 언어 변경
언어 변경즐겨찾는 뉴스 웹사이트 추가¶
calibre는 인터넷에서 뉴스를 다운로드하고 전자책으로 변환하는 강력하고 유연하며 사용하기 쉬운 프레임워크를 제공합니다. 다음에서는 예시를 통해 다양한 웹사이트에서 뉴스를 가져오는 방법을 보여줍니다.
프레임워크 사용법을 이해하려면 아래에 나열된 순서대로 예시를 따르세요:
완전 자동 가져오기¶
뉴스 출처가 충분히 단순하다면 calibre가 완전 자동으로 뉴스를 가져올 수 있습니다. URL을 제공하기만 하면 됩니다. calibre는 뉴스 출처를 다운로드하는 데 필요한 모든 정보를 :term:`레시피`에 수집합니다. calibre에 뉴스 출처를 알려주려면 해당 뉴스 출처에 대한 :term:`레시피`를 만들어야 합니다. 몇 가지 예시를 살펴보겠습니다:
calibre 블로그¶
calibre 블로그는 새로운 calibre 사용자에게 유용한 calibre 기능을 간단하고 접근하기 쉽게 설명하는 게시물 블로그입니다. 이 블로그를 전자책으로 다운로드하려면 블로그의 RSS 피드를 사용합니다:
http://blog.calibre-ebook.com/feeds/posts/default
블로그 페이지 하단의 “구독하기”에서 게시물 → Atom`을 선택하여 RSS URL을 얻었습니다. calibre가 피드를 다운로드하고 전자책으로 변환하도록 하려면 :guilabel:`뉴스 가져오기 버튼을 마우스 오른쪽 버튼 클릭한 다음 사용자 지정 뉴스 소스 추가 메뉴 항목을 클릭하고 새 레시피 버튼을 클릭하세요. 아래와 유사한 대화상자가 열립니다.
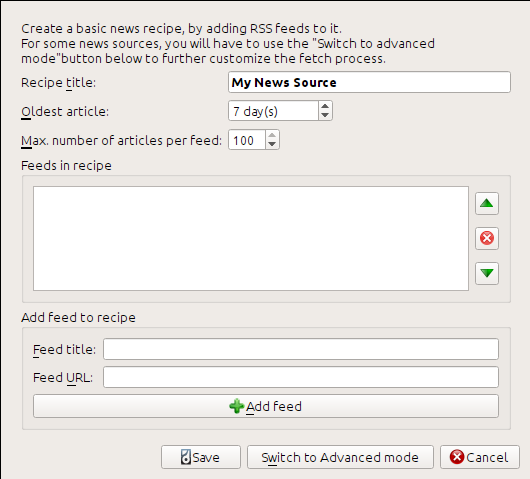
먼저 레시피 제목 필드에 ``Calibre Blog``를 입력하세요. 이것이 위 피드의 기사로 생성될 전자책의 제목이 됩니다.
다음 두 필드(가장 오래된 기사`와 :guilabel:`피드당 최대 기사 수)는 각 피드에서 다운로드할 기사 수를 제어할 수 있으며, 의미를 쉽게 유추할 수 있습니다.
레시피에 피드를 추가하려면 피드 제목과 피드 URL을 입력하고 피드 추가 버튼을 클릭하세요. 피드를 추가한 후 저장 버튼을 클릭하면 완료입니다! 대화상자를 닫으세요.
새 레시피`를 테스트하려면 :guilabel:`뉴스 가져오기 버튼을 클릭하고 사용자 지정 뉴스 소스 하위 메뉴에서 calibre 블로그`를 클릭하세요. 몇 분 후, 새로 다운로드된 블로그 게시물 전자책이 기본 라이브러리 보기(리더가 연결되어 있으면 라이브러리 대신 리더에 저장됨)에 나타납니다. 선택하고 :guilabel:`보기 버튼을 눌러 읽으세요!
