 Изменить язык
Изменить языкДобавление любимых новостных веб-сайтов¶
calibre обладает мощной, гибкой и простой в использовании платформой для загрузки новостей из Интернета и преобразования их в электронную книгу. Далее на примерах будет показано, как получать новости с различных веб-сайтов.
Чтобы понять, как использовать платформу, следуйте примерам в порядке, указанном ниже:
Полностью автоматическая загрузка¶
Если ваш источник новостей достаточно прост, calibre вполне может получить его полностью автоматически, все, что вам нужно сделать, это предоставить URL. calibre собирает всю информацию, необходимую для загрузки источника новостей, в recipe. Чтобы сообщить calibre об источнике новостей, вы должны создать для него recipe. Давайте посмотрим несколько примеров:
Блог calibre¶
Блог calibre - это блог постов, которые описывают многие полезные функции calibre простым и доступным способом для пользователей нового calibre. Чтобы загрузить этот блог в электронную книгу, мы полагаемся на RSS ленту блога:
http://blog.calibre-ebook.com/feeds/posts/default
Я получил URL-адрес RSS, посмотрев в разделе «Подписаться на» в нижней части страницы блога и выбрав Posts → Atom. Чтобы заставить calibre загружать каналы и конвертировать их в электронную книгу, вы должны щелкнуть правой кнопкой мыши по кнопке Fetch news, а затем Добавить пользовательский источник новостей и затем по кнопке :guilabel:`«Новый рецепт». Должно открыться диалоговое окно, подобное показанному ниже.
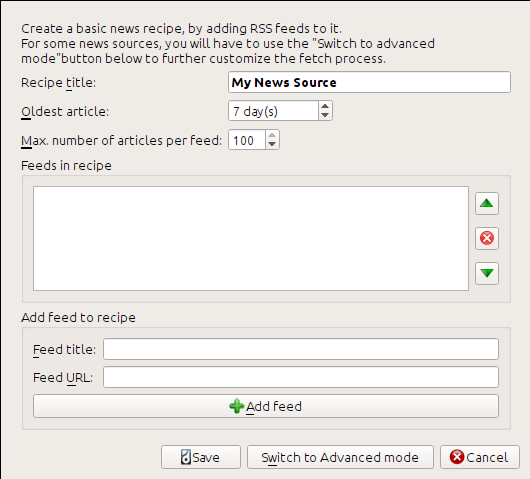
Сначала введите Calibre Blog в поле Название рецепта. Это будет название электронной книги, которая будет создана из статей в вышеупомянутых каналах.
Следующие два поля (Самая старая статья и :guilabel:` Максимальное количество статей`) позволяют вам контролировать, сколько статей следует загружать из каждого канала, и они довольно понятны.
Чтобы добавить каналы в рецепт, введите заголовок канала и URL-адрес канала и нажмите кнопку Добавить канал. После добавления канала просто нажмите кнопку Сохранить, и все готово! Закройте диалог.
Чтобы проверить свой новый recipe, нажмите кнопку Получить новости и в подменю Пользовательские источники новостей нажмите Блог calibre. Через пару минут недавно загруженная электронная книга из сообщений блога появится в главном представлении библиотеки (если у вас подключена читалка, она будет помещена в читалку, а не в библиотеку). Выберите книгу и нажмите кнопку View, чтобы прочитать!
Причина, по которой это сработало так хорошо, с таким небольшим усилием, состоит в том, что блог предоставляет полный контентные RSS фиды, то есть контент статьи внедряется в сам фид. Для большинства новостных источников, которые предоставляют новости таким образом, с полнотекстовыми новостями, вам не нужно больше усилий, чтобы преобразовать их в электронные книги. Теперь мы рассмотрим источник новостей, который не предоставляет полную ленту контента. В таких каналах полная статья является веб-страницей, а лента содержит только ссылку на веб-страницу с кратким обзором статьи.
bbc.co.uk¶
Давайте попробуем следующие два фида из * BBC *:
Главная страница новостей: https://newsrss.bbc.co.uk/rss/newsonline_world_edition/front_page/rss.xml
Наука/Природа: https://newsrss.bbc.co.uk/rss/newsonline_world_edition/science/nature/rss.xml
Следуйте процедуре, описанной в Блог calibre выше, чтобы создать рецепт для BBC (используя фиды выше). Глядя на загруженную электронную книгу, мы видим, что calibre проделал достойную работу по извлечению только того контента, который вам интересен, с веб-страницы каждой статьи. Однако процесс извлечения не идеален. Иногда он оставляет нежелательный контент, такой как меню и навигационные средства, или удаляет контент, который должен был остаться, например заголовки статей. Чтобы обеспечить идеальное извлечение контента, нам нужно настроить процесс извлечения, как описано в следующем разделе.
