 Alterar Idioma
Alterar IdiomaConversão de E-book¶
O calibre tem um sistema de conversão que é projetado para ser muito fácil de usar. Normalmente, você só adiciona um livro ao calibre, clica em converter e o calibre tentará criar um resultado o mais próximo possível da origem. Contudo, o calibre aceita um número muito grande de formatos de origem e uns não são tão adequados quanto outros para conversão em ebooks. No caso de tais formatos de origem, ou se você quer apenas um controle maior sobre o sistema de conversão, o calibre tem uma gama de opções para ajustar o processo de conversão. Note, contudo, que o sistema de conversão do calibre não é um substituto de um editor de ebooks completo. Para editar ebooks eu recomendo que primeiro se converta para EPUB ou AZW3, usando o calibre e, então, usar a função ‘Editar Livro’ para o ajustá-lo. Você poderá, então, utilizar o ebook já editado e converter o mesmo em outros formatos dentro do calibre.
Esse documento fará referência principalmente às configurações de conversão, da maneira como são encontradas na caixa de diálogo de conversão, mostrada na figura abaixo. Todas essas configurações também estão disponíveis por meio da interface de linha de comando para conversão, esclarecida em ebook-convert. Dentro do calibre, você pode obter ajuda sobre qualquer configuração individual, mantendo seu mouse sobre ela. Uma dica irá aparecer, descrevendo a configuração.
Introdução¶
A primeira coisa a entender sobre o sistema de conversão é que ele é projetado como um pipeline e pode ser esquematizado da seguinte forma:
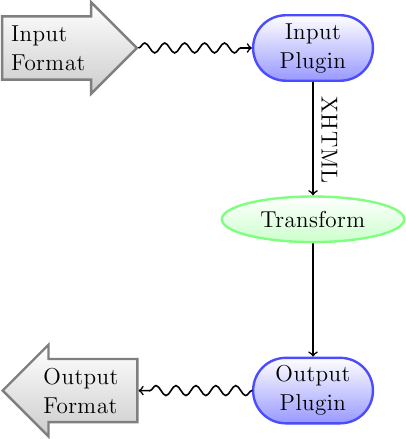
Primeiramente, o formato de entrada é convertido em XHTML pelo plugin de entrada adequado. Então o HTML é transformado. Por fim, o XHTML processado é convertido no formato de saída pelo plugin de saída apropriado. Os resultados da conversão podem variar muito, de acordo com o formado de entrada, alguns são mais bem convertidos do que outros. Uma lista dos melhores formatos de origem para conversão está disponível aqui.
As transformações sobre XHTML de saída são onde todo o trabalho acontece. Há diversas transformações, como a inserção dos metadados do livro como página no início do livro, a criação do Sumário com base nos títulos dos capítulos e o ajuste proporcional do tamanho das fontes. Importante lembrar que todas as transformações no XHTML de saída se devem ao plugin de entrada, e não ao arquivo de entrada propriamente. Assim, para ser convertido de RTF em EPUB, o arquivo é antes convertido internamente em XHTML, que recebe as várias transformações e só então o plugin de saída cria o arquivo EPUB, gerando automaticamente todos os metadados, o Sumário etc.
Você pode ver esse processo em ação usando a opção de depuração  . Basta especificar o caminho para uma pasta para a saída de depuração. Durante a conversão, o calibre colocará o XHTML gerado pelos vários estágios do pipeline de conversão em diferentes subpastas. As quatro subpastas são:
. Basta especificar o caminho para uma pasta para a saída de depuração. Durante a conversão, o calibre colocará o XHTML gerado pelos vários estágios do pipeline de conversão em diferentes subpastas. As quatro subpastas são:
Pasta |
Descrição |
|---|---|
entrada |
Contém o HTML de saída gerado pelo plugin de entrada. Use-o para depurar o plugin de entrada. |
analisado |
É o resultada do pré-processamento da saída e conversão em XHTML pelo plugin de entrada. Use-o para depurar a detecção da estrutura. |
estrutura |
Pós detecção de estrutira, mas antes do achatamento de CSS e conversão de tamanho de fonte. Utilizado para depurar a conversão de fonte e transformação de CSS. |
processado |
Logo antes de o e-book passar para o plugin de saída. Use-o para depurar o plugin de saída. |
Se você quiser editar o documento de entrada um pouco antes de convertê-lo, a melhor coisa a fazer é editar os arquivos na subpasta :file:’input’, compactá-lo e usar o arquivo ZIP como formato de entrada para conversões subsequentes. Para fazer isso, use a caixa de diálogo :guilabel:’Editar meta informações’ para adicionar o arquivo ZIP como um formato para o livro e, em seguida, no canto superior esquerdo da caixa de diálogo de conversão, selecione ZIP como o formato de entrada.
