 Changer la langue
Changer la langueAjouter votre site web favori d’actualités¶
calibre contient une structure de création puissante, flexible et facile à utiliser pour télécharger des actualités sur Internet et les convertir en livre numérique. Ce qui suit vous montrera, au moyen d’exemples, comment obtenir les actualités de divers sites web.
Pour avoir une compréhension de la façon d’employer cette structure de création, suivez les exemples ci-dessous dans l’ordre :
Récupération entièrement automatique¶
Si votre source d’actualité est assez simple, calibre est capable d’en effectuer la récupération de manière complètement automatique. Tout ce que vous avez à faire est de fournir l’URL. calibre recueille toutes les informations nécessaires pour télécharger une source d’actualités dans une recette. Pour intégrer à calibre une nouvelle source d’actualité, vous devez créer une recette pour celle-ci. Voyons quelques exemples :
Le blog calibre¶
Le blog calibre est un blog de postes qui décrivent beaucoup de fonctionnalités utiles de calibre d’une manière simple et accessible pour les nouveaux utilisateurs de calibre. Pour pouvoir télécharger ce blog dans un livre numérique, nous nous référons au flux RSS du blog:
http://blog.calibre-ebook.com/feeds/posts/default
J’ai obtenu l’URL RSS en regardant sous « Subscribe to » en bas de la page du blog et en choisissant Posts → Atom. Pour faire en sorte que calibre télécharge les flux et les convertissent en livre numérique, vous devrez faire une clic droit sur le bouton Récupérer des actualités et puis le bouton Ajouter une source personnalisée d’informations. Une boite de dialogue semblable à celle montrée ci-dessous devrait s’ouvrir.
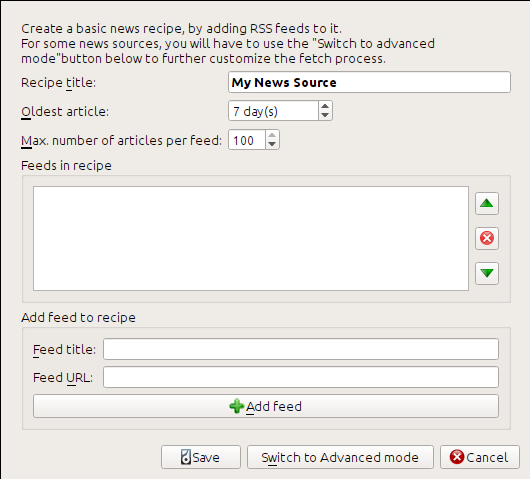
Tout d’abord entrez Blog calibre dans le champ Titre de la recette. Ceci sera le titre du livre numérique qui sera créé à partir des articles des flux ci-dessus.
Les deux champs suivants (Article le plus ancien et Max. Nombre d’articles par flux) donnent la possibilité de contrôler combien d’articles pourront être téléchargés de chaque flux. Ils sont assez explicites.
Pour ajouter les flux à la recette, entrer le titre du flux et l’URL du flux et cliquez sur le bouton Ajouter un flux. Une fois que vous avez ajouté le flux, cliquez simplement sur le bouton Sauvegarder et vous avez fini ! Fermez la boîte de dialogue.
Pour tester votre nouvelle recette, cliquez le bouton Récupérer des informations et dans le sous menu Personnaliser les sources d’actualités cliquez guilabel:Blog calibre. Après quelques minutes, le nouveau livre numérique de postes de blog apparaîtra dans la vue de la bibliothèque principale (si votre lecteur est connecté, il sera déposé sur le lecteur plutôt que dans la bibliothèque). Sélectionnez-le et appuyer le bouton Visualiser pour le lire !
