 Taal veranderen
Taal veranderenUw favoriete nieuws website toevoegen¶
calibre heeft een krachtig, flexibel en gemakkelijk te gebruiken kader voor downloaden van nieuws van internet en converteren naar een e-boek. Het volgende toont u aan de hand van voorbeelden, hoe u nieuws van verschillende websites kunt krijgen.
Om een goed begrip te krijgen van het gebruik van het raamwerk, volgt u de voorbeelden in de onderstaande volgorde:
Compleet automatisch ophalen¶
Als uw nieuwsbron eenvoudig genoeg is, kan Calibre deze mogelijk volledig automatisch ophalen, het enige wat u hoeft te doen is de URL opgeven. Calibre verzamelt alle informatie die nodig is om een nieuwsbron te downloaden naar een :term :recept. Om Calibre over een nieuwsbron te vertellen, moet je een :term :recept ervoor maken. Laten we enkele voorbeelden bekijken:
De Calibre blog¶
De calibre blog is een blog met posts die veel nuttige calibre kenmerken beschrijven op een simpele en toegankelijke manier voor nieuwe calibre gebruikers. Om deze blog te downloaden als e-boek, vertrouwen we op de RSS feed of the blog:
http://blog.calibre-ebook.com/feeds/posts/default
Ik vond de RSS URL door te zoeken in “Abonneren op” onderaan de blogpagina en kiezen voor Posts → Atom. Om calibre de feeds te laten downloaden en converteren naar een e-boek, moet u rechtsklikken op de Nieuws ophalen knop en dan het Aangepaste nieuwsbron toevoegen menu item en dan de Nieuw Recept knop. Een dialoog zoals onder getoond verschijnt.
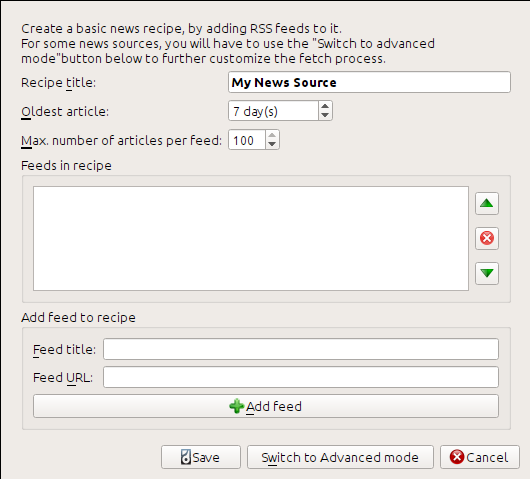
Voer eerst Calibre Blog in in het Recept titel veld. Dit zal de titel van het e-boek zijn dat wordt gecreëerd van het artikel in de feeds boven.
De volgende twee velden (Oudste artikel en Max. aantal artikelen) geven u enige controle over hoeveel artikelen moeten gedownload worden van elke feed, en ze zijn zo klaar als een klontje.
Om de feeds aan het recept toe te voegen, voer de feedtitel en de feed URL in en klik op de Feed toevoegen knop. Als u de feed hebt toegevoegd, klik gewoon op de Opslaan knop en u bent klaar! Sluit de dialoog.
Om uw nieuw recept te testen, klik op de Nieuws ophalen knop en in hat Aangepaste nieuwsbronnen sub-menu klik op calibre Blog. Na een paar minuten verschijnt het nieuw gedownloade e-boek met blogposts in de hoofdbibliotheekweergave (als uw reader aangesloten is, wordt het op de reader gezet i.p.v. in de bibliotheek). Selecteer het en raak de Tonen knop om te lezen!