Aqui são tratadas várias transformações que atuam no XHTML intermediário e como controlá-las. Ao final, são apresentadas dicas específicas para cada tipo de formato de entrada/saída.
Aparência¶
Esse conjunto de opções controla vários aspectos da aparência do e-book convertido.
Fontes¶
One of the nicest features of the e-reading experience is the ability to easily adjust font sizes to suit individual needs and lighting conditions. calibre has sophisticated algorithms to ensure that all the books it outputs have consistent font sizes, no matter what font sizes are specified in the input document.
O tamanho básico da fonte de um documento é o tamanho mais comum no referido documento, isto é, o tamanho do volume de texto no documento. Quando você especificar :guilabel:’Base font size’, calibre automaticamente redimensionará todos os tamanhos de fonte no documento proporcionalmente, de modo que o tamanho de fonte mais comum torna-se o tamanho básico de fonte especificado e os outros tamanhos de fonte são redimensionados adequadamente. Ao escolher um tamanho básico de fonte maior, você pode tornar as fontes do documento maior ou vice-versa Quando você define o tamanho básico da fonte, para melhores resultados, você deve também definir o tamanho da fonte chave.
Via de regra, o calibre escolhe automaticamente um tamanho-padrão de fonte adequado para o perfil de saída que você escolheu (leia Configurar Página). No entanto, você pode alterá-lo aqui, caso o padrão não esteja adequado.
A opção :guilabel:’Font size key’ permite controlar como tamanho não-básico de fonte é redimensionado. O algoritmo de redimensionamento de fonte trabalha utilizando um tamanho de fonte chave, que é simplesmente uma lista de tamanhos de fonte separados por vírgula. O tamanho da fonte chave diz ao calibre quantos “passos” maior ou menor um determinado tamanho de fonte deve ser comparado com o tamanho básico da fonte. A ideia é deve ter um número limitado de tamanhos de fonte no documento. Por exemplo, um tamanho para o texto do corpo, alguns tamanhos de diferentes níveis de título e alguns super/sub scripts e notas de rodapé. O tamanho da fonte chave permite ao calibre compartamentalizar o tamanho das fontes nos documentos de entrada em “caixotes” separados correspondendo aos diferentes tamanhos de fonte lógicos.
Vamos ilustrar com um exemplo. Suponha que o documento de origem que estamos convertendo foi produzido por alguém com uma visão excelente e tem uma tamanho básico de fonte de 8pt. Isso significa que a maior parte do texto no documento está dimensionado em 8pts, enquanto os títulos são um pouco maior (digamos 10 e 12 pt) e as notas de rodapé um pouco menor em 6pt. Agora se nós usamos as seguintes configurações:
Base font size : 12pt
Font size key : 7, 8, 10, 12, 14, 16, 18, 20
O documento de saída terá um tamanho básico de fonte de 12pt, títulos de 14 e 16pt e notas de rodapé de 8pt. Agora, suponha que queremos que o título de maior tamanho se destaque e as notas de rodapé um pouco maior também. Para conseguir isso, o tamanho de fonte chave deve ser alterado para :
New font size key : 7, 9, 12, 14, 18, 20, 22
O título maior agora será de 18pt, enquanto as notas de rodapé serão de 9pt. Você pode jogar com estas configurações para tentar descobrir qual seria a melhor configuração usando o assistente de redimensionamento, que pode ser acessado clicando no pequeno botão ao lado da definição de :guilabel:’Font size key’
Todo o redimensionamento do tamanho da fonte feita na conversão pode ser desativada aqui, se você quiser preservar o tamanho das fontes do documento de entrada.
Uma configuração relacionada é a Altura da linha, que controla o tamanho vertical das linhas de texto. Por padrão (altura da linha 0), não há manipulação da altura das linhas. Se você especificar um valor diferente, a altura vai ser aplicada a todos os locais que não tiverem seu próprio valor. No entanto, trata-se de um recurso arriscado e deve ser usado com cautela. Para ajustar a altura de linha de uma seção do arquivo de entrada, prefira Extra CSS.
