 Cambia lingua
Cambia linguaAggiunta del tuo sito di notizie preferito¶
calibre ha un sistema potente, flessibile e facile da usare per scaricare notizie da Internet e convertirle in un e-book. Ciò che segue ti mostrerà, usando degli esempi, come ottenere notizie da vari siti web.
Per poter utilizzare questo sistema con cognizione di causa, segui gli esempi nell’ordine elencato qui sotto:
Recupero completamente automatico¶
Se la tua fonte di notizie è abbastanza semplice, calibre potrebbe essere in grado di utilizzarla in modo completamente automatico, e tutto ciò che dovrai fare è fornire l’URL. calibre raccoglie tutte le informazioni necessarie a scaricare una fonte di notizie in una ricetta. Per portare a conoscenza di calibre una fonte di notizie, devi creare una ricetta per essa. Vediamo alcuni esempi:
Il blog di calibre¶
Il blog di calibre è una raccolta di post che descrivono molte utili funzionalità di calibre in un modo semplice e accessibile ai nuovi utenti di calibre. Per poter scaricare questo blog in un e-book, ci affidiamo al feed RSS del blog:
http://blog.calibre-ebook.com/feeds/posts/default
Ho ottenuto l’URL dell’RSS cercando sotto a «Iscriviti a» in fondo alla pagina del blog e scegliendo Post → Atom. Per fare in modo che calibre scarichi i feed e li converta in un e-book, devi fare clic con il tasto destro del mouse sul pulsante Scarica notizie, poi sulla voce del menu Aggiungi una fonte di notizie personalizzata e infine sul pulsante Nuova ricetta. Dovrebbe aprirsi una finestra simile a quella mostrata qui sotto.
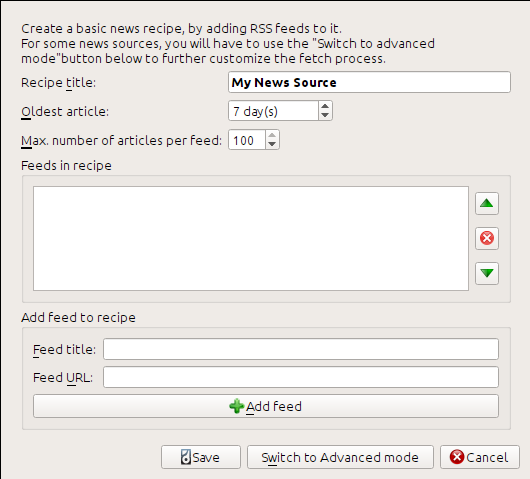
Per prima cosa inserisci Blog di calibre nel campo Titolo ricetta. Questo sarà il titolo dell’e-book creato dagli articoli dei feed qui sopra.
I due campi successivi (Articolo più vecchio and Numero massimo di articoli) ti permettono di controllare quanti (e quali) articoli debbano essere scaricati da ciascun feed, e non hanno bisogno di spiegazioni.
Per aggiungere i feed alla ricetta, inserisci titolo e URL del feed e fai clic sul pulsante Aggiungi feed. Una volta aggiunto il feed, basta fare clic sul pulsante Salva e avrai finito! Chiudi la finestra.
Per provare la tua nuova ricetta, fai clic sul pulsante Scarica notizie e nel sottomenu Fonti di notizie personalizzate su Blog di calibre. Dopo qualche minuto un nuovo e-book con i contenuti del blog apparirà nella vista principale della biblioteca (se il tuo lettore è connesso, apparirà nel lettore invece che nella biblioteca). Selezionalo e usa il pulsante Leggi per leggerlo!
