 更改语言
更改语言添加你喜欢的新闻站点¶
caliber有一个强大,灵活且易于使用的框架,用于从Internet下载新闻并将其转换为电子书。 以下将通过示例向您展示如何从各种网站获取新闻。
要了解如何使用框架,请按照下面列出的顺序执行示例:
完全自动获取¶
如果你的新闻来源足够简单,Calibre很可能能够完全自动获取它,你所需要做的就是提供URL。Calibre收集下载新闻源到`Receipe`所需的所有信息。为了告诉Calibre关于一个新闻源的信息,你必须为它创建一个“Receipe”。让我们来看一些例子:
calibre博客¶
calibre 博客是一个帖子博客,以简单易懂的方式为新 calibre 用户描述许多有用的 calibre 功能。 为了将此博客下载成电子书,我们依赖博客的“RSS”提要:
http://blog.calibre-ebook.com/feeds/posts/default
我通过查看博客页面底部的“订阅”并选择“Posts->Atom”获得了 RSS URL。 要使 calibre 下载提要并将其转换为电子书,您应该右键单击“获取新闻”按钮,然后单击“添加自定义新闻源”菜单项,然后单击“新新闻源”按钮。 应该会打开一个类似于下图所示的对话框。
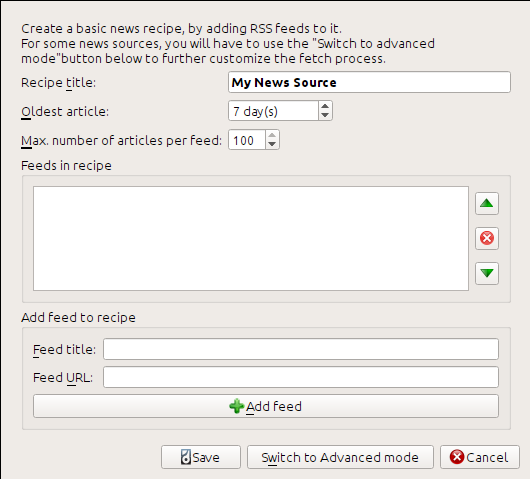
首先在“新闻源标题”字段中输入“Calibre Blog”。 这将是根据上述提要中的文章创建的电子书的标题。
接下来的两个字段(“最旧的文章”和“最大文章数”)允许您控制应该从每个提要下载多少文章,并且它们非常不言自明。
要将提要添加到新闻源中,请输入提要标题和提要 URL,然后单击“添加提要”按钮。 添加提要后,只需单击“保存”按钮即可完成! 关闭对话框。
要测试新的“新闻源”,请单击“获取新闻”按钮,然后在“自定义新闻源”子菜单中单击“calibre Blog”。 几分钟后,新下载的博客文章电子书将出现在主书库视图中(如果您连接了阅读器,它将被放入阅读器而不是书库中)。 选择它并点击“查看”按钮即可阅读!
这种方法效果如此之好、花费如此之少的原因是博客提供了“完整内容”“RSS”提要,即文章内容嵌入在提要本身中。 对于大多数以这种方式提供新闻的新闻源,通过“完整内容”提要,您不需要更多的努力将它们转换为电子书。 现在我们将看看不提供完整内容提要的新闻源。 在此类提要中,完整的文章是一个网页,并且提要仅包含指向该网页的链接以及文章的简短摘要。
bbc.co.uk¶
让我们尝试一下来自 The BBC 的以下两个提要:
按照上面“calibre_blog”中概述的过程为 The BBC 创建新闻源(使用上面的提要)。 查看下载的电子书,我们发现 calibre 做得工作非常出色,它只从每篇文章的网页中提取您关心的内容。 然而,提取过程并不完美。 有时,它会留下不需要的内容,例如菜单和导航辅助工具,或者删除本应保留的内容,例如文章标题。 为了实现完美的内容提取,我们需要自定义获取过程,如下一节所述。
自定义获取过程¶
当您想要完善下载过程或从特别复杂的网站下载内容时,您可以利用“recipe”框架的所有功能和灵活性。 为此,在“添加自定义新闻源”对话框中,只需单击“切换到高级模式”按钮即可。