이렇게 적은 노력으로 잘 작동한 이유는 블로그가 전체 콘텐츠 RSS 피드를 제공하기 때문입니다. 즉, 기사 콘텐츠가 피드 자체에 포함되어 있습니다. 이러한 방식으로 전체 콘텐츠 피드를 제공하는 대부분의 뉴스 소스에서는 전자책으로 변환하기 위해 추가 노력이 필요하지 않습니다. 이제 전체 콘텐츠 피드를 제공하지 않는 뉴스 소스를 살펴보겠습니다. 이러한 피드에서 전체 기사는 웹페이지이며 피드에는 웹페이지 링크와 기사의 짧은 요약만 포함됩니다.
bbc.co.uk¶
*The BBC*의 다음 두 피드를 시도해 보겠습니다:
위의 :ref:`calibre_blog`에서 설명한 절차를 따라 *The BBC*에 대한 레시피를 만드세요(위의 피드 사용). 다운로드한 전자책을 살펴보면 calibre가 각 기사 웹페이지에서 관심 있는 콘텐츠만 추출하는 훌륭한 작업을 수행한 것을 알 수 있습니다. 그러나 추출 과정이 완벽하지는 않습니다. 때때로 메뉴나 탐색 도구와 같은 원치 않는 콘텐츠가 남거나 기사 머리글과 같이 남겨져야 할 콘텐츠가 제거됩니다. 완벽한 콘텐츠 추출을 위해서는 다음 섹션에서 설명하는 것처럼 가져오기 과정을 맞춤 설정해야 합니다.
가져오기 프로세스 맞춤 설정¶
다운로드 과정을 완벽하게 하거나 특히 복잡한 웹사이트에서 콘텐츠를 다운로드하려면 레시피 프레임워크의 모든 기능과 유연성을 활용할 수 있습니다. 그렇게 하려면 사용자 지정 뉴스 소스 추가 대화상자에서 고급 모드로 전환 버튼을 클릭하세요.
가장 쉽고 종종 가장 효과적인 맞춤 설정은 온라인 기사의 인쇄 버전을 사용하는 것입니다. 인쇄 버전은 일반적으로 불필요한 요소가 훨씬 적고 전자책으로 변환이 훨씬 원활합니다. The BBC 기사의 인쇄 버전을 사용해 보겠습니다.
bbc.co.uk 인쇄 버전 사용하기¶
첫 번째 단계는 이전에 :ref:`bbc`에서 다운로드한 전자책을 살펴보는 것입니다. 전자책의 각 기사 끝에 기사가 어디서 다운로드되었는지 알려주는 작은 설명이 있습니다. 해당 URL을 복사하여 브라우저에 붙여넣으세요. 이제 기사 웹페이지에서 “인쇄 가능한 버전”을 가리키는 링크를 찾으세요. 클릭하여 기사의 인쇄 버전을 확인하세요. 훨씬 깔끔합니다! 이제 두 URL을 비교해 보세요. 제 경우는 다음과 같습니다:
인쇄 버전을 얻으려면 모든 기사 URL 앞에 다음을 붙여야 합니다:
newsvote.bbc.co.uk/mpapps/pagetools/print/
이제 사용자 지정 뉴스 소스 대화상자의 :guilabel:`고급 모드`에서 다음과 같은 내용이 표시됩니다(고급 모드로 전환하기 전에 The BBC 레시피를 선택하세요):
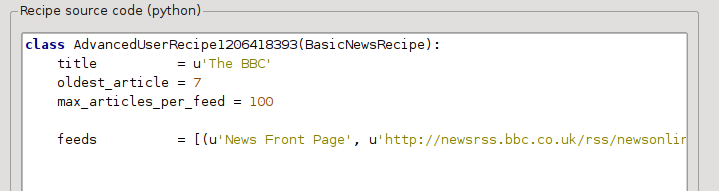
:guilabel:`기본 모드`의 필드가 간단한 방식으로 Python 코드로 변환된 것을 확인할 수 있습니다. 기사의 인쇄 버전을 사용하도록 이 레시피에 지시를 추가해야 합니다. 다음 두 줄만 추가하면 됩니다:
def print_version(self, url):
return url.replace('https://', 'https://newsvote.bbc.co.uk/mpapps/pagetools/print/')
Python이므로 들여쓰기가 중요합니다. 줄을 추가한 후 다음과 같아야 합니다:
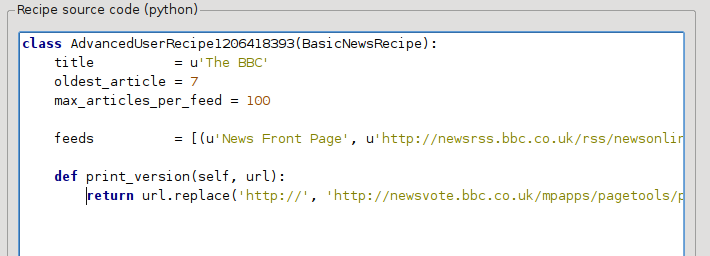
위에서 ``def print_version(self, url)``은 calibre가 각 기사에 대해 호출하는 *메서드*를 정의합니다. ``url``은 원본 기사의 URL입니다. ``print_version``은 해당 URL을 가져와 기사의 인쇄 버전을 가리키는 새 URL로 대체합니다. `Python <https://www.python.org>`_에 대해 알아보려면 `튜토리얼 <https://docs.python.org/tutorial/>`_을 참조하세요.