Il motivo per cui tutto ha funzionato così bene e con così poco sforzo richiesto è che il blog mette a disposizione feed RSS di contenuto, ovverosia, il contenuto dell’articolo è incluso nel feed stesso. Per la maggior parte delle fonti di notizie organizzate in questo modo, con feed di contenuto, non è richiesto alcuno sforzo per convertirle in e-book. Ora daremo uno sguardo a una fonte di notizie che non fornisce feed di contenuto. In questi feed l’articolo completo è in una pagina web, mentre il feed contiene solo un collegamento alla pagina web con un breve riassunto dell’articolo.
bbc.co.uk¶
Proviamo con i seguenti due feed della BBC:
Segui la procedura descritta poco fa in Il blog di calibre per creare una ricetta per The BBC (utilizzando i feed qui sopra). Se diamo un’occhiata all’e-book scaricato, vediamo che calibre ha fatto un lavoro più che dignitoso nell’estrarre solamente i contenuti che ti interessano dalla pagina di ciascun articolo. Tuttavia, il processo di estrazione non è perfetto. A volte si porta dietro contenuti indesiderati come menu e aiuti di navigazione o rimuove contenuti che avrebbero dovuto essere lasciati intatti, come i titoli degli articoli. Per ottenere una perfetta estrazione dei contenuti, dovremo personalizzare il processo di recupero, come descritto nella sezione successiva.
Personalizzazione del processo di recupero¶
Se vuoi perfezionare il processo di scaricamento, o scaricare il contenuto di un sito web particolarmente complesso, puoi fare uso di tutta la potenza e flessibilità del sistema delle ricetta. Per fare ciò, devi solo fare clic sul pulsante Passa alla modalità avanzata nella finestra Aggiungi fonti di notizie personalizzate.
La personalizzazione più semplice, e spesso anche la più efficace, è quella di usare la versione di stampa degli articoli online. La versione di stampa ha spesso molti meno fronzoli, e si adatta molto meglio ad essere convertita in un e-book. Proviamo a utilizzare la versione di stampa degli articoli della BBC.
Uso della versione di stampa di bbc.co.uk¶
Il primo passo è dare un’occhiata all’e-book che abbiamo scaricato poco fa dalla bbc.co.uk. In fondo ad ogni articolo nell’e-book c’è una piccola nota che ti dice da dove l’articolo in questione è stato scaricato. Copia e incolla quell’URL nel browser. Ora, nella pagina dell’articolo, cerca un collegamento che indichi la «Printable version». Fai clic per vedere la versione di stampa dell’articolo. Ha un aspetto decisamente migliore! Ora confronta i due URL. Nel mio caso erano:
Sembra quindi che, per ottenere la versione di stampa, dobbiamo anteporre ad ogni URL di articolo ciò che segue:
newsvote.bbc.co.uk/mpapps/pagetools/print/
Ora nella Modalità avanzata della finestra Fonti di notizie personalizzate, dovresti vedere qualcosa di simile a questo (ricorda di selezionare la ricetta The BBC prima di passare alla modalità avanzata):
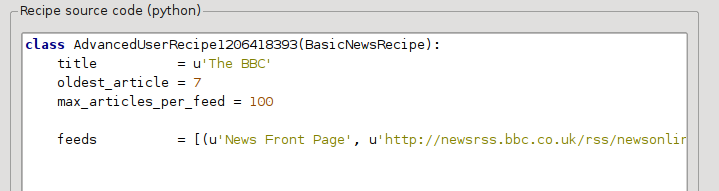
Puoi vedere che i campi della Modalità base sono stati tradotti in codice Python in un modo chiaro e trasparente. Dobbiamo aggiungere istruzioni a questa ricetta perché utilizzi la versione di stampa degli articoli. Tutto ciò che serve è aggiungere le seguenti due righe:
def print_version(self, url):
return url.replace('https://', 'https://newsvote.bbc.co.uk/mpapps/pagetools/print/')
Stiamo usando Python, perciò i rientri sono importanti. Dopo aver aggiunto le righe, il risultato dovrebbe essere:
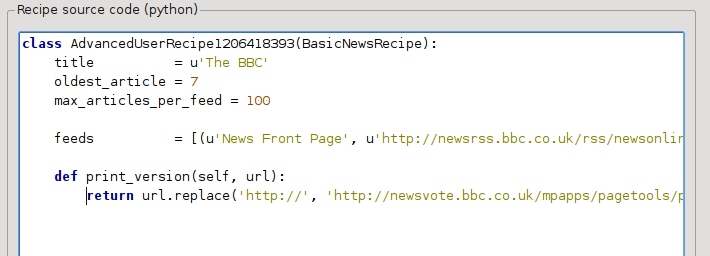
Qui def print_version(self, url) definisce un metodo che viene chiamato da calibre per ogni articolo. url è l’URL dell’articolo originale. Quello che print_version fa è prendere quell’url e sostituirlo con il nuovo URL che rimanda alla versione di stampa dell’articolo. Per conoscere meglio Python vedi il tutorial.
Ora fai clic sul pulsante Aggiungi/aggiorna ricetta e i tuoi cambiamenti saranno salvati. Riscarica l’e-book. Dovresti ottenere un e-book molto migliore. Uno dei problemi della nuova versione è che i caratteri della versione di stampa sono troppo piccoli. Questo problema è automaticamente risolto durante la conversione in e-book, ma anche dopo questo processo, la dimensione dei caratteri dei menu e della barra di navigazione diventa troppo grande rispetto al testo dell’articolo. Per ovviare a questo nuovo problema, ci serviranno delle personalizzazioni aggiuntive, che vediamo nella prossima sezione.
Sostituire gli stili dell’articolo¶
Nella sezione precedente abbiamo visto che la dimensione dei caratteri negli articoli della BBC in versione di stampa era troppo piccola. Nella maggior parte dei siti web, BBC inclusa, questa dimensione è impostata tramite fogli di stile CSS. Possiamo disabilitare lo scaricamento di tali fogli di stile aggiungendo la riga:
no_stylesheets = True
La ricetta è ora diventata:
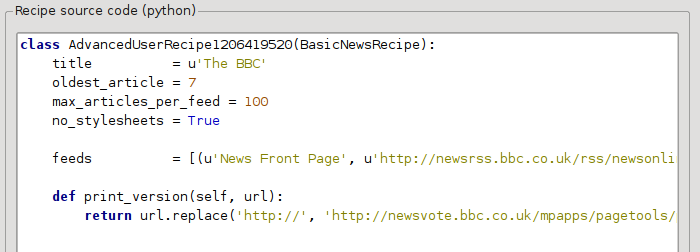
La nuova versione ha un aspetto più che accettabile. Se sei un perfezionista vorrai leggere la prossima sezione, che si occupa della modifica effettiva del contenuto scaricato.
Rifinitura dei contenuti¶
calibre può far uso di abilità molto potenti e flessibili per quanto riguarda la manipolazione del contenuto scaricato. Per mostrarne un paio ritorniamo alla nostra vecchia conoscenza, la ricetta per The BBC. Osservando il codice sorgente (HTML) di un paio di articoli (versione di stampa), notiamo che hanno un piè di pagina privo di informazioni utili, racchiuso in
<div class="footer">
...
</div>
Questo piè di pagina essere rimosso aggiungendo:
remove_tags = [dict(name='div', attrs={'class':'footer'})]
to the recipe. Finally, let’s replace some of the CSS that we disabled earlier, with our own CSS that is suitable for conversion to an e-book:
extra_css = '.headline {font-size: x-large;} \n .fact { padding-top: 10pt }'
Con queste aggiunte, la nostra ricetta ha raggiunto una quailtà ottimale.
Questa ricetta è solo la punta dell’iceberg della potenza di calibre. Per esplorare una parte maggiore delle capacità di calibre, nella prossima sezione esamineremo un caso reale più complesso.
Un caso reale¶
Un esempio reale ragionevolmente complesso che presenta una parte maggiore dell’API di BasicNewsRecipe è la ricetta per il New York Times
import string, re
from calibre import strftime
from calibre.web.feeds.recipes import BasicNewsRecipe
from calibre.ebooks.BeautifulSoup import BeautifulSoup
class NYTimes(BasicNewsRecipe):
title = 'The New York Times'
__author__ = 'Kovid Goyal'
description = 'Daily news from the New York Times'
timefmt = ' [%a, %d %b, %Y]'
needs_subscription = True
remove_tags_before = dict(id='article')
remove_tags_after = dict(id='article')
remove_tags = [dict(attrs={'class':['articleTools', 'post-tools', 'side_tool', 'nextArticleLink clearfix']}),
dict(id=['footer', 'toolsRight', 'articleInline', 'navigation', 'archive', 'side_search', 'blog_sidebar', 'side_tool', 'side_index']),
dict(name=['script', 'noscript', 'style'])]
encoding = 'cp1252'
no_stylesheets = True
extra_css = 'h1 {font: sans-serif large;}\n.byline {font:monospace;}'
def get_browser(self):
br = BasicNewsRecipe.get_browser(self)
if self.username is not None and self.password is not None:
br.open('https://www.nytimes.com/auth/login')
br.select_form(name='login')
br['USERID'] = self.username
br['PASSWORD'] = self.password
br.submit()
return br
def parse_index(self):
soup = self.index_to_soup('https://www.nytimes.com/pages/todayspaper/index.html')
def feed_title(div):
return ''.join(div.findAll(text=True, recursive=False)).strip()
articles = {}
key = None
ans = []
for div in soup.findAll(True,
attrs={'class':['section-headline', 'story', 'story headline']}):
if ''.join(div['class']) == 'section-headline':
key = string.capwords(feed_title(div))
articles[key] = []
ans.append(key)
elif ''.join(div['class']) in ['story', 'story headline']:
a = div.find('a', href=True)
if not a:
continue
url = re.sub(r'\?.*', '', a['href'])
url += '?pagewanted=all'
title = self.tag_to_string(a, use_alt=True).strip()
description = ''
pubdate = strftime('%a, %d %b')
summary = div.find(True, attrs={'class':'summary'})
if summary:
description = self.tag_to_string(summary, use_alt=False)
feed = key if key is not None else 'Uncategorized'
if feed not in articles:
articles[feed] = []
if not 'podcasts' in url:
articles[feed].append(
dict(title=title, url=url, date=pubdate,
description=description,
content=''))
ans = self.sort_index_by(ans, {'The Front Page':-1, 'Dining In, Dining Out':1, 'Obituaries':2})
ans = [(key, articles[key]) for key in ans if key in articles]
return ans
def preprocess_html(self, soup):
refresh = soup.find('meta', {'http-equiv':'refresh'})
if refresh is None:
return soup
content = refresh.get('content').partition('=')[2]
raw = self.browser.open('https://www.nytimes.com'+content).read()
return BeautifulSoup(raw.decode('cp1252', 'replace'))
Ci sono parecchie nuove caratteristiche in questa ricetta. Come prima cosa abbiamo:
timefmt = ' [%a, %d %b, %Y]'
Questa riga fa in modo che la data mostrata nella prima pagina dell’e-book creato sia nel formato Giorno, Numero_Giorno Mese, Anno. Vedi timefmt.
Segue un gruppo di direttive atte a ripulire l”HTML scaricato:
remove_tags_before = dict(name='h1')
remove_tags_after = dict(id='footer')
remove_tags = ...
Queste direttive rimuovono tutto ciò che precede il primo tag <h1> e tutto ciò che segue il primo tag con id footer. Vedi remove_tags, remove_tags_before, remove_tags_after.
La prossima caratteristica interessante è:
needs_subscription = True
...
def get_browser(self):
...
needs_subscription = True dice a calibre che questa ricetta ha bisogno di un nome utente e di una password per poter accedere al contenuto. La conseguenza è che calibre chiederà un nome utente e una password ogni volta che provi a usare questa ricetta. Il codice in calibre.web.feeds.news.BasicNewsRecipe.get_browser() è quello che effettua effettivamente l’accesso al sito del NYT. Una volta dentro, calibre utilizzerà la stessa istanza del browser, connessa al sito, per recuperare tutto il contenuto. Vedi mechanize per comprendere il codice di get_browser.
The next new feature is the
calibre.web.feeds.news.BasicNewsRecipe.parse_index() method. Its job is
to go to https://www.nytimes.com/pages/todayspaper/index.html and fetch the list
of articles that appear in today’s paper. While more complex than simply using
RSS, the recipe creates an e-book that corresponds very closely to the
day’s paper. parse_index makes heavy use of BeautifulSoup to parse
the daily paper webpage. You can also use other, more modern parsers if you
dislike BeautifulSoup. calibre comes with lxml and
html5lib, which are the
recommended parsers. To use them, replace the call to index_to_soup() with
the following:
raw = self.index_to_soup(url, raw=True)
# For html5lib
import html5lib
root = html5lib.parse(raw, namespaceHTMLElements=False, treebuilder='lxml')
# For the lxml html 4 parser
from lxml import html
root = html.fromstring(raw)
L’ultima nuova caratteristica è il metodo calibre.web.feeds.news.BasicNewsRecipe.preprocess_html(). Può essere usato per eseguire trasformazioni arbitrarie su tutte le pagine HTML scaricate. Qui viene impiegato per aggirare le pubblicità che il nytimes ti mostra prima di ogni articolo.
Suggerimenti per lo sviluppo di nuove ricette¶
Il modo migliore per sviluppare nuove ricette è utilizzare l’interfaccia da linea di comando. Crea la ricetta utilizzando il tuo editor Python preferito e salvala in un file, ad esempio myrecipe.recipe. L’estensione .recipe è necessaria. Puoi scaricare del contenuto con questa ricetta usando il comando:
ebook-convert myrecipe.recipe .epub --test -vv --debug-pipeline debug
Il comando ebook-convert scaricherà tutte le pagine web e le salverà nel file EPUB myrecipe.epub. L’opzione -vv fa in modo che ebook-convert restituisca parecchie informazioni su quello che sta facendo. L’opzione ebook-convert-recipe-input --test limita lo scaricamento a un paio di articoli, da due feed al massimo. In più, ebook-convert porrà l’HTML scaricato nella cartella debug/input, dove debug è la cartella che hai specificato nell’opzione ebook-convert --debug-pipeline.
Una volta completato lo scaricamento, puoi guardare l’HTML scaricato aprendo il file debug/input/index.html in un browser. Una volta verificato che lo scaricamento e la pre-elaborazione stiano avvenendo correttamente, puoi generare e-book in diversi formati come mostrato di seguito:
ebook-convert myrecipe.recipe myrecipe.epub
ebook-convert myrecipe.recipe myrecipe.mobi
...
Se sei soddisfatto della tua ricetta e ritieni che ci sia abbastanza richiesta da giustificarne l’inclusione nel novero delle ricette integrate, pubblica la tua ricetta nel forum delle ricette di calibre per condividerla con altri utenti di calibre.
Nota
In macOS, gli strumenti da linea di comando si trovano dentro il bundle di calibre, per esempio, se hai installato calibre in /Applications gli strumenti si trovano in /Applications/calibre.app/Contents/MacOS/.
Vedi anche
- ebook-convert
L’interfaccia da linea di comando per tutte le conversioni di e-book.
Ulteriori approfondimenti¶
Per saperne di più sulla produzione di ricette avanzate usando alcune delle funzioni disponibili in BasicNewsRecipe, consulta le fonti seguenti:
- Documentazione API
Documentazione della classe
BasicNewsRecipee di tutti i suoi metodi e campi importanti.- BasicNewsRecipe
Il codice sorgente di
BasicNewsRecipe- Ricette integrate
Il codice sorgente per le ricette integrate in calibre
- Il forum delle ricette di calibre <https://www.mobileread.com/forums/forumdisplay.php?f=228>`_
Qui si trovano parecchi esperti scrittori di ricette per calibre.
Documentazione API¶
- Documentazione API per le ricette
BasicNewsRecipeBasicNewsRecipe.adeify_images()BasicNewsRecipe.image_url_processor()BasicNewsRecipe.print_version()BasicNewsRecipe.tag_to_string()BasicNewsRecipe.abort_article()BasicNewsRecipe.abort_recipe_processing()BasicNewsRecipe.add_toc_thumbnail()BasicNewsRecipe.canonicalize_internal_url()BasicNewsRecipe.cleanup()BasicNewsRecipe.clone_browser()BasicNewsRecipe.default_cover()BasicNewsRecipe.download()BasicNewsRecipe.extract_readable_article()BasicNewsRecipe.get_article_url()BasicNewsRecipe.get_browser()BasicNewsRecipe.get_cover_url()BasicNewsRecipe.get_extra_css()BasicNewsRecipe.get_feeds()BasicNewsRecipe.get_masthead_title()BasicNewsRecipe.get_masthead_url()BasicNewsRecipe.get_obfuscated_article()BasicNewsRecipe.get_url_specific_delay()BasicNewsRecipe.index_to_soup()BasicNewsRecipe.is_link_wanted()BasicNewsRecipe.parse_feeds()BasicNewsRecipe.parse_index()BasicNewsRecipe.populate_article_metadata()BasicNewsRecipe.postprocess_book()BasicNewsRecipe.postprocess_html()BasicNewsRecipe.preprocess_html()BasicNewsRecipe.preprocess_image()BasicNewsRecipe.preprocess_raw_html()BasicNewsRecipe.publication_date()BasicNewsRecipe.skip_ad_pages()BasicNewsRecipe.sort_index_by()BasicNewsRecipe.articles_are_obfuscatedBasicNewsRecipe.auto_cleanupBasicNewsRecipe.auto_cleanup_keepBasicNewsRecipe.browser_typeBasicNewsRecipe.center_navbarBasicNewsRecipe.compress_news_imagesBasicNewsRecipe.compress_news_images_auto_sizeBasicNewsRecipe.compress_news_images_max_sizeBasicNewsRecipe.conversion_optionsBasicNewsRecipe.cover_marginsBasicNewsRecipe.delayBasicNewsRecipe.descriptionBasicNewsRecipe.encodingBasicNewsRecipe.extra_cssBasicNewsRecipe.feedsBasicNewsRecipe.filter_regexpsBasicNewsRecipe.handle_gzipBasicNewsRecipe.ignore_duplicate_articlesBasicNewsRecipe.keep_only_tagsBasicNewsRecipe.languageBasicNewsRecipe.masthead_urlBasicNewsRecipe.match_regexpsBasicNewsRecipe.max_articles_per_feedBasicNewsRecipe.needs_subscriptionBasicNewsRecipe.no_stylesheetsBasicNewsRecipe.oldest_articleBasicNewsRecipe.preprocess_regexpsBasicNewsRecipe.publication_typeBasicNewsRecipe.recipe_disabledBasicNewsRecipe.recipe_specific_optionsBasicNewsRecipe.recursionsBasicNewsRecipe.remove_attributesBasicNewsRecipe.remove_empty_feedsBasicNewsRecipe.remove_javascriptBasicNewsRecipe.remove_tagsBasicNewsRecipe.remove_tags_afterBasicNewsRecipe.remove_tags_beforeBasicNewsRecipe.requires_versionBasicNewsRecipe.resolve_internal_linksBasicNewsRecipe.reverse_article_orderBasicNewsRecipe.scale_news_imagesBasicNewsRecipe.scale_news_images_to_deviceBasicNewsRecipe.simultaneous_downloadsBasicNewsRecipe.summary_lengthBasicNewsRecipe.template_cssBasicNewsRecipe.timefmtBasicNewsRecipe.timeoutBasicNewsRecipe.titleBasicNewsRecipe.use_embedded_content