding of how to use the framework, follow the examples in the order listed below:
Completely automatic fetching¶
If your news source is simple enough, calibre may well be able to fetch it completely automatically, all you need to do is provide the URL. calibre gathers all the information needed to download a news source into a recipe. In order to tell calibre about a news source, you have to create a recipe for it. Let’s see some examples:
The calibre blog¶
The calibre blog is a blog of posts that describe many useful calibre features in a simple and accessible way for new calibre users. In order to download this blog into an e-book, we rely on the RSS feed of the blog:
http://blog.calibre-ebook.com/feeds/posts/default
I got the RSS URL by looking under “Subscribe to” at the bottom of the blog page and choosing Posts → Atom. To make calibre download the feeds and convert them into an e-book, you should right click the Fetch news button and then the Add a custom news source menu item and then the New Recipe button. A dialog similar to that shown below should open up.
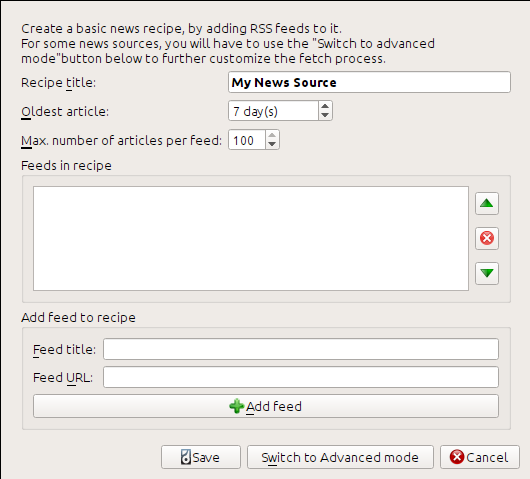
First enter Calibre Blog into the Recipe title field. This will be the title of the e-book that will be created from the articles in the above feeds.
The next two fields (Oldest article and Max. number of articles) allow you some control over how many articles should be downloaded from each feed, and they are pretty self explanatory.
To add the feeds to the recipe, enter the feed title and the feed URL and click the Add feed button. Once you have added the feed, simply click the Save button and you’re done! Close the dialog.
To test your new recipe, click the Fetch news button and in the Custom news sources sub-menu click calibre Blog. After a couple of minutes, the newly downloaded e-book of blog posts will appear in the main library view (if you have your reader connected, it will be put onto the reader instead of into the library). Select it and hit the View button to read!
The reason this worked so well, with so little effort is that the blog provides full-content RSS feeds, i.e., the article content is embedded in the feed itself. For most news sources that provide news in this fashion, with full-content feeds, you don’t need any more effort to convert them to e-books. Now we will look at a news source that does not provide full content feeds. In such feeds, the full article is a webpage and the feed only contains a link to the webpage with a short summary of the article.
bbc.co.uk¶
Let’s try the following two feeds from The BBC:
Follow the procedure outlined in The calibre blog above to create a recipe for The BBC (using the feeds above). Looking at the downloaded e-book, we see that calibre has done a creditable job of extracting only the content you care about from each article’s webpage. However, the extraction process is not perfect. Sometimes it leaves in undesirable content like menus and navigation aids or it removes content that should have been left alone, like article headings. In order, to have perfect content extraction, we will need to customize the fetch process, as described in the next section.
Customizing the fetch process¶
When you want to perfect the download process, or download content from a particularly complex website, you can avail yourself of all the power and flexibility of the recipe framework. In order to do that, in the Add custom news sources dialog, simply click the Switch to Advanced mode button.
The easiest and often most productive customization is to use the print version of the online articles. The print version typically has much less cruft and translates much more smoothly to an e-book. Let’s try to use the print version of the articles from The BBC.