最简单且通常最有效的定制是使用在线文章的印刷版。 印刷版通常没有那么繁琐,并且可以更顺利地转换为电子书。 让我们尝试使用 The BBC 文章的印刷版。
使用 bbc.co.uk 的印刷版¶
第一步是查看我们之前从“bbc”下载的电子书。 在电子书中每篇文章的末尾都有一个小简介,告诉您该文章是从哪里下载的。 将该 URL 复制并粘贴到浏览器中。 现在,在文章网页上查找指向“可打印版本”的链接。 单击它可查看文章的打印版本。 看起来整洁多了! 现在比较两个 URL。 对我来说,他们是:
所以看起来要获取打印版本,我们需要在每篇文章的 URL 前加上以下前缀:
newsvote.bbc.co.uk/mpapps/pagetools/print/
现在,在“自定义新闻源”对话框的“高级模式”中,您应该看到类似的内容(请记住在切换到高级模式之前选择 The BBC 菜谱):
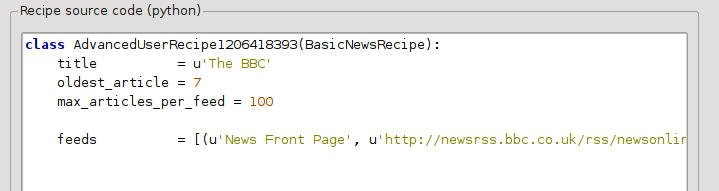
您可以看到“基本模式”中的字段已以简单的方式转换为 Python 代码。 我们需要向此新闻源添加说明以使用文章的打印版本。 所需要做的就是添加以下两行:
def print_version(self, url):
return url.replace('https://', 'https://newsvote.bbc.co.uk/mpapps/pagetools/print/')
这是Python,所以缩进很重要。 添加这些行后,它应该如下所示:
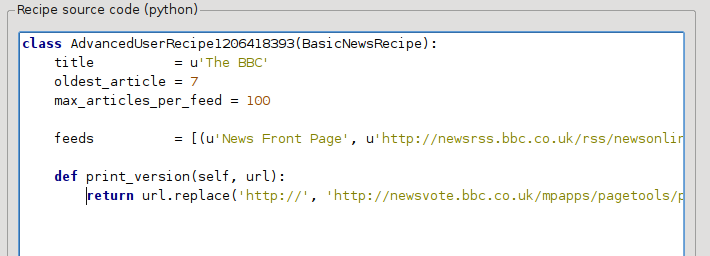
在上面,“def print_version(self, url)”定义了一个由 calibre 为每篇文章调用的*方法*。 url 是原始文章的 URL。 print_version 的作用是获取该 url 并将其替换为指向文章打印版本的新 URL。 要了解“Python <https://www.python.org>”_,请参阅“教程 <https://docs.python.org/tutorial/>”_。
现在,单击“添加/更新新闻源”按钮,您的更改将被保存。 重新下载电子书。 你应该有一本改进了很多的电子书。 新版本的问题之一是印刷版网页上的字体太小。 当转换为电子书时,此问题会自动修复,但即使在修复过程之后,菜单和导航栏的字体大小相对于文章文本也变得太大。 为了解决这个问题,我们将在下一节中进行更多自定义。
替换文章样式¶
在上一节中,我们看到 The BBC 印刷版文章的字体太小。 在大多数网站包括 BBC 中,此字体大小是通过“CSS”样式表设置的。 我们可以通过添加以下行来禁用此类样式表的获取:
no_stylesheets = True
新闻源现在看起来像:
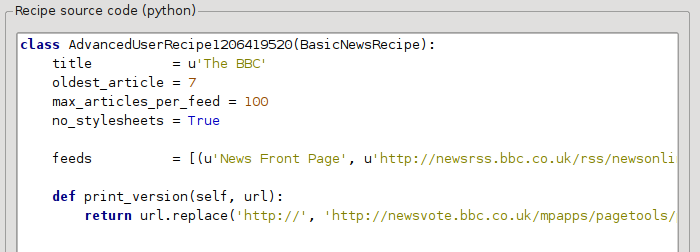
新版本看起来还不错。 如果您是完美主义者,您将需要阅读下一节,其中涉及实际修改下载的内容。
数据交叉分析¶
在操作下载内容方面,calibre 包含非常强大且灵活的功能。 为了展示其中的一些,让我们再次看看我们的老朋友“BBC <bbc1>”新闻源。 查看几篇文章(打印版)的源代码(“HTML”),我们看到它们的页脚不包含任何有用的信息,包含在
<div class="footer">
...
</div>
可以通过添加以下内容来删除它:
remove_tags = [dict(name='div', attrs={'class':'footer'})]
对新闻源。 最后,让我们用我们自己的适合转换为电子书的“CSS”替换我们之前禁用的一些“CSS”:
extra_css = '.headline {font-size: x-large;} \n .fact { padding-top: 10pt }'
通过这些添加,我们的配方已成为“生产质量”。
当谈到calibre的能力时,这个“秘诀”只探索了冰山一角。 为了探索 calibre 的更多功能,我们将在下一节中研究一个更复杂的现实生活示例。
现实生活中的例子¶
一个相当复杂的现实生活示例,公开了“BasicNewsRecipe”的更多“API”,是“纽约时报”的“recipe”
import string, re
from calibre import strftime
from calibre.web.feeds.recipes import BasicNewsRecipe
from calibre.ebooks.BeautifulSoup import BeautifulSoup
class NYTimes(BasicNewsRecipe):
title = 'The New York Times'
__author__ = 'Kovid Goyal'
description = 'Daily news from the New York Times'
timefmt = ' [%a, %d %b, %Y]'
needs_subscription = True
remove_tags_before = dict(id='article')
remove_tags_after = dict(id='article')
remove_tags = [dict(attrs={'class':['articleTools', 'post-tools', 'side_tool', 'nextArticleLink clearfix']}),
dict(id=['footer', 'toolsRight', 'articleInline', 'navigation', 'archive', 'side_search', 'blog_sidebar', 'side_tool', 'side_index']),
dict(name=['script', 'noscript', 'style'])]
encoding = 'cp1252'
no_stylesheets = True
extra_css = 'h1 {font: sans-serif large;}\n.byline {font:monospace;}'
def get_browser(self):
br = BasicNewsRecipe.get_browser(self)
if self.username is not None and self.password is not None:
br.open('https://www.nytimes.com/auth/login')
br.select_form(name='login')
br['USERID'] = self.username
br['PASSWORD'] = self.password
br.submit()
return br
def parse_index(self):
soup = self.index_to_soup('https://www.nytimes.com/pages/todayspaper/index.html')
def feed_title(div):
return ''.join(div.findAll(text=True, recursive=False)).strip()
articles = {}
key = None
ans = []
for div in soup.findAll(True,
attrs={'class':['section-headline', 'story', 'story headline']}):
if ''.join(div['class']) == 'section-headline':
key = string.capwords(feed_title(div))
articles[key] = []
ans.append(key)
elif ''.join(div['class']) in ['story', 'story headline']:
a = div.find('a', href=True)
if not a:
continue
url = re.sub(r'\?.*', '', a['href'])
url += '?pagewanted=all'
title = self.tag_to_string(a, use_alt=True).strip()
description = ''
pubdate = strftime('%a, %d %b')
summary = div.find(True, attrs={'class':'summary'})
if summary:
description = self.tag_to_string(summary, use_alt=False)
feed = key if key is not None else 'Uncategorized'
if feed not in articles:
articles[feed] = []
if not 'podcasts' in url:
articles[feed].append(
dict(title=title, url=url, date=pubdate,
description=description,
content=''))
ans = self.sort_index_by(ans, {'The Front Page':-1, 'Dining In, Dining Out':1, 'Obituaries':2})
ans = [(key, articles[key]) for key in ans if key in articles]
return ans
def preprocess_html(self, soup):
refresh = soup.find('meta', {'http-equiv':'refresh'})
if refresh is None:
return soup
content = refresh.get('content').partition('=')[2]
raw = self.browser.open('https://www.nytimes.com'+content).read()
return BeautifulSoup(raw.decode('cp1252', 'replace'))
我们在这个“新闻源”中看到了几个新功能。 首先,我们有:
timefmt = ' [%a, %d %b, %Y]'
这会将创建的电子书首页上的显示时间设置为“日,日_数字月,年”格式。 请参阅“timefmt <calibre.web.feeds.news.BasicNewsRecipe.timefmt>”。
然后我们看到一组指令来清理下载的“HTML”:
remove_tags_before = dict(name='h1')
remove_tags_after = dict(id='footer')
remove_tags = ...
这些会删除第一个“<h1>”标签之前的所有内容以及第一个 id 为“footer”的标签之后的所有内容。 请参阅 remove_tags <calibre.web.feeds.news.BasicNewsRecipe.remove_tags>、remove_tags_before <calibre.web.feeds.news.BasicNewsRecipe.remove_tags_before>、`remove_tags_after <calibre.web.feeds.news.BasicNewsRecipe.remove_tags_after> `。
下一个有趣的功能是:
needs_subscription = True
...
def get_browser(self):
...
needs_subscription = True 告诉 calibre 该菜谱需要用户名和密码才能访问内容。 这会导致每当您尝试使用此配方时,calibre 都会要求输入用户名和密码。calibre.web.feeds.news.BasicNewsRecipe.get_browser 中的代码实际上登录了《纽约时报》网站。 登录后,calibre 将使用相同的已登录浏览器实例来获取所有内容。 请参阅 mechanize 以了解 get_browser 中的代码。
下一个新功能是“calibre.web.feeds.news.BasicNewsRecipe.parse_index”方法。 它的 工作是访问 https://www.nytimes.com/pages/todayspaper/index.html 并获取 todays 报纸中出现的文章列表。 虽然比简单地使用“RSS”更复杂,但该方法创建了一本与每日报纸非常接近的电子书。 parse_index 大量使用 BeautifulSoup 来解析日报网页。 如果您不喜欢 BeautifulSoup,您也可以使用其他更现代的解析器。 calibre 附带 lxml 和 html5lib,这是推荐的解析器。 要使用它们,请将对“index_to_soup()”的调用替换为以下内容:
raw = self.index_to_soup(url, raw=True)
# For html5lib
import html5lib
root = html5lib.parse(raw, namespaceHTMLElements=False, treebuilder='lxml')
# For the lxml html 4 parser
from lxml import html
root = html.fromstring(raw)
最后一个新功能是“calibre.web.feeds.news.BasicNewsRecipe.preprocess_html”方法。 它可用于对每个下载的 HTML 页面执行任意转换。 这里它用于绕过纽约时报在每篇文章之前向您展示的广告。
开发新新闻源的技巧¶
开发新新闻源的最佳方法是使用命令行界面。 使用您最喜欢的 Python 编辑器创建新闻源并将其保存到文件名为 “myrecipe.recipe”的文件中。 需要“.recipe”扩展名。 您可以使用此新闻源通过以下命令下载内容:
ebook-convert myrecipe.recipe .epub --test -vv --debug-pipeline debug
命令“ebook-convert”将下载所有网页并将它们保存到 EPUB 文件“myrecipe.epub”。 “-vv”选项使 ebook-convert 吐出大量有关其正在执行的操作的信息。 “ebook-convert-recipe-input --test”选项使其最多只能从两个提要中下载几篇文章。 此外,ebook-convert 会将下载的 HTML 放入“debug/input”文件夹中,其中“debug”是您在“ebook-convert --debug-pipeline”选项中指定的文件夹。
下载完成后,您可以通过在浏览器中打开文件 `debug/input/index.html`来查看下载的“HTML”。 一旦您对下载和预处理正确进行感到满意,您就可以生成不同格式的电子书,如下所示:
ebook-convert myrecipe.recipe myrecipe.epub
ebook-convert myrecipe.recipe myrecipe.mobi
...
如果您对自己的新闻源感到满意,并且您认为有足够的需求来证明将其包含在内置新闻源集中,请将您的新闻源发布在“calibre 新闻源论坛”<https://www.mobileread.com/forums/forumdisplay.php?f=228>`_ 与其他 calibre 用户分享。
备注
在 macOS 上,命令行工具位于 calibre 包内,例如,如果您在“/Applications”中安装了 calibre,则命令行工具位于“/Applications/calibre.app/Contents/MacOS/”中。
参见
- “生成/en/电子书转换”
所有电子书转换的命令行界面。
以后阅读¶
要了解有关使用“BasicNewsRecipe”中提供的某些工具编写高级食谱的更多信息,您应该查阅以下来源:
- “API文档<news_recipe>”
“BasicNewsRecipe” 类及其所有重要方法和字段的文档。
- BasicNewsRecipe
``基本新闻源``的源代码
- 内置新闻源
calibre自带的内置新闻源的源代码
- calibre 新闻源论坛
许多知识渊博的新闻源作家都在这里闲逛。
API文档¶
- 清单的API文档
BasicNewsRecipeBasicNewsRecipe.adeify_images()BasicNewsRecipe.image_url_processor()BasicNewsRecipe.print_version()BasicNewsRecipe.tag_to_string()BasicNewsRecipe.abort_article()BasicNewsRecipe.abort_recipe_processing()BasicNewsRecipe.add_toc_thumbnail()BasicNewsRecipe.canonicalize_internal_url()BasicNewsRecipe.cleanup()BasicNewsRecipe.clone_browser()BasicNewsRecipe.default_cover()BasicNewsRecipe.download()BasicNewsRecipe.extract_readable_article()BasicNewsRecipe.get_article_url()BasicNewsRecipe.get_browser()BasicNewsRecipe.get_cover_url()BasicNewsRecipe.get_extra_css()BasicNewsRecipe.get_feeds()BasicNewsRecipe.get_masthead_title()BasicNewsRecipe.get_masthead_url()BasicNewsRecipe.get_obfuscated_article()BasicNewsRecipe.get_url_specific_delay()BasicNewsRecipe.index_to_soup()BasicNewsRecipe.is_link_wanted()BasicNewsRecipe.parse_feeds()BasicNewsRecipe.parse_index()BasicNewsRecipe.populate_article_metadata()BasicNewsRecipe.postprocess_book()BasicNewsRecipe.postprocess_html()BasicNewsRecipe.preprocess_html()BasicNewsRecipe.preprocess_image()BasicNewsRecipe.preprocess_raw_html()BasicNewsRecipe.publication_date()BasicNewsRecipe.skip_ad_pages()BasicNewsRecipe.sort_index_by()BasicNewsRecipe.articles_are_obfuscatedBasicNewsRecipe.auto_cleanupBasicNewsRecipe.auto_cleanup_keepBasicNewsRecipe.browser_typeBasicNewsRecipe.center_navbarBasicNewsRecipe.compress_news_imagesBasicNewsRecipe.compress_news_images_auto_sizeBasicNewsRecipe.compress_news_images_max_sizeBasicNewsRecipe.conversion_optionsBasicNewsRecipe.cover_marginsBasicNewsRecipe.delayBasicNewsRecipe.descriptionBasicNewsRecipe.encodingBasicNewsRecipe.extra_cssBasicNewsRecipe.feedsBasicNewsRecipe.filter_regexpsBasicNewsRecipe.handle_gzipBasicNewsRecipe.ignore_duplicate_articlesBasicNewsRecipe.keep_only_tagsBasicNewsRecipe.languageBasicNewsRecipe.masthead_urlBasicNewsRecipe.match_regexpsBasicNewsRecipe.max_articles_per_feedBasicNewsRecipe.needs_subscriptionBasicNewsRecipe.no_stylesheetsBasicNewsRecipe.oldest_articleBasicNewsRecipe.preprocess_regexpsBasicNewsRecipe.publication_typeBasicNewsRecipe.recipe_disabledBasicNewsRecipe.recipe_specific_optionsBasicNewsRecipe.recursionsBasicNewsRecipe.remove_attributesBasicNewsRecipe.remove_empty_feedsBasicNewsRecipe.remove_javascriptBasicNewsRecipe.remove_tagsBasicNewsRecipe.remove_tags_afterBasicNewsRecipe.remove_tags_beforeBasicNewsRecipe.requires_versionBasicNewsRecipe.resolve_internal_linksBasicNewsRecipe.reverse_article_orderBasicNewsRecipe.scale_news_imagesBasicNewsRecipe.scale_news_images_to_deviceBasicNewsRecipe.simultaneous_downloadsBasicNewsRecipe.summary_lengthBasicNewsRecipe.template_cssBasicNewsRecipe.timefmtBasicNewsRecipe.timeoutBasicNewsRecipe.titleBasicNewsRecipe.use_embedded_content