 Cambiar idioma
Cambiar idiomaAñadir su sitio de noticias favorito¶
calibre tiene un estructura potente, flexible y fácil de usar para descargar noticias de Internet y convertirlas en un libro electrónico. A continuación se le mostrará, a través de ejemplos, cómo acceder a las noticias de varios sitios de Internet.
Para comprender mejor cómo utilizar la estructura, siga los ejemplos en el orden indicado a continuación:
Recopilación totalmente automática¶
Si la fuente de noticias es suficientemente simple, es posible que calibre sea capaz de obtener las noticias de forma totalmente automática, todo lo que tiene que hacer es proporcionar el URL. calibre reúne toda la información necesaria para descargar una fuente de noticias en una fórmula. Si quiere añadir una fuente de noticias en calibre, debe crear una fórmula para ello. Veamos algunos ejemplos:
El blog de calibre¶
El blog de calibre es un blog de mensajes que describen varias características útiles de calibre de una manera sencilla y accesible para los nuevos usuarios de calibre. Para descargar este blog en un libro electrónico, nos basamos en el RSS del blog:
http://blog.calibre-ebook.com/feeds/posts/default
Obtenemos la dirección URL del RSS de la sección «Subscribe to» al final de la página del blog, eligiendo «Posts > Atom». Para hacer que calibre descargue los canales y los convierta en un libro electrónico, debe pulsar con el botón derecho en el botón Obtener noticias y luego el elemento del menú Añadir una nueva fuente de noticias y el botón Nueva fórmula. Se abrirá un cuadro de diálogo similar al que se muestra a continuación.
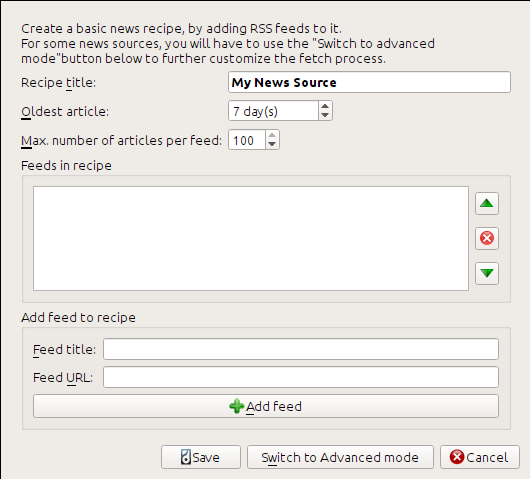
Primero introduzca Blog de calibre dentro del campo Título de la fórmula. Éste será el título del libro electrónico que se creará a partir de los artículos provenientes de los canales anteriores.
Los dos campos siguientes (Artículo más antiguo y Número máximo de artículos por canal) le permiten controlar cuántos artículos se descargan desde cada canal, ambos son suficientemente explícitos.
Para añadir los canales a la fórmula, introduzca el título y dirección URL del canal y pulse en el botón Añadir canal. Una vez añadido el canal, simplemente pulse en el botón Añadir o actualizar fórmula ¡y ya está! Cierre el cuadro de diálogo.
Para probar la nueva fórmula, pulse en el botón Obtener noticias, en el submenú Personalizado, y en Blog de calibre. En un par de minutos, el nuevo libro electrónico descargado con las entradas al blog aparecerá en la biblioteca principal (si tiene conectado un dispositivo de lectura, aparecerá en él en vez de la biblioteca). Selecciónelo y pulse en el botón Mostrar para leerlo.
