 言語を変更
言語を変更お気に入りのニュースサイトを追加¶
calibre は、インターネットからニュースをダウンロードして電子書籍に変換するための、柔軟かつ強力で使いやすいフレームワークを備えています。下では例を用いて、さまざまな Web サイトからニュースを取得する方法を説明します。
フレームワークの使い方を理解するには、下に並んでいる順に例を追ってください:
完全自動の取得¶
もしニュースソースが単純なものなら、calibre は完全に自動で取得することができます。必要なのは URL を与えることだけです。calibre はニュースソースのダウンロードに必要な情報を レシピ に集めています。calibre にニュースソースについての情報を与えるためには、レシピ を作る必要があります。では、いくつか例を見てみましょう。
calibre ブログ¶
calibre ブログには、calibre の新規ユーザが簡単に情報を入手できるよう、calibre の多くの便利な機能を説明する記事が置かれています。このブログをダウンロードして電子書籍にするのに、ブログの RSS フィードを頼っています。
http://blog.calibre-ebook.com/feeds/posts/default
RSS URL はブログページ下部の "Subscribe to" の下にある Posts → Atom を選択します。calibre にフィードをダウンロードして電子書籍に変換させるには、ニュースを取得 を右クリックしてメニュー項目の カスタムニュースソースを追加 を選択し、新規レシピ ボタンを押します。下に示すものと似たようなダイアログが表示されます。
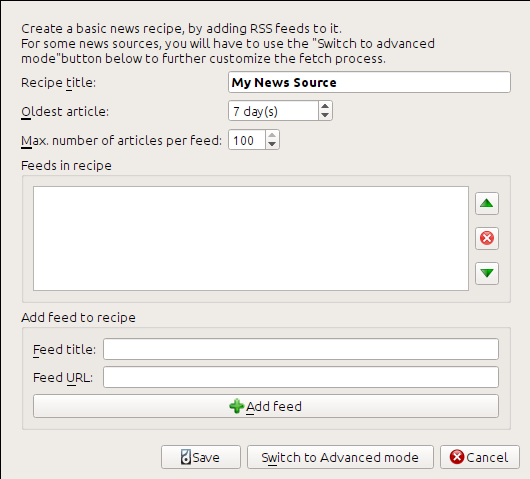
まず レシピのタイトル フィールドに Calibre Blog と入力します。これは上記のフィードの記事から作成される電子書籍のタイトルとなります。
次のふたつのフィールド (一番古い記事 および 記事の最大数) を使って、各フィードからどれだけの記事をダウンロードするかを制御できます。意味は名前のとおりです。
フィードをレシピに追加するには、フィードのタイトルと URL を入力して フィードを追加 ボタンをクリックします。フィードを追加したら 保存 ボタンをクリックすれば完了です。ダイアログを閉じてください。
レシピ をテストするには、ニュースを取得 ボタンをクリックして、サブメニュー カスタムニュースソース の中から calibre Blog をクリックします。数分後、新しくダウンロードしたブログ記事の電子書籍がメインのライブラリビューに (もしリーダーを接続していれば、ライブラリの代わりにリーダー上に) 現れます。それを選択して 表示 ボタンを押せば、読めます。
ほとんど手間をかけることなくこれがうまく機能する理由は、ブログが フルコンテンツの RSS フィードを提供しているためです。つまり、記事内容がフィード自体に埋めこまれているのです。ニュースをこの形、すなわち フルコンテンツの フィードで提供するほとんどのニュースソースでは、電子書籍に変換するのにこれ以上の手間は必要ありません。では、フルコンテンツのフィードを提供していないニュースソースについて見てみましょう。そのようなフィードには、記事の全文は Web ページにあり、フィードには短い要約とともにその Web ページへのリンクのみが含まれています。
bbc.co.uk¶
次の The BBC からのふたつのフィードを追ってみましょう:
上記の calibre ブログ で概説した手順に沿って The BBC 用のレシピを (上のフィードを使って) 作成します。ダウンロードした電子書籍を見ると、calibre はそれぞれの記事の Web ページから読みたい記事だけを抽出する仕事を立派にこなしていることがわかります。しかし、その抽出の処理は完全ではありません。メニューやナビゲーションなどの望ましくないコンテンツがそのまま残っていたり、記事の見出しのような残しておくべきコンテンツを削除してしまっていることがあります。コンテンツの抽出を完璧に行うには、次の章で説明するように取得処理をカスタマイズする必要があります。
取得処理のカスタマイズ¶
ダウンロード処理を完璧にしたいときや、特に複雑な Web サイトからコンテンツをダウンロードしたいときこそ、レシピ フレームワークの威力と柔軟性が役立ちます。これには カスタムニュースソースを追加 ダイアログで 上級者モードに切替え をクリックします。
最も簡単で、かつ多くの場合最も生産的なカスタマイズは、オンライン記事の印刷用バージョンを使うことです。印刷用バージョンは通例、よけいなものがはるかに少なく、電子書籍への変換もスムーズに行えます。The BBC の記事の印刷用バージョンを使ってみましょう.