La raison pour laquelle cela fonctionne si bien, avec si peu d’efforts, est parce que le blog fournit un flux RSS à contenu plein, c’est à dire, dont le contenu de l’article est inclut dans le flux lui-même. Pour la plupart des sites d’actualités qui fournissent des actualités de cette façon, avec des flux à contenu plein, vous n’avez pas besoin de faire beaucoup plus d’efforts pour les convertir en livres numériques. Maintenant nous allons regarder à des sources d’actualités qui ne fournissent pas des flux à contenu plein. Dans de tels flux, L’article complet est une page web et le flux contient uniquement un lien vers la page web avec un petit résumé de l’article.
bbc.co.uk¶
Essayons les deux flux suivants de The BBC :
Suivez la procédure comme exposée dans Le blog calibre pour créer une recette pour The BBC (en utilisant les flux ci-dessus). Regardez le livre numérique téléchargé,nous voyons que calibre a réalisé un travail honorable d’extraire seulement le contenu qui vous intéresse depuis la page web de chaque article. Cependant, le processus d’extraction n’est pas parfait. Parfois il laisse du contenu indésirable comme des menus et des aides à la navigation ou enlève du contenu qui aurait dû apparaître seul, comme des titres d’article. Pour obtenir une extraction parfaite, nous aurons besoin d’adapter le processus de récupération, tel que décrit dans la section suivante.
Personnaliser le processus de récupération¶
Quand vous voulez perfectionner le processus de téléchargement, ou télécharger du contenu d’un site web particulièrement complexe, vous pouvez vous servir de toutes la puissance et de la flexibilité de la structure recette. Afin de faire cela, dans la boîte de dialogue Ajouter des sources d’actualités personnalisées, cliquez simplement sur le bouton Basculer vers le mode Avancé.
La personnalisation la plus facile et souvent la plus productive est d’employer la version imprimable des articles en ligne. La version imprimable est habituellement moins compliqué et se traduit beaucoup plus souplement en un livre numérique. Essayons d’employer la version imprimable des articles de The BBC.
Utilisation de la version imprimable de bbc.co.uk¶
La première étape est de regarder le livre numérique que nous avons précédemment téléchargé depuis bbc.co.uk. A la fin de chaque article, dans le livre numérique il y a un petit texte de présentation vous indiquant d’où l’article a été téléchargé. Copier et coller cette URL dans un navigateur. Maintenant sur la page Web de l’article recherchez un lien qui pointe vers la « version imprimable ». Cliquez le pour voir la version imprimable de l’article. Il parait beaucoup plus ordonné ! Comparez maintenant les deux URLs. Pour moi elles étaient :
- URL d’article
- URL de version imprimable
https://newsvote.bbc.co.uk/mpapps/pagetools/print/news.bbc.co.uk/2/hi/science/nature/7312016.stm
Aussi il semble que pour obtenir la version imprimable, nous avons besoin de préfixer que URL d’article avec :
newsvote.bbc.co.uk/mpapps/pagetools/print/
Dorénavant dans le Mode Avancé de la boîte de dialogue Personnaliser les sources d’actualités, vous devriez voir quelque chose comme (rappeler vous de sélectionner la recette The BBC avant de basculer vers le mode avancé) :
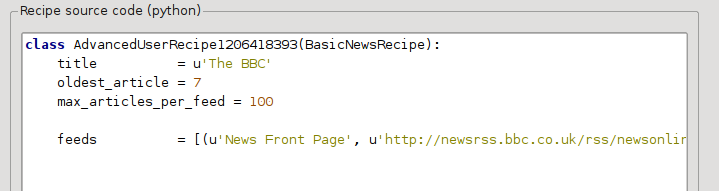
Vous pouvez voir que les champs du Mode de base ont été traduits en code de Python d’une façon simple. Nous devons ajouter des instructions à cette recette pour employer la version imprimable des articles. Tout ce qui est nécessaire est d’ajouter les deux lignes suivantes :
def print_version(self, url):
return url.replace('https://', 'https://newsvote.bbc.co.uk/mpapps/pagetools/print/')
C’est du Python, donc l’indentation est importante. Après que vous ayez ajouté les lignes, elles devraient ressembler à :
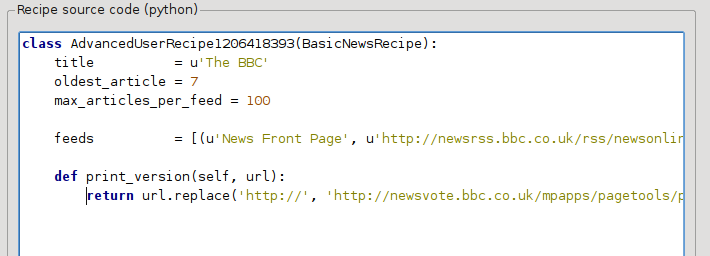
Ci-dessus, def print_version(self, url) définit une méthode qui est appelée par calibre pour chaque article. url est l’URL de l’article original. Ce que print_version fait est de prendre cette url et de la remplacer avec l’URL qui pointe vers la version imprimable de l’article. Pour apprendre à propos de Python voir le tutoriel.