La razón por la que esto funcionó tan bien, con tan poco esfuerzo, es que el blog proporciona una fuente RSS con el contenido completo, es decir, el contenido del artículo está incrustado en el propio canal de información. Para la mayoría de las fuentes de noticias que proporcionan noticias de esta manera, con un canal RSS con el contenido completo, no necesitará mayores esfuerzos para convertirlas en libros electrónicos. Ahora veremos en una fuente de noticias que no proporciona un canal de noticias RSS con el contenido completo. En dichos canales, el artículo completo es una página de Internet y el canal de información RSS sólo contiene un enlace a la página con un breve resumen del artículo.
bbc.co.uk¶
Vamos a probar los siguentes dos canales de The BBC:
Portal de noticias: https://newsrss.bbc.co.uk/rss/newsonline_world_edition/front_page/rss.xml
Ciencia y naturaleza: https://newsrss.bbc.co.uk/rss/newsonline_world_edition/science/nature/rss.xml
Siga el procedimiento descrito anteriormente en El blog de calibre para crear una fórmula para La BBC (usando los canales RSS mencionados más arriba). Al examinar el libro electrónico descargado, vemos que calibre ha hecho un trabajo encomiable al extraer sólo el contenido que significativo de la página de Internet de cada artículo. Sin embargo, el proceso de extracción no es perfecto. A veces quedan contenidos no deseados como los menús y las ayudas a la navegación o se elimina contenido que debería haber sido mantenido, como las cabeceras de los artículos. Para que la extracción de contenido sea perfecta, tendremos que personalizar el proceso de Obtención, como se describe en la siguiente sección.
Personalizar el proceso de obtención¶
Cuando desea perfeccionar el proceso de descarga, o descargar el contenido de un sitio de Internet particularmente complejo, puede servirse de toda la potencia y flexibilidad de la estructura de una fórmula. Con ese fin, en el cuadro de diálogo Añadir nueva fuente de noticias, simplemente pulse en el botón Cambiar a modo avanzado.
La personalización más fácil y a menudo más productiva es el uso de la versión para imprimir de los artículos en línea. La versión para imprimir normalmente tiene mucho menos contenido superfluo y se transforma de maner más fluida en un libro electrónico. Vamos a tratar de utilizar la versión impresa de los artículos de La BBC.
Usar la versión para imprimir de bbc.co.uk¶
El primer paso es buscar en el libro electrónico que descargamos previamente de bbc.co.uk. Al final de cada artículo, en el libro electrónico, hay una pequeña reseña que dice desde dónde ha sido descargado el artículo. Copie y pegue la dirección URL en un navegador. Ahora en la página de Internet del artículo, busque un enlace que apunta a la «Versión para imprimir». Pulse en él para ver la versión para imprimir del artículo. ¡Es mucho más limpia! Ahora compare ambas direcciones URL. En mi caso eran:
- URL del artículo
- URL de la versión para imprimir
https://newsvote.bbc.co.uk/mpapps/pagetools/print/news.bbc.co.uk/2/hi/science/nature/7312016.stm
Así que parece que para obtener la versión para imprimir, tenemos que poner delante de cada URL de artículo:
newsvote.bbc.co.uk/mpapps/pagetools/print/
Ahora en el Modo avanzado cuadro de diálogo de nuevas fuentes de noticias, debería ver algo así (recuerde seleccionar la fórmula La BBC antes de cambiar al modo avanzado):
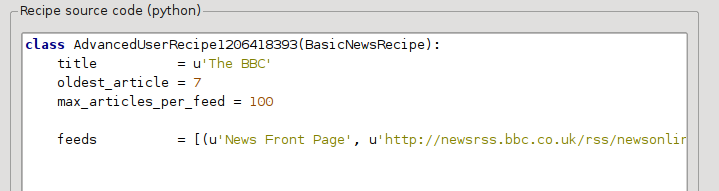
Se puede ver que los campos del Modo básico han sido traducidos a código Python de una manera directa. Necesitamos añadir instrucciones para que esta fórmula utilice la versión para imprimir de los artículos. Todo lo que se necesita es añadir las siguientes dos líneas:
def print_version(self, url):
return url.replace('https://', 'https://newsvote.bbc.co.uk/mpapps/pagetools/print/')
Esto es Python, por lo que la sangría es importante. Después de añadir las líneas, debe ser algo así:
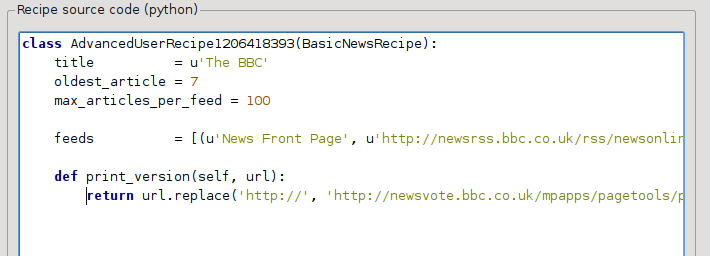
En lo anterior, def print_version(self, url) define un método que es utilizado por calibre para cada artículo. url es la dirección URL del artículo original. Lo que hace print_version es tomar la dirección URL y sustituirla por la nueva dirección URL que apunta a la versión para imprimir del artículo. Para aprender sobre Python vea el cursillo (en inglés).