Nessa seção, você ainda pode configurar o calibre para embutir as fontes citadas no livro, o que permite que as fontes operem no dispositivo de leitura, mesmo que não estejam disponíveis nele.
Texto¶
O texto pode ou não ser justificado. Um texto justificado apresenta mais espaço entre as palavras para uniformizar a margem direita. Nem todo mundo gosta de texto justificado. Normalmente, o calibre retém a justificação no documento original. Para alterar o padrão, use a opção Texto justificado nessa seção.
Você pode ainda configurar o calibre para Pontuação inteligente, que substitui aspas, traços e reticências sem formatação pelas alternativas tipográficas corretas. O algoritmo, no entanto, não é perfeito, e o resultado precisa ser revisto. Também está disponível um algorítimo contrário, a Pontuação não inteligente.
Finalmente, existe: guilabel: Codificação de caracteres de entrada. Documentos antigos às vezes não especificam a codificação de caracteres. Quando convertido, isso pode resultar em caracteres não ingleses ou caracteres especiais, como aspas inteligentes, sendo corrompidos. O calibre tenta detectar automaticamente a codificação de caracteres do documento de origem, mas nem sempre é bem-sucedido. Você pode forçá-lo a assumir uma codificação de caracteres específica usando essa configuração. cp1252 é uma codificação comum para documentos produzidos usando o software Windows. Você também deve ler: ref: char-encoding-faq para mais informações sobre problemas de codificação.
Layout¶
Normalmente, os parágrafos em XHTML são renderizados com uma linha em branco entre eles e sem recuo de texto inicial. O calibre tem algumas opções para controlar isso. : guilabel: Remova o espaçamento entre parágrafos ‘forçosamente, assegure que todos os parágrafos não tenham espaçamento entre parágrafos. Também define o recuo do texto como 1,5em (pode ser alterado) para marcar o início de cada parágrafo. : guilabel: `Inserir linha em branco faz o oposto, garantindo que exista exatamente uma linha em branco entre cada par de parágrafos. Ambas as opções são muito abrangentes, removendo o espaçamento ou inserindo-o em * todos * parágrafos (tecnicamente e tags). Isso é para que você possa definir a opção e garantir que ela funcione conforme anunciado, independentemente de como o arquivo de entrada esteja confuso. A única exceção é quando o arquivo de entrada usa quebras de linha rígida para implementar o espaçamento entre parágrafos.
Se você deseja remover o espaçamento entre todos os parágrafos, exceto alguns selecionados, não use essas opções. Em vez disso, adicione o seguinte código CSS a: ref: `CSS extra
p, div { margin: 0pt; border: 0pt; text-indent: 1.5em }
.spacious { margin-bottom: 1em; text-indent: 0pt; }
Em seguida, no documento de origem, marque os parágrafos que precisam de espaçamento com ‘class=”spacious”’. Se o documento de entrada não estiver em HTML, use a opção Depurar, descrita na Introdução para obter HTML (use a subpasta :file:’input’).
Another useful option is Linearize tables. Some badly designed documents use tables to control the layout of text on the page. When converted these documents often have text that runs off the page and other artifacts. This option will extract the content from the tables and present it in a linear fashion. Note that this option linearizes all tables, so only use it if you are sure the input document does not use tables for legitimate purposes, like presenting tabular information.
Estilização¶
A opção: guilabel: CSS extra permite especificar CSS arbitrário que será aplicado a todos os arquivos HTML na entrada. Esse CSS é aplicado com prioridade muito alta e, portanto, deve substituir a maioria dos CSS presentes no próprio ** documento de entrada **. Você pode usar esta configuração para ajustar a apresentação / layout do seu documento. Por exemplo, se você quiser que todos os parágrafos da classe endnote estejam alinhados à direita, basta adicionar:
.endnote { text-align: right }
ou se você quiser trocar para a o entalhe de todos os parágrafos:
p { text-indent: 5mm; }
:guilabel:’Extra CSS’ é uma opção muito poderosa, mas você precisa enter como funciona o CSS para usar todo seu potencial. Você pode usar a opção de debug pipeline descrita acima para ver como o CSS está presente em seu documento de entrada.
Uma opção mais simples é usar: guilabel: Filtrar informações de estilo. Isso permite remover todas as propriedades CSS dos tipos especificados do documento. Por exemplo, você pode usá-lo para remover todas as cores ou fontes.