이제 레시피 추가/업데이트 버튼을 클릭하면 변경 사항이 저장됩니다. 전자책을 다시 다운로드하세요. 훨씬 개선된 전자책을 얻을 수 있어야 합니다. 새 버전의 문제 중 하나는 인쇄 버전 웹페이지의 글꼴이 너무 작다는 것입니다. 전자책으로 변환할 때 자동으로 수정되지만 수정 과정 후에도 메뉴와 탐색 모음의 글꼴 크기가 기사 텍스트에 비해 너무 커집니다. 이 문제를 해결하기 위해 다음 섹션에서 추가 맞춤 설정을 하겠습니다.
기사 스타일 대체¶
이전 섹션에서 The BBC 인쇄 버전 기사의 글꼴 크기가 너무 작은 것을 보았습니다. *The BBC*를 포함한 대부분의 웹사이트에서 이 글꼴 크기는 CSS 스타일시트로 설정됩니다. 다음 줄을 추가하여 이러한 스타일시트의 가져오기를 비활성화할 수 있습니다:
no_stylesheets = True
이제 레시피는 다음과 같습니다:
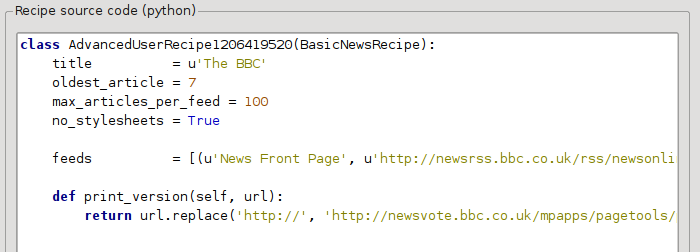
새 버전은 상당히 좋아 보입니다. 완벽주의자라면 다운로드한 콘텐츠를 실제로 수정하는 방법을 다루는 다음 섹션을 읽고 싶을 것입니다.
자르고 다듬기¶
calibre에는 다운로드한 콘텐츠를 조작하는 매우 강력하고 유연한 기능이 포함되어 있습니다. 몇 가지를 보여주기 위해 오랜 친구인 The BBC 레시피를 다시 살펴보겠습니다. 몇몇 기사(인쇄 버전)의 소스 코드(HTML)를 살펴보면 유용한 정보가 전혀 없는 꼬리말이 포함되어 있습니다
<div class="footer">
...
</div>
다음을 추가하여 제거할 수 있습니다:
remove_tags = [dict(name='div', attrs={'class':'footer'})]
마지막으로, 이전에 비활성화한 CSS 일부를 전자책 변환에 적합한 자체 :term:`CSS`로 대체합니다:
extra_css = '.headline {font-size: x-large;} \n .fact { padding-top: 10pt }'
이러한 추가로 인해 레시피가 “프로덕션 품질”이 되었습니다.
이 :term:`레시피`는 calibre의 능력 중 빙산의 일각만을 보여줍니다. calibre의 더 많은 능력을 탐색하기 위해 다음 섹션에서 더 복잡한 실제 예시를 살펴보겠습니다.
실제 예시¶
``BasicNewsRecipe``의 :term:`API`를 더 많이 활용하는 꽤 복잡한 실제 예시는 *The New York Times*에 대한 :term:`레시피`입니다
import string, re
from calibre import strftime
from calibre.web.feeds.recipes import BasicNewsRecipe
from calibre.ebooks.BeautifulSoup import BeautifulSoup
class NYTimes(BasicNewsRecipe):
title = 'The New York Times'
__author__ = 'Kovid Goyal'
description = 'Daily news from the New York Times'
timefmt = ' [%a, %d %b, %Y]'
needs_subscription = True
remove_tags_before = dict(id='article')
remove_tags_after = dict(id='article')
remove_tags = [dict(attrs={'class':['articleTools', 'post-tools', 'side_tool', 'nextArticleLink clearfix']}),
dict(id=['footer', 'toolsRight', 'articleInline', 'navigation', 'archive', 'side_search', 'blog_sidebar', 'side_tool', 'side_index']),
dict(name=['script', 'noscript', 'style'])]
encoding = 'cp1252'
no_stylesheets = True
extra_css = 'h1 {font: sans-serif large;}\n.byline {font:monospace;}'
def get_browser(self):
br = BasicNewsRecipe.get_browser(self)
if self.username is not None and self.password is not None:
br.open('https://www.nytimes.com/auth/login')
br.select_form(name='login')
br['USERID'] = self.username
br['PASSWORD'] = self.password
br.submit()
return br
def parse_index(self):
soup = self.index_to_soup('https://www.nytimes.com/pages/todayspaper/index.html')
def feed_title(div):
return ''.join(div.findAll(text=True, recursive=False)).strip()
articles = {}
key = None
ans = []
for div in soup.findAll(True,
attrs={'class':['section-headline', 'story', 'story headline']}):
if ''.join(div['class']) == 'section-headline':
key = string.capwords(feed_title(div))
articles[key] = []
ans.append(key)
elif ''.join(div['class']) in ['story', 'story headline']:
a = div.find('a', href=True)
if not a:
continue
url = re.sub(r'\?.*', '', a['href'])
url += '?pagewanted=all'
title = self.tag_to_string(a, use_alt=True).strip()
description = ''
pubdate = strftime('%a, %d %b')
summary = div.find(True, attrs={'class':'summary'})
if summary:
description = self.tag_to_string(summary, use_alt=False)
feed = key if key is not None else 'Uncategorized'
if feed not in articles:
articles[feed] = []
if not 'podcasts' in url:
articles[feed].append(
dict(title=title, url=url, date=pubdate,
description=description,
content=''))
ans = self.sort_index_by(ans, {'The Front Page':-1, 'Dining In, Dining Out':1, 'Obituaries':2})
ans = [(key, articles[key]) for key in ans if key in articles]
return ans
def preprocess_html(self, soup):
refresh = soup.find('meta', {'http-equiv':'refresh'})
if refresh is None:
return soup
content = refresh.get('content').partition('=')[2]
raw = self.browser.open('https://www.nytimes.com'+content).read()
return BeautifulSoup(raw.decode('cp1252', 'replace'))
이 :term:`레시피`에서 여러 새로운 기능을 볼 수 있습니다. 먼저:
timefmt = ' [%a, %d %b, %Y]'
생성된 전자책의 첫 페이지에 표시되는 시간을 요일, 일 번호 월, 연도 형식으로 설정합니다. :attr:`timefmt <calibre.web.feeds.news.BasicNewsRecipe.timefmt>`를 참조하세요.
그런 다음 다운로드한 :term:`HTML`을 정리하기 위한 지시문 그룹이 표시됩니다:
remove_tags_before = dict(name='h1')
remove_tags_after = dict(id='footer')
remove_tags = ...
첫 번째 <h1> 태그 이전의 모든 것과 id가 ``footer``인 첫 번째 태그 이후의 모든 것을 제거합니다. remove_tags, remove_tags_before, :attr:`remove_tags_after <calibre.web.feeds.news.BasicNewsRecipe.remove_tags_after>`를 참조하세요.
다음으로 흥미로운 기능은:
needs_subscription = True
...
def get_browser(self):
...
``needs_subscription = True``는 이 레시피가 콘텐츠에 접근하려면 사용자 이름과 암호가 필요하다는 것을 calibre에 알려줍니다. 이로 인해 calibre는 이 레시피를 사용할 때마다 사용자 이름과 암호를 요청합니다. :meth:`calibre.web.feeds.news.BasicNewsRecipe.get_browser`의 코드가 실제로 NYT 웹사이트에 로그인합니다. 로그인하면 calibre는 동일한 로그인된 브라우저 인스턴스를 사용하여 모든 콘텐츠를 가져옵니다. ``get_browser``의 코드를 이해하려면 `mechanize <https://mechanize.readthedocs.io/en/latest/>`_를 참조하세요.
다음 새로운 기능은 calibre.web.feeds.news.BasicNewsRecipe.parse_index() 메서드입니다. 이 메서드는 https://www.nytimes.com/pages/todayspaper/index.html로 이동하여 오늘 신문에 실린 기사 목록을 가져오는 역할을 합니다. RSS`를 단순히 사용하는 것보다 복잡하지만, 이 레시피는 그날의 신문에 매우 밀접하게 대응하는 전자책을 생성합니다. ``parse_index``는 일간지 웹페이지를 파싱하기 위해 `BeautifulSoup <https://www.crummy.com/software/BeautifulSoup/bs4/doc/>`_을 많이 사용합니다. BeautifulSoup이 마음에 들지 않으면 다른 더 현대적인 파서를 사용할 수도 있습니다. calibre에는 권장 파서인 `lxml <https://lxml.de/>`_과 `html5lib <https://github.com/html5lib/html5lib-python>`_이 포함되어 있습니다. 이를 사용하려면 ``index_to_soup()` 호출을 다음으로 바꾸세요:
raw = self.index_to_soup(url, raw=True)
# For html5lib
import html5lib
root = html5lib.parse(raw, namespaceHTMLElements=False, treebuilder='lxml')
# For the lxml html 4 parser
from lxml import html
root = html.fromstring(raw)
마지막 새로운 기능은 calibre.web.feeds.news.BasicNewsRecipe.preprocess_html() 메서드입니다. 다운로드한 모든 HTML 페이지에서 임의의 변환을 수행하는 데 사용할 수 있습니다. 여기서는 NYTimes가 각 기사 앞에 표시하는 광고를 우회하는 데 사용됩니다.
새 레시피 개발 팁¶
새 레시피를 개발하는 가장 좋은 방법은 명령줄 인터페이스를 사용하는 것입니다. 좋아하는 Python 편집기를 사용하여 레시피를 만들고 myrecipe.recipe 파일에 저장하세요. .recipe 확장자가 필요합니다. 다음 명령으로 이 레시피를 사용하여 콘텐츠를 다운로드할 수 있습니다:
ebook-convert myrecipe.recipe .epub --test -vv --debug-pipeline debug
ebook-convert 명령은 모든 웹페이지를 다운로드하여 EPUB 파일 myrecipe.epub`에 저장합니다. `-vv`` 옵션은 ebook-convert가 수행 중인 작업에 대한 많은 정보를 출력합니다. ebook-convert-recipe-input --test 옵션은 최대 두 개의 피드에서 몇 개의 기사만 다운로드합니다. 또한 ebook-convert는 다운로드한 HTML을 ebook-convert --debug-pipeline 옵션에서 지정한 debug/input 폴더에 저장합니다.
다운로드가 완료되면 파일 :file:`debug/input/index.html`을 브라우저에서 열어 다운로드한 :term:`HTML`을 확인할 수 있습니다. 다운로드와 전처리가 올바르게 수행되고 있다고 확인되면 아래와 같이 다양한 형식의 전자책을 생성할 수 있습니다:
ebook-convert myrecipe.recipe myrecipe.epub
ebook-convert myrecipe.recipe myrecipe.mobi
...
레시피에 만족하고 내장 레시피 세트에 포함될 만큼 충분한 수요가 있다고 생각되면 `calibre 레시피 포럼 <https://www.mobileread.com/forums/forumdisplay.php?f=228>`_에 레시피를 게시하여 다른 calibre 사용자와 공유하세요.
참고
macOS에서는 명령줄 도구가 calibre 번들 안에 있습니다. 예를 들어, calibre를 /Applications`에 설치한 경우 명령줄 도구는 :file:/Applications/calibre.app/Contents/MacOS/`에 있습니다.
더 보기
- ebook-convert
모든 전자책 변환을 위한 명령줄 인터페이스입니다.
더 읽을 거리¶
``BasicNewsRecipe``에서 사용할 수 있는 일부 기능을 사용하여 고급 레시피를 작성하는 방법에 대해 자세히 알아보려면 다음 출처를 참조하세요:
- API 문서
BasicNewsRecipe클래스와 모든 중요한 메서드 및 필드에 대한 문서입니다.- 기본 뉴스 레시피
``BasicNewsRecipe``의 소스 코드
- 기본 제공 레시피
calibre에 포함된 내장 레시피의 소스 코드
- 캘리버 레시피 포럼
지식이 풍부한 많은 calibre 레시피 작성자들이 이곳에서 활동합니다.
API 문서¶
- 레시피 API 문서
BasicNewsRecipeBasicNewsRecipe.adeify_images()BasicNewsRecipe.image_url_processor()BasicNewsRecipe.print_version()BasicNewsRecipe.tag_to_string()BasicNewsRecipe.abort_article()BasicNewsRecipe.abort_recipe_processing()BasicNewsRecipe.add_toc_thumbnail()BasicNewsRecipe.canonicalize_internal_url()BasicNewsRecipe.cleanup()BasicNewsRecipe.clone_browser()BasicNewsRecipe.default_cover()BasicNewsRecipe.download()BasicNewsRecipe.extract_readable_article()BasicNewsRecipe.get_article_url()BasicNewsRecipe.get_browser()BasicNewsRecipe.get_cover_url()BasicNewsRecipe.get_extra_css()BasicNewsRecipe.get_feeds()BasicNewsRecipe.get_masthead_title()BasicNewsRecipe.get_masthead_url()BasicNewsRecipe.get_obfuscated_article()BasicNewsRecipe.get_url_specific_delay()BasicNewsRecipe.index_to_soup()BasicNewsRecipe.is_link_wanted()BasicNewsRecipe.parse_feeds()BasicNewsRecipe.parse_index()BasicNewsRecipe.populate_article_metadata()BasicNewsRecipe.postprocess_book()BasicNewsRecipe.postprocess_html()BasicNewsRecipe.preprocess_html()BasicNewsRecipe.preprocess_image()BasicNewsRecipe.preprocess_raw_html()BasicNewsRecipe.publication_date()BasicNewsRecipe.skip_ad_pages()BasicNewsRecipe.sort_index_by()BasicNewsRecipe.articles_are_obfuscatedBasicNewsRecipe.auto_cleanupBasicNewsRecipe.auto_cleanup_keepBasicNewsRecipe.browser_typeBasicNewsRecipe.center_navbarBasicNewsRecipe.compress_news_imagesBasicNewsRecipe.compress_news_images_auto_sizeBasicNewsRecipe.compress_news_images_max_sizeBasicNewsRecipe.conversion_optionsBasicNewsRecipe.cover_marginsBasicNewsRecipe.delayBasicNewsRecipe.descriptionBasicNewsRecipe.encodingBasicNewsRecipe.extra_cssBasicNewsRecipe.feedsBasicNewsRecipe.filter_regexpsBasicNewsRecipe.handle_gzipBasicNewsRecipe.ignore_duplicate_articlesBasicNewsRecipe.keep_only_tagsBasicNewsRecipe.languageBasicNewsRecipe.masthead_urlBasicNewsRecipe.match_regexpsBasicNewsRecipe.max_articles_per_feedBasicNewsRecipe.needs_subscriptionBasicNewsRecipe.no_stylesheetsBasicNewsRecipe.oldest_articleBasicNewsRecipe.preprocess_regexpsBasicNewsRecipe.publication_typeBasicNewsRecipe.recipe_disabledBasicNewsRecipe.recipe_specific_optionsBasicNewsRecipe.recursionsBasicNewsRecipe.remove_attributesBasicNewsRecipe.remove_empty_feedsBasicNewsRecipe.remove_javascriptBasicNewsRecipe.remove_tagsBasicNewsRecipe.remove_tags_afterBasicNewsRecipe.remove_tags_beforeBasicNewsRecipe.requires_versionBasicNewsRecipe.resolve_internal_linksBasicNewsRecipe.reverse_article_orderBasicNewsRecipe.scale_news_imagesBasicNewsRecipe.scale_news_images_to_deviceBasicNewsRecipe.simultaneous_downloadsBasicNewsRecipe.summary_lengthBasicNewsRecipe.template_cssBasicNewsRecipe.timefmtBasicNewsRecipe.timeoutBasicNewsRecipe.titleBasicNewsRecipe.use_embedded_content