 Changer la langue
Changer la langueConversion de livre numérique¶
calibre a un système de conversion qui est prévu pour être très simple d’utilisation. Normalement, il suffit d’ajouter un livre à calibre, cliquer sur « convertir » et calibre s’efforcera de générer un résultat aussi proche que possible de l’original. calibre accepte un très large panel de formats, certains étant plus appropriés que d’autres à la conversion en livre numérique. Dans le cas de ces formats, ou si vous souhaitez simplement avoir plus de contrôle sur le système de conversion, calibre a beaucoup d’options pour affiner le processus de conversion. Cependant, il faut noter que le système de conversion de calibre ne peut pas remplacer un programme d’édition de livre numérique. Pour éditer des livres numériques, je recommande de les convertir d’abord en EPUB ou AZW3 en utilisant calibre et ensuite, utiliser la fonction Éditer le livre pour les perfectionner. Vous pouvez alors utiliser le livre numérique édité comme base pour la conversion vers d’autres formats avec calibre.
Ce document fera principalement référence aux paramètres de conversion comme trouvé dans la boîte de dialogue de conversion, représentée ci-dessous. Tous ces paramètres sont aussi disponible par l’interface en invite de commande pour la conversion, documenté dans ebook-convert. Dans calibre, vous pouvez obtenir de l’aide sur n’importe quel paramètre individuel en passant par-dessus avec votre souris, une info-bulle décrivant le paramètre apparaîtra.
Introduction¶
La première chose à comprendre à propos du système de conversion, c’est qu’il fonctionne comme un pipeline. Schématiquement, cela ressemble à ceci :
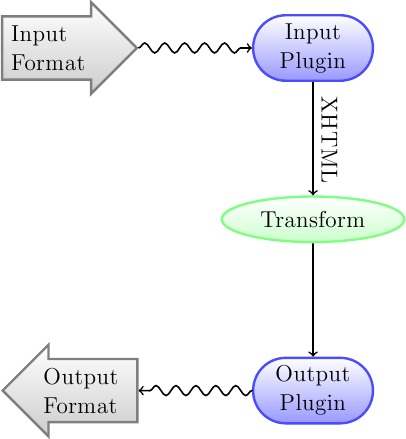
Le format d’entrée est tout d’abord converti en XHTML par l”Extension d’Entrée appropriée. Ce fichier HTML est alors transformé. En dernier lieu, le fichier XHTML traité est converti vers le format spécifié par l”Extension de Sortie appropriée. Les résultats de la conversion peuvent grandement varier, en fonction du format entrant. Certains formats se convertissent bien mieux que d’autres. Une liste des meilleures sources de format pour la conversion peut être trouvée ici.
C’est dans les manipulations qui s’opèrent sur la sortie XHTML que tout le travail se fait. Il existe de nombreuses manipulations, par exemple, l’insertion des métadonnées en tant que première page du livre électronique, la détection des titres de chapitres pour la création d’une Table des Matières, l’ajustement des tailles des polices, et cetera. Il est important de se souvenir que toutes les manipulations se font sur le fichier XHTML par l” Extension d’entrée, pas sur le fichier de base lui-même. Donc, par exemple, si vous demandez à calibre de convertir un fichier RTF vers de l’EPUB, il convertira d’abord en XHTML en interne, les multiples manipulations seront appliquées au fichier XHTML et ensuite l” Extension de sortie créera le fichier EPUB, générant automatiquement toutes les métadonnées, la Table des Matières, et cetera.
Vous pouvez voir ce procédé en action en utilisant l’option de débogage  . Spécifiez juste le chemin vers un dossier pour le fichier de débogage. Pendant la conversion, calibre placera le fichier XHTML généré aux différentes étapes du pipeline de conversion dans différents sous-dossier. Les quatre sous-dossiers sont :
. Spécifiez juste le chemin vers un dossier pour le fichier de débogage. Pendant la conversion, calibre placera le fichier XHTML généré aux différentes étapes du pipeline de conversion dans différents sous-dossier. Les quatre sous-dossiers sont :
Dossier |
Description |
|---|---|
entrée |
Ceci contient le fichier HTML fr sortie créé par l’Extension d’origine. Utilisez le pour déboguer l’Extension d’entrée. |
analysé |
Le résultat du prétraitement du fichier et de sa conversion en XHTML par l’Extension d’entrée. Utiliser ceci pour déboguer la détection de structures. |
structure |
Après la détection de structure, mais avant l’aplanissement du CSS et la conversion des tailles de polices. Utiliser pour déboguer la conversion de la taille des polices et les transformations CSS. |
traité |
Juste avant que le livre numérique ne soit passé à l’extension de sortie. Utiliser ceci pour déboguer l’extension de sortie. |
Si vous souhaitez légèrement éditer le document d’entrée avant que calibre ne le convertisse, la meilleure chose à faire est d’éditer les fichiers dans le sous-dossier Input, puis de les archiver, et d’utiliser l’archive ZIP en tant que fichier d’entrée pour les conversions suivantes. Pour ceci, utiliser la boîte de dialogue Édition des méta informations pour ajouter l’archive ZIP en tant que format pour le livre et ensuite, dans le coin supérieur gauche de la boîte de dialogue de conversion, sélectionner ZIP comme le format d’entrée.
Ce document s’occupera principalement des différentes manipulations qui agiront sur le fichier XHTML intermédiaire et sur comment les contrôler. À la fin se trouve des astuces pour chaque format d’entrée/de sortie.
Apparence¶
Ce groupe d’options contrôle de nombreux aspects de l’apparence et de la présentation du livre numérique converti.
Polices¶
Une des meilleures particularités lors de l’expérience de lecture électronique est la possibilité de facilement réajuster la taille des polices pour s’adapter aux besoins personnels et conditions d’éclairage. calibre a des algorithmes sophistiqués pour s’assurer que tous les livres ont une taille de police cohérente, quelle que soit la taille de police spécifiée dans le fichier d’entrée
La taille de police de base est la taille de police la plus utilisée dans ce document, càd, la taille de la masse de texte dans le document. Quand vous spécifiez un Taille de police de base, calibre redimensionne automatiquement toutes les tailles de police proportionnellement, pour que la taille de police la plus utilisée devienne la taille spécifiée et que les autres tailles se dimensionnent adéquatement. En choisissant une taille plus large, vous pouvez augmenter la taille des polices du document, et vice versa. Quand vous fixez la taille de police de base, il vaut mieux aussi fixer la clef de taille de police .
Normalement, calibre choisira automatiquement une taille de police de base appropriée au profil de sortie que vous avez choisi (voir Mise en page). Toutefois, vous pouvez outrepassez ceci si le choix par défaut ne vous convient pas.
L’option Clef de taille de police vous permet de contrôler comment la taille des polices qui ne sont pas celles de base sont redimensionnées. L’algorithme de redimensionnement des polices utilise une clef de taille de police, qui est simplement une liste séparée par des virgules des tailles de police. La clef des tailles de police donne à calibre combien de fois plus grosse ou plus petite une police devrait être par rapport à la police de base. L’idée est qu’il devrait y avoir une quantité limitée de tailles de police dans un document. Par exemple, une taille pour le corps de texte, quelques tailles pour les différents niveaux de titres et quelques tailles pour les indices, exposants et pied de pages. La clef de taille de police permettra à calibre de compartimenter les tailles de police dans le document entrant en différentes « boîtes » correspondantes aux différentes tailles de police logique.
Illustrons avec une exemple. Supposons que le document source que l’on convertit soit produit par quelqu’un qui possède une excellente acuité visuelle et utilise une taille de police de base de 8pt. Ce qui veut dire que la masse de texte du document est à 8pt, alors que les titres sont légèrement plus large (disons 10 et 12pt) et les pied de pages un peu plus petit à 6pt. Maintenant, si nous utilisons les paramètres suivant
Base font size : 12pt
Font size key : 7, 8, 10, 12, 14, 16, 18, 20
Le document de sortie aura une taille de police de base de 12pt, des titres de 14pt et 16pt et des pieds de pages de 8pt. Supposons maintenant que nous voulions que les plus gros titres ressortent mieux et que les pieds de pages soient aussi légèrement plus larges. Pour arriver à ce résultat, la clef de taille de police devrait être changée en
New font size key : 7, 9, 12, 14, 18, 20, 22
Le plus gros titres feront maintenant 18pt, alors que les pieds de pages feront 9pt. Vous pouvez jouer avec ces options pour essayer de trouver quels seraient les conditions optimale pour vous en utilisant l’assistant de redimensionnement des polices, qui peut être accédé en cliquant sur le petit bouton à coté du paramètre Clef de taille de police.
Tous les redimensionnements de taille de police peuvent aussi être désactivé ici, si vous désirez conserver les tailles de police du document original.
Un paramètre lié est Hauteur de ligne. Hauteur de ligne contrôle la longueur verticale des lignes. Par défaut, (une hauteur de ligne de 0), aucune manipulation n’est effectuée sur la hauteur des lignes. Si vous spécifiez une valeur différente de 0, la hauteur des lignes sera fixée à tous les endroits qui ne spécifient pas leur propre hauteur de ligne. Toutefois, cet outil est « brutal » et devrait être utilisé avec modération. Si vous voulez ajuster la hauteur des ligne de certaines section du fichier original, il vaut mieux utiliser le Extra-CSS.
Dans cette section, vous pouvez également dire à calibre d’incorporer toutes les polices référencées dans le livre. Cela permettra aux polices de fonctionner sur les liseuses même si elles ne sont pas disponibles sur le périphérique.
Texte¶
Le texte peut être justifié ou non. Le texte justifié comporte des espaces supplémentaires entre les mots pour donner une marge droite lisse. Certains préfèrent le texte justifié, d’autres non. Normalement, calibre conserve la justification dans le document original. Si vous voulez l’écraser, vous pouvez utiliser l’option Justification du texte dans cette section.
Vous pouvez également indiquer le calibre d”Améliorer la ponctuation qui remplacera les guillemets, tirets et ellipses par leurs alternatives typographiquement correctes. Notez que cet algorithme n’est pas parfait et qu’il vaut la peine d’examiner les résultats. L’inverse, à savoir, Simplifier la ponctuation est également disponible.
Enfin, il y a Encodage des caractères d’entrée. De vieux documents peuvent parfois ne pas spécifier leur encodage de caractère. Une fois convertis, cela peut entraîner une corruption des caractères ne faisant pas partie du français ou des caractères spéciaux comme les guillemets intelligents. calibre essaye de détecter automatiquement l’encodage de caractère du document source, mais n’y arrive pas toujours. Vous pouvez le forcer à supposer un encodage de caractère particulier en utilisant ce paramètre. cp1252 est un encodage classique pour les documents qui ont été réalisé par des programmes utilisant Windows. Vous devriez aussi lire Comment puis-je convertir mon fichier contenant des caractères non-anglais, ou des guillemets intelligents ? pour plus d’information sur les problèmes d’encodage.
Mise en page¶
Normalement, les paragraphes d’un fichier XHTML sont rendus avec un saut de ligne et sans retrait de texte. calibre a plusieurs paramètres qui permettent de contrôler cela. Retirer l’espace entre les paragraphes s’assure qu’aucun des paragraphes n’ont d’espace entre eux. Il fixe aussi le retrait de texte à 1.5em (cela peut être changé) pour marquer le début de chaque paragraphe. Insère une ligne vide fait l’opposé, garantissant qu’il y ait bien un saut de ligne entre chaque paragraphe. Chacun de ces paramètres sont complet, retirant les espaces, ou en insérant pour « tous » les paragraphes (techniquement, les balises <p> et <div>). Ceci est fait afin que vous puissiez régler le paramètre et être sûr qu’il fonctionne comme annoncé, quel que soit l’état du fichier original. La seule exception est lorsque le fichier d’origine utilise des sauts de ligne poussifs pour augmenter l’espace entre les paragraphes
Si vous souhaitez retirer l’espace entre tous les paragraphes à part une petite partie, n’utilisez pas ces options. Ajouter ces lignes de CSS au fichier Extra-CSS:
p, div { margin: 0pt; border: 0pt; text-indent: 1.5em }
.spacious { margin-bottom: 1em; text-indent: 0pt; }
Ensuite, dans le document source, marquer les paragraphes qui nécessite un espacement avec class= »spacious ». Si votre document original n’est pas en HTML, utiliser l’option de Débogage, décrite dans l’Introduction pour obtenir de l’HTML (utiliser le sous dossier input).
Une autre option utile est Transformer les tableaux en texte. Certains documents mal conçus utilisent les tableaux pour contrôler l’affichage du texte dans la page. Convertis, ces documents ont souvent le texte qui déborde de la page et d’autres dysfonctionnements. Cette option extraira le contenu des tableaux et le présentera dans un mode linéaire. Noter que cette option linéarise tous les tableaux, à utiliser uniquement si vous êtes sûr que le document source n’utilise pas de tableaux à des fins appropriées, comme la présentation de données.
Esthétique¶
L’option CSS supplémentaire vous permet de spécifier du CSS quelconque qui sera appliqué à tous les fichiers HTML dans la source. Ce CSS est appliqué en priorité et devrait donc outrepasser la plupart du CSS présent dans le document source lui-même. Vous pouvez utiliser ce paramètre pour mettre au point finement la présentation/disposition de votre document. Par exemple, si vous voulez que tous les paragraphes de class endnote soient alignés sur la droite, ajoutez juste
.endnote { text-align: right }
ou si vous souhaitez changer la découpure de chaque paragraphe
p { text-indent: 5mm; }
Extra CSS est une option très puissant, mais il est nécessaire de comprendre comment le CSS fonctionne pour pouvoir l’utiliser à son plein potentiel. Vous pouvez utiliser l’option pipeline de débogage ci-dessus pour voir quel CSS est présent dans votre document d’origine.
Une option plus simple est d’utiliser Filtrer l’information de style. Ceci vous permet de supprimer toutes les propriétés CSS, des types spécifiés, du document. Par exemple, vous pouvez l’utiliser pour supprimer toutes les couleurs ou polices.
Transformer les styles¶
Il s’agit de l’instrument le plus puissant en matière de style. Vous pouvez l’utiliser pour définir des règles qui modifient les styles en fonction de diverses conditions. Par exemple, vous pouvez l’utiliser pour changer toutes les couleurs vertes en bleu, ou supprimer tous les styles gras du texte ou colorier tous les titres d’une certaine couleur, etc.
Transformer du HTML¶
Similaire aux transformations de styles, mais vous permet d’apporter des modifications au contenu HTML du livre. Vous pouvez remplacer une balise par une autre, ajouter des classes ou d’autres attributs aux balises en fonction de leur contenu, etc.
Mise en page¶
Les options de Mise en page sont faites pour contrôler la disposition de l’écran, comme les marges et les tailles d’écran. Il comprend des options permettant de régler les marges des pages, qui seront utilisées par l’extension de sortie si le format de sortie supporte les marges. De plus, il vous faudra décider d’un profil d’entrée et d’un profil de Sortie. Chaque ensemble de profil gère comment interpréter les mesures dans les documents d’entrée/de sortie, les tailles d’écrans et les clefs de redimensionnement de police par défaut.
Si vous savez que le fichier que vous convertissez était destiné à être utilisé sur un dispositif/une plate-forme logicielle particulière, choisissez le profil d’entrée correspondant, sinon choisissez simplement le profil d’entrée par défaut. Si vous savez que les fichiers que vous produisez sont destinés à un type d’appareil particulier, choisissez le profil de sortie correspondant. Sinon, choisissez l’un des profils de sortie génériques. Si vous convertissez en MOBI ou AZW3, vous voudrez presque toujours choisir l’un des profils de sortie Kindle. Sinon, votre meilleur choix pour les appareils modernes de lecture de livres électroniques est de choisir le profil de sortie Generic e-ink HD.
Le profil de Sortie contrôle aussi la taille de l’écran. Ceci induira, par exemple, le redimensionnement automatique des images afin qu’elle tienne à l’écran pour certains formats de sortie. Choisissez donc un profil de périphérique qui a une taille proche de votre taille d’écran.
Traitement heuristique¶
Le traitement heuristique offre une variété de fonctions qui peuvent être utilisée pour détecter et corriger des problèmes communs dans des fichiers source médiocrement formatés. Utilisez cette option si votre document source souffre d’un formatage médiocre. Vu que ces fonctions reposent sur des modèles communs, sachez que dans certain cas le résultat peut s’avérer pire, à utiliser avec précaution donc. Par exemple, plusieurs de ces options retireront tous les espaces qui ne sont pas insécable, ou pourrait inclure des faux positifs dépendant de la fonction.
- Activer le traitement heuristique
Cette option active l’étape Traitement heuristique du pipeline de conversion de calibre. Elle doit être activée pour que différentes sous-fonctions s’appliquent.
- Redéfinir les lignes
Activer cette option forcera calibre à essayer de détecter et corriger les sauts de ligne brutaux qui existe au sein du document en utilisant des indices dans la ponctuation et la longueur des lignes. calibre essayera d’abord de déterminer si des sauts de ligne brutaux existent, et s’ils n’en apparaissent aucun calibre n’essayera pas de redéfinir les lignes. Le facteur de redéfinition des lignes peut-être réduit sir vous souhaitez « forcer » calibre à redéfinir les lignes
- Facteur de redéfinition des lignes
Cette option contrôle l’algorithme utilisé par calibre pour supprimer les ruptures de ligne. Par exemple, si la valeur de cette option est de 0,4, cela signifie que calibre supprimera les sauts de ligne à la fin des lignes dont la longueur est inférieure de 40 % de toutes les lignes du document. Si votre document ne comporte que quelques sauts de ligne qui doivent être corrigés, cette valeur doit être réduite à une valeur comprise entre 0,1 et 0,2.
- Détecter et mettre en forme les titres de chapitre et les sous-titres sans mise en forme
Si votre document n’a pas de format différent pour les titres et en-têtes de chapitre par rapport au reste du texte, calibre peut utiliser cette option pour essayer de les détecter et de les entourer d’une balise de titre. Des balises <h2> sont utilisées pour les en-têtes de chapitres; Des balises <h3> sont utilisées pour tout titre détectés.
Cette fonction ne créera pas une TdM, mais dans de nombreux cas, cela permettra à la détection des chapitres par défaut de calibre de détecter les chapitres correctement et de construire une TdM. Ajuster l’XPath sous Détection de la Structure si une TdM n’est pas créée automatiquement. S’il n’y a aucun autre titre utilisé dans le document, alors régler Détection de Structure à « //h:h2 » sera le moyen le plus simple de créer une TdM pour votre document.
Les titres insérés ne sont pas formaté, pour appliquer un format, utiliser l’option Extra CSS sous le paramètre Apparence et Présentation de conversion. Par exemple, pour centrer les titres, utiliser ceci
h2, h3 { text-align: center }
- Renuméroter les séquences de balises <h1> ou <h2>
Certains formats de publication utilise de multiple balises <h1> ou <h2> successivement pour leurs titres. Les paramètres de conversion par défaut de calibre couperont ces titres en 2 parties. Cette option renumérotera les balises de titre pour éviter cette scission.
- Supprime les lignes blanches entre les paragraphes
Cette option permet à calibre d’analyser les lignes vides incluses dans le document. Si chaque paragraphe est entrecoupé d’une ligne blanche, calibre supprimera tous ces paragraphes blancs. Les séquences de plusieurs lignes vides seront considérées comme des sauts de scène et conservées comme un seul paragraphe. Cette option diffère de l’option Supprimer l’espacement des paragraphes sous Apparence et présentation” Cette option peut également supprimer les paragraphes qui ont été insérés à l’aide de l’option :guilabel:`Insérer une ligne vide de calibre.
- Garantir une mise en forme cohérente des séparations entre deux scènes
Grâce à cette option, calibre essayera de détecter des marqueurs de ruptures de scènes commun et s’assurera qu’ils sont alignés au centre. Des marqueurs de rupture de scène « doux », càd les rupture de scène qui ne sont définies que par des espaces blanc additionel, sont créer pour s’assurer qu’ils ne s’affichent pas de pairs avec de saut de ligne.
- Remplacer les symboles de séparation de scène
Si cette option est configurée alors calibre remplacera les marqueurs de rupture de scène qu’il trouve avec le texte spécifié par l’utilisateur. Noter que certains caractères ornementaux peuvent ne pas être supportés sur tous les périphériques.
En général il vaudrait mieux éviter d’utiliser des balises HTML, calibre écartera toutes les balises et utilisera un balisage pré-défini. Les balises <hr />, càd les règles horizontales, et les balises <img> font exceptions. Les règles horizontales peuvent optionnellement être spécifiées dans les styles, si vous choisissez d’ajouter votre propre style pour vous assurer qu’il comprend le paramètre “largeur”, sinon les informations de style seront écartées. Les balises d’images peuvent être utilisées, mais calibre ne permet pas d’ajouter des images durant la conversion, cela doit être faire après coup en utilisant la fonctionnalité “Éditer le livre”.
- Exemple de balise d’image (placer l’image dans un dossier “Images” dans l’EPUB après conversion):
<img style= »width:10% » src= »../Images/scenebreak.png » />
- Exemple de règle horizontale avec styles:
<hr style= »width:20%;padding-top: 1px;border-top: 2px ridge black;border-bottom: 2px groove black; »/>
- Enlever les traits d’union superflus
calibre analysera tout le contenu présentant des traits d’union dans le document lorsque cette option est activée. Le document lui-même est utilisé en tant que base d’analyse. Cela permet à calibre de retirer avec précision les traits d’unions pour n’importe quel mot du document quelque soit la langue, ainsi que pour les mots inventés et les mots scientifiques. Le problème principal est que les mots n’apparaissant qu’une fois dans le document ne seront pas modifiés. L’analyse s’effectue en deux passages, le premier analyse les fins de lignes. Les lignes sont redéfinies uniquement si le mot existe avec ou sans trait d’union dans le document. Le second passage analyse tous les mots comprenant des traits d’union dans le document, les traits d’unions sont retirés si les mots existent autre part dans le document sans tiret.
- Mettre en italique les mots et les schémas usuels
Si active, calibre cherchera des mots et modèles qui dénote de l’italique et les mettra en italique. Par exemple les conventions habituelles de texte comme « mot » ou les phrases qui devrait normalement être en italique, par exemple les phrases latines comme “etc” ou “et cetera”
- Remplacer les mises en retrait par des retraits CSS
Certains documents prennent comme convention d’utiliser des espaces insécables pour les retraits de texte. Lorsque cette option est activée calibre tentera de détecter ce type de formatage et les convertira à un retrait de texte de 3% en utilisant le CSS.
Rechercher & remplacer¶
Ces options sont principalement utiles pour la conversion de documents PDF ou OCR, mais elles peuvent aussi être utilisée pour arranger beaucoup de documents avec des problèmes spécifiques. Par exemple, certaines conversion laissent des en-têtes ou des pieds de page dans le texte. Ces options utilisent des expressions régulière pour essayer de détecter en-têtes, pied de page et autres textes quelconques pour les retirer ou les remplacer. Gardez en tête qu’ils opèrent sur le fichier XHTML intermédiaire produit par le pipeline de conversion. Il existe un assistant pour vous aidez à customiser les expressions habituelles dans votre document. Cliquez sur la baguette magique sous le la boîte de dialogue, et puis sur le bouton “Test” après avoir entrer votre expression de recherche. Les résultats probant seront surlignés en Jaune
La recherche fonctionne en utilisant une expression habituelle en Python. Tout le texte identifié sera retiré ou remplacer par le modèle de remplacement. Le modèle de remplacement est optionnel, si laissé blanc alors le texte correspondant à la recherche sera supprimé du document. Vous pouvez en apprendre plus sur les expressions régulières et leur syntaxe dans Tout à propos de l’utilisation des expressions régulières dans calibre.
Détection de la structure¶
La détection de structure pousse calibre à essayer de détecter au mieux les éléments structuraux dans le document original, quand ils ne sont pas spécifiés correctement. Par exemple, les chapitres, saut de page, en-tête, pied de page, etc. Comme vous pouvez l’imaginer, ce processus change grandement d’un livre à l’autre. Heureusement, calibre a de puissantes options pour le contrôler. Avec la puissance vient la complexité, mais une fois que vous avez pris le temps de comprendre cette complexité, vous vous rendrez compe que votre effort en valait le coup.
Chapitres et sauts de page¶
calibre a deux ensemble d’options pour détection des chapitres et insertion des sauts de page. Cela peut parfois être légèrement déboussolant, car par défaut, calibre insérera automatiquement un saut de page après un chapitre détecté mais aussi après les endroits perçu par l’option de détection de saut de page. La raison est qu’il existe de nombreux emplacements où des sauts de page devrait être inséré mais qui ne sont pas des limites de chapitres. Aussi, les chapitres détecté peuvent optionnellement être inséré dans la Table des Matières générée automatiquement.
calibre utilise XPath, un langage puissant pour permettre à l’utilisateur de spécifier les limites de chapitres/sauts de page. XPath peut sembler un peu décourageant au premier abord, mais heureusement, il y a le tutoriel XPath dans le Manuel de l’Utilisateur. Gardez en tête que la Détection de la structure s’opère sur le fichier XHML intermédiaire produit par le pipeline de conversion. Utilisez l’option de débogage décrite dans Introduction pour comprendre les paramètres appropriés pour votre livre. Il existe aussi un bouton pour un assistant XPath pour vous aider à générer des expressions XPath simples.
Par défaut, calibre utilise les expressions suivantes pour la détection de chapitre:
//*[((name()='h1' or name()='h2') and re:test(., 'chapter|book|section|part\s+', 'i')) or @class = 'chapter']
Cette expression est assez complexe, car elle essaye de gérer un certain nombre de cas généraux simultanément. Ce qui veut dire que calibre considérera que les chapitres commencent soit à des balises <h1> ou <h2> qui ont les mots (chapitre, livre, section ou partie) en elles ou qui ont l’attribut class= »chapter ».
Une option apparentée est Marque de chapitre, qui vous permet de contrôler ce que calibre fait lorsqu’il détecte des chapitres. Par défaut, il insérera un saut de page avant le chapitre. Vous pouvez aussi insérez une ligne à la place, ou en plus du saut de page. Il peut aussi ne rien faire.
Le paramètre par défaut pour détecter les sauts de page est
//*[name()='h1' or name()='h2']
ce qui veut dire que calibre insérera un saut de page avant chaque balise <h1> et <h2> par défaut.
Note
Les expressions par défaut peuvent changer en fonction du format d’origine que vous convertissez.
Divers¶
Il y a quelque options de plus dans cette section.
- Insérer les métadonnées sur une page au début du livre
Une des choses pratique avec calibre c’est qu’il vous permet d’entretenir des métadonnées très complètes sur tous vos livres, par exemple un classement, les étiquettes, les commentaires, etc. Cette option créera une page unique avec toutes les métadonnées et l’insérera dans le livre numérique converti, habituellement juste après la couverture. Pensez-y pour créer votre propre jaquette personnalisée.
- Retirer la première image
Parfois, le document source que vous convertissez inclue la couverture dans le livre, au lieu de la séparer. Si vous spécifiez aussi une couverture dans calibre, alors le livre converti en aura deux. Cette option enlèvera simplement la première image du document source, s’assurant ainsi que le livre converti à uniquement une couverture, celle spécifiée dans calibre.
Table des matières¶
Quand le document source a une Table des Matières dans ses métadonnées, calibre l’utilisera simplement. Cependant, soit certain vieux formats ne supportent pas les Table des Matières intégrée dans les métadonnées, soit certains livres n’en ont tout simplement pas. Dans ces cas là, les options dans cette section peuvent vous aider à générer automatiquement une Table des Matières dans le livre numérique converti, basée sur le contenu réel du document source.
Note
L’utilisation de ces options peut être un peu difficile pour un résultat parfait. Si vous préférez créer/éditer la Table des Matières à la main, convertissez en EPUB ou en AZW3 et sélectionner la case en bas de la section Table des Matières dans la boite de dialogue de conversion intitulé Affiner la Table des matière manuellement après conversion. Ceci lancera l’éditeur de TdM après la conversion. Cela permet de créer des entrées dans la Table des Matières simplement en cliquant dans le livre à l’endroit où vous voulez que l’entrée pointe. Vous pouvez aussi utiliser l’éditeur de TdM seul, sans conversion. Allez à Préférences → Interface → Barre d’Outils et ajouter Éditeur de TdM à la barre d’outil principale. Sélectionner alors simplement le livre que vous souhaitez éditer et cliquez sur le bouton Éditeur de TdM.
La première option est Utilisation forcée de la Table des Matières générée automatiquement. En cochant cette option vous pouvez forcer calibre à outrepasser toutes les Table des Matières qu’il trouve dans les métadonnées du document source et à en générer une.
La manière de fonctionner par défaut de la création de Table des Matières automatique est que, calibre essayera d’abord d’ajouter tout chapitres détectés à la table des matières générée. Vous pouvez apprendre comment personnaliser la détection des chapitres dans la section Détection de la structure ci-dessus. Si vous ne souhaitez pas inclure les chapitres détectés dans la table des matières générée, coché l’option Ne pas ajouter les chapitres détectés.
Si moins de chapitres que Seuil de chapitre sont détecté, calibre ajoutera alors tout hyperlien qu’il trouve dans le document à la Table des Matières. Cela fonctionne souvent bien car beaucoup de document source incluent dans la Table des Matières en lien hypertexte. L’option Nombre de lien peut être utilisée pour contrôler ce comportement. Si fixé à zéro, aucun lien ne sera ajouté. Si fixé à un nombre plus grand que zéro, le nombre de chapitre ajouté sera maximum de ce nombre.
calibre filtrera automatiquement les doublons dans la Table des Matières générée. Cependant, s’il y a d’autres entrées indésirable, vous pouvez les filtrer en utilisant l’option Filtre TdM. Ceci est une expression régulière qui fera correspondre le titre des entrées dans la table des matières générée. Dès qu’une correspondance est trouvée, elle sera supprimée. Par exemple, pour retirer toutes les entrée « Next » ou « Previous » utiliser
Next|Previous
L’option TdM niveau 1,2,3 vous permet de créer une Table des Matières sophistiquée à plusieurs niveaux. Ce sont des expressions XPath qui correspondent à des balises dans le fichier XHTML intermédiaire produit par le pipeline de conversion. Voir Introduction sur comment avoir accès à ce fichier XHTML. Lire aussi le Tutoriel XPath, pour apprendre comment construire des expressions XPath. À côté de chacune des options il y a un bouton qui lance un assistant pour aider à la création d’expressions XPath basiques. Les exemples suivant illustreront comment utiliser ces options.
Supposons que vous avez un document source qui donne un fichier XHTML qui ressemble à ceci :
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<title>Sample document</title>
</head>
<body>
<h1>Chapter 1</h1>
...
<h2>Section 1.1</h2>
...
<h2>Section 1.2</h2>
...
<h1>Chapter 2</h1>
...
<h2>Section 2.1</h2>
...
</body>
</html>
Alors, nous fixons les options à
Level 1 TOC : //h:h1
Level 2 TOC : //h:h2
Ceci résultera en une Table des Matières générée automatiquement à deux niveaux qui ressemblera à
Chapter 1
Section 1.1
Section 1.2
Chapter 2
Section 2.1
Avertissement
Les formats de sortie ne supportent pas tous les Tables des Matières à plusieurs niveaux. Il vaut mieux d’abord essayer en format EPUB. Si cela fonctionne, alors essayez votre format de préférence.
Utiliser des images comme titre de chapitre en convertissant des documents sources en HTML.¶
Supposons que vous souhaitiez utiliser une image comme titre de chapitre, mais vous souhaitez toujours que calibre soit capable de générer automatiquement une Table des Matières pour vous à partir des titres des chapitres. Utilisez le balisage HTML suivant pour faire cela :
<html>
<body>
<h2>Chapter 1</h2>
<p>chapter 1 text...</p>
<h2 title="Chapter 2"><img src="chapter2.jpg" /></h2>
<p>chapter 2 text...</p>
</body>
</html>
Fixer le paramètre TdM à 1 niveau à //h:h2`. Ensuite, pour le chapitre deux, calibre prendra le titre à partir de la valeur de l'attribut ``title sur la balise <h2>, vu que la balise ne contient aucun texte.
Utiliser les attributs de balise pour le texte des entrées dans la Table des Matières¶
Si vous avez des chapitres particulièrement long et que vous souhaitez des versions raccourcies dans la Table des Matières, vous pouvez utiliser les attributs de titre pour atteindre cela, par exemple :
<html>
<body>
<h2 title="Chapter 1">Chapter 1: Some very long title</h2>
<p>chapter 1 text...</p>
<h2 title="Chapter 2">Chapter 2: Some other very long title</h2>
<p>chapter 2 text...</p>
</body>
</html>
Fixer le paramètre TdM à 1 niveau à //h:h2/@title. Alors calibre prendra le titre dans la valeur de l’attribut title sur les balises <h2>, au lieu d’utiliser le texte dans la balise. Noter le /@title restant dans l’expression XPath, vous pouvez utiliser ceci pour dire à calibre de prendre le texte de n’importe quel attribut.
Comment les options sont définies/sauvegardées pour la conversion¶
Il existe deux endroits où les options de conversions peuvent être fixées dans calibre. La première est dans Préférences->Conversion. Ces paramètres sont ceux par défaut pour les options de conversions. Dès que vous essayerez de convertir un nouveau livre, les paramètres fixés ici seront utilisés par défaut.
Vous pouvez aussi changer les paramètres dans la boite de dialogue de conversion à chaque conversion de livre. Quand vous convertissez un livre, calibre se souvient des paramètres utilisés pour ce livre, et si vous souhaitez le convertir à nouveau, les paramètres sauvés pour ce livre auront priorité sur les paramètres par défaut fixés dans Préférences. Vous pouvez ramener les paramètres individuels à ceux par défaut en utilisant le bouton Restaurer par défaut dans la boite de dialogue de conversion du livre susmentionné. Vous pouvez retirer des paramètres sauvegardés pour un groupe de livre en sélectionnant tous les livres et en cliquant sur le bouton Édition des métadonnées, pour ouvrir la boîte de dialogue de l’éditeur de métadonnées multiples, il existe une option pour retirer des paramètres de conversion sauvegardés au pied de cette fenêtre
Lorsque vous convertissez par lot un ensemble de livres, les paramètres sont pris dans l’ordre suivant (le dernier l’emporte):
De paramètres par défaut fixés dans Préférences->Conversion
Des paramètres de conversion sauvé pour chaque livre converti (s’ils existent). Ceci peut-être désactivé par l’option dans le coin supérieur gauche de la boîte de dialogue de Conversion par Lot.
Des paramètres fixés dans la boîte de dialogue de la Conversion par Lot
Notez que les paramètres finaux pour chaque livre dans une Conversion par Lot sera sauvegardé et réutilisé si ce livre est à nouveau converti. Vu que la priorité la plus haute dans la Conversion par Lot est donnée aux paramètres de la Conversion par Lot, ceux-ci surpasseront tous les paramètres spécifiques de livre. Convertissez donc uniquement par lot des livres qui nécessitent des paramètres similaires. Les exceptions sont les métadonnées et les paramètres de formats entrant spécifique. Vu que la boîte de dialogue de Conversion par Lot n’a pas de paramètres pour ces deux catégories, ils seront pris des paramètres spécifiques du livre (s’ils existent) ou de ceux par défaut.
Note
Vous pouvez voir quels sont les paramètres qui ont été utilisés durant n’importe quelle conversion en cliquant sur l’icone tournante dans le coin inférieur droit, puis en double cliquant sur la tache de conversion individuelle. Ceci fera apparaître un journal de conversion qui contiendra les paramètres qui ont effectivement été utilisé, en haut.
Conseil spécifique au format¶
Vous trouverez ici des conseils spécifique quant à la conversion de formats particulier. Les options spécifiques à chaque format, d’entrée ou de sortie, sont disponibles dans le dialogue de conversion sous leur propre section, par exemple Entrée TXT ou Sortie EPUB.
Convertir des documents Mircosoft Word¶
calibre peut convertir automatiquement des fichiers .docx créer par Microsoft Word 2007 et plus récent. Ajoutez simplement le fichier dans calibre et cliquez sur convertir.
Note
Il y a un fichier .docx de démonstration qui illustrent les capacités du moteur de conversion de calibre. Téléchargez-le et convertissez-le en EPUB ou en AZW3 pour voir ce que calibre peut faire.
calibre générera automatiquement une Table des Matières à partir des titres si vous marquez vos titres avec les styles Titre 1, Titre 2, etc. dans Microsoft Word. Ouvrez le livre numérique sorti dans la Visionneuse de livre numérique de calibre et cliquez sur le bouton Table des Matières pour voir la Table des Matières générée.
Des fichiers .doc plus ancien¶
Pour des fichiers .doc plus ancien, vous pouvez sauver le document en HTML avec Microsoft Word et ensuite convertir le fichier HTML qui en résulte avec calibre. En sauvant en HTML, soyez sûr d’utiliser l’option « Sauvegarder comme une page Web, Filtrée » car cela produira un HTML propre qui se convertira facilement. Notez que Word produit de très mauvais fichier HTML, la conversion peut prendre beaucoup de temps, soyez donc patient. Si vous possédez une version plus récente de Word, vous pouvez aussi le sauver directement en .docx.
Une autre alternative est d’utiliser le logiciel gratuit LibreOffice. Ouvrez votre fichier .doc dans LibreOffice et enregistrez-le au format .docx, qui peut être directement converti dans calibre.
Convertir des documents TXT¶
Les documents TXT n’ont aucun moyen bien définis de spécifié le formatage de texte comme le gras, l’italique, etc., ou la structure du document comme les paragraphes, les titres, les sections et ainsi de suite, mais il y une variété de conventions qui sont habituellement utilisées. Par défaut, calibre tente de détecter automatiquement le formatage et le balisage adéquat en fonction de ces conventions.
L’entrée TXT comporte un certain nombre d’option pour différencié comment les paramètres sont détectés.
- Style de paragraphe: Auto
Analyse le fichier texte et essaye de déterminer automatiquement comment les paragraphes sont définis. Cette option fonctionne généralement bien, si les résultats obtenus ne sont pas bon, essayez l’une des options manuelles.>
- Style de paragraphe : Bloc
Considère que les limites de paragraphes sont un saut de ligne ou plus
This is the first. This is the second paragraph.- Style de paragraphe: Unique
Considère que chaque ligne est un paragraphe:
This is the first. This is the second. This is the third.- Style de paragraphe: Imprimé
Considère que chaque paragraphe commence avec un retrait de texte (soit un tab ou plus de 2 espaces). Les paragraphes finissent quand la prochaine ligne commençant avec un retrait est atteinte.
This is the first. This is the second. This is the third.- Style de paragraphe: Non formaté
Considère que le document n’a pas de formatage, mais utilise des sauts de lignes « dûr ». La ponctuation et des lignes de demi-longueur sont utilisée pour recréer les paragraphes.
- Style de formatage: Automatique
Essaye de détecter le type de balisage de formatage. Si aucun balisage n’est utilisé alors le formatage heuristique sera utilisé.
- Style de formatage: Heuristique
Analyse le document pour des en-têtes de chapitres communs, des ruptures de scènes, et des mots en italique et applique le balisage HTML approprié durant la conversion.
- Style de formatage: Markdown
calibre supporte également la syntaxe Markdown pour les entrées TXT. Le Markdown permet d’ajouter un formatage basique au document TXT, comme du gras, de l’italique, des en-têtes de section, des tableaux, des listes, une Table des Matières, etc. Marquer le titre des chapitres avec un # (p. ex. : # Mon titre) et paramétrer l’expression XPath de détection des chapitres à « //h:h1 » est la manière la plus simple de générer une bonne Table des Matières à partir d’un document TXT. Vous pouvez en apprendre plus sur la syntaxe Markdown ici : daringfireball.
- Style de formatage: Aucun
N’applique aucun formatage spécial au texte, le document est converti en HTML sans aucun changement.
Conversion de documents PDF¶
Les documents PDF sont les pires formats à partir desquels on peut convertir. C’est un format à taille de page et placement de texte fixe. Ce qui veut dire qu’il est très difficile de déterminer où un paragraphe commence et l’autre finit. calibre essayera de déballer mes paragraphes en utilisant un Facteur de déballage de ligne. Ceci est une échelle utilisée pour déterminer la longueur à laquelle les lignes devraient être déballée. Les valeurs valide sont des décimaux se trouvant entre 0 et 1. LA valeur par défaut est 0.45, juste en dessous de la moitié de la longueur d’une ligne. Descendez cette valeur si vous souhaitez inclure plus de texte au déballage. Augmentez pour en inclure moins. Vous pouvez ajuster cette valeur dans les paramètres de conversion sous guilabel:Entrée PDF.
Aussi, ils ont souvent des en-têtes et des pieds de page qui font partie du document et qui seront inclus dans le texte. Utilisez l’option Rechercher et remplacer pour retirer les en-têtes et pieds de pages pour réduire ce problème. Si les en-têtes et pieds de page ne sont pas supprimés cela peu endommager le déballage des paragraphes. Pour apprendre à utiliser les options de suppression d’en-tête et de pieds de page, lire Tout à propos de l’utilisation des expressions régulières dans calibre.
Quelques limitations des entrée PDF sont:
Les documents complexe, à multiple colonne et basé sur des images ne sont pas supportés
L’extraction d’image vectorielle et de tableau à partir du document ne sont pas supportées non plus.
Certains PDF utilisent des glyphes spéciaux pour représenter ll ou ff ou fi, etc. La conversion ce ceux-ci pourrait ne pas marcher simplement en fonction de comment ils sont représenté à l’intérieur du PDF.
Les liens et les Tables des Matières ne sont pas supportés
Les PDFs qui utilisent des polices non-Unicode intégrée pour représenter des caractères qui ne font pas partie du français engendreront une sortie tronquée pour ces caractères
Certain PDF sont fait de photographies de page avec du texte reconnu par OCR derrière elles. Dans ces cas là, calibre utilise le texte venant de l’OCR, qui peut être fort différent de ce que vous voyez dans le fichier PDF.
Les PDFs utilisés pour afficher du texte complexe, comme des langages lu de droite à gauche et les composition mathématiques ne se convertiront pas bien
Pour répéter le PDF est un vraiment, vraiment mauvais format à utilisé comme source. Si vous devez absolument utiliser du PDF, alors soyez prêt à trouver un fichier de sortie se trouvant n’importe où entre décent et inutilisable, dépendant du PDF source.
Collections de Bandes Dessinées¶
Une collection de bandes dessinée est un fichier .cbc. Un fichier .cbc est un ZIP qui contient d’autres fichiers CBZ/CBR. Le fichier .cbc doit aussi contenir un simple fichier texte appelé comics.txt, encodé en UTF-8. Le fichier comics.txt doit contenir une liste des bandes dessinées contenue dans le fichier .cbc, sous la forme nom_du_fichier:titre, comme illustré ci-dessous:
one.cbz:Chapter One
two.cbz:Chapter Two
three.cbz:Chapter Three
Le fichier .cbc contiendra alors:
comics.txt
one.cbz
two.cbz
three.cbz
calibre convertira automatiquement ce fichier .cbc en un livre numérique avec une Table des Matières pointant vers chaque entrée dans comics.txt
Démonstration de formatage d’EPUB avancée¶
Divers formatages avancés pour les fichiers EPUB sont expliqués dans ce fichier de démonstration. Le fichier a été créé à partir d’HTML codé à la main en utilisant calibre et est destiné à être utilisé comme modèle pour vos efforts de création d’EPUB.
L’HTML source à partir duquel il a été créé est disponible ici demo.zip. Les paramètres utilisés pour créer l’EPUB à partir du ZIP sont
ebook-convert demo.zip .epub -vv --authors "Kovid Goyal" --language en --level1-toc '//*[@class="title"]' --disable-font-rescaling --page-breaks-before / --no-default-epub-cover
Notez que vu que ce fichier explore le potentiel de l’EPUB, la plupart des formatages avancés ne fonctionneront pas sur des lecteurs moins capable que le lecteur intégré de calibre.
Convertir des documents ODT¶
calibre peut convertir directement les fichiers ODT (OpenDocument Text). Vous devriez utilisé les styles pour formater votre document et minimiser l’utilisation de formatage direct. En insérant des images dans votre document, vous devez les ancrer aux paragraphes, les images qui sont ancrées aux pages finiront au début de la conversion.
Pour permettre la détection automatique des chapitres, vous devez les marquer avec les styles intégrés appelés Heading 1, Heading 2, …, Heading 6 (Heading 1 équivaut à la balise HTML <h1>, Heading 2 à <h2>, etc). Lorsque vous convertissez dans calibre, vous pouvez indiquer le style que vous avez utilisé dans la case Détecter les chapitres à. Exemple :
Si vous marquez les chapitres avec le style Heading 2, vous devez définir la case « Détecter les chapitres à » sur //h:h2`.
Pour une table des matières imbriquée avec des sections marquées par Heading 2 et des chapitres marqués par Heading 3, vous devez entrer
//h:h2|//h:h3. Sur la page Convertir - Table des matières, mettez la case Niveau 1 de la Table des matières à `//h:h2` et la case Niveau 2 de la Table des matières à `//h:h3`.
Les propriétés de document bien connues (Titre, Mots-clefs, Description, Créateur) sont reconnues et calibre utilisera la première image (pas trop petite, et avec de bonnes proportions) comme image de couverture.
Il y a aussi un mode de propriété avancé de conversion qui est activé en définissant la propriété personnalisée opf.metadata (de type “Oui ou Non”) à Oui dans votre document ODT (Fichier->Propriétés->Propriétés personnalisées). Si cette propriété est détectée par calibre, les propriétés personnalisées suivantes sont reconnues (opf.authors remplace le créateur du document):
opf.titlesort
opf.authors
opf.authorsort
opf.publisher
opf.pubdate
opf.isbn
opf.language
opf.series
opf.seriesindex
De plus, vous pouvez spécifier l’image à utiliser comme couverture en la nommant opf.cover (clic droit, Image->Options->Nom) dans le fichier ODT. Si aucune image de ce nom n’est trouvée, la méthode «intelligente» est utilisée. La détection de la couverture pourrait entraîner des couvertures en double dans certains formats de sortie, le processus supprimera le paragraphe (uniquement si le seul contenu est la couverture!) du document. Mais cela ne fonctionne que avec l’image nommée!
Pour désactiver la détection de couverture vous pouvez définir la propriété personnalisée opf.nocover (de type “Oui ou Non”) à Oui en mode avancé.
Convertir en PDF¶
Le premier paramètre, le plus important, à décider lors de la conversion en PDF est la taille de la page. Par défaut, calibre utilise une taille de page « U.S. Letter ». Vous pouvez changer ceci vers un autre standard de taille de page ou une taille complètement personnalisée dans la section Sortie PDF de la boîte de dialogue de conversion. Si vous générez un PDF à utiliser sur un périphérique spécifique, vous pouvez activer, à la place, l’option pour utiliser la taille de page à partir de Profil de sortie de l’onglet Mise en page de la boîte de dialogue de conversion. De cette façon, si votre profil de sortie est paramétré sur Kindle, calibre créera un PDF avec une taille de page adaptée pour la lecture sur le petit écran Kindle.
Table des Matières imprimable¶
Vous pouvez aussi ajouter une Table des Matières imprimable à la fin du PDF qui liste le numéro de page de chaque section. Ceci est très pratique si vous comptez imprimer le PDF sur papier. Si vous souhaitez utiliser le PDF sur un support électronique, alors l’Aperçu PDF permet cette fonctionnalité et est généré par défaut.
Vous pouvez personnaliser l’aspect de la Table des Matières générée en utilisant le paramètre de conversion Extra CSS sous Apparence dans la boite de dialogue de conversion. Le CSS utilisé par défaut est listé ci-dessous, copier le simplement et appliquer tous les changements que vous souhaitez.
.calibre-pdf-toc table { width: 100%% }
.calibre-pdf-toc table tr td:last-of-type { text-align: right }
.calibre-pdf-toc .level-0 {
font-size: larger;
}
.calibre-pdf-toc .level-1 td:first-of-type { padding-left: 1.4em }
.calibre-pdf-toc .level-2 td:first-of-type { padding-left: 2.8em }
Marges de page personnalisées pour les fichiers HTML individuels¶
Si vous convertissez un EPUB ou AZW3 avec plusieurs fichiers HTML individuels à l’intérieur et que vous souhaitez modifier les marges de page pour un fichier HTML particulier, vous pouvez ajouter le bloc de style suivant au fichier HTML en utilisant l’éditeur de livre numérique de calibre :
<style>
@page {
margin-left: 10pt;
margin-right: 10pt;
margin-top: 10pt;
margin-bottom: 10pt;
}
</style>
Ensuite, dans la section sortie PDF de la boîte de dialogue de conversion, activez l’option Utiliser les marges de page du document à convertir. Maintenant toutes les pages générées à partir de ce fichier HTML auront des marges 10pt.