Maintenant, cliquez sur le bouton Ajouter/Mettre à jour la recette et vos changements seront enregistrés. Téléchargez à nouveau le livre numérique. Vous devriez obtenir un livre numérique beaucoup plus amélioré. Un des problèmes avec la nouvelle version est que les polices sur la page Web de la version imprimable sont trop petites. Ceci est automatiquement fixé en convertissant en livre numérique, mais même après le processus de fixation, la taille de la police des menus et la barre de navigation peuvent être trop grandes relativement au texte de l’article. Pour fixer ceci, nous ferons encore plus de personnalisation dans la prochaine section.
Remplacer les styles d’article¶
Dans la section précédente, nous avons vu que la taille de la police pour des articles de la version imprimable de The BBC était trop petite. Dans la plupart des sites Web, le The BBC inclus, cette taille de la police est placée au moyen de feuilles de style CSS. Nous pouvons désactiver la récupération de telles feuilles de style n ajoutant la ligne:
no_stylesheets = True
La recette ressemble maintenant à :
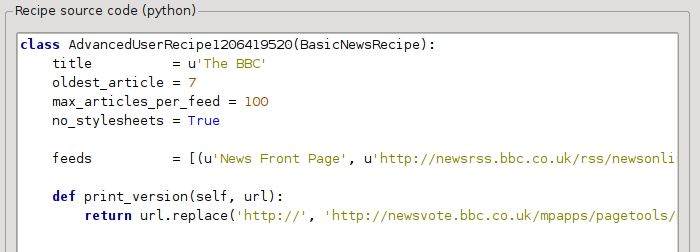
La nouvelle version parait assez bonne. Si vous êtes un perfectionniste, vous voudrez lire la prochaine section, qui traite de modifier réellement le contenu téléchargé.
Découper et émincer¶
calibre a des capacités très puissantes et flexibles quand il s’agit de manipuler le contenu téléchargé. Pour montrer quelques uns de ces derniers, regardons encore notre vieille amie la recette The BBC. Regardez le code source (HTML) de quelques articles (version imprimable), nous voyons qu’il contient un pied de page qui n’apporte aucune information utile
<div class="footer">
...
</div>
Ceci peut être supprimé en ajoutant:
remove_tags = [dict(name='div', attrs={'class':'footer'})]
à la recette. Finalement, remplaçons certains des CSS que nous avons désactivés plus tôt, avec notre propre CSS qui est plus adapté pour la conversion en livre numérique :
extra_css = '.headline {font-size: x-large;} \n .fact { padding-top: 10pt }'
Avec ces ajouts, notre recette est devenue « qualité de production ».
Cette recette explore seulement la partie émergée de l’iceberg quand il s’agit de la puissance de calibre. Pour mieux explorer les capacités de calibre nous examinerons un exemple plus complexe de vie réelle dans la prochaine section.
