 تغيير اللغة
تغيير اللغةإضافة موقعك الإخباري المفضل¶
يحتوي calibre على إطار عمل قوي ومرن وسهل الاستخدام لتنزيل الأخبار من الإنترنت وتحويلها إلى كتاب إلكتروني. سيوضح لك ما يلي، بواسطة الأمثلة، كيفية الحصول على الأخبار من مواقع الويب المختلفة.
لفهم كيفية استخدام الإطار، اتبع الأمثلة بالترتيب المذكور أدناه:
جلب تلقائي بالكامل¶
إذا كان مصدر أخبارك بسيطًا بما فيه الكفاية، فقد يتمكن calibre من جلبه تلقائيًا بالكامل، كل ما عليك فعله هو توفير عنوان URL. يجمع calibre جميع المعلومات اللازمة لتنزيل مصدر أخبار في وصفة. لإخبار calibre بمصدر أخبار، يجب عليك إنشاء وصفة له. دعنا نرى بعض الأمثلة:
مدونة calibre¶
مدونة calibre هي مدونة تحتوي على منشورات تصف العديد من ميزات calibre المفيدة بطريقة بسيطة ومتاحة لمستخدمي calibre الجدد. لتنزيل هذه المدونة في كتاب إلكتروني، نعتمد على خلاصة RSS للمدونة:
http://blog.calibre-ebook.com/feeds/posts/default
حصلت على عنوان URL لـ RSS بالبحث تحت "اشترك في" في أسفل صفحة المدونة واختيار المنشورات → Atom. لجعل calibre يقوم بتنزيل الخلاصات وتحويلها إلى كتاب إلكتروني، يجب عليك النقر بزر الفأرة الأيمن على زر جلب الأخبار ثم عنصر قائمة إضافة مصدر أخبار مخصص ثم زر وصفة جديدة. يجب أن يفتح مربع حوار مشابه لما هو موضح أدناه.
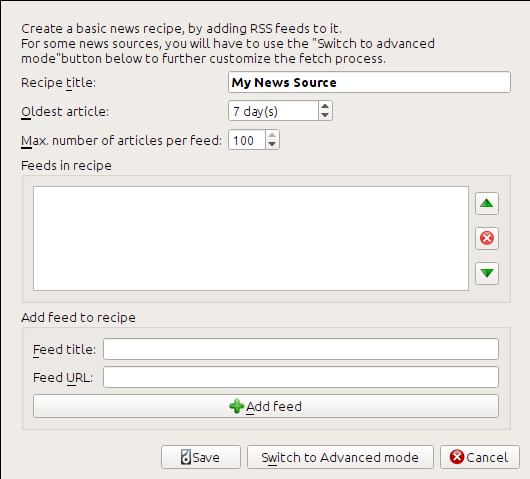
أولاً، أدخل مدونة calibre في حقل عنوان الوصفة. سيكون هذا هو عنوان الكتاب الإلكتروني الذي سيتم إنشاؤه من المقالات في الخلاصات المذكورة أعلاه.
الحقلان التاليان (أقدم مقال و الحد الأقصى لعدد المقالات) يمنحانك بعض التحكم في عدد المقالات التي يجب تنزيلها من كل خلاصة، وهما واضحان تمامًا.
لإضافة الخلاصات إلى الوصفة، أدخل عنوان الخلاصة وعنوان URL للخلاصة وانقر على زر إضافة خلاصة. بمجرد إضافة الخلاصة، ما عليك سوى النقر على زر حفظ وقد انتهيت! أغلق مربع الحوار.
لاختبار وصفتك الجديدة، انقر على زر جلب الأخبار وفي القائمة الفرعية مصادر الأخبار المخصصة، انقر على مدونة calibre. بعد بضع دقائق، سيظهر الكتاب الإلكتروني الذي تم تنزيله حديثًا من منشورات المدونة في عرض المكتبة الرئيسي (إذا كان جهاز القارئ الخاص بك متصلاً، فسيتم وضعه على القارئ بدلاً من المكتبة). حدده واضغط على زر عرض للقراءة!