Настройка процесса получения¶
Если вы хотите усовершенствовать процесс загрузки или загрузить контент с особенно сложного веб-сайта, вы можете воспользоваться всей мощью и гибкостью среды recipe. Для этого в диалоге Добавить пользовательские источники новостей просто нажмите кнопку Переключиться в расширенный режим.
Самая простая и часто наиболее производительная настройка заключается в использовании версии для печати онлайн-статей. Такая версия, как правило, имеет гораздо меньше ошибок и гораздо более гладко переводится в электронную книгу. Давайте попробуем использовать версию для печати статей из BBC.
Использование печатной версии bbc.co.uk¶
Первым шагом является просмотр электронной книги, которую мы скачали ранее bbc.co.uk. В конце каждой статьи в электронной книге есть небольшая реклама, в которой рассказывается, откуда была загружена статья. Скопируйте и вставьте этот URL в браузер. Теперь на веб-странице статьи найдите ссылку, которая указывает на «Версия для печати». Нажмите на неё, чтобы увидеть печатную версию статьи. Это выглядит намного аккуратнее! Теперь сравните два URL. Для меня они были такими:
Таким образом, похоже, чтобы получить версию для печати, нам нужно добавить префикс к каждой статье:
newsvote.bbc.co.uk/mpapps/pagetools/print/
Теперь в Advanced Mode диалога Custom news sources вы должны увидеть что-то вроде (не забудьте выбрать рецепт BBC перед переходом в расширенный режим):
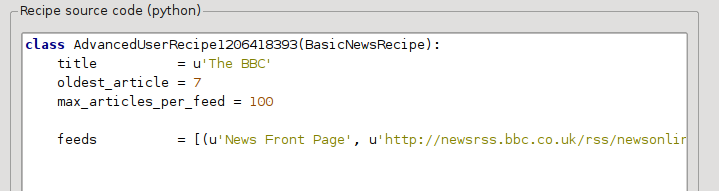
Вы можете видеть, что поля из Basic mode были прямо переведены в код Python. Нам нужно добавить инструкции к этому рецепту, чтобы использовать печатную версию статей. Всё, что нужно, это добавить следующие две строки:
def print_version(self, url):
return url.replace('https://', 'https://newsvote.bbc.co.uk/mpapps/pagetools/print/')
Это Python, поэтому отступы важны. После того, как вы добавили строки, это должно выглядеть так:
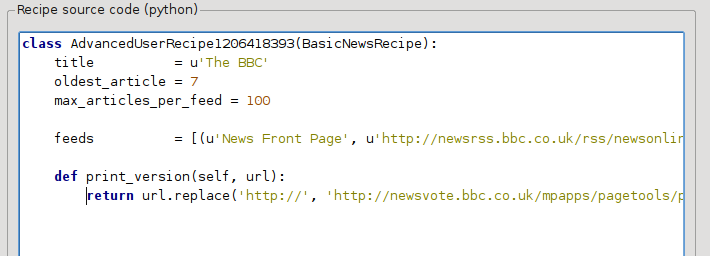
Выше def print_version(self, url) определяет метод, который вызывается calibre для каждой статьи. url - это URL оригинальной статьи. print_version - это взять этот URL и заменить его новым URL, который указывает на печатную версию статьи. Чтобы узнать о Python, см. tutorial.
Теперь нажмите кнопку Добавить/обновить рецепт, и ваши изменения будут сохранены. Повторно загрузите электронную книгу. У вас должна быть намного улучшенная электронная книга. Одна из проблем новой версии заключается в том, что шрифты на веб-странице версии для печати слишком малы. Это автоматически исправляется при преобразовании в электронную книгу, но даже после процесса исправления размер шрифта меню и панели навигации становится слишком большим по сравнению с текстом статьи. Чтобы исправить это, мы сделаем ещё несколько настроек в следующем разделе.
Замена стилей статей¶
В предыдущем разделе мы видели, что размер шрифта для статей из печатной версии BBC был слишком мал. На большинстве веб-сайтов, включая BBC, этот размер шрифта устанавливается с помощью CSS таблиц стилей. Мы можем отключить выборку таких таблиц стилей, добавив строку:
no_stylesheets = True
Рецепт теперь выглядит так:
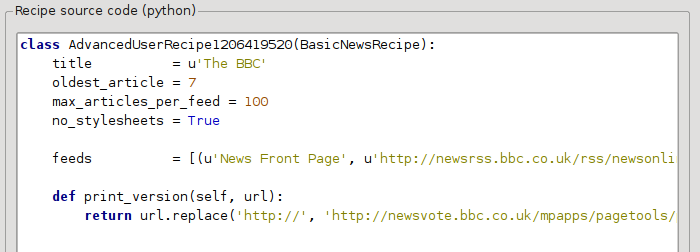
Новая версия выглядит довольно хорошо. Если вы перфекционист, вам нужно прочитать следующий раздел, посвященный изменению загруженного контента.
Шинковка ломтиками и кубиками¶
Что касается управления загруженным содержимым, calibre обладает мощными и гибкими возможностями. Чтобы похвастаться парочкой, давайте снова посмотрим на нашего старого друга — рецепт BBC. Взглянув на исходный код (HTML) пары статей (версия для печати), мы увидим в них нижний колонтитул без какой-либо полезной информации, содержащейся в
<div class="footer">
...
</div>
Это может быть удалено путем добавления:
remove_tags = [dict(name='div', attrs={'class':'footer'})]
к рецепту. Наконец, давайте заменим некоторые из CSS, которые мы отключили ранее, на наш собственный CSS, который подходит для преобразования в электронную книгу:
extra_css = '.headline {font-size: x-large;} \n .fact { padding-top: 10pt }'
Благодаря этим дополнениям наш рецепт стал «производственным качеством».
Это recipe исследует только верхушку айсберга, когда дело доходит до силы calibre. Чтобы изучить больше возможностей calibre, мы рассмотрим более сложный пример из реальной жизни в следующем разделе.
Пример из реальной жизни¶
Достаточно сложный пример из реальной жизни, который раскрывает большую часть API BasicNewsRecipe, это recipe для The New York Times
import string, re
from calibre import strftime
from calibre.web.feeds.recipes import BasicNewsRecipe
from calibre.ebooks.BeautifulSoup import BeautifulSoup
class NYTimes(BasicNewsRecipe):
title = 'The New York Times'
__author__ = 'Kovid Goyal'
description = 'Daily news from the New York Times'
timefmt = ' [%a, %d %b, %Y]'
needs_subscription = True
remove_tags_before = dict(id='article')
remove_tags_after = dict(id='article')
remove_tags = [dict(attrs={'class':['articleTools', 'post-tools', 'side_tool', 'nextArticleLink clearfix']}),
dict(id=['footer', 'toolsRight', 'articleInline', 'navigation', 'archive', 'side_search', 'blog_sidebar', 'side_tool', 'side_index']),
dict(name=['script', 'noscript', 'style'])]
encoding = 'cp1252'
no_stylesheets = True
extra_css = 'h1 {font: sans-serif large;}\n.byline {font:monospace;}'
def get_browser(self):
br = BasicNewsRecipe.get_browser(self)
if self.username is not None and self.password is not None:
br.open('https://www.nytimes.com/auth/login')
br.select_form(name='login')
br['USERID'] = self.username
br['PASSWORD'] = self.password
br.submit()
return br
def parse_index(self):
soup = self.index_to_soup('https://www.nytimes.com/pages/todayspaper/index.html')
def feed_title(div):
return ''.join(div.findAll(text=True, recursive=False)).strip()
articles = {}
key = None
ans = []
for div in soup.findAll(True,
attrs={'class':['section-headline', 'story', 'story headline']}):
if ''.join(div['class']) == 'section-headline':
key = string.capwords(feed_title(div))
articles[key] = []
ans.append(key)
elif ''.join(div['class']) in ['story', 'story headline']:
a = div.find('a', href=True)
if not a:
continue
url = re.sub(r'\?.*', '', a['href'])
url += '?pagewanted=all'
title = self.tag_to_string(a, use_alt=True).strip()
description = ''
pubdate = strftime('%a, %d %b')
summary = div.find(True, attrs={'class':'summary'})
if summary:
description = self.tag_to_string(summary, use_alt=False)
feed = key if key is not None else 'Uncategorized'
if feed not in articles:
articles[feed] = []
if not 'podcasts' in url:
articles[feed].append(
dict(title=title, url=url, date=pubdate,
description=description,
content=''))
ans = self.sort_index_by(ans, {'The Front Page':-1, 'Dining In, Dining Out':1, 'Obituaries':2})
ans = [(key, articles[key]) for key in ans if key in articles]
return ans
def preprocess_html(self, soup):
refresh = soup.find('meta', {'http-equiv':'refresh'})
if refresh is None:
return soup
content = refresh.get('content').partition('=')[2]
raw = self.browser.open('https://www.nytimes.com'+content).read()
return BeautifulSoup(raw.decode('cp1252', 'replace'))
В этом мы видим несколько новых функций recipe. Во-первых, у нас есть:
timefmt = ' [%a, %d %b, %Y]'
Это устанавливает отображаемое время на первой странице созданной электронной книги в формате Day, Day_Number Month, Year. Смотрите timefmt.
Затем мы видим группу директив для очистки загруженного файла HTML:
remove_tags_before = dict(name='h1')
remove_tags_after = dict(id='footer')
remove_tags = ...
Они удаляют все до первого тега <h1> и все после первого тега с идентификатором `` footer``. Смотрите remove_tags, remove_tags_before, remove_tags_after.
Следующая интересная особенность:
needs_subscription = True
...
def get_browser(self):
...
needs_subscription = True сообщает calibre, что для получения доступа к содержимому этого рецепта требуется имя пользователя и пароль. Это заставляет calibre запрашивать имя пользователя и пароль всякий раз, когда вы пытаетесь использовать этот рецепт. Код в calibre.web.feeds.news.BasicNewsRecipe.get_browser() фактически выполняет вход на веб-сайт NYT. После входа в систему calibre будет использовать тот же, вошедший в систему, экземпляр браузера, чтобы получить весь контент. Смотрите mechanize, чтобы понять код в get_browser.
Следующей новой функцией является метод calibre.web.feeds.news.BasicNewsRecipe.parse_index(). Его работа заключается в том, чтобы перейти на https://www.nytimes.com/pages/todayspaper/index.html и получить список статей, которые появляются в сегодняшнем документе. Хотя этот рецепт сложнее, чем просто использовать RSS, этот рецепт создает электронную книгу, которая очень точно соответствует дневнику. parse_index интенсивно использует BeautifulSoup для анализа ежедневной веб-страницы газеты. Вы также можете использовать другие, более современные парсеры, если вам не нравится BeautifulSoup. calibre поставляется с lxml <https://lxml.de/> _ и html5lib, которые являются рекомендуемыми парсерами. Чтобы использовать их, замените вызов index_to_soup() следующим:
raw = self.index_to_soup(url, raw=True)
# For html5lib
import html5lib
root = html5lib.parse(raw, namespaceHTMLElements=False, treebuilder='lxml')
# For the lxml html 4 parser
from lxml import html
root = html.fromstring(raw)
Последняя новая функция - это метод calibre.web.feeds.news.BasicNewsRecipe.preprocess_html(). Его можно использовать для выполнения произвольных преобразований на каждой загруженной HTML-странице. Здесь он используется для обхода рекламы, которую nytimes показывает перед каждой статьей.
Советы по созданию новых рецептов¶
Лучший способ разработать новые рецепты - использовать интерфейс командной строки. Создайте рецепт, используя ваш любимый редактор Python, и сохраните его в файл, скажем myrecipe.recipe. Требуется расширение .recipe. Вы можете скачать контент, используя этот рецепт с командой:
ebook-convert myrecipe.recipe .epub --test -vv --debug-pipeline debug
Команда ebook-convert загрузит все веб-страницы и сохранит их в файл EPUB myrecipe.epub. Параметр -vv заставляет ebook-convert выдавать много информации о том, что он делает. Параметр ebook-convert-recipe-input --test позволяет загружать только пару статей максимум из двух каналов. Кроме того, ebook-convert поместит загруженный HTML-код в папку debug/input, где debug - это папка, указанная в параметре ebook-convert --debug-pipeline.
После завершения загрузки вы можете просмотреть загруженный файл HTML, открыв файл debug/input/index.html в браузере. Убедившись, что загрузка и предварительная обработка выполняются правильно, вы можете создавать электронные книги в различных форматах, как показано ниже:
ebook-convert myrecipe.recipe myrecipe.epub
ebook-convert myrecipe.recipe myrecipe.mobi
...
Если вы удовлетворены своим рецептом и чувствуете, что существует достаточный спрос, чтобы оправдать его включение в набор встроенных рецептов, опубликуйте свой рецепт на форуме рецептов calibre, чтобы поделиться им с другими пользователями.
Примечание
В macOS инструменты командной строки находятся внутри пакета calibre, например, если вы установили calibre в /Applications, то инструменты командной строки будут в /Applications/calibre.app/Contents/MacOS/.
См. также
- ebook-convert
Интерфейс командной строки для всех конвертаций электронных книг.
Дальнейшее чтение¶
Чтобы узнать больше о написании расширенных рецептов с использованием некоторых средств, доступных в BasicNewsRecipe, вам следует обратиться к следующим источникам:
- Документация API
Документация класса
BasicNewsRecipeи всех его важных методов и полей.- BasicNewsRecipe
Исходный код
BasicNewsRecipe- Встроенные рецепты
Исходный код для встроенных рецептов, которые идут с calibre
- Форум рецептов calibre
Много знающих авторов рецепта calibre тусуются здесь.
Документация API¶
- Документация API рецептов
BasicNewsRecipeBasicNewsRecipe.adeify_images()BasicNewsRecipe.image_url_processor()BasicNewsRecipe.print_version()BasicNewsRecipe.tag_to_string()BasicNewsRecipe.abort_article()BasicNewsRecipe.abort_recipe_processing()BasicNewsRecipe.add_toc_thumbnail()BasicNewsRecipe.canonicalize_internal_url()BasicNewsRecipe.cleanup()BasicNewsRecipe.clone_browser()BasicNewsRecipe.default_cover()BasicNewsRecipe.download()BasicNewsRecipe.extract_readable_article()BasicNewsRecipe.get_article_url()BasicNewsRecipe.get_browser()BasicNewsRecipe.get_cover_url()BasicNewsRecipe.get_extra_css()BasicNewsRecipe.get_feeds()BasicNewsRecipe.get_masthead_title()BasicNewsRecipe.get_masthead_url()BasicNewsRecipe.get_obfuscated_article()BasicNewsRecipe.get_url_specific_delay()BasicNewsRecipe.index_to_soup()BasicNewsRecipe.is_link_wanted()BasicNewsRecipe.parse_feeds()BasicNewsRecipe.parse_index()BasicNewsRecipe.populate_article_metadata()BasicNewsRecipe.postprocess_book()BasicNewsRecipe.postprocess_html()BasicNewsRecipe.preprocess_html()BasicNewsRecipe.preprocess_image()BasicNewsRecipe.preprocess_raw_html()BasicNewsRecipe.publication_date()BasicNewsRecipe.skip_ad_pages()BasicNewsRecipe.sort_index_by()BasicNewsRecipe.articles_are_obfuscatedBasicNewsRecipe.auto_cleanupBasicNewsRecipe.auto_cleanup_keepBasicNewsRecipe.browser_typeBasicNewsRecipe.center_navbarBasicNewsRecipe.compress_news_imagesBasicNewsRecipe.compress_news_images_auto_sizeBasicNewsRecipe.compress_news_images_max_sizeBasicNewsRecipe.conversion_optionsBasicNewsRecipe.cover_marginsBasicNewsRecipe.delayBasicNewsRecipe.descriptionBasicNewsRecipe.encodingBasicNewsRecipe.extra_cssBasicNewsRecipe.feedsBasicNewsRecipe.filter_regexpsBasicNewsRecipe.handle_gzipBasicNewsRecipe.ignore_duplicate_articlesBasicNewsRecipe.keep_only_tagsBasicNewsRecipe.languageBasicNewsRecipe.masthead_urlBasicNewsRecipe.match_regexpsBasicNewsRecipe.max_articles_per_feedBasicNewsRecipe.needs_subscriptionBasicNewsRecipe.no_stylesheetsBasicNewsRecipe.oldest_articleBasicNewsRecipe.preprocess_regexpsBasicNewsRecipe.publication_typeBasicNewsRecipe.recipe_disabledBasicNewsRecipe.recipe_specific_optionsBasicNewsRecipe.recursionsBasicNewsRecipe.remove_attributesBasicNewsRecipe.remove_empty_feedsBasicNewsRecipe.remove_javascriptBasicNewsRecipe.remove_tagsBasicNewsRecipe.remove_tags_afterBasicNewsRecipe.remove_tags_beforeBasicNewsRecipe.requires_versionBasicNewsRecipe.resolve_internal_linksBasicNewsRecipe.reverse_article_orderBasicNewsRecipe.scale_news_imagesBasicNewsRecipe.scale_news_images_to_deviceBasicNewsRecipe.simultaneous_downloadsBasicNewsRecipe.summary_lengthBasicNewsRecipe.template_cssBasicNewsRecipe.timefmtBasicNewsRecipe.timeoutBasicNewsRecipe.titleBasicNewsRecipe.use_embedded_content