Exemple de la vie réelle¶
Un exemple de la vie réelle raisonnablement complexe qui expose plus de l”API de BasicNewsRecipe est la recette pour The New York Times
import string, re
from calibre import strftime
from calibre.web.feeds.recipes import BasicNewsRecipe
from calibre.ebooks.BeautifulSoup import BeautifulSoup
class NYTimes(BasicNewsRecipe):
title = 'The New York Times'
__author__ = 'Kovid Goyal'
description = 'Daily news from the New York Times'
timefmt = ' [%a, %d %b, %Y]'
needs_subscription = True
remove_tags_before = dict(id='article')
remove_tags_after = dict(id='article')
remove_tags = [dict(attrs={'class':['articleTools', 'post-tools', 'side_tool', 'nextArticleLink clearfix']}),
dict(id=['footer', 'toolsRight', 'articleInline', 'navigation', 'archive', 'side_search', 'blog_sidebar', 'side_tool', 'side_index']),
dict(name=['script', 'noscript', 'style'])]
encoding = 'cp1252'
no_stylesheets = True
extra_css = 'h1 {font: sans-serif large;}\n.byline {font:monospace;}'
def get_browser(self):
br = BasicNewsRecipe.get_browser(self)
if self.username is not None and self.password is not None:
br.open('https://www.nytimes.com/auth/login')
br.select_form(name='login')
br['USERID'] = self.username
br['PASSWORD'] = self.password
br.submit()
return br
def parse_index(self):
soup = self.index_to_soup('https://www.nytimes.com/pages/todayspaper/index.html')
def feed_title(div):
return ''.join(div.findAll(text=True, recursive=False)).strip()
articles = {}
key = None
ans = []
for div in soup.findAll(True,
attrs={'class':['section-headline', 'story', 'story headline']}):
if ''.join(div['class']) == 'section-headline':
key = string.capwords(feed_title(div))
articles[key] = []
ans.append(key)
elif ''.join(div['class']) in ['story', 'story headline']:
a = div.find('a', href=True)
if not a:
continue
url = re.sub(r'\?.*', '', a['href'])
url += '?pagewanted=all'
title = self.tag_to_string(a, use_alt=True).strip()
description = ''
pubdate = strftime('%a, %d %b')
summary = div.find(True, attrs={'class':'summary'})
if summary:
description = self.tag_to_string(summary, use_alt=False)
feed = key if key is not None else 'Uncategorized'
if feed not in articles:
articles[feed] = []
if not 'podcasts' in url:
articles[feed].append(
dict(title=title, url=url, date=pubdate,
description=description,
content=''))
ans = self.sort_index_by(ans, {'The Front Page':-1, 'Dining In, Dining Out':1, 'Obituaries':2})
ans = [(key, articles[key]) for key in ans if key in articles]
return ans
def preprocess_html(self, soup):
refresh = soup.find('meta', {'http-equiv':'refresh'})
if refresh is None:
return soup
content = refresh.get('content').partition('=')[2]
raw = self.browser.open('https://www.nytimes.com'+content).read()
return BeautifulSoup(raw.decode('cp1252', 'replace'))
Nous voyons plusieurs nouvelles fonctionnalités dans cette recipe. En premier, nous avons:
timefmt = ' [%a, %d %b, %Y]'
Ceci règle le temps affiché sur la page de garde du livre numérique créé au format , Day, Day_Number Month, Year. Voir timefmt.
Voyons maintenant un groupe de directives pour nettoyer l”:term:` HTML` téléchargé:
remove_tags_before = dict(name='h1')
remove_tags_after = dict(id='footer')
remove_tags = ...
Celle-ci supprime tout avant la première balise <h1> et tout ce qui se trouve après le première balise dont l’id est footer. Voir remove_tags, remove_tags_before, remove_tags_after.
La prochaine fonctionnalité intéressante est:
needs_subscription = True
...
def get_browser(self):
...
needs_subscription = True dit à calibre que cette recette nécessite un nom d’utilisateur et un mot de passe pour accéder au contenu. Ceci amène calibre à demander après un nom d’utilisateur et un mot de passe à chaque fois que vous essayez d’utiliser cette recette. Le code dans calibre.web.feeds.news.BasicNewsRecipe.get_browser() fait réellement l’ouverture de session sur le site Web de NYT. Une fois connecté, calibre utilisera la même instance, connectée, du navigateur pour récupérer tout le contenu. Voir mechanize pour comprendre le code dans get_browser.