السبب في نجاح هذا الأمر بهذا الشكل الجيد، وبجهد قليل، هو أن المدونة توفر خلاصات RSS كاملة المحتوى، أي أن محتوى المقال مضمن في الخلاصة نفسها. بالنسبة لمعظم مصادر الأخبار التي توفر الأخبار بهذه الطريقة، مع خلاصات كاملة المحتوى، لا تحتاج إلى مزيد من الجهد لتحويلها إلى كتب إلكترونية. الآن سننظر إلى مصدر أخبار لا يوفر خلاصات كاملة المحتوى. في مثل هذه الخلاصات، يكون المقال الكامل صفحة ويب وتحتوي الخلاصة فقط على رابط لصفحة الويب مع ملخص قصير للمقال.
bbc.co.uk¶
دعنا نجرب خلاصتي الأخبار التاليتين من بي بي سي:
الصفحة الرئيسية للأخبار: https://newsrss.bbc.co.uk/rss/newsonline_world_edition/front_page/rss.xml
العلوم/الطبيعة: https://newsrss.bbc.co.uk/rss/newsonline_world_edition/science/nature/rss.xml
اتبع الإجراء الموضح في مدونة calibre أعلاه لإنشاء وصفة لـ بي بي سي (باستخدام الخلاصات أعلاه). بالنظر إلى الكتاب الإلكتروني الذي تم تنزيله، نرى أن calibre قد قام بعمل جيد في استخراج المحتوى الذي تهتم به فقط من صفحة الويب لكل مقال. ومع ذلك، فإن عملية الاستخراج ليست مثالية. أحيانًا تترك محتوى غير مرغوب فيه مثل القوائم وأدوات التنقل أو تزيل محتوى كان يجب تركه، مثل عناوين المقالات. لكي يكون استخراج المحتوى مثاليًا، سنحتاج إلى تخصيص عملية الجلب، كما هو موضح في القسم التالي.
تخصيص عملية الجلب¶
عندما ترغب في تحسين عملية التنزيل، أو تنزيل المحتوى من موقع ويب معقد بشكل خاص، يمكنك الاستفادة من كل قوة ومرونة إطار عمل الوصفة. للقيام بذلك، في مربع حوار إضافة مصادر أخبار مخصصة، ما عليك سوى النقر على زر التبديل إلى الوضع المتقدم.
التخصيص الأسهل والأكثر إنتاجية غالبًا هو استخدام النسخة المطبوعة من المقالات عبر الإنترنت. تحتوي النسخة المطبوعة عادةً على فوضى أقل بكثير وتتحول بسلاسة أكبر إلى كتاب إلكتروني. دعنا نحاول استخدام النسخة المطبوعة من المقالات من بي بي سي.
استخدام النسخة المطبوعة من bbc.co.uk¶
الخطوة الأولى هي النظر إلى الكتاب الإلكتروني الذي قمنا بتنزيله سابقًا من bbc.co.uk. في نهاية كل مقال، في الكتاب الإلكتروني يوجد وصف قصير يخبرك من أين تم تنزيل المقال. انسخ والصق عنوان URL هذا في متصفح. الآن في صفحة الويب الخاصة بالمقال، ابحث عن رابط يشير إلى "النسخة القابلة للطباعة". انقر عليه لرؤية النسخة المطبوعة من المقال. تبدو أكثر أناقة بكثير! الآن قارن بين عنواني URL. بالنسبة لي كانا:
- عنوان URL للمقال
- عنوان URL للنسخة المطبوعة
https://newsvote.bbc.co.uk/mpapps/pagetools/print/news.bbc.co.uk/2/hi/science/nature/7312016.stm
لذلك يبدو أنه للحصول على النسخة المطبوعة، نحتاج إلى إضافة بادئة لكل عنوان URL للمقال بـ:
newsvote.bbc.co.uk/mpapps/pagetools/print/