De reden dat dit zo goed werkt en met zo weinig inspanning is dat de blog volledige inhoud RSS feeds voorziet, m.a.w. de artikel inhoud is ingebed in de feed zelf. Voor de meeste bronnen die nieuws voorzien op deze wijze, met volledige inhoud feeds, moet u niet meer inspanning doen om ze te converteren naar e-boeken. Nu een kijkje naar een nieuwsbron die geen volledige inhoud feeds levert. In zo’n feeds is het volledige artikel een webpagina en bevat de feed enkel een link met een korte samenvatting.
bbc.co.uk¶
Laten we de volgende twee feeds van De BBC proberen:
Nieuws Front Pagina: https://newsrss.bbc.co.uk/rss/newsonline_world_edition/front_page/rss.xml
Wetenschap/Natuur: https://newsrss.bbc.co.uk/rss/newsonline_world_edition/science/nature/rss.xml
Volg de procedure beschreven in De Calibre blog boven om een recept te creëren voor The BBC (met de feeds boven). Kijkend naar het gedownloade e-boek zien we dat calibre een lovenswaardige inspanning heeft gedaan om enkel de inhoud waar u om geeft te halen uit elk artikel z’n webpagina. Het proces is echter niet perfect. Soms is er nog ongewenste inhoud zoals menu’s en navigatie hulpjes of het verwijderde inhoud waar het had moeten afblijven, zoals artikelkoppen. Voor het perfecte proces zullen we het moeten aanpassen zoals beschreven in het volgende onderdeel.
Het ophaalproces aanpassen¶
Als u het downloadproces wil perfectioneren of inhoud downloaden van een zeer complexe webstek, kan u gebruik maken van al de kracht en soepelheid van het recept raamwerk. Om dat te doen, klik in de Aangepaste nieuwsbronnen dialoog gewoon op de Schakel over naar Geavanceerde modus knop.
De gemakkelijkste en dikwijls productiefste aanpassing is de afdrukversie van de online artikelen gebruiken. De afdrukversie bevat gewoonlijk veel minder rommel en vertaalt veel vlotter naar een e-boek. Laten we de afdrukversie van de artikelen van De BBC proberen.
Gebruik van de print versie van bbc.co.uk¶
De eerste stap is kijken naar het e-boek dat we downloadden van bbc.co.uk. Aan het einde van elk artikel in het e-boek is een kleine blurb die toont waar het artikel werd gedownload. Kopieer en plak die URL in een browser. Zoek op de webpagina van het artikel voor een link die wijst naar de “Afdrukversie”. Klik erop om de afdrukversie van het artikel te zien. Ziet er veel strakker uit! Vergelijk nu de twee URL’s. Bij mij waren het:
Het lijkt erop dat om de afdrukversie te krijgen, we elke artikel URL moeten laten voorafgaan door:
newsvote.bbc.co.uk/mpapps/pagetools/print/
In de Geavanceerde modus van de Aangepaste nieuwsbronnendialoog zou u iets moeten zien zoals (denk eraan om het The BBC recept te selecteren voor naar geavanceerde modus over te schakelen):
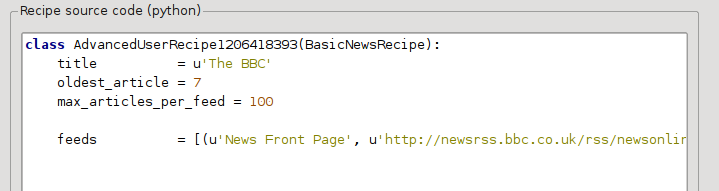
U ziet dat de velden van de Basis modus op een rechttoe rechtaan manier zijn vertaald naar Python code. We moeten instructies toevoegen aan dit recept om de afdrukversie van het artikel te gebruiken. Al wat nodig is, is toevoegen van volgende twee regels:
def print_version(self, url):
return url.replace('https://', 'https://newsvote.bbc.co.uk/mpapps/pagetools/print/')
Dit is Python, dus inspringing is belangrijk. Na toevoegen van de lijnen zou het er moeten uitzien als:
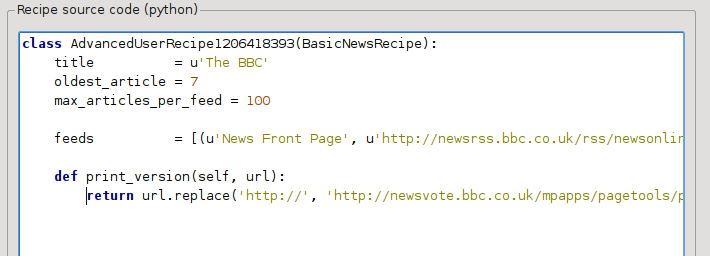
Boven definieert def print_version(self, url) een methode die door calibre wordt aangeroepen voor elk artikel. url is de URL van het originele artikel. Wat print_version doet, is die url nemen en vervangen door de nieuwe URL die wijst naar de afdrukversie van het artikel. Om te leren over Python see the tutorial.
Klik nu op de Toevoegen/updaten recept knop en uw wijzigingen worden opgeslagen. Download het e-boek opnieuw. U zou nu een veel betere versie moeten hebben. Een van de problemen met de nieuwe versie is dat de lettertypes op de webpagina van de afdrukversie te klein zijn. Dit wordt ge-auto-fixxed bij converteren naar een e-boek maar zelfs daarna is de lettertypegrootte van menu’s en navigatiebalk te groot vergeleken met de artikeltekst. Om dit te in orde te brengen, doen we nog wat aanpassingen in het volgende onderdeel.
Artikel stijlen vervangen¶
In de vorige sectie zagen we dat de lettertypegrootte voor artikelen van de afdrukversie van The BBC te klein was. Op de meeste webstekken, The BBC inbegrepen, is deze lettertypegrootte ingesteld door de CSS stijlbladen. We kunnen dit ophalen uitschakelen door toevoegen van de regel:
no_stylesheets = True
Het recept ziet er als volgt uit:
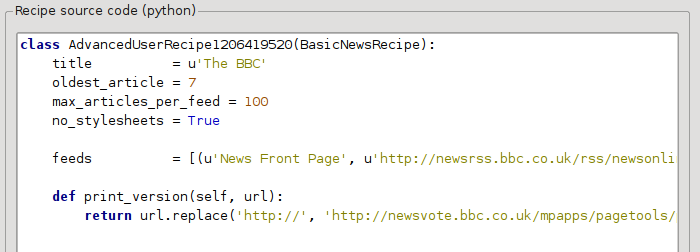
De nieuwe versie ziet er goed uit. Als u een perfectionist bent, dan zult u het volgende gedeelte willen lezen, deze gaat over het aanpassen van de gedownloade content.
Splitsen en verdelen¶
calibre bevat zeer krachtige en flexibele mogelijkheden om gedownloadede inhoud te manipuleren. Om enkele hiervan te tonen, laten we nogmaals een kijkje nemen bij onze oude vriend het The BBC recept. Bij kijken naar de broncode (HTML) van een paar artikelen (afdrukversie), zien we dat ze een voettekst hebben zonder bruikbare informatie, gevat in
<div class="footer">
...
</div>
Dit kan worden verwijderd door toevoeging van:
remove_tags = [dict(name='div', attrs={'class':'footer'})]
to the recipe. Finally, let’s replace some of the CSS that we disabled earlier, with our own CSS that is suitable for conversion to an e-book:
extra_css = '.headline {font-size: x-large;} \n .fact { padding-top: 10pt }'
Met deze toevoegingen is ons recept “productiekwaliteit” geworden.
Deze recept verkent enkel het tipje van de ijsberg als het over de kracht van calibre gaat. Om meer mogelijkheden van calibre te ontdekken, onderzoeken we een ingewikkelder voorbeeld uit het echte leven in de volgende sectie.
Werkend voorbeeld¶
Een redelijk complex real life voorbeeld dat meer van de API van BasicNewsRecipe toont is het recept voor The New York Times
import string, re
from calibre import strftime
from calibre.web.feeds.recipes import BasicNewsRecipe
from calibre.ebooks.BeautifulSoup import BeautifulSoup
class NYTimes(BasicNewsRecipe):
title = 'The New York Times'
__author__ = 'Kovid Goyal'
description = 'Daily news from the New York Times'
timefmt = ' [%a, %d %b, %Y]'
needs_subscription = True
remove_tags_before = dict(id='article')
remove_tags_after = dict(id='article')
remove_tags = [dict(attrs={'class':['articleTools', 'post-tools', 'side_tool', 'nextArticleLink clearfix']}),
dict(id=['footer', 'toolsRight', 'articleInline', 'navigation', 'archive', 'side_search', 'blog_sidebar', 'side_tool', 'side_index']),
dict(name=['script', 'noscript', 'style'])]
encoding = 'cp1252'
no_stylesheets = True
extra_css = 'h1 {font: sans-serif large;}\n.byline {font:monospace;}'
def get_browser(self):
br = BasicNewsRecipe.get_browser(self)
if self.username is not None and self.password is not None:
br.open('https://www.nytimes.com/auth/login')
br.select_form(name='login')
br['USERID'] = self.username
br['PASSWORD'] = self.password
br.submit()
return br
def parse_index(self):
soup = self.index_to_soup('https://www.nytimes.com/pages/todayspaper/index.html')
def feed_title(div):
return ''.join(div.findAll(text=True, recursive=False)).strip()
articles = {}
key = None
ans = []
for div in soup.findAll(True,
attrs={'class':['section-headline', 'story', 'story headline']}):
if ''.join(div['class']) == 'section-headline':
key = string.capwords(feed_title(div))
articles[key] = []
ans.append(key)
elif ''.join(div['class']) in ['story', 'story headline']:
a = div.find('a', href=True)
if not a:
continue
url = re.sub(r'\?.*', '', a['href'])
url += '?pagewanted=all'
title = self.tag_to_string(a, use_alt=True).strip()
description = ''
pubdate = strftime('%a, %d %b')
summary = div.find(True, attrs={'class':'summary'})
if summary:
description = self.tag_to_string(summary, use_alt=False)
feed = key if key is not None else 'Uncategorized'
if feed not in articles:
articles[feed] = []
if not 'podcasts' in url:
articles[feed].append(
dict(title=title, url=url, date=pubdate,
description=description,
content=''))
ans = self.sort_index_by(ans, {'The Front Page':-1, 'Dining In, Dining Out':1, 'Obituaries':2})
ans = [(key, articles[key]) for key in ans if key in articles]
return ans
def preprocess_html(self, soup):
refresh = soup.find('meta', {'http-equiv':'refresh'})
if refresh is None:
return soup
content = refresh.get('content').partition('=')[2]
raw = self.browser.open('https://www.nytimes.com'+content).read()
return BeautifulSoup(raw.decode('cp1252', 'replace'))
We zien verscheidene nieuwe kenmerken in dit recept. Om te beginnen:
timefmt = ' [%a, %d %b, %Y]'
Dit stelt de getoonde tijd op de voorpagina van het gecreëerde e-boek in op het formaat, Day, Day_Number Month, Year. Kijk op timefmt.
Dan zien we een groep richtlijnen voor het opschonen van de gedownloade HTML:
remove_tags_before = dict(name='h1')
remove_tags_after = dict(id='footer')
remove_tags = ...
Deze verwijderen alles voor de eerste <h1> tag en alle na de eerste tag wiens id is footer. Bekijk remove_tags, remove_tags_before, remove_tags_after.
De volgende interessante functie is:
needs_subscription = True
...
def get_browser(self):
...
needs_subscription = True zegt calibre dat dit recept een gebruikersnaam en wachtwoord nodig heeft voor content toegang. Dit laat calibre vragen naar een gebruikersnaam en wachtwoord telkens u dit recept probeert te gebruiken. De code in calibre.web.feeds.news.BasicNewsRecipe.get_browser() doet het inloggen op de NYT website. Eens ingelogd zal calibre dezelfde ingelogde browser instance gebruiken om alle inhoud op te halen. Bekijk mechanize om de code in get_browser te begrijpen.
The next new feature is the
calibre.web.feeds.news.BasicNewsRecipe.parse_index() method. Its job is
to go to https://www.nytimes.com/pages/todayspaper/index.html and fetch the list
of articles that appear in today’s paper. While more complex than simply using
RSS, the recipe creates an e-book that corresponds very closely to the
day’s paper. parse_index makes heavy use of BeautifulSoup to parse
the daily paper webpage. You can also use other, more modern parsers if you
dislike BeautifulSoup. calibre comes with lxml and
html5lib, which are the
recommended parsers. To use them, replace the call to index_to_soup() with
the following:
raw = self.index_to_soup(url, raw=True)
# For html5lib
import html5lib
root = html5lib.parse(raw, namespaceHTMLElements=False, treebuilder='lxml')
# For the lxml html 4 parser
from lxml import html
root = html.fromstring(raw)
Het laatste, nieuwe kenmerk is de calibre.web.feeds.news.BasicNewsRecipe.preprocess_html() methode. Ze kan gebruikt worden voor willekeurige transformaties op elke gedownloade HTML pagina. Hier wordt ze gebruikt om de advertenties die de nytimes toont voor elk artikel te omzeilen.
Tips voor ontwikkelen van nieuwe recepten¶
De beste manier om nieuwe recepten te ontwikkelen is met de opdrachtregel. Creëer het recept in uw favoriete Python editor en sla het op in een bestand, bv. myrecipe.recipe. De .recipe extensie is vereist. U kan inhoud downloaden met dit recept met het commando:
ebook-convert myrecipe.recipe .epub --test -vv --debug-pipeline debug
Het commando e-boek-converteren downloadt alle webpagina’s en slaat ze op in het EPUB bestand mijnrecept.epub. De -vv optie laat e-boek-converteren een hoop informatie uitspuwen over wat het doet. De e-boek-converteren-recept-invoer --test optie laat het juist een paar artikels downloaden van maximaal twee feeds. Bijkomend plaatst e-boek-converteren de gedownloade HTML in de debug/input map, waar debug de map is die u specificeerde in de e-boek-converteren --debug-pipeline optie.
Als de download compleet is, kan u de gedownloade HTML bekijken door het bestand debug/input/index.html in een browser te openen. Als u tevreden bent dat de download en voorbewerking correct gebeurt, kan e-boeken genereren in verschillende formaten zoals onder getoond:
ebook-convert myrecipe.recipe myrecipe.epub
ebook-convert myrecipe.recipe myrecipe.mobi
...
Als tevreden bent met uw recept en u vindt dat er genoeg vraag is om het in te voegen in de set met ingebouwde recepten, post dan uw recept in het calibre recipes forum om het te delen met andere gebruikers.
Notitie
Op macOS bevinden de commandoregelprogramma’s zich in de calibre-bundel, bijvoorbeeld, als u calibre hebt geïnstalleerd in /Applications bevinden de commandoregelprogramma’s zich in /Applications/calibre.app/Contents/MacOS/.
Zie ook
- ebook-convert
De opdrachtregelinterface voor alle e-boekconversies.
Verder lezen¶
Om meer te leren over schrijven van geavanceerde recepten met enkele van de mogelijkheden beschikbaar in BasicNewsRecipe moet u volgende bronnen raadplegen:
- API documentation
Documentatie over de
BasicNewsRecipeclass en al zijn belangrijke methodes en velden.- BasicNewsRecipe
De broncode van
BasicNewsRecipe- Ingebouwde recepten
De broncode voor de ingebouwde recepten die bij Calibre horen
- Het calibre recepten forum
Massa’s ervaren calibre recept schrijven hier.
API documentatie¶
- API documentatie voor recepten
BasicNewsRecipeBasicNewsRecipe.adeify_images()BasicNewsRecipe.image_url_processor()BasicNewsRecipe.print_version()BasicNewsRecipe.tag_to_string()BasicNewsRecipe.abort_article()BasicNewsRecipe.abort_recipe_processing()BasicNewsRecipe.add_toc_thumbnail()BasicNewsRecipe.canonicalize_internal_url()BasicNewsRecipe.cleanup()BasicNewsRecipe.clone_browser()BasicNewsRecipe.default_cover()BasicNewsRecipe.download()BasicNewsRecipe.extract_readable_article()BasicNewsRecipe.get_article_url()BasicNewsRecipe.get_browser()BasicNewsRecipe.get_cover_url()BasicNewsRecipe.get_extra_css()BasicNewsRecipe.get_feeds()BasicNewsRecipe.get_masthead_title()BasicNewsRecipe.get_masthead_url()BasicNewsRecipe.get_obfuscated_article()BasicNewsRecipe.get_url_specific_delay()BasicNewsRecipe.index_to_soup()BasicNewsRecipe.is_link_wanted()BasicNewsRecipe.parse_feeds()BasicNewsRecipe.parse_index()BasicNewsRecipe.populate_article_metadata()BasicNewsRecipe.postprocess_book()BasicNewsRecipe.postprocess_html()BasicNewsRecipe.preprocess_html()BasicNewsRecipe.preprocess_image()BasicNewsRecipe.preprocess_raw_html()BasicNewsRecipe.publication_date()BasicNewsRecipe.skip_ad_pages()BasicNewsRecipe.sort_index_by()BasicNewsRecipe.articles_are_obfuscatedBasicNewsRecipe.auto_cleanupBasicNewsRecipe.auto_cleanup_keepBasicNewsRecipe.browser_typeBasicNewsRecipe.center_navbarBasicNewsRecipe.compress_news_imagesBasicNewsRecipe.compress_news_images_auto_sizeBasicNewsRecipe.compress_news_images_max_sizeBasicNewsRecipe.conversion_optionsBasicNewsRecipe.cover_marginsBasicNewsRecipe.delayBasicNewsRecipe.descriptionBasicNewsRecipe.encodingBasicNewsRecipe.extra_cssBasicNewsRecipe.feedsBasicNewsRecipe.filter_regexpsBasicNewsRecipe.handle_gzipBasicNewsRecipe.ignore_duplicate_articlesBasicNewsRecipe.keep_only_tagsBasicNewsRecipe.languageBasicNewsRecipe.masthead_urlBasicNewsRecipe.match_regexpsBasicNewsRecipe.max_articles_per_feedBasicNewsRecipe.needs_subscriptionBasicNewsRecipe.no_stylesheetsBasicNewsRecipe.oldest_articleBasicNewsRecipe.preprocess_regexpsBasicNewsRecipe.publication_typeBasicNewsRecipe.recipe_disabledBasicNewsRecipe.recipe_specific_optionsBasicNewsRecipe.recursionsBasicNewsRecipe.remove_attributesBasicNewsRecipe.remove_empty_feedsBasicNewsRecipe.remove_javascriptBasicNewsRecipe.remove_tagsBasicNewsRecipe.remove_tags_afterBasicNewsRecipe.remove_tags_beforeBasicNewsRecipe.requires_versionBasicNewsRecipe.resolve_internal_linksBasicNewsRecipe.reverse_article_orderBasicNewsRecipe.scale_news_imagesBasicNewsRecipe.scale_news_images_to_deviceBasicNewsRecipe.simultaneous_downloadsBasicNewsRecipe.summary_lengthBasicNewsRecipe.template_cssBasicNewsRecipe.timefmtBasicNewsRecipe.timeoutBasicNewsRecipe.titleBasicNewsRecipe.use_embedded_content