Une autre nouvelle fonctionnalité est la méthode calibre.web.feeds.news.BasicNewsRecipe.parse_index(). Sont travail est d’aller sur https://www.nytimes.com/pages/todayspaper/index.html et de récupérer la liste des articles qui apparaissent dans le journal du jour. Beaucoup plus complexe que d’utiliser simplement le RSS, la recette crée un livre numérique qui correspond pratiquement au journal du jour. parse_index fait une forte utilisation de BeautifulSoup pour examiner la page web quotidienne. Vous pouvez aussi en utiliser d’autres, de plus modernes analyseurs si vous n’aimez pas BeautifulSoup. calibre est fourni avec lxml et html5lib, qui sont les analyseurs recommandés. Pour les utiliser, remplacer l’appel à index_to_soup() avec le suivant :
raw = self.index_to_soup(url, raw=True)
# For html5lib
import html5lib
root = html5lib.parse(raw, namespaceHTMLElements=False, treebuilder='lxml')
# For the lxml html 4 parser
from lxml import html
root = html.fromstring(raw)
La nouvelle fonctionnalité finale est la méthode calibre.web.feeds.news.BasicNewsRecipe.preprocess_html(). Elle peut être employée pour exécuter des transformations quelconques sur chaque page HTML téléchargée. Ici elle est employée pour éviter les publicités que le nytimes place avant chaque article.
Astuces pour développer de nouvelles recettes¶
La meilleure manière de développer de nouvelles recettes est d’utiliser l’interface de commande en ligne. Créer la recette en utilisant votre éditeur Python favori et sauvegardez la dans un fichier nommé myrecipe.recipe. L’extension .recipe est obligatoire. Vous pouvez télécharger le contenu qu’utilise cette recette avec la commande:
ebook-convert myrecipe.recipe .epub --test -vv --debug-pipeline debug
La commande ebook-convert téléchargera toutes les pages web et les enregistrera dans le fichier EPUB myrecipe.epub. L’option -vv fait en sorte que ebook-convert renvoie beaucoup d’informations sur ce qu’il fait. L’option ebook-convert-recipe-input --test fait qu’il ne télécharge que quelques articles d’au maximum deux flux. En outre, ebook-convert déposera l’HTML téléchargé dans le répertoire debug/input, où debug est le répertoire que vous avez spécifié dans l’option ebook-convert --debug-pipeline.
Une fois le téléchargement terminé, vous pouvez regarder l’HTML téléchargé en ouvrant le fichier debug/input/index.html dans un navigateur. Une fois que vous êtes satisfait que le téléchargement et le pré-traitement se sont déroulés correctement, vous pouvez générer des livres numériques dans différents formats comme montré ci-dessous:
ebook-convert myrecipe.recipe myrecipe.epub
ebook-convert myrecipe.recipe myrecipe.mobi
...
Si vous êtes satisfait de votre recette et que vous sentez qu’il y a suffisamment de demandes pour l’inclure dans le jeu de recettes intégrées, déposez votre recette sur le forum calibre de recettes pour la partager avec les autres utilisateurs de calibre.
Note
Sous macOS, les outils en de ligne de commande sont à l’intérieur de la suite logicielle calibre, par exemple, si vous installez calibre dans /Applications les outils de ligne de commande sont dans /Applications/calibre.app/Contents/MacOS/.
Voir aussi
- ebook-convert
L’interface en ligne de commande pour toute conversion de livre numérique
Lectures recommandées¶
Pour en apprendre plus sur l’écriture avancée de recettes utilisant quelques unes des facilités disponibles dans BasicNewsRecipe, vous devriez consulter les sources suivantes :
- Documentation API
Documentation sur la classe
BasicNewsRecipeet toutes ses méthodes importantes et champs.- BasicNewsRecipe
Le code source de
BasicNewsRecipe- Recettes intégrées
Le code source des recettes intégrées qui est fourni avec calibre
- Le forum de recettes calibre
Un bon nombre d’auteurs bien informés des recettes calibre traînent ici.