الآن في الوضع المتقدم لمربع حوار مصادر الأخبار المخصصة، يجب أن ترى شيئًا مثل (تذكر تحديد وصفة بي بي سي قبل التبديل إلى الوضع المتقدم):
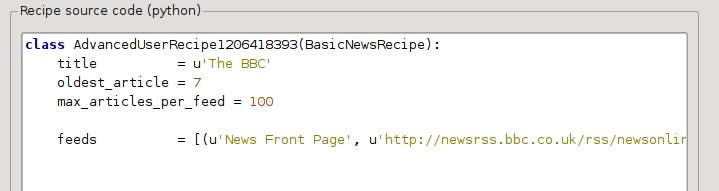
يمكنك أن ترى أن الحقول من الوضع الأساسي قد تم ترجمتها إلى كود بايثون بطريقة مباشرة. نحتاج إلى إضافة تعليمات إلى هذه الوصفة لاستخدام النسخة المطبوعة من المقالات. كل ما هو مطلوب هو إضافة السطرين التاليين:
def print_version(self, url):
return url.replace('https://', 'https://newsvote.bbc.co.uk/mpapps/pagetools/print/')
هذه لغة بايثون، لذا المسافة البادئة مهمة. بعد إضافة الأسطر، يجب أن تبدو كالتالي:
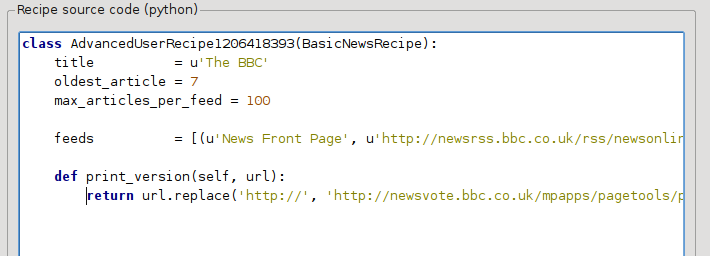
فيما سبق، def print_version(self, url) يُعرّف دالة يتم استدعاؤها بواسطة calibre لكل مقال. url هو عنوان URL للمقال الأصلي. ما تفعله print_version هو أخذ عنوان URL هذا واستبداله بعنوان URL الجديد الذي يشير إلى النسخة المطبوعة من المقال. لمعرفة المزيد عن بايثون، راجع البرنامج التعليمي.
الآن، انقر على زر إضافة/تحديث الوصفة وسيتم حفظ تغييراتك. أعد تنزيل الكتاب الإلكتروني. يجب أن يكون لديك كتاب إلكتروني محسّن بشكل كبير. إحدى المشكلات في الإصدار الجديد هي أن الخطوط على صفحة الويب للنسخة المطبوعة صغيرة جدًا. يتم إصلاح هذا تلقائيًا عند التحويل إلى كتاب إلكتروني، ولكن حتى بعد عملية الإصلاح، يصبح حجم خط القوائم وشريط التنقل كبيرًا جدًا بالنسبة لنص المقال. لإصلاح ذلك، سنقوم ببعض التخصيصات الإضافية، في القسم التالي.
استبدال أنماط المقالات¶
في القسم السابق، رأينا أن حجم الخط للمقالات من النسخة المطبوعة من بي بي سي كان صغيرًا جدًا. في معظم مواقع الويب، بما في ذلك بي بي سي، يتم تعيين حجم الخط هذا بواسطة أوراق أنماط CSS. يمكننا تعطيل جلب هذه الأوراق الأنماط بإضافة السطر:
no_stylesheets = True
تبدو الوصفة الآن كالتالي:
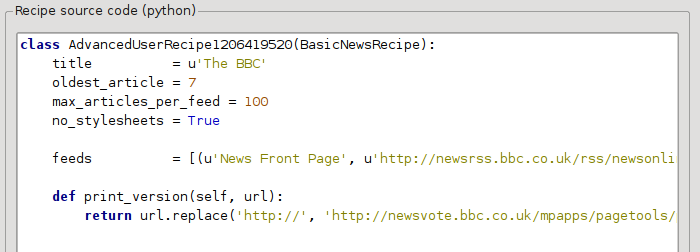
النسخة الجديدة تبدو جيدة جداً. إذا كنت من محبي الكمال، فسترغب في قراءة القسم التالي، الذي يتناول تعديل المحتوى الذي تم تنزيله فعلياً.
التقطيع والتقسيم¶
يحتوي calibre على قدرات قوية ومرنة للغاية عندما يتعلق الأمر بمعالجة المحتوى الذي تم تنزيله. لإظهار بعض هذه القدرات، دعنا نلقي نظرة على وصفتنا القديمة بي بي سي مرة أخرى. بالنظر إلى الكود المصدري (HTML) لبعض المقالات (النسخة المطبوعة)، نرى أن لديهم تذييلًا لا يحتوي على معلومات مفيدة، موجودة في
<div class="footer">
...
</div>
يمكن إزالة هذا بإضافة:
remove_tags = [dict(name='div', attrs={'class':'footer'})]
to the recipe. Finally, let's replace some of the CSS that we disabled earlier, with our own CSS that is suitable for conversion to an e-book:
extra_css = '.headline {font-size: x-large;} \n .fact { padding-top: 10pt }'
مع هذه الإضافات، أصبحت وصفتنا "جودة إنتاج".