Transformar estilos¶
Esta é a instalação mais poderosa relacionada ao estilo. Você pode usá-lo para definir regras que mudam de estilo com base em várias condições. Por exemplo, você pode usá-lo para alterar todas as cores verdes para azuis ou remover todo o estilo em negrito do texto ou colorir todos os títulos de uma determinada cor, etc.
Transformar HTML¶
Similar a transformar estilos, mas permite fazer alterações no conteúdo HTML do livro. Você pode substituir uma tapa por outra, adicionar classes ou outros atribuir às tags com base em seu conteúdo, etc.
Configurar Página¶
As opções: guilabel: Page setup são para controlar o layout da tela, como margens e tamanhos de tela. Existem opções para configurar as margens da página, que serão usadas pelo plug-in de saída, se o formato de saída selecionado suportar as margens da página. Além disso, você deve escolher um perfil de entrada e um perfil de saída. Ambos os conjuntos de perfis lidam basicamente com como interpretar medições nos documentos de entrada / saída, tamanhos de tela e teclas de redimensionamento de fonte padrão.
Se você sabe que o arquivo que está convertendo se destina a ser usado em um determinado dispositivo/plataforma de software, escolha o perfil de entrada correspondente, caso contrário, basta escolher o perfil de entrada padrão. Se você sabe que os arquivos que está produzindo são destinados a um tipo de dispositivo, escolha o perfil de saída correspondente. Caso contrário, escolhe um dos perfis de saída Genéricos. Se você está estiver convertendo para MOBI ou AZW3, então você quase sempre vai querer escolher um dos perfis de saída para Kindle. Fora isso, sua melhor aposta para dispositivos modernos de leitura de Ebook é escolher o perfil de saída: Generic e-ink HD.
O perfil de saída também controla o tamanho da tela. Isso fará com que, por exemplo, as imagens sejam redimensionadas automaticamente para caberem na tela em alguns formatos de saída. Portanto, escolha o perfil de um dispositivo com tamanho de tela semelhante ao seu.
Processamento heurístico¶
O processamento heurístico fornece uma variedade de funções que podem ser usadas para tentar detectar e corrigir problemas comuns em documentos de entrada mal formatados. Use essas funções se o documento de entrada sofrer uma formatação ruim. Como essas funções dependem de padrões comuns, saiba que, em alguns casos, uma opção pode levar a piores resultados, portanto, use com cuidado. Como exemplo, várias dessas opções removerão todas as entidades sem espaço de quebra ou podem incluir correspondências falsas positivas relacionadas à função.
- :guilabe:’Habilitar processamento heurístico’
Esta opção ativa o estágio calibre’s: guilabel: Heuristic processing do pipeline de conversão. Isso deve estar ativado para que várias sub-funções sejam aplicadas
- :guilabel:’Eliminar quebra de linhas’
A ativação dessa opção fará com que o calibre tente detectar e corrigir quebras de linha rígida existentes em um documento usando pistas de pontuação e comprimento de linha. O calibre primeiro tentará detectar se existem quebras de linha rígida; se elas não parecem existir, o calibre não tentará desembrulhar as linhas. O fator de desembrulhar da linha pode ser reduzido se você quiser ‘forçar’ o calibre a desembrulhar as linhas.
- :guilabel:’Fator de eliminação de quebras de linha’
Essa opção controla o calibre do algoritmo usado para remover quebras de linha rígidas. Por exemplo, se o valor dessa opção for 0,4, isso significa que o calibre removerá quebras de linha rígidas do final de linhas cujos comprimentos são menores que o comprimento de 40% de todas as linhas no documento. Se o documento tiver apenas algumas quebras de linha que precisam de correção, esse valor deve ser reduzido para algo entre 0,1 e 0,2.
- :guilabel:’Detectar e formatar capítulos não formatados e subtítulos’
Se o documento não tiver títulos de capítulo e títulos formatados de forma diferente do restante do texto, o calibre poderá usar essa opção para tentar detectá-los e cercá-los com tags de cabeçalho. <h2> são usadas para títulos de capítulos; <h3> são usadas para todos os títulos detectados.
Esta função não criará um sumário, mas em muitos casos fará com que as configurações padrão de detecção de capítulo do calibre detectem corretamente capítulos e construam um sumário. Ajuste o XPath em Detecção de estrutura se um sumário não for criado automaticamente. Se não houver outros títulos usados no documento, a configuração “// h: h2” em Detecção de estrutura seria a maneira mais fácil de criar um sumário para o documento.
Os cabeçalhos inseridos não são formatados, para aplicar a formatação, use a opção: guilabel: CSS extra nas configurações de conversão Aparência. Por exemplo, para centralizar tags de cabeçalho, use o seguinte
h2, h3 { text-align: center }
- Renumerar as sequências de etiquetas <h1> ou <h2>
Alguns editores formatam os cabeçalhos dos capítulos usando várias ou tags sequencialmente. as configurações de conversão padrão do calibre farão com que esses títulos sejam divididos em duas partes. Esta opção renumerará as tags de cabeçalho para evitar a divisão.
- :guilabel:’Apagar linhas em branco entre parágrafos’
Essa opção fará com que o calibre analise as linhas em branco incluídas no documento. Se cada parágrafo for intercalado com uma linha em branco, o calibre removerá todos esses parágrafos em branco. Sequências de várias linhas em branco serão consideradas quebras de cena e mantidas como um único parágrafo. Essa opção difere da opção :guilabel:’Remove paragraph espaçamento’ em :guilabel:’Look and Feel’ porque ela realmente modifica o conteúdo HTML, enquanto a outra opção modifica os estilos do documento. Essa opção também pode remover parágrafos que foram inseridos usando a opção :guilabel:’Inserir linha em branco’ do calibre.
- :guilabel:’Assegura que as quebras de cena estejam formatadas consistentemente’
Com esta opção, o calibre tentará detectar marcadores comuns de quebra de cena e garantir que eles estejam alinhados ao centro. Os marcadores de quebra de cena ‘suaves’, ou seja, quebras de cena definidas apenas por espaço em branco extra, são estilizados para garantir que eles não sejam exibidos em conjunto com as quebras de página.
- :guilabel:’Substituir quebras de cena’
Se esta opção estiver configurada então o calibre irá substituir os marcadores de quebra de cena que encontrar com o texto de substituição especificado pelo usuário. Por favor, note que alguns caracteres ornamentais podem não ser suportados em todos os dispositivos de leitura.
Em geral, você deve evitar o uso de tags HTML, o calibre descartará todas as tags e usará a marcação predefinida. tags, ou seja, regras horizontais, e tags são exceções. As regras horizontais podem opcionalmente ser especificadas com estilos; se você optar por adicionar seu próprio estilo, inclua a configuração ‘width’, caso contrário, as informações de estilo serão descartadas. As tags de imagem podem ser usadas, mas o calibre não fornece a capacidade de adicionar a imagem durante a conversão. Isso deve ser feito após o fato, usando o recurso ‘Editar livro’.
- Exemplo de tag de imagem (coloque a imagem em uma pasta ‘Imagens’ dentro do EPUB após a conversão):
<img style=”width:10%” src=”../Images/scenebreak.png” />
- Exemplo de régua horizontal com estilos:
1
- :guilabel:’ Remover hífens desnecessários’
calibre vai analisar todo o conteúdo hifenizado no documento quando essa opção for ativada. O documento propriamente dito é utilizado como um dicionário para análise. Isto permite ao calibre remover com precisão hífens de qualquer palavra no documento em qualquer idioma, juntamente com palavras científicas obscuras e inventadas. A principal desvantagem são palavras que aparecem apenas uma única vez n o documento que não será alterado. A análise acontece em dois passos, o primeiro passo analisa finais de linha. Linhas só são descobertas, se a palavra existir com ou sem um hífen no documento. O segundo passo analisa todas as palavras com hífen em todo o documento, hifens são removidos se a palavra existe em outras partes do documento sem uma combinação.
- :guilabel:’Colocar em itálico palavras e padrões comuns’
Quando ativado, o calibre procurará palavras e padrões comuns que denotam itálico e itálico. Exemplos são convenções de texto comuns, como ~ palavras ~ ou frases que geralmente devem estar em itálico, por exemplo frases latinas como ‘etc.’ ou ‘et cetera’.
- :guilabel:’Substituir a identação de entidade por CSS’
Alguns documentos usam uma convenção de definição de recuos de texto usando entidades de espaço sem quebra. Quando essa opção está ativada, o calibre tentará detectar esse tipo de formatação e convertê-los em um recuo de texto de 3% usando CSS.
Buscar & Substituir¶
These options are useful primarily for conversion of PDF documents or OCR conversions, though they can also be used to fix many document specific problems. As an example, some conversions can leave behind page headers and footers in the text. These options use regular expressions to try and detect headers, footers, or other arbitrary text and remove or replace them. Remember that they operate on the intermediate XHTML produced by the conversion pipeline. There is a wizard to help you customize the regular expressions for your document. Click the magic wand beside the expression box, and click the ‘Test’ button after composing your search expression. Successful matches will be highlighted in Yellow.
A pesquisa funciona usando uma expressão regular do Python. Todo o texto correspondente é simplesmente removido do documento ou substituído usando o padrão de substituição. O padrão de substituição é opcional, se deixado em branco, o texto correspondente ao padrão de pesquisa será excluído do documento. Você pode aprender mais sobre expressões regulares e sua sintaxe em: ref: regexptutorial.
Detecção da Estrutura¶
Detecção de estrutura envolve a tentativa do calibre dar o seu melhor para detectar elementos estruturais no documento de entrada, quando eles não estão devidamente especificados. Por exemplo, capítulos, quebras de página, cabeçalhos, rodapés, etc. Como você pode imaginar, este processo varia muito de livro para livro. Felizmente, o calibre tem opções muito poderosas para controlar isso. Com o poder vem a complexidade, mas se uma vez que você leva um tempo para aprender a complexidade, você bem que vai achar que vale o esforço.
Capítulos e quebras de página¶
calibre has two sets of options for chapter detection and inserting page breaks. This can sometimes be slightly confusing, as by default, calibre will insert page breaks before detected chapters as well as the locations detected by the page breaks option. The reason for this is that there are often locations where page breaks should be inserted that are not chapter boundaries. Also, detected chapters can be optionally inserted into the auto generated Table of Contents.
O calibre usa * XPath *, uma linguagem poderosa para permitir ao usuário especificar limites de capítulos / quebras de página. O XPath pode parecer um pouco assustador de se usar no começo, felizmente, existe: ref: XPath tutorial no Manual do Usuário. Lembre-se de que a detecção de estrutura opera no XHTML intermediário produzido pelo pipeline de conversão. Use a opção de depuração descrita em: ref: conversion-Introduction para descobrir as configurações apropriadas para o seu livro. Há também um botão para um assistente XPath para ajudar na geração de expressões XPath simples.
Por padrão, o Calibre usa a seguinte expressão para detectar capítulos:
//*[((name()='h1' or name()='h2') and re:test(., 'chapter|book|section|part\s+', 'i')) or @class = 'chapter']
Essa expressão é bastante complexa, porque tenta lidar com vários casos comuns simultaneamente. O que isso significa é que o calibre assumirá que os capítulos começam com `` ou `` tags com qualquer uma das palavras (capítulo, livro, seção ou parte) nelas ou que tenham o atributo class =” chapter “.
Uma opção relacionada é: guilabel: Marca do capítulo, que permite controlar o calibre quando detecta um capítulo. Por padrão, ele inserirá uma quebra de página antes do capítulo. Você pode inserir uma linha ordenada em vez de ou além da quebra de página. Você também pode fazer com que não faça nada.
A configuração padrão para a detecção de quebra de página é:
//*[name()='h1' or name()='h2']
o que significa que o calibre irá inserir a quebras de página antes de cada tag <h1> e <h2> por padrão.
Nota
A expressão padrão pode depender do formato de entrada que você está convertendo.
Extras¶
Existem algumas outras opções para esta seção.
- :guilabel:’Inserir os metadados como uma página no início do livro’
Uma das grandes vantagens do calibre é que ele permite que você mantenha metadados muito completos sobre todos os seus livros, por exemplo, uma classificação, tags, comentários etc. Essa opção criará uma única página com todos esses metadados e inseri-los em o e-book convertido, normalmente logo após a capa. Pense nisso como uma maneira de criar sua própria capa de livro personalizada.
- : guilabel: Remover primeira imagem
Às vezes, o documento de origem que você está convertendo inclui a capa como parte do livro, em vez de como uma capa separada. Se você também especificar uma capa no calibre, o livro convertido terá duas capas. Essa opção simplesmente remove a primeira imagem do documento de origem, garantindo assim que o livro convertido tenha apenas uma capa, a especificada no calibre.
Índice¶
Quando o documento de entrada tem um índice em seus metadados, o calibre apenas o usa. No entanto, vários formatos mais antigos não suportam um índice baseado em metadados ou documentos individuais não o possuem. Nesses casos, as opções nesta seção podem ajudá-lo a gerar automaticamente um Sumário no e-book convertido, com base no conteúdo real no documento de entrada.
Nota
O uso dessas opções pode ser um pouco desafiador para ser exatamente correto. Se você preferir criar / editar o Índice manualmente, converta para os formatos EPUB ou AZW3 e marque a caixa de seleção na parte inferior da seção Índice da caixa de diálogo de conversão que diz: guilabel: Ajuste manualmente o Índice de Conteúdo após a conversão ». Isso iniciará a ferramenta ToC Editor após a conversão. Ele permite que você crie entradas no Sumário simplesmente clicando no local do livro em que deseja que a entrada aponte. Você também pode usar o ToC Editor por si só, sem fazer uma conversão. Vá para: guilabel: `Preferências-> Interface-> Barras de Ferramentas e adicione o: guilabel:` ToC Editor` à barra de ferramentas principal. Depois, basta selecionar o livro que deseja editar e clicar no botão: guilabel: ToC Editor.
A primeira opção é: guilabel: `Força o uso do índice gerado automaticamente ‘. Ao marcar esta opção, você pode substituir o calibre de qualquer Índice encontrado nos metadados do documento de entrada pelo gerado automaticamente.
A maneira padrão pela qual a criação do Índice gerado automaticamente funciona é que, o calibre tentará primeiro adicionar os capítulos detectados ao índice gerado. Você pode aprender como personalizar a detecção de capítulos na seção: ref: structure-detection acima. Se você não deseja incluir capítulos detectados no índice gerado, marque a opção: guilabel: Não adicione capítulos detectados.
Se for detectado um número inferior ao número de capítulos :guilabel:’Chapter threshold’, o calibre adicionará quaisquer hiperlinks encontrados no documento de entrada ao Índice. Isso geralmente funciona bem: muitos documentos de entrada incluem um Sumário com hiperlink logo no início. A opção :guilabel:’Número de links’ pode ser usada para controlar esse comportamento. Se definido como zero, nenhum link será adicionado. Se definido como um número maior que zero, no máximo esse número de links será adicionado.
calibre will automatically filter duplicates from the generated Table of Contents. However, if there are some additional undesirable entries, you can filter them using the TOC Filter option. This is a regular expression that will match the title of entries in the generated table of contents. Whenever a match is found, it will be removed. For example, to remove all entries titles “Next” or “Previous” use:
Next|Previous
As opções: guilabel: Nível 1,2,3 TOC permitem criar um sofisticado Índice multinível. São expressões XPath que correspondem a tags no XHTML intermediário produzido pelo pipeline de conversão. Veja o: ref: conversion-Introduction para obter acesso a este XHTML. Leia também o: ref: xpath-tutorial, para aprender como construir expressões XPath. Ao lado de cada opção há um botão que inicia um assistente para ajudar na criação de expressões XPath básicas. O exemplo simples a seguir ilustra como usar essas opções.
Suppose you have an input document that results in XHTML that looks like this:
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<title>Sample document</title>
</head>
<body>
<h1>Chapter 1</h1>
...
<h2>Section 1.1</h2>
...
<h2>Section 1.2</h2>
...
<h1>Chapter 2</h1>
...
<h2>Section 2.1</h2>
...
</body>
</html>
Então, nós colocamos a opção como:
Level 1 TOC : //h:h1
Level 2 TOC : //h:h2
Isto vai resultar em um sumário automaticamente gerado que se parece como:
Chapter 1
Section 1.1
Section 1.2
Chapter 2
Section 2.1
Aviso
Nem todos os formatos de saída suportam um índice multinível. Você deve primeiro tentar com a saída EPUB. Se isso funcionar, tente o seu formato de escolha.
Usando imagens como títulos de capítulos ao converter documentos de entrada HTML¶
Suponha que você queira usar uma imagem como título do capítulo, mas ainda queira que o calibre seja capaz de gerar automaticamente um Índice para você a partir dos títulos dos capítulos. Use a seguinte marcação HTML para conseguir isso:
<html>
<body>
<h2>Chapter 1</h2>
<p>chapter 1 text...</p>
<h2 title="Chapter 2"><img src="chapter2.jpg" /></h2>
<p>chapter 2 text...</p>
</body>
</html>
Defina a configuração: guilabel: Nível 1 TOC como` // h: h2`. Então, para o capítulo dois, o