Documentation de l’API¶
- Documentation API pour les recettes
BasicNewsRecipeBasicNewsRecipe.adeify_images()BasicNewsRecipe.image_url_processor()BasicNewsRecipe.print_version()BasicNewsRecipe.tag_to_string()BasicNewsRecipe.abort_article()BasicNewsRecipe.abort_recipe_processing()BasicNewsRecipe.add_toc_thumbnail()BasicNewsRecipe.canonicalize_internal_url()BasicNewsRecipe.cleanup()BasicNewsRecipe.clone_browser()BasicNewsRecipe.default_cover()BasicNewsRecipe.download()BasicNewsRecipe.extract_readable_article()BasicNewsRecipe.get_article_url()BasicNewsRecipe.get_browser()BasicNewsRecipe.get_cover_url()BasicNewsRecipe.get_extra_css()BasicNewsRecipe.get_feeds()BasicNewsRecipe.get_masthead_title()BasicNewsRecipe.get_masthead_url()BasicNewsRecipe.get_obfuscated_article()BasicNewsRecipe.get_url_specific_delay()BasicNewsRecipe.index_to_soup()BasicNewsRecipe.is_link_wanted()BasicNewsRecipe.parse_feeds()BasicNewsRecipe.parse_index()BasicNewsRecipe.populate_article_metadata()BasicNewsRecipe.postprocess_book()BasicNewsRecipe.postprocess_html()BasicNewsRecipe.preprocess_html()BasicNewsRecipe.preprocess_image()BasicNewsRecipe.preprocess_raw_html()BasicNewsRecipe.publication_date()BasicNewsRecipe.skip_ad_pages()BasicNewsRecipe.sort_index_by()BasicNewsRecipe.articles_are_obfuscatedBasicNewsRecipe.auto_cleanupBasicNewsRecipe.auto_cleanup_keepBasicNewsRecipe.browser_typeBasicNewsRecipe.center_navbarBasicNewsRecipe.compress_news_imagesBasicNewsRecipe.compress_news_images_auto_sizeBasicNewsRecipe.compress_news_images_max_sizeBasicNewsRecipe.conversion_optionsBasicNewsRecipe.cover_marginsBasicNewsRecipe.delayBasicNewsRecipe.descriptionBasicNewsRecipe.encodingBasicNewsRecipe.extra_cssBasicNewsRecipe.feedsBasicNewsRecipe.filter_regexpsBasicNewsRecipe.handle_gzipBasicNewsRecipe.ignore_duplicate_articlesBasicNewsRecipe.keep_only_tagsBasicNewsRecipe.languageBasicNewsRecipe.masthead_urlBasicNewsRecipe.match_regexpsBasicNewsRecipe.max_articles_per_feedBasicNewsRecipe.needs_subscriptionBasicNewsRecipe.no_stylesheetsBasicNewsRecipe.oldest_articleBasicNewsRecipe.preprocess_regexpsBasicNewsRecipe.publication_typeBasicNewsRecipe.recipe_disabledBasicNewsRecipe.recipe_specific_optionsBasicNewsRecipe.recursionsBasicNewsRecipe.remove_attributesBasicNewsRecipe.remove_empty_feedsBasicNewsRecipe.remove_javascriptBasicNewsRecipe.remove_tagsBasicNewsRecipe.remove_tags_afterBasicNewsRecipe.remove_tags_beforeBasicNewsRecipe.requires_versionBasicNewsRecipe.resolve_internal_linksBasicNewsRecipe.reverse_article_orderBasicNewsRecipe.scale_news_imagesBasicNewsRecipe.scale_news_images_to_deviceBasicNewsRecipe.simultaneous_downloadsBasicNewsRecipe.summary_lengthBasicNewsRecipe.template_cssBasicNewsRecipe.timefmtBasicNewsRecipe.timeoutBasicNewsRecipe.titleBasicNewsRecipe.use_embedded_content