هذه الوصفة تستكشف فقط قمة الجبل الجليدي عندما يتعلق الأمر بقوة calibre. لاستكشاف المزيد من قدرات calibre، سنفحص مثالًا واقعيًا أكثر تعقيدًا في القسم التالي.
مثال واقعي¶
مثال واقعي معقد بشكل معقول يكشف المزيد عن API لـ BasicNewsRecipe هو وصفة صحيفة نيويورك تايمز
import string, re
from calibre import strftime
from calibre.web.feeds.recipes import BasicNewsRecipe
from calibre.ebooks.BeautifulSoup import BeautifulSoup
class NYTimes(BasicNewsRecipe):
title = 'The New York Times'
__author__ = 'Kovid Goyal'
description = 'Daily news from the New York Times'
timefmt = ' [%a, %d %b, %Y]'
needs_subscription = True
remove_tags_before = dict(id='article')
remove_tags_after = dict(id='article')
remove_tags = [dict(attrs={'class':['articleTools', 'post-tools', 'side_tool', 'nextArticleLink clearfix']}),
dict(id=['footer', 'toolsRight', 'articleInline', 'navigation', 'archive', 'side_search', 'blog_sidebar', 'side_tool', 'side_index']),
dict(name=['script', 'noscript', 'style'])]
encoding = 'cp1252'
no_stylesheets = True
extra_css = 'h1 {font: sans-serif large;}\n.byline {font:monospace;}'
def get_browser(self):
br = BasicNewsRecipe.get_browser(self)
if self.username is not None and self.password is not None:
br.open('https://www.nytimes.com/auth/login')
br.select_form(name='login')
br['USERID'] = self.username
br['PASSWORD'] = self.password
br.submit()
return br
def parse_index(self):
soup = self.index_to_soup('https://www.nytimes.com/pages/todayspaper/index.html')
def feed_title(div):
return ''.join(div.findAll(text=True, recursive=False)).strip()
articles = {}
key = None
ans = []
for div in soup.findAll(True,
attrs={'class':['section-headline', 'story', 'story headline']}):
if ''.join(div['class']) == 'section-headline':
key = string.capwords(feed_title(div))
articles[key] = []
ans.append(key)
elif ''.join(div['class']) in ['story', 'story headline']:
a = div.find('a', href=True)
if not a:
continue
url = re.sub(r'\?.*', '', a['href'])
url += '?pagewanted=all'
title = self.tag_to_string(a, use_alt=True).strip()
description = ''
pubdate = strftime('%a, %d %b')
summary = div.find(True, attrs={'class':'summary'})
if summary:
description = self.tag_to_string(summary, use_alt=False)
feed = key if key is not None else 'Uncategorized'
if feed not in articles:
articles[feed] = []
if not 'podcasts' in url:
articles[feed].append(
dict(title=title, url=url, date=pubdate,
description=description,
content=''))
ans = self.sort_index_by(ans, {'The Front Page':-1, 'Dining In, Dining Out':1, 'Obituaries':2})
ans = [(key, articles[key]) for key in ans if key in articles]
return ans
def preprocess_html(self, soup):
refresh = soup.find('meta', {'http-equiv':'refresh'})
if refresh is None:
return soup
content = refresh.get('content').partition('=')[2]
raw = self.browser.open('https://www.nytimes.com'+content).read()
return BeautifulSoup(raw.decode('cp1252', 'replace'))
نرى العديد من الميزات الجديدة في هذه الوصفة. أولاً، لدينا:
timefmt = ' [%a, %d %b, %Y]'
يحدد هذا الوقت المعروض على الصفحة الأولى من الكتاب الإلكتروني الذي تم إنشاؤه ليكون بالتنسيق، اليوم، رقم_اليوم الشهر، السنة. انظر timefmt.
ثم نرى مجموعة من التوجيهات لتنظيف HTML الذي تم تنزيله:
remove_tags_before = dict(name='h1')
remove_tags_after = dict(id='footer')
remove_tags = ...
تزيل هذه كل شيء قبل أول علامة <h1> وكل شيء بعد أول علامة معرفها footer. راجع remove_tags، remove_tags_before، remove_tags_after.