Using the print version of bbc.co.uk¶
The first step is to look at the e-book we downloaded previously from bbc.co.uk. At the end of each article, in the e-book is a little blurb telling you where the article was downloaded from. Copy and paste that URL into a browser. Now on the article webpage look for a link that points to the “Printable version”. Click it to see the print version of the article. It looks much neater! Now compare the two URLs. For me they were:
So it looks like to get the print version, we need to prefix every article URL with:
newsvote.bbc.co.uk/mpapps/pagetools/print/
Now in the Advanced mode of the Custom news sources dialog, you should see something like (remember to select The BBC recipe before switching to advanced mode):
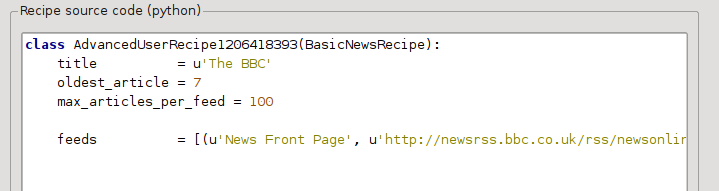
You can see that the fields from the Basic mode have been translated to Python code in a straightforward manner. We need to add instructions to this recipe to use the print version of the articles. All that’s needed is to add the following two lines:
def print_version(self, url):
return url.replace('https://', 'https://newsvote.bbc.co.uk/mpapps/pagetools/print/')
This is Python, so indentation is important. After you’ve added the lines, it should look like:
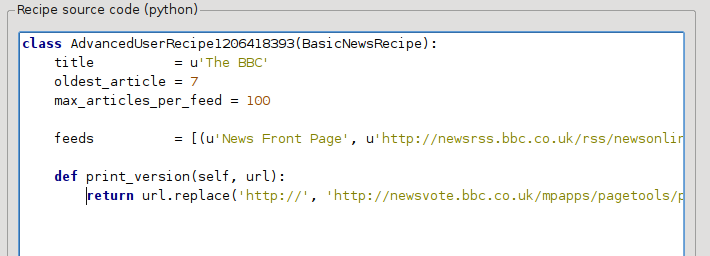
In the above, def print_version(self, url) defines a method that is called by calibre for every article. url is the URL of the original article. What print_version does is take that url and replace it with the new URL that points to the print version of the article. To learn about Python see the tutorial.
Now, click the Add/update recipe button and your changes will be saved. Re-download the e-book. You should have a much improved e-book. One of the problems with the new version is that the fonts on the print version webpage are too small. This is automatically fixed when converting to an e-book, but even after the fixing process, the font size of the menus and navigation bar become too large relative to the article text. To fix this, we will do some more customization, in the next section.
Replacing article styles¶
In the previous section, we saw that the font size for articles from the print version of The BBC was too small. In most websites, The BBC included, this font size is set by means of CSS stylesheets. We can disable the fetching of such stylesheets by adding the line:
no_stylesheets = True
The recipe now looks like:
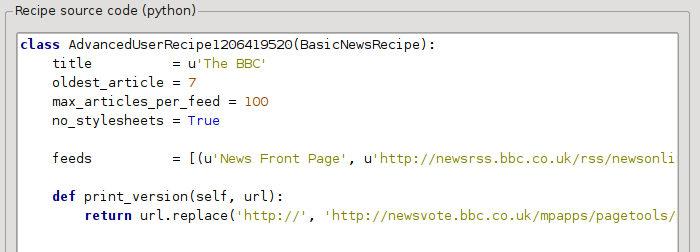
The new version looks pretty good. If you’re a perfectionist, you’ll want to read the next section, which deals with actually modifying the downloaded content.
Slicing and dicing¶
calibre contains very powerful and flexible abilities when it comes to manipulating downloaded content. To show off a couple of these, let’s look at our old friend the The BBC recipe again. Looking at the source code (HTML) of a couple of articles (print version), we see that they have a footer that contains no useful information, contained in
<div class="footer">
...
</div>
This can be removed by adding:
remove_tags = [dict(name='div', attrs={'class':'footer'})]
to the recipe. Finally, let’s replace some of the CSS that we disabled earlier, with our own CSS that is suitable for conversion to an e-book:
extra_css = '.headline {font-size: x-large;} \n .fact { padding-top: 10pt }'
With these additions, our recipe has become “production quality”.
This recipe explores only the tip of the iceberg when it comes to the power of calibre. To explore more of the abilities of calibre we’ll examine a more complex real life example in the next section.
Real life example¶
A reasonably complex real life example that exposes more of the API of BasicNewsRecipe is the recipe for The New York Times
import string, re
from calibre import strftime
from calibre.web.feeds.recipes import BasicNewsRecipe
from calibre.ebooks.BeautifulSoup import BeautifulSoup
class NYTimes(BasicNewsRecipe):
title = 'The New York Times'
__author__ = 'Kovid Goyal'
description = 'Daily news from the New York Times'
timefmt = ' [%a, %d %b, %Y]'
needs_subscription = True
remove_tags_before = dict(id='article')
remove_tags_after = dict(id='article')
remove_tags = [dict(attrs={'class':['articleTools', 'post-tools', 'side_tool', 'nextArticleLink clearfix']}),
dict(id=['footer', 'toolsRight', 'articleInline', 'navigation', 'archive', 'side_search', 'blog_sidebar', 'side_tool', 'side_index']),
dict(name=['script', 'noscript', 'style'])]
encoding = 'cp1252'
no_stylesheets = True
extra_css = 'h1 {font: sans-serif large;}\n.byline {font:monospace;}'
def get_browser(self):
br = BasicNewsRecipe.get_browser(self)
if self.username is not None and self.password is not None:
br.open('https://www.nytimes.com/auth/login')
br.select_form(name='login')
br['USERID'] = self.username
br['PASSWORD'] = self.password
br.submit()
return br
def parse_index(self):
soup = self.index_to_soup('https://www.nytimes.com/pages/todayspaper/index.html')
def feed_title(div):
return ''.join(div.findAll(text=True, recursive=False)).strip()
articles = {}
key = None
ans = []
for div in soup.findAll(True,
attrs={'class':['section-headline', 'story', 'story headline']}):
if ''.join(div['class']) == 'section-headline':
key = string.capwords(feed_title(div))
articles[key] = []
ans.append(key)
elif ''.join(div['class']) in ['story', 'story headline']:
a = div.find('a', href=True)
if not a:
continue
url = re.sub(r'\?.*', '', a['href'])
url += '?pagewanted=all'
title = self.tag_to_string(a, use_alt=True).strip()
description = ''
pubdate = strftime('%a, %d %b')
summary = div.find(True, attrs={'class':'summary'})
if summary:
description = self.tag_to_string(summary, use_alt=False)
feed = key if key is not None else 'Uncategorized'
if feed not in articles:
articles[feed] = []
if not 'podcasts' in url:
articles[feed].append(
dict(title=title, url=url, date=pubdate,
description=description,
content=''))
ans = self.sort_index_by(ans, {'The Front Page':-1, 'Dining In, Dining Out':1, 'Obituaries':2})
ans = [(key, articles[key]) for key in ans if key in articles]
return ans
def preprocess_html(self, soup):
refresh = soup.find('meta', {'http-equiv':'refresh'})
if refresh is None:
return soup
content = refresh.get('content').partition('=')[2]
raw = self.browser.open('https://www.nytimes.com'+content).read()
return BeautifulSoup(raw.decode('cp1252', 'replace'))
We see several new features in this recipe. First, we have:
timefmt = ' [%a, %d %b, %Y]'
This sets the displayed time on the front page of the created e-book to be in the format,
Day, Day_Number Month, Year. See timefmt.
Then we see a group of directives to cleanup the downloaded HTML:
remove_tags_before = dict(name='h1')
remove_tags_after = dict(id='footer')
remove_tags = ...
These remove everything before the first <h1> tag and everything after the first tag whose id is footer. See remove_tags, remove_tags_before, remove_tags_after.
The next interesting feature is:
needs_subscription = True
...
def get_browser(self):
...
needs_subscription = True tells calibre that this recipe needs a username and password in order to access the content. This causes, calibre to ask for a username and password whenever you try to use this recipe. The code in calibre.web.feeds.news.BasicNewsRecipe.get_browser() actually does the login into the NYT website. Once logged in, calibre will use the same, logged in, browser instance to fetch all content. See mechanize to understand the code in get_browser.
The next new feature is the
calibre.web.feeds.news.BasicNewsRecipe.parse_index() method. Its job is
to go to https://www.nytimes.com/pages/todayspaper/index.html and fetch the list
of articles that appear in today’s paper. While more complex than simply using
RSS, the recipe creates an e-book that corresponds very closely to the
day’s paper. parse_index makes heavy use of BeautifulSoup to parse
the daily paper webpage. You can also use other, more modern parsers if you
dislike BeautifulSoup. calibre comes with lxml and
html5lib, which are the
recommended parsers. To use them, replace the call to index_to_soup() with
the following:
raw = self.index_to_soup(url, raw=True)
# For html5lib
import html5lib
root = html5lib.parse(raw, namespaceHTMLElements=False, treebuilder='lxml')
# For the lxml html 4 parser
from lxml import html
root = html.fromstring(raw)
The final new feature is the calibre.web.feeds.news.BasicNewsRecipe.preprocess_html() method. It can be used to perform arbitrary transformations on every downloaded HTML page. Here it is used to bypass the ads that the nytimes shows you before each article.
Tips for developing new recipes¶
The best way to develop new recipes is to use the command line interface. Create the recipe using your favorite Python editor and save it to a file say myrecipe.recipe. The .recipe extension is required. You can download content using this recipe with the command:
ebook-convert myrecipe.recipe .epub --test -vv --debug-pipeline debug
The command ebook-convert will download all the webpages and save
them to the EPUB file myrecipe.epub. The -vv option makes
ebook-convert spit out a lot of information about what it is doing. The
ebook-convert-recipe-input --test option makes it download only a couple of articles from at most two
feeds. In addition, ebook-convert will put the downloaded HTML into the
debug/input folder, where debug is the folder you specified in
the ebook-convert --debug-pipeline option.
Once the download is complete, you can look at the downloaded HTML by opening the file debug/input/index.html in a browser. Once you’re satisfied that the download and preprocessing is happening correctly, you can generate e-books in different formats as shown below:
ebook-convert myrecipe.recipe myrecipe.epub
ebook-convert myrecipe.recipe myrecipe.mobi
...
If you’re satisfied with your recipe, and you feel there is enough demand to justify its inclusion into the set of built-in recipes, post your recipe in the calibre recipes forum to share it with other calibre users.
Note
On macOS, the command line tools are inside the calibre bundle, for example,
if you installed calibre in /Applications the command line tools
are in /Applications/calibre.app/Contents/MacOS/.
See also
- ebook-convert
The command line interface for all e-book conversion.
Further reading¶
To learn more about writing advanced recipes using some of the facilities, available in BasicNewsRecipe you should consult the following sources:
- API documentation
Documentation of the
BasicNewsRecipeclass and all its important methods and fields.- BasicNewsRecipe
The source code of
BasicNewsRecipe- Built-in recipes
The source code for the built-in recipes that come with calibre
- The calibre recipes forum
Lots of knowledgeable calibre recipe writers hang out here.
API documentation¶
- API documentation for recipes
BasicNewsRecipeBasicNewsRecipe.adeify_images()BasicNewsRecipe.image_url_processor()BasicNewsRecipe.print_version()BasicNewsRecipe.tag_to_string()BasicNewsRecipe.abort_article()BasicNewsRecipe.abort_recipe_processing()BasicNewsRecipe.add_toc_thumbnail()BasicNewsRecipe.canonicalize_internal_url()BasicNewsRecipe.cleanup()BasicNewsRecipe.clone_browser()BasicNewsRecipe.default_cover()BasicNewsRecipe.download()BasicNewsRecipe.extract_readable_article()BasicNewsRecipe.get_article_url()BasicNewsRecipe.get_browser()BasicNewsRecipe.get_cover_url()BasicNewsRecipe.get_extra_css()BasicNewsRecipe.get_feeds()BasicNewsRecipe.get_masthead_title()BasicNewsRecipe.get_masthead_url()BasicNewsRecipe.get_obfuscated_article()BasicNewsRecipe.get_url_specific_delay()BasicNewsRecipe.index_to_soup()BasicNewsRecipe.is_link_wanted()BasicNewsRecipe.parse_feeds()BasicNewsRecipe.parse_index()BasicNewsRecipe.populate_article_metadata()BasicNewsRecipe.postprocess_book()BasicNewsRecipe.postprocess_html()BasicNewsRecipe.preprocess_html()BasicNewsRecipe.preprocess_image()BasicNewsRecipe.preprocess_raw_html()BasicNewsRecipe.publication_date()BasicNewsRecipe.skip_ad_pages()BasicNewsRecipe.sort_index_by()BasicNewsRecipe.articles_are_obfuscatedBasicNewsRecipe.auto_cleanupBasicNewsRecipe.auto_cleanup_keepBasicNewsRecipe.browser_typeBasicNewsRecipe.center_navbarBasicNewsRecipe.compress_news_imagesBasicNewsRecipe.compress_news_images_auto_sizeBasicNewsRecipe.compress_news_images_max_sizeBasicNewsRecipe.conversion_optionsBasicNewsRecipe.cover_marginsBasicNewsRecipe.delayBasicNewsRecipe.descriptionBasicNewsRecipe.encodingBasicNewsRecipe.extra_cssBasicNewsRecipe.feedsBasicNewsRecipe.filter_regexpsBasicNewsRecipe.handle_gzipBasicNewsRecipe.ignore_duplicate_articlesBasicNewsRecipe.keep_only_tagsBasicNewsRecipe.languageBasicNewsRecipe.masthead_urlBasicNewsRecipe.match_regexpsBasicNewsRecipe.max_articles_per_feedBasicNewsRecipe.needs_subscriptionBasicNewsRecipe.no_stylesheetsBasicNewsRecipe.oldest_articleBasicNewsRecipe.preprocess_regexpsBasicNewsRecipe.publication_typeBasicNewsRecipe.recipe_disabledBasicNewsRecipe.recipe_specific_optionsBasicNewsRecipe.recursionsBasicNewsRecipe.remove_attributesBasicNewsRecipe.remove_empty_feedsBasicNewsRecipe.remove_javascriptBasicNewsRecipe.remove_tagsBasicNewsRecipe.remove_tags_afterBasicNewsRecipe.remove_tags_beforeBasicNewsRecipe.requires_versionBasicNewsRecipe.resolve_internal_linksBasicNewsRecipe.reverse_article_orderBasicNewsRecipe.scale_news_imagesBasicNewsRecipe.scale_news_images_to_deviceBasicNewsRecipe.simultaneous_downloadsBasicNewsRecipe.summary_lengthBasicNewsRecipe.template_cssBasicNewsRecipe.timefmtBasicNewsRecipe.timeoutBasicNewsRecipe.titleBasicNewsRecipe.use_embedded_content