Ahora pulse en el botón Añadir o actualizar fórmula y se guardarán los cambios. Vuelva a descargar el libro electrónico. Ahora debe tener un libro electrónico muy mejorado. Uno de los problemas con la nueva versión es que los tipos de letra en la página de Internet de la versión impresa son demasiado pequeños. Esto es corregido automáticamente cuando se convierte a un libro electrónico, pero incluso después del proceso de corrección, el tamaño de la letra de los menús y barra de navegación es demasiado grande en relación con el texto del artículo. Para solucionar esto, vamos a personalizar un poco más, en la siguiente sección.
Sustituir los estilos de los artículos¶
En la sección anterior, hemos visto que el tamaño de letra para los artículos de la versión impresa de La BBC era demasiado pequeño. En la mayoría de sitios de Internet, incluido La BBC, el tamaño de letra se establece por medio de las hojas de estilo CSS. Podemos desactivar la obtención de dichas hojas de estilo añadiendo esta línea:
no_stylesheets = True
La fórmula queda ahora como:
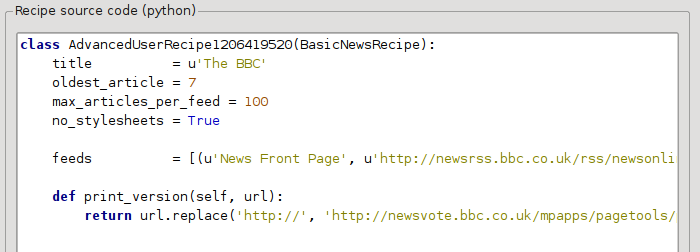
La nueva versión está bastante bien. Si es usted perfeccionista, querrá leer la siguiente sección, que trata de hacer cambios en el contenido descargado.
Dividir y reordenar¶
calibre contiene funciones muy poderosas y flexibles a la hora de manipular el contenido descargado. Para mostrar un par de ellas, echemos un nuevo vistazo a nuestra vieja amiga, la fórmula La BBC. Mirando el código fuente (HTML) de un par de artículos (versiones para imprimir), vemos que tienen un pie de página que no contiene ninguna información útil, que figura en
<div class="footer">
...
</div>
Esto se puede quitar agregando:
remove_tags = [dict(name='div', attrs={'class':'footer'})]
A la receta. Finalmente, reemplacemos algunos de los CSS que desactivamos anteriormente con nuestro propio CSS, apto para la conversión a libro electrónico:
extra_css = '.headline {font-size: x-large;} \n .fact { padding-top: 10pt }'
Con estos añadidos, nuestra fórmula ha alcanzado «calidad de producción».
Esta fórmula muestra sólo la punta del iceberg en lo que se refiere a la potencia de calibre. Para explorar más sobre las capacidades de calibre, examinaremos un ejemplo de la vida real más complejo en la siguiente sección.