الميزة المثيرة التالية هي:
needs_subscription = True
...
def get_browser(self):
...
needs_subscription = True يخبر calibre أن هذه الوصفة تحتاج إلى اسم مستخدم وكلمة مرور للوصول إلى المحتوى. هذا يتسبب في أن يطلب calibre اسم مستخدم وكلمة مرور كلما حاولت استخدام هذه الوصفة. الكود في calibre.web.feeds.news.BasicNewsRecipe.get_browser() يقوم بالفعل بتسجيل الدخول إلى موقع NYT. بمجرد تسجيل الدخول، سيستخدم calibre نفس مثيل المتصفح المسجل الدخول لجلب جميع المحتوى. راجع mechanize لفهم الكود في get_browser.
The next new feature is the
calibre.web.feeds.news.BasicNewsRecipe.parse_index() method. Its job is
to go to https://www.nytimes.com/pages/todayspaper/index.html and fetch the list
of articles that appear in today's paper. While more complex than simply using
RSS, the recipe creates an e-book that corresponds very closely to the
day's paper. parse_index makes heavy use of BeautifulSoup to parse
the daily paper webpage. You can also use other, more modern parsers if you
dislike BeautifulSoup. calibre comes with lxml and
html5lib, which are the
recommended parsers. To use them, replace the call to index_to_soup() with
the following:
raw = self.index_to_soup(url, raw=True)
# For html5lib
import html5lib
root = html5lib.parse(raw, namespaceHTMLElements=False, treebuilder='lxml')
# For the lxml html 4 parser
from lxml import html
root = html.fromstring(raw)
الميزة الجديدة الأخيرة هي طريقة calibre.web.feeds.news.BasicNewsRecipe.preprocess_html(). يمكن استخدامها لإجراء تحويلات عشوائية على كل صفحة HTML تم تنزيلها. هنا يتم استخدامها لتجاوز الإعلانات التي تعرضها صحيفة نيويورك تايمز لك قبل كل مقال.
نصائح لتطوير وصفات جديدة¶
أفضل طريقة لتطوير وصفات جديدة هي استخدام واجهة سطر الأوامر. أنشئ الوصفة باستخدام محرر Python المفضل لديك واحفظها في ملف وليكن myrecipe.recipe. امتداد .recipe مطلوب. يمكنك تنزيل المحتوى باستخدام هذه الوصفة بالأمر:
ebook-convert myrecipe.recipe .epub --test -vv --debug-pipeline debug
سيقوم الأمر ebook-convert بتنزيل جميع صفحات الويب وحفظها في ملف EPUB myrecipe.epub. خيار -vv يجعل ebook-convert يعرض الكثير من المعلومات حول ما يفعله. خيار ebook-convert-recipe-input --test يجعله ينزل فقط مقالتين من خلاصتين على الأكثر. بالإضافة إلى ذلك، سيضع ebook-convert ملف HTML الذي تم تنزيله في مجلد debug/input، حيث debug هو المجلد الذي حددته في خيار ebook-convert --debug-pipeline.
بمجرد اكتمال التنزيل، يمكنك الاطلاع على HTML الذي تم تنزيله بفتح الملف debug/input/index.html في متصفح. بمجرد أن تكون راضيًا عن أن التنزيل والمعالجة المسبقة تتم بشكل صحيح، يمكنك إنشاء كتب إلكترونية بتنسيقات مختلفة كما هو موضح أدناه:
ebook-convert myrecipe.recipe myrecipe.epub
ebook-convert myrecipe.recipe myrecipe.mobi
...
إذا كنت راضيًا عن وصفتك، وتشعر أن هناك طلبًا كافيًا لتبرير إدراجها في مجموعة الوصفات المضمنة، فانشر وصفتك في منتدى وصفات calibre هنا لمشاركتها مع مستخدمي calibre الآخرين.
ملاحظة
على نظام macOS، توجد أدوات سطر الأوامر داخل حزمة calibre، على سبيل المثال، إذا قمت بتثبيت calibre في /Applications فإن أدوات سطر الأوامر موجودة في /Applications/calibre.app/Contents/MacOS/.
شاهد أيضا
- ebook-convert
واجهة سطر الأوامر لجميع تحويلات الكتب الإلكترونية.
قراءات إضافية¶
لمعرفة المزيد حول كتابة وصفات متقدمة باستخدام بعض المرافق، المتوفرة في BasicNewsRecipe يجب عليك استشارة المصادر التالية:
- توثيق API
توثيق فئة
BasicNewsRecipeوجميع طرقها وحقولها الهامة.- وصفة الأخبار الأساسية
الرمز المصدري لـ
BasicNewsRecipe- وصفات مدمجة
الرمز المصدري للوصفات المضمنة التي تأتي مع calibre
- منتدى وصفات calibre
يتواجد هنا العديد من كتاب وصفات calibre ذوي المعرفة.
توثيق API¶
- توثيق API للوصفات
BasicNewsRecipeBasicNewsRecipe.adeify_images()BasicNewsRecipe.image_url_processor()BasicNewsRecipe.print_version()BasicNewsRecipe.tag_to_string()BasicNewsRecipe.abort_article()BasicNewsRecipe.abort_recipe_processing()BasicNewsRecipe.add_toc_thumbnail()BasicNewsRecipe.canonicalize_internal_url()BasicNewsRecipe.cleanup()BasicNewsRecipe.clone_browser()BasicNewsRecipe.default_cover()BasicNewsRecipe.download()BasicNewsRecipe.extract_readable_article()BasicNewsRecipe.get_article_url()BasicNewsRecipe.get_browser()BasicNewsRecipe.get_cover_url()BasicNewsRecipe.get_extra_css()BasicNewsRecipe.get_feeds()BasicNewsRecipe.get_masthead_title()BasicNewsRecipe.get_masthead_url()BasicNewsRecipe.get_obfuscated_article()BasicNewsRecipe.get_url_specific_delay()BasicNewsRecipe.index_to_soup()BasicNewsRecipe.is_link_wanted()BasicNewsRecipe.parse_feeds()BasicNewsRecipe.parse_index()BasicNewsRecipe.populate_article_metadata()BasicNewsRecipe.postprocess_book()BasicNewsRecipe.postprocess_html()BasicNewsRecipe.preprocess_html()BasicNewsRecipe.preprocess_image()BasicNewsRecipe.preprocess_raw_html()BasicNewsRecipe.publication_date()BasicNewsRecipe.skip_ad_pages()BasicNewsRecipe.sort_index_by()BasicNewsRecipe.articles_are_obfuscatedBasicNewsRecipe.auto_cleanupBasicNewsRecipe.auto_cleanup_keepBasicNewsRecipe.browser_typeBasicNewsRecipe.center_navbarBasicNewsRecipe.compress_news_imagesBasicNewsRecipe.compress_news_images_auto_sizeBasicNewsRecipe.compress_news_images_max_sizeBasicNewsRecipe.conversion_optionsBasicNewsRecipe.cover_marginsBasicNewsRecipe.delayBasicNewsRecipe.descriptionBasicNewsRecipe.encodingBasicNewsRecipe.extra_cssBasicNewsRecipe.feedsBasicNewsRecipe.filter_regexpsBasicNewsRecipe.handle_gzipBasicNewsRecipe.ignore_duplicate_articlesBasicNewsRecipe.keep_only_tagsBasicNewsRecipe.languageBasicNewsRecipe.masthead_urlBasicNewsRecipe.match_regexpsBasicNewsRecipe.max_articles_per_feedBasicNewsRecipe.needs_subscriptionBasicNewsRecipe.no_stylesheetsBasicNewsRecipe.oldest_articleBasicNewsRecipe.preprocess_regexpsBasicNewsRecipe.publication_typeBasicNewsRecipe.recipe_disabledBasicNewsRecipe.recipe_specific_optionsBasicNewsRecipe.recursionsBasicNewsRecipe.remove_attributesBasicNewsRecipe.remove_empty_feedsBasicNewsRecipe.remove_javascriptBasicNewsRecipe.remove_tagsBasicNewsRecipe.remove_tags_afterBasicNewsRecipe.remove_tags_beforeBasicNewsRecipe.requires_versionBasicNewsRecipe.resolve_internal_linksBasicNewsRecipe.reverse_article_orderBasicNewsRecipe.scale_news_imagesBasicNewsRecipe.scale_news_images_to_deviceBasicNewsRecipe.simultaneous_downloadsBasicNewsRecipe.summary_lengthBasicNewsRecipe.template_cssBasicNewsRecipe.timefmtBasicNewsRecipe.timeoutBasicNewsRecipe.titleBasicNewsRecipe.use_embedded_content