bbc.co.uk のプリント用バージョンを使用¶
最初のステップは、以前 bbc.co.uk からダウンロードした電子書籍を確認することです。各記事の末尾に、電子書籍ではその記事がどこからダウンロードされたものなのかを示す小さな記載があります。その URL をブラウザにコピーして貼り付けてください。では、記事の Web ページ上で "Printable version" へのリンクを探しましょう。それをクリックして記事の印刷用バージョンを見てみます。こちらの方がずっときれいです。さて、ふたつの URL を比較してみましょう。次のように見えます:
したがって印刷用バージョンを入手するためには、すべての記事の URL に次のプレフィックスをつける必要がありそうです:
newsvote.bbc.co.uk/mpapps/pagetools/print/
これでカスタムニュースソースダイアログの 上級者モード に入りました。次のように表示されます (上級者モードに切り替える前に、忘れずに The BBC レシピを選択してください):
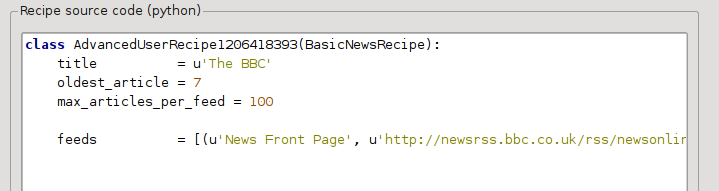
ベーシックモード のフィールドが Python コードに簡単な方法で変換されていることがわかります。このレシピに、記事のプリント用バージョンを利用するよう指示を加える必要があります。必要なのは、次の 2 行を追加することです:
def print_version(self, url):
return url.replace('https://', 'https://newsvote.bbc.co.uk/mpapps/pagetools/print/')
これは Python なので、インデントが重要です。行を追加すると、次のようになります:
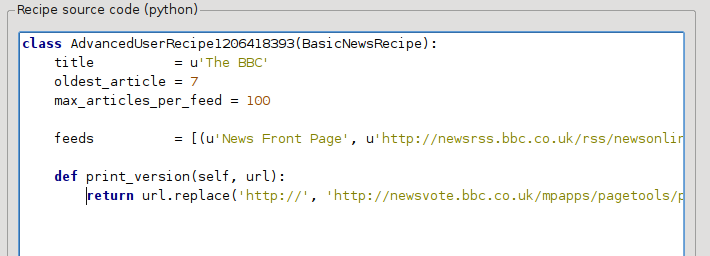
上では def print_version(self, url) は記事ごとに calibre から呼び出される メソッド を定義しています。url は元の記事の URL です。print_version は、その URL を記事の印刷用バージョンを指す新しい URL で置き換えます。 Python について学習するには、 チュートリアル を参照してください。
次に、保存 ボタンを押すと変更が保存されます。電子書籍を再ダウンロードしてください。電子書籍はかなり改善されているはずです。この新しいバージョンの問題点のひとつは、印刷用バージョンの Web ページのフォントは小さすぎることです。これは電子書籍への変換時に自動的に修正されますが、修正処理の後でも、メニューとナビゲーションバーのフォントサイズは記事のテキストと比較して大きくなりすぎます。これを修正するには、次の章で説明するようにさらにカスタマイズが必要です。
記事のスタイルを置換¶
前の章では、The BBC の印刷用バージョンの記事のフォントサイズが小さすぎることを確認しました。The BBC を含めほとんどの Web サイトでは、このフォントサイズを CSS スタイルシートを使って設定しています。そのようなスタイルシートの取得は、次の行を加えることでやめさせられます:
no_stylesheets = True
レシピは次のようになります:
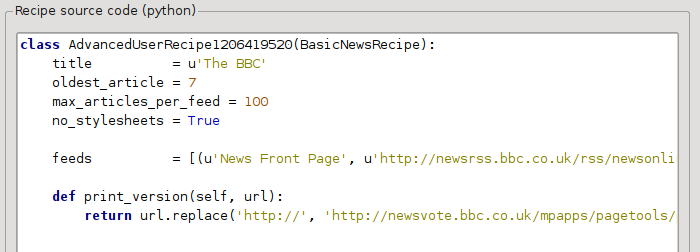
新しいバージョンは大変よくなりました。完全主義者であれば、ダウンロードしたコンテンツを実際に変更することを扱う次の章を読むことをお勧めします。
スライス&ダイス分析¶
ダウンロードしたコンテンツの処理にかけては、calibre には非常に強力で柔軟性のある機能を持っています。いくつか紹介するために、もはやお馴染みとなった The BBC レシピをもう一度見てみましょう。いくつかの記事 (印刷用バージョン) のソースコード (HTML) を見ると、下で示すフッタ部分には有用な情報が含まれていないことがわかります。
<div class="footer">
...
</div>
これはレシピに次を追加することで削除できます:
remove_tags = [dict(name='div', attrs={'class':'footer'})]
最後に、以前無効にした CSS の一部を、電子書籍への変換に適した自前の CSS に置き換えましょう:
extra_css = '.headline {font-size: x-large;} \n .fact { padding-top: 10pt }'
こうした追加によって、レシピは「製品レベルの品質」になりました。
この レシピ は calibre の威力に関する氷山の一角に触れたにすぎません。calibre の能力にさらに触れるため、次の章ではより複雑な実例を取り上げます。
実例¶
BasicNewsRecipe の API を体験できる適度に複雑な実例は、The New York Times の レシピ です。
import string, re
from calibre import strftime
from calibre.web.feeds.recipes import BasicNewsRecipe
from calibre.ebooks.BeautifulSoup import BeautifulSoup
class NYTimes(BasicNewsRecipe):
title = 'The New York Times'
__author__ = 'Kovid Goyal'
description = 'Daily news from the New York Times'
timefmt = ' [%a, %d %b, %Y]'
needs_subscription = True
remove_tags_before = dict(id='article')
remove_tags_after = dict(id='article')
remove_tags = [dict(attrs={'class':['articleTools', 'post-tools', 'side_tool', 'nextArticleLink clearfix']}),
dict(id=['footer', 'toolsRight', 'articleInline', 'navigation', 'archive', 'side_search', 'blog_sidebar', 'side_tool', 'side_index']),
dict(name=['script', 'noscript', 'style'])]
encoding = 'cp1252'
no_stylesheets = True
extra_css = 'h1 {font: sans-serif large;}\n.byline {font:monospace;}'
def get_browser(self):
br = BasicNewsRecipe.get_browser(self)
if self.username is not None and self.password is not None:
br.open('https://www.nytimes.com/auth/login')
br.select_form(name='login')
br['USERID'] = self.username
br['PASSWORD'] = self.password
br.submit()
return br
def parse_index(self):
soup = self.index_to_soup('https://www.nytimes.com/pages/todayspaper/index.html')
def feed_title(div):
return ''.join(div.findAll(text=True, recursive=False)).strip()
articles = {}
key = None
ans = []
for div in soup.findAll(True,
attrs={'class':['section-headline', 'story', 'story headline']}):
if ''.join(div['class']) == 'section-headline':
key = string.capwords(feed_title(div))
articles[key] = []
ans.append(key)
elif ''.join(div['class']) in ['story', 'story headline']:
a = div.find('a', href=True)
if not a:
continue
url = re.sub(r'\?.*', '', a['href'])
url += '?pagewanted=all'
title = self.tag_to_string(a, use_alt=True).strip()
description = ''
pubdate = strftime('%a, %d %b')
summary = div.find(True, attrs={'class':'summary'})
if summary:
description = self.tag_to_string(summary, use_alt=False)
feed = key if key is not None else 'Uncategorized'
if feed not in articles:
articles[feed] = []
if not 'podcasts' in url:
articles[feed].append(
dict(title=title, url=url, date=pubdate,
description=description,
content=''))
ans = self.sort_index_by(ans, {'The Front Page':-1, 'Dining In, Dining Out':1, 'Obituaries':2})
ans = [(key, articles[key]) for key in ans if key in articles]
return ans
def preprocess_html(self, soup):
refresh = soup.find('meta', {'http-equiv':'refresh'})
if refresh is None:
return soup
content = refresh.get('content').partition('=')[2]
raw = self.browser.open('https://www.nytimes.com'+content).read()
return BeautifulSoup(raw.decode('cp1252', 'replace'))
この レシピ にはいくつか新しい機能があります。まず、次のものがあります:
timefmt = ' [%a, %d %b, %Y]'
これは作成する電子書籍のとびらに日付を 曜日, 日 月, 年 の形式で表示します。timefmt を参照してください。
そして、ダウンロードした HTML をきれいにするための指令のかたまりがあるのがわかります。
remove_tags_before = dict(name='h1')
remove_tags_after = dict(id='footer')
remove_tags = ...
これは最初の <h1> の前にあるすべてと、id が footer である最初のタグの後ろのすべてを削除します。remove_tags, remove_tags_before, remove_tags_after を参照してください。
次の興味深い機能は次のものです:
needs_subscription = True
...
def get_browser(self):
...
needs_subscription = True はコンテンツにアクセスするためにユーザ名とパスワードが必要であることを calibre に伝えます。これにより、calibre はこのレシピを使うたびにユーザ名とパスワードを要求します。calibre.web.feeds.news.BasicNewsRecipe.get_browser() の中のコードで、実際に NYT の Web サイトにログインしています。ログインすると、同じログイン済みのブラウザインスタンスを使用してすべてのコンテンツを取得します。get_browser のコードを理解するには mechanize を参照してください。
次の新しい機能は calibre.web.feeds.news.BasicNewsRecipe.parse_index() メソッドです。これの仕事は https://www.nytimes.com/pages/todayspaper/index.html へ行き、 今日 の 新聞に掲載されている記事のリストを取得することです。:term`RSS` を使用することに比べると複雑ですが、このレシピはその日の新聞に非常に近い電子書籍を作成します。parse_index は日刊紙の Web サイトを解析するのに BeautifulSoup を多用します。BeautifulSoup が気に入らなければ、もっとモダンな別のパーサを利用することもできます。calibre には推奨パーサである lxml と`html5lib <https://github.com/html5lib/html5lib-python>`_ が付属しています。これを使用するには、index_to_soup() の呼び出しを次のもので置き換えてください:
raw = self.index_to_soup(url, raw=True)
# For html5lib
import html5lib
root = html5lib.parse(raw, namespaceHTMLElements=False, treebuilder='lxml')
# For the lxml html 4 parser
from lxml import html
root = html.fromstring(raw)
最後の新しい機能は calibre.web.feeds.news.BasicNewsRecipe.preprocess_html() メソッドです。ダウンロードした HTML ページごとに任意の変換を行うために利用できます。ここでは記事の前に表示される広告をよけるために使用しています。
新しいレシピを開発するコツ¶
新しいレシピを開発するのに最適なのは、コマンドラインインタフェースを利用することです。好みの Python エディタを使ってレシピを作成し、たとえば myrecipe.recipe のようなファイルに保存します。拡張子は .recipe とする必要があります。このレシピを使ってコンテンツをダウンロードするには、次のコマンドを使用します:
ebook-convert myrecipe.recipe .epub --test -vv --debug-pipeline debug
ebook-convert コマンドは、すべての Web ページをダウンロードして myrecipe.epub という EPUB ファイルに保存します。-vv オプションを使うと、最大 2 つのフィードから数記事のみをダウンロードします。さらに、ebook-convert はダウンロードした HTML を debug/input フォルダに置きます。debug は ebook-convert --debug-pipeline オプションで指定したフォルダです。
ダウンロードが完了したら、ブラウザで debug/input/index.html ファイルを開いてダウンロードした HTML を確認できます。ダウンロードと前処理が正しく行われていることを確認できたら、下に示すようにさまざまな形式の電子書籍を生成できます:
ebook-convert myrecipe.recipe myrecipe.epub
ebook-convert myrecipe.recipe myrecipe.mobi
...
作成したレシピに満足して、calibre のビルトインレシピに含めるに十分なだけの需要があると感じた場合には、 calibre レシピフォーラム に投稿して他のユーザと共有してください 。
注釈
macOS では、コマンドラインツールは calibre バンドルの中にあります。たとえば calibre を /Applications にインストールしたのであれば、コマンドラインツールは /Applications/calibre.app/Contents/console.app/Contents/MacOS/ にあります。
参考
- ebook-convert
すべての電子書籍変換用のコマンドラインインタフェース。
参考文献¶
BasicNewsRecipe で利用可能な機能を利用して上級レシピを作成する方法をさらに学ぶには、下のソースを参照してください:
- API 取扱説明書
BasicNewsRecipeクラスと、すべての重要なメソッドおよびフィールドについての取扱説明書です。- BasicNewsRecipe
BasicNewsRecipeのソースコード- ビルトインレシピ
calibre に付属しているビルトインレシピのソースコード
- calibre レシピフォーラム
知識豊富なレシピ作者の多くがここにたむろしています。
API 取扱説明書¶
- レシピの API 説明書
BasicNewsRecipeBasicNewsRecipe.adeify_images()BasicNewsRecipe.image_url_processor()BasicNewsRecipe.print_version()BasicNewsRecipe.tag_to_string()BasicNewsRecipe.abort_article()BasicNewsRecipe.abort_recipe_processing()BasicNewsRecipe.add_toc_thumbnail()BasicNewsRecipe.canonicalize_internal_url()BasicNewsRecipe.cleanup()BasicNewsRecipe.clone_browser()BasicNewsRecipe.default_cover()BasicNewsRecipe.download()BasicNewsRecipe.extract_readable_article()BasicNewsRecipe.get_article_url()BasicNewsRecipe.get_browser()BasicNewsRecipe.get_cover_url()BasicNewsRecipe.get_extra_css()BasicNewsRecipe.get_feeds()BasicNewsRecipe.get_masthead_title()BasicNewsRecipe.get_masthead_url()BasicNewsRecipe.get_obfuscated_article()BasicNewsRecipe.get_url_specific_delay()BasicNewsRecipe.index_to_soup()BasicNewsRecipe.is_link_wanted()BasicNewsRecipe.parse_feeds()BasicNewsRecipe.parse_index()BasicNewsRecipe.populate_article_metadata()BasicNewsRecipe.postprocess_book()BasicNewsRecipe.postprocess_html()BasicNewsRecipe.preprocess_html()BasicNewsRecipe.preprocess_image()BasicNewsRecipe.preprocess_raw_html()BasicNewsRecipe.publication_date()BasicNewsRecipe.skip_ad_pages()BasicNewsRecipe.sort_index_by()BasicNewsRecipe.articles_are_obfuscatedBasicNewsRecipe.auto_cleanupBasicNewsRecipe.auto_cleanup_keepBasicNewsRecipe.browser_typeBasicNewsRecipe.center_navbarBasicNewsRecipe.compress_news_imagesBasicNewsRecipe.compress_news_images_auto_sizeBasicNewsRecipe.compress_news_images_max_sizeBasicNewsRecipe.conversion_optionsBasicNewsRecipe.cover_marginsBasicNewsRecipe.delayBasicNewsRecipe.descriptionBasicNewsRecipe.encodingBasicNewsRecipe.extra_cssBasicNewsRecipe.feedsBasicNewsRecipe.filter_regexpsBasicNewsRecipe.handle_gzipBasicNewsRecipe.ignore_duplicate_articlesBasicNewsRecipe.keep_only_tagsBasicNewsRecipe.languageBasicNewsRecipe.masthead_urlBasicNewsRecipe.match_regexpsBasicNewsRecipe.max_articles_per_feedBasicNewsRecipe.needs_subscriptionBasicNewsRecipe.no_stylesheetsBasicNewsRecipe.oldest_articleBasicNewsRecipe.preprocess_regexpsBasicNewsRecipe.publication_typeBasicNewsRecipe.recipe_disabledBasicNewsRecipe.recipe_specific_optionsBasicNewsRecipe.recursionsBasicNewsRecipe.remove_attributesBasicNewsRecipe.remove_empty_feedsBasicNewsRecipe.remove_javascriptBasicNewsRecipe.remove_tagsBasicNewsRecipe.remove_tags_afterBasicNewsRecipe.remove_tags_beforeBasicNewsRecipe.requires_versionBasicNewsRecipe.resolve_internal_linksBasicNewsRecipe.reverse_article_orderBasicNewsRecipe.scale_news_imagesBasicNewsRecipe.scale_news_images_to_deviceBasicNewsRecipe.simultaneous_downloadsBasicNewsRecipe.summary_lengthBasicNewsRecipe.template_cssBasicNewsRecipe.timefmtBasicNewsRecipe.timeoutBasicNewsRecipe.titleBasicNewsRecipe.use_embedded_content