Ejemplo de la vida real¶
Un ejemplo real bastante complejo que expone más partes de la API de BasicNewsRecipe es la fórmula de The New York Times
import string, re
from calibre import strftime
from calibre.web.feeds.recipes import BasicNewsRecipe
from calibre.ebooks.BeautifulSoup import BeautifulSoup
class NYTimes(BasicNewsRecipe):
title = 'The New York Times'
__author__ = 'Kovid Goyal'
description = 'Daily news from the New York Times'
timefmt = ' [%a, %d %b, %Y]'
needs_subscription = True
remove_tags_before = dict(id='article')
remove_tags_after = dict(id='article')
remove_tags = [dict(attrs={'class':['articleTools', 'post-tools', 'side_tool', 'nextArticleLink clearfix']}),
dict(id=['footer', 'toolsRight', 'articleInline', 'navigation', 'archive', 'side_search', 'blog_sidebar', 'side_tool', 'side_index']),
dict(name=['script', 'noscript', 'style'])]
encoding = 'cp1252'
no_stylesheets = True
extra_css = 'h1 {font: sans-serif large;}\n.byline {font:monospace;}'
def get_browser(self):
br = BasicNewsRecipe.get_browser(self)
if self.username is not None and self.password is not None:
br.open('https://www.nytimes.com/auth/login')
br.select_form(name='login')
br['USERID'] = self.username
br['PASSWORD'] = self.password
br.submit()
return br
def parse_index(self):
soup = self.index_to_soup('https://www.nytimes.com/pages/todayspaper/index.html')
def feed_title(div):
return ''.join(div.findAll(text=True, recursive=False)).strip()
articles = {}
key = None
ans = []
for div in soup.findAll(True,
attrs={'class':['section-headline', 'story', 'story headline']}):
if ''.join(div['class']) == 'section-headline':
key = string.capwords(feed_title(div))
articles[key] = []
ans.append(key)
elif ''.join(div['class']) in ['story', 'story headline']:
a = div.find('a', href=True)
if not a:
continue
url = re.sub(r'\?.*', '', a['href'])
url += '?pagewanted=all'
title = self.tag_to_string(a, use_alt=True).strip()
description = ''
pubdate = strftime('%a, %d %b')
summary = div.find(True, attrs={'class':'summary'})
if summary:
description = self.tag_to_string(summary, use_alt=False)
feed = key if key is not None else 'Uncategorized'
if feed not in articles:
articles[feed] = []
if not 'podcasts' in url:
articles[feed].append(
dict(title=title, url=url, date=pubdate,
description=description,
content=''))
ans = self.sort_index_by(ans, {'The Front Page':-1, 'Dining In, Dining Out':1, 'Obituaries':2})
ans = [(key, articles[key]) for key in ans if key in articles]
return ans
def preprocess_html(self, soup):
refresh = soup.find('meta', {'http-equiv':'refresh'})
if refresh is None:
return soup
content = refresh.get('content').partition('=')[2]
raw = self.browser.open('https://www.nytimes.com'+content).read()
return BeautifulSoup(raw.decode('cp1252', 'replace'))
Vemos varias características nuevas en esta fórmula. En primer lugar, tenemos:
timefmt = ' [%a, %d %b, %Y]'
Esto hace que la fecha que aparece en la primera página del libro electrónico creado se muestre en este formato, Día, Número de día Mes, Año. Vea: attr:timefmt <calibre.web.feeds.news.BasicNewsRecipe.timefmt>.
Después vemos un grupo de directivas para depurar el HTML descargado:
remove_tags_before = dict(name='h1')
remove_tags_after = dict(id='footer')
remove_tags = ...
Éstas eliminan todo lo que hay antes de la primera etiqueta <h1> y todo lo que hay después de la primera etiqueta cuyo id es footer. Véanse remove_tags, remove_tags_before, remove_tags_after.
La siguiente función interesante es:
needs_subscription = True
...
def get_browser(self):
...
needs_subscription = True le comunica a calibre que esta fórmula necesita un nombre de usuario y contraseña para poder acceder al contenido. Esto hace que calibre pida un nombre de usuario y contraseña cada vez que intente utilizar esta fórmula. El código en calibre.web.feeds.news.BasicNewsRecipe.get_browser() es el que realmente inicia la sesión en el sitio de Internet del New York Times. Una vez iniciada la sesión, calibre utilizará esta misma sesión para obtener todo el contenido. Véase mechanize para entender el código en get_browser.
La siguiente característica nueva es el método :meth:calibre.web.feeds.news.BasicNewsRecipe.parse_index. Su función es ir a https://www.nytimes.com/pages/todayspaper/index.html y obtener la lista de artículos que aparecen en el periódico de hoy. Aunque es más complejo que el simple uso de RSS, la receta crea un libro electrónico que se corresponde muy fielmente con el periódico del día. parse_index hace un uso intensivo de BeautifulSoup para analizar la página web del diario. También puedes utilizar otros analizadores más modernos si no te gusta BeautifulSoup. calibre incluye lxml y html5lib <https://github.com/html5lib/html5lib-python>_, que son los analizadores recomendados. Para utilizarlos, sustituye la llamada a index_to_soup() por lo siguiente:
raw = self.index_to_soup(url, raw=True)
# For html5lib
import html5lib
root = html5lib.parse(raw, namespaceHTMLElements=False, treebuilder='lxml')
# For the lxml html 4 parser
from lxml import html
root = html.fromstring(raw)
La última nueva característica es el método calibre.web.feeds.news.BasicNewsRecipe.preprocess_html(). Se puede utilizar para realizar transformaciones arbitrarias en cada página HTML descargada. Aquí se usa para evitar la publicidad que nytimes muestra antes de cada artículo.
Consejos para desarrollar nuevas fórmulas¶
La mejor manera de desarrollar nuevas fórmulas es utilizar la interfaz de línea de órdenes. Cree la fórmula usando su editor de Python favorito y guárdela en un archivo, digamos mifórmula.recipe. La extensión .recipe es necesaria. Puede descargar contenido usando esta fórmula con la orden:
ebook-convert myrecipe.recipe .epub --test -vv --debug-pipeline debug
La orden ebook-convert descargará todas las páginas de Internet y las guardará en el archivo EPUB mifórmula.epub. La opción -vv hace que ebook-convert muestre una gran cantidad de información acerca de lo que está haciendo. La opción ebook-convert-recipe-input --test hace que se descargue sólo un par de artículos de un máximo de dos canales RSS. Además, ebook-convert pondrá el HTML descargado en la carpeta debug/input, donde debug es la carpeta que haya especificado en la opción :option:`ebook-convert –debug-pipeline.
Una vez que la descarga está completa, puede ver el HTML descargado abriendo el archivo debug/input/index.html en un navegador. Cuando que esté satisfecho con la descarga y el procesado previo, puede generar libros electrónicos en diferentes formatos, como se muestra a continuación:
ebook-convert myrecipe.recipe myrecipe.epub
ebook-convert myrecipe.recipe myrecipe.mobi
...
Si está satisfecho con fórmula y cree que existe suficiente demanda para justificar su inclusión en el conjunto de fórmulas incorporadas, compártala en el Foro de fórmulas de calibre (en inglés).
Nota
En macOS, las herramientas de línea de órdenes están dentro del paquete calibre, por ejemplo, si ha instalado calibre en /Aplicaciones las herramientas de línea de órdenes están en :file:/Aplicaciones/calibre.app/Contents/MacOS/`.
Ver también
- ebook-convert
La interfaz de la línea de órdenes para todas las conversiones de libros electrónicos.
Lecturas adicionales¶
Para obtener más información acerca de cómo escribir fórmulas avanzadas usando algunas de las opciones disponibles en BasicNewsRecipe debe consultar las siguientes fuentes:
- Documentación de la API
La documentación de la clase
BasicNewsRecipey todos sus métodos y campos importantes.- BasicNewsRecipe
El código fuente de
BasicNewsRecipe- Fórmulas predefinidas
El código fuente de las fórmulas predefinidas que incluye calibre
- El foro de fórmulas de calibre (en inglés)
Un buen número de creadores de fórmulas de calibre pasan el rato aquí.
Documentación de la API¶
- Documentación de la API para fórmulas
BasicNewsRecipeBasicNewsRecipe.adeify_images()BasicNewsRecipe.image_url_processor()BasicNewsRecipe.print_version()BasicNewsRecipe.tag_to_string()BasicNewsRecipe.abort_article()BasicNewsRecipe.abort_recipe_processing()BasicNewsRecipe.add_toc_thumbnail()BasicNewsRecipe.canonicalize_internal_url()BasicNewsRecipe.cleanup()BasicNewsRecipe.clone_browser()BasicNewsRecipe.default_cover()BasicNewsRecipe.download()BasicNewsRecipe.extract_readable_article()BasicNewsRecipe.get_article_url()BasicNewsRecipe.get_browser()BasicNewsRecipe.get_cover_url()BasicNewsRecipe.get_extra_css()BasicNewsRecipe.get_feeds()BasicNewsRecipe.get_masthead_title()BasicNewsRecipe.get_masthead_url()BasicNewsRecipe.get_obfuscated_article()BasicNewsRecipe.get_url_specific_delay()BasicNewsRecipe.index_to_soup()BasicNewsRecipe.is_link_wanted()BasicNewsRecipe.parse_feeds()BasicNewsRecipe.parse_index()BasicNewsRecipe.populate_article_metadata()BasicNewsRecipe.postprocess_book()BasicNewsRecipe.postprocess_html()BasicNewsRecipe.preprocess_html()BasicNewsRecipe.preprocess_image()BasicNewsRecipe.preprocess_raw_html()BasicNewsRecipe.publication_date()BasicNewsRecipe.skip_ad_pages()BasicNewsRecipe.sort_index_by()BasicNewsRecipe.articles_are_obfuscatedBasicNewsRecipe.auto_cleanupBasicNewsRecipe.auto_cleanup_keepBasicNewsRecipe.browser_typeBasicNewsRecipe.center_navbarBasicNewsRecipe.compress_news_imagesBasicNewsRecipe.compress_news_images_auto_sizeBasicNewsRecipe.compress_news_images_max_sizeBasicNewsRecipe.conversion_optionsBasicNewsRecipe.cover_marginsBasicNewsRecipe.delayBasicNewsRecipe.descriptionBasicNewsRecipe.encodingBasicNewsRecipe.extra_cssBasicNewsRecipe.feedsBasicNewsRecipe.filter_regexpsBasicNewsRecipe.handle_gzipBasicNewsRecipe.ignore_duplicate_articlesBasicNewsRecipe.keep_only_tagsBasicNewsRecipe.languageBasicNewsRecipe.masthead_urlBasicNewsRecipe.match_regexpsBasicNewsRecipe.max_articles_per_feedBasicNewsRecipe.needs_subscriptionBasicNewsRecipe.no_stylesheetsBasicNewsRecipe.oldest_articleBasicNewsRecipe.preprocess_regexpsBasicNewsRecipe.publication_typeBasicNewsRecipe.recipe_disabledBasicNewsRecipe.recipe_specific_optionsBasicNewsRecipe.recursionsBasicNewsRecipe.remove_attributesBasicNewsRecipe.remove_empty_feedsBasicNewsRecipe.remove_javascriptBasicNewsRecipe.remove_tagsBasicNewsRecipe.remove_tags_afterBasicNewsRecipe.remove_tags_beforeBasicNewsRecipe.requires_versionBasicNewsRecipe.resolve_internal_linksBasicNewsRecipe.reverse_article_orderBasicNewsRecipe.scale_news_imagesBasicNewsRecipe.scale_news_images_to_deviceBasicNewsRecipe.simultaneous_downloadsBasicNewsRecipe.summary_lengthBasicNewsRecipe.template_cssBasicNewsRecipe.timefmtBasicNewsRecipe.timeoutBasicNewsRecipe.titleBasicNewsRecipe.use_embedded_content