 Змінити мову
Змінити мовуДодавання вашого улюбленого сайта новин¶
У calibre передбачено потужну, гнучку і просту у користуванні бібліотеку для отримання новин з інтернету та перетворення даних цих новин на електронну книгу. Нижче ми покажемо вам, на прикладах, як отримувати новини з різноманітних сайтів.
Щоб дізнатися більше про те, як користуватися бібліотекою, послідовно ознайомтеся із прикладами з наведеного нижче переліку:
Повністю автоматизоване отримання даних¶
Якщо ваше джерело новин є доволі простим, calibre, ймовірно, зможе отримувати дані з нього у повністю автоматичному режимі — вам достатньо буде лише вказати адресу. calibre збирає усі дані, потрібні для дотримання даних джерела новин до рецепт`а. Щоб повідомити calibre про джерело новин, вам слід створити для нього :term:`рецепт. Розгляньмо декілька прикладів:
Блог calibre¶
У блозі calibre розміщують дописи, які описують для нових користувачів calibre багато корисних можливостей програми. Щоб отримати дані цього блогу у форматі електронної книги, ми скористаємося подачею RSS блогу:
http://blog.calibre-ebook.com/feeds/posts/default
Отримати адресу RSS можна, пошукавши у розділі «Subscribe to» у нижній частині сторінки блогу і вибравши Posts → Atom. Щоб зробити так, щоб програма calibre отримувала подачі і перетворювала вміст дописів на електронні книги, вам слід натиснути стрілку, розташовану праворуч від кнопки Отримати новини, і потім вибрати пункт меню Додати власне джерело новин, і далі натиснути кнопку Створити рецепт. У відповідь буде відкрито діалогове вікно, подібне до наведеного нижче.
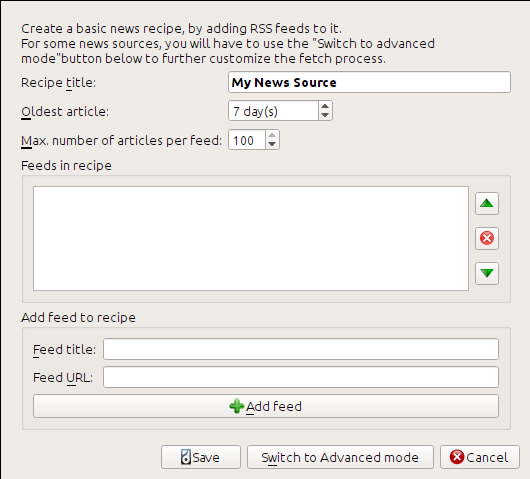
Спочатку введіть Calibre Blog у поле Назва рецепта. Ця назва визначить назву електронної книги, яку буде створено на основі статей у вказаних вище подачах.
За допомогою наступних двох полів (Найстаріша стаття і Макс. кількість статей) ви можете керувати тим, скільки статей слід отримувати для кожної з подач. Призначення цих полів є доволі очевидним.
Щоб додати подачі до рецепта, вкажіть назву подачі та її адресу, а потім натисніть кнопку Додати подачу. Після додавання подачі натисніть кнопку Зберегти, і усе! Закрийте діалогове вікно.
Щоб випробувати ваш новий рецепт, натисніть кнопку Отримати новини і у підменю Нетипові джерела новин вибрати пункт calibre Blog. За декілька хвилин на панелі основної бібліотеки з’явиться щойно отримана електронна книга із дописами у блозі. Якщо з комп’ютером з’єднано ваш пристрій для читання електронних книг, книгу буде записано на пристрій замість бібліотеки. Позначте книгу і натисніть кнопку Перегляд, щоб розпочати читання!
Причиною того, що все спрацювало так добре із мінімумом зусиль, є те, що блозі використано повноформатні подачі RSS, тобто вміст статей вбудовано до самої подачі. Для більшості джерел новин, які надають дані у цей спосіб, із повноформатними подачами, вам не знадобляться ніяких зусилля для перетворення даних на електронні книги. Тепер погляньмо на джерело новин, яке не надає повноформатних подач. У подачах таких джерел повний текст новини міститься на сторінці сайта, а у подачі міститься лише посилання на сторінку із коротким резюме статті.
bbc.co.uk¶
Спробуємо скористатися вказаними нижче двома подачами з The BBC:
Перша сторінка новин: https://newsrss.bbc.co.uk/rss/newsonline_world_edition/front_page/rss.xml
Наука і природа: https://newsrss.bbc.co.uk/rss/newsonline_world_edition/science/nature/rss.xml
Виконайте процедуру, яку описано вище у розділі Блог calibre, для створення рецепта для The BBC (використайте наведені вище адреси подач). Якщо поглянути на отриману електронну книгу, можна побачити, що calibre виконано значний обсяг робіт для видобування лише потрібних вам даних зі сторінок усіх статей. Втім, процедура видобування не є ідеальною. Іноді, після неї залишаються небажані дані, зокрема меню та навігаційні засоби, або вилучаються дані, які варто було б лишити, зокрема заголовки статей. Для отримання ідеального набору даних нам доведеться налаштувати процес отримання у спосіб, який описано у наступному розділі.
Налаштовування процесу отримання даних¶
Якщо ви хочете зробити процес отримання даних або вміст книг з якогось складного сайта ідеальним, ви можете скористатися усією потужністю та гнучкістю набору бібліотек recipe. Для цього у діалоговому вікні Додати нетипове джерело новин натисніть кнопку Перемкнутися у розширений режим.
Найпростішою і часто найпродуктивнішою зміною є використання друкованої версії інтернет-статей. Зазвичай, така друкована версія містить набагато менше зайвих частин і набагато простіше перетворюється на електронну книгу. Давайте спробуємо скористатися друкованою версією статей з The BBC.
Використання друкованої версії bbc.co.uk¶
Першим кроком є вивчення електронної книги, яку ми раніше отримати з bbc.co.uk. Наприкінці кожної зі статей у електронній книзі є невеличка анотація, яка повідомляє про те, звідки було отримано статтю. Скопіюйте і вставте цю адресу до вікна програми для перегляду інтернету. Тепер, на сторінці статті знайдіть посилання, яке вказує на друковану версію («Printable version»). Натисніть його, щоб переглянути друковану версію статті. Усе виглядає набагато краще! Тепер порівняймо дві адреси. У мене вони виглядають так:
- Адреса статті
- Адреса друкованої версії
https://newsvote.bbc.co.uk/mpapps/pagetools/print/news.bbc.co.uk/2/hi/science/nature/7312016.stm
Отже, здається, для того, щоб отримати придатну до друку версію, нам слід додати до кожної адреси статті такий префікс:
newsvote.bbc.co.uk/mpapps/pagetools/print/
Тепер, у Розширеному режимі діалогового вікна нетипових джерел новин ви маєте побачити щось таке (не забудьте вибрати рецепт The BBC перед перемиканням у розширений режим):
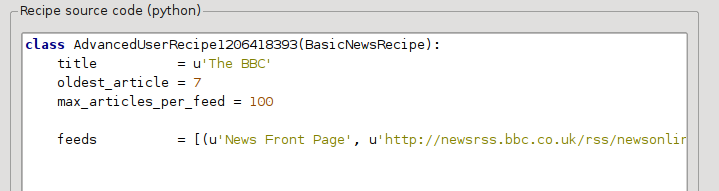
Як бачите, поля з Базового режиму перетворилися на код Python у доволі очевидний спосіб. Нам слід додати до цього рецепту інструкції для використання друкованої версії статей. Для цього достатньо додати такі два рядки:
def print_version(self, url):
return url.replace('https://', 'https://newsvote.bbc.co.uk/mpapps/pagetools/print/')
Це мова програмування Python, тому важливо використовувати відступи у рядках коду. Після додавання вами рядків, код має виглядати так:
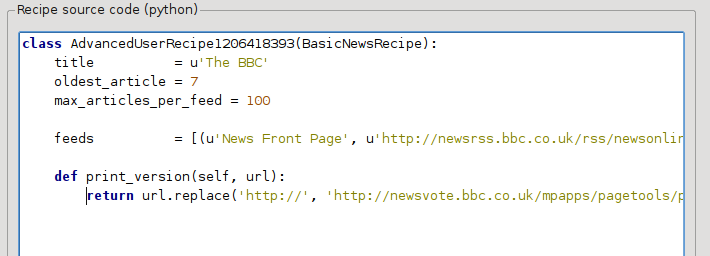
У наведеному вище коді def print_version(self, url) визначає метод, який викликається calibre для кожної статті. url — це адреса початкової версії статті. print_version бере адресу і замінює її новою адресою, яка вказує на друковану версію статті. Щоб дізнатися більше про програмування мовою Python, ознайомтеся з підручником.
Тепер натисніть кнопку Додати/Оновити рецепт, і внесені вами зміни буде збережено. Повторно отримайте книгу. Тепер вона має бути набагато ліпшою. Однією з проблем у новій версії є те, що типові шрифти друкованої версії сторінки є надто малими. Це автоматично виправляється під час перетворення даних на електронну книгу, але навіть після виправлення розмір шрифту меню і панелі навігації є набагато більшим за розмір шрифту тексту статті. Щоб виправити це, ми реалізуємо певні додаткові виправлення у наступному розділі.
Заміна стилів статті¶
У попередньому розділі ми бачили, що розмір шрифту для статей у версії для друку сторінок The BBC є надто малим. На більшості сайтів, зокрема і на The BBC, цей розмір шрифту встановлюється таблицями стилів CSS. Ви можете вимкнути отримання таких таблиць стилів додаванням такого рядка:
no_stylesheets = True
Тепер рецепт виглядає так:
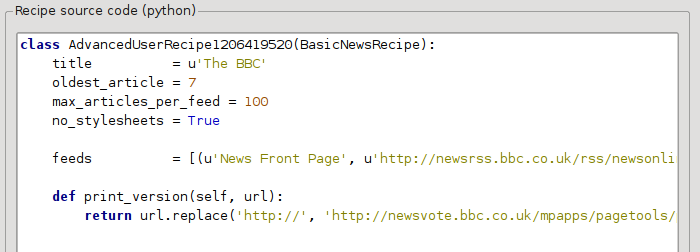
Нова версія виглядає достатньо якісною. Якщо вам завжди хочеться повної досконалості, вам варто ознайомитися із наступним розділом, де обговорено внесення змін до отриманих даних.
Вирізання і склеювання¶
У calibre передбачено дуже потужні і гнучкі можливості щодо обробки отриманих даних. Щоб продемонструвати частину цих можливостей, звернімося до нашого старого доброго рецепта The BBC. Погляньмо на початковий код (HTML) статей (версії для друку). Як можна помітити, у них є нижній колонтитул, у якому не міститься корисної інформації. Він є частиною
<div class="footer">
...
</div>
Його можна вилучити додаванням такого коду:
remove_tags = [dict(name='div', attrs={'class':'footer'})]
до рецепта. Нарешті, давайте замінимо частину CSS, які ми вимкнули раніше, нашими власними CSS, які придатні для застосування перетворення до книги:
extra_css = '.headline {font-size: x-large;} \n .fact { padding-top: 10pt }'
Із цими доповненнями наш рецепт набув «промислової якості».
Цей рецепт використовує лише верхівку айсберга, якщо йдеться про потужність calibre. Щоб познайомитися із ширшим спектром можливостей calibre, ми вивчимо складніший приклад з реального життя у наступному розділі.
Наближений до реальності приклад¶
Прийнятно складним наближеним до реальності прикладом, який продемонструє ширші можливості програмного інтерфейсу BasicNewsRecipe є рецепт для The New York Times
import string, re
from calibre import strftime
from calibre.web.feeds.recipes import BasicNewsRecipe
from calibre.ebooks.BeautifulSoup import BeautifulSoup
class NYTimes(BasicNewsRecipe):
title = 'The New York Times'
__author__ = 'Kovid Goyal'
description = 'Daily news from the New York Times'
timefmt = ' [%a, %d %b, %Y]'
needs_subscription = True
remove_tags_before = dict(id='article')
remove_tags_after = dict(id='article')
remove_tags = [dict(attrs={'class':['articleTools', 'post-tools', 'side_tool', 'nextArticleLink clearfix']}),
dict(id=['footer', 'toolsRight', 'articleInline', 'navigation', 'archive', 'side_search', 'blog_sidebar', 'side_tool', 'side_index']),
dict(name=['script', 'noscript', 'style'])]
encoding = 'cp1252'
no_stylesheets = True
extra_css = 'h1 {font: sans-serif large;}\n.byline {font:monospace;}'
def get_browser(self):
br = BasicNewsRecipe.get_browser(self)
if self.username is not None and self.password is not None:
br.open('https://www.nytimes.com/auth/login')
br.select_form(name='login')
br['USERID'] = self.username
br['PASSWORD'] = self.password
br.submit()
return br
def parse_index(self):
soup = self.index_to_soup('https://www.nytimes.com/pages/todayspaper/index.html')
def feed_title(div):
return ''.join(div.findAll(text=True, recursive=False)).strip()
articles = {}
key = None
ans = []
for div in soup.findAll(True,
attrs={'class':['section-headline', 'story', 'story headline']}):
if ''.join(div['class']) == 'section-headline':
key = string.capwords(feed_title(div))
articles[key] = []
ans.append(key)
elif ''.join(div['class']) in ['story', 'story headline']:
a = div.find('a', href=True)
if not a:
continue
url = re.sub(r'\?.*', '', a['href'])
url += '?pagewanted=all'
title = self.tag_to_string(a, use_alt=True).strip()
description = ''
pubdate = strftime('%a, %d %b')
summary = div.find(True, attrs={'class':'summary'})
if summary:
description = self.tag_to_string(summary, use_alt=False)
feed = key if key is not None else 'Uncategorized'
if feed not in articles:
articles[feed] = []
if not 'podcasts' in url:
articles[feed].append(
dict(title=title, url=url, date=pubdate,
description=description,
content=''))
ans = self.sort_index_by(ans, {'The Front Page':-1, 'Dining In, Dining Out':1, 'Obituaries':2})
ans = [(key, articles[key]) for key in ans if key in articles]
return ans
def preprocess_html(self, soup):
refresh = soup.find('meta', {'http-equiv':'refresh'})
if refresh is None:
return soup
content = refresh.get('content').partition('=')[2]
raw = self.browser.open('https://www.nytimes.com'+content).read()
return BeautifulSoup(raw.decode('cp1252', 'replace'))
У цьому :term:`рецепт`і ми познайомимося із декількома новими можливостями. На початку маємо:
timefmt = ' [%a, %d %b, %Y]'
Це встановлює формат показаного часу на першій сторінці створеної електронної книги День, Номер_дня Місяць, Рік. Див. timefmt.
Далі йде група інструкцій для чищення отриманих даних HTML:
remove_tags_before = dict(name='h1')
remove_tags_after = dict(id='footer')
remove_tags = ...
Ці команди вилучають усе до першого теґу <h1> і усе після першого теґу, чиїм ідентифікатором є footer. Див. remove_tags, remove_tags_before, remove_tags_after.
Ще одна цікава можливість:
needs_subscription = True
...
def get_browser(self):
...
needs_subscription = True повідомляє calibre, що рецепту потрібні ім’я користувача і пароль для доступу до даних. Використання цього значення спричиняє у calibre появу діалогового вікна запиту щодо імені користувача і пароля кожного разу, коли ви намагатиметеся скористатися цим рецептом. Код у calibre.web.feeds.news.BasicNewsRecipe.get_browser() виконує дії, які потрібні для того, щоб увійти як зареєстрований користувача на сайт NYT. Після входу calibre використає той самий, уповноважений екземпляр програми для перегляду інтернету для отримання усіх даних. Щоб краще зрозуміти код у get_browser, див mechanize.
Наступною новою можливістю є метод calibre.web.feeds.news.BasicNewsRecipe.parse_index(). Його завданням є перехід на https://www.nytimes.com/pages/todayspaper/index.html і отримання списку статей, які з’являються у сьогоднішній газеті. Хоча рецепт є складнішим за просте використання RSS, він створює електронну книгу, яка дуже схожа на щоденну газету. parse_index широко використовує BeautifulSoup для обробки сторінки щоденної газети. Ви можете скористатися іншими, новішими обробниками, якщо вам не подобається BeautifulSoup. У calibre вбудовано lxml та html5lib, які є рекомендованими засобами обробки. Щоб скористатися ними, замініть виклик index_to_soup() на такий код:
raw = self.index_to_soup(url, raw=True)
# For html5lib
import html5lib
root = html5lib.parse(raw, namespaceHTMLElements=False, treebuilder='lxml')
# For the lxml html 4 parser
from lxml import html
root = html.fromstring(raw)
Останньою новою можливістю є метод calibre.web.feeds.news.BasicNewsRecipe.preprocess_html(). Цим методом можна скористатися для виконання довільних перетворень на кожною отриманою сторінкою HTML. Тут його використано для того, щоб обійти рекламні повідомлення, які nytimes показує перед кожною статтею.
Підказки щодо створення нових рецептів¶
Найкращим інструментом під час розробки нових рецептів є інтерфейс командного рядка. Ви можете створити рецепт за допомогою вашого улюбленого редактора коду мовою Python і зберегти його до файла, скажімо myrecipe.recipe. Суфіксом назви файла має бути обов’язково .recipe. Далі, ви можете отримати дані за допомогою цього рецепта, скориставшись такою командою:
ebook-convert myrecipe.recipe .epub --test -vv --debug-pipeline debug
Команда ebook-convert отримає усі сторінки сайта і збереже їх до файла EPUB myrecipe.epub. Параметр -vv наказує ebook-convert вивести багато даних щодо того, які дії виконуються. Параметр ebook-convert-recipe-input --test наказує програмі отримати лише пару статей із не більше двох подач. Крім того, ebook-convert розташує отриманий файл HTML у теці debug/input, де debug є текою, який вказано у аргументі параметра ebook-convert --debug-pipeline.
Щойно отримання даних буде завершено, ви зможете переглянути отриманий HTML, відкривши файл debug/input/index.html у програмі для перегляду сторінок інтернету. Коли вас задовольнять результати отримання і попередньої обробки, ви можете створити електронні книги у різних форматах ось так:
ebook-convert myrecipe.recipe myrecipe.epub
ebook-convert myrecipe.recipe myrecipe.mobi
...
Якщо робота рецепта задовольняє ваші потреби і вам здається, що рецепт варто включити до набору вбудованих рецептів, розмістіть ваш рецепт на форумі рецептів calibre, щоб його роботу могли обговорити інші користувачі calibre.
Примітка
У macOS засоби керування за допомогою командного рядка є частиною пакунка calibre. Наприклад, якщо calibre встановлено до /Applications, засоби керування за допомогою командного рядка зберігатимуться у каталозі /Applications/calibre.app/Contents/MacOS/.
Дивись також
- ebook-convert
Інтерфейс командного рядка для перетворення усіх книг.
Додаткові матеріали¶
Щоб дізнатися більше про написання складних рецептів з використанням можливостей, доступ до яких надає BasicNewsRecipe, вам слід ознайомитися з такими джерелами:
- Документація з програмного інтерфейсу
Документація з класу «BasicNewsRecipe» та усіх його важливих методів та полів.
- BasicNewsRecipe
Початковий код «BasicNewsRecipe`»
- Вбудовані рецепти
Початковий код вбудованих рецептів, які постачаються разом із calibre
- Форум рецептів calibre
Там ви зможете обговорити різні питання із багатьма досвідченими творцями рецептів для calibre.
Документація з програмного інтерфейсу¶
- Документація з програмного інтерфейсу для роботи з рецептами
BasicNewsRecipeBasicNewsRecipe.adeify_images()BasicNewsRecipe.image_url_processor()BasicNewsRecipe.print_version()BasicNewsRecipe.tag_to_string()BasicNewsRecipe.abort_article()BasicNewsRecipe.abort_recipe_processing()BasicNewsRecipe.add_toc_thumbnail()BasicNewsRecipe.canonicalize_internal_url()BasicNewsRecipe.cleanup()BasicNewsRecipe.clone_browser()BasicNewsRecipe.default_cover()BasicNewsRecipe.download()BasicNewsRecipe.extract_readable_article()BasicNewsRecipe.get_article_url()BasicNewsRecipe.get_browser()BasicNewsRecipe.get_cover_url()BasicNewsRecipe.get_extra_css()BasicNewsRecipe.get_feeds()BasicNewsRecipe.get_masthead_title()BasicNewsRecipe.get_masthead_url()BasicNewsRecipe.get_obfuscated_article()BasicNewsRecipe.get_url_specific_delay()BasicNewsRecipe.index_to_soup()BasicNewsRecipe.is_link_wanted()BasicNewsRecipe.parse_feeds()BasicNewsRecipe.parse_index()BasicNewsRecipe.populate_article_metadata()BasicNewsRecipe.postprocess_book()BasicNewsRecipe.postprocess_html()BasicNewsRecipe.preprocess_html()BasicNewsRecipe.preprocess_image()BasicNewsRecipe.preprocess_raw_html()BasicNewsRecipe.publication_date()BasicNewsRecipe.skip_ad_pages()BasicNewsRecipe.sort_index_by()BasicNewsRecipe.articles_are_obfuscatedBasicNewsRecipe.auto_cleanupBasicNewsRecipe.auto_cleanup_keepBasicNewsRecipe.browser_typeBasicNewsRecipe.center_navbarBasicNewsRecipe.compress_news_imagesBasicNewsRecipe.compress_news_images_auto_sizeBasicNewsRecipe.compress_news_images_max_sizeBasicNewsRecipe.conversion_optionsBasicNewsRecipe.cover_marginsBasicNewsRecipe.delayBasicNewsRecipe.descriptionBasicNewsRecipe.encodingBasicNewsRecipe.extra_cssBasicNewsRecipe.feedsBasicNewsRecipe.filter_regexpsBasicNewsRecipe.handle_gzipBasicNewsRecipe.ignore_duplicate_articlesBasicNewsRecipe.keep_only_tagsBasicNewsRecipe.languageBasicNewsRecipe.masthead_urlBasicNewsRecipe.match_regexpsBasicNewsRecipe.max_articles_per_feedBasicNewsRecipe.needs_subscriptionBasicNewsRecipe.no_stylesheetsBasicNewsRecipe.oldest_articleBasicNewsRecipe.preprocess_regexpsBasicNewsRecipe.publication_typeBasicNewsRecipe.recipe_disabledBasicNewsRecipe.recipe_specific_optionsBasicNewsRecipe.recursionsBasicNewsRecipe.remove_attributesBasicNewsRecipe.remove_empty_feedsBasicNewsRecipe.remove_javascriptBasicNewsRecipe.remove_tagsBasicNewsRecipe.remove_tags_afterBasicNewsRecipe.remove_tags_beforeBasicNewsRecipe.requires_versionBasicNewsRecipe.resolve_internal_linksBasicNewsRecipe.reverse_article_orderBasicNewsRecipe.scale_news_imagesBasicNewsRecipe.scale_news_images_to_deviceBasicNewsRecipe.simultaneous_downloadsBasicNewsRecipe.summary_lengthBasicNewsRecipe.template_cssBasicNewsRecipe.timefmtBasicNewsRecipe.timeoutBasicNewsRecipe.titleBasicNewsRecipe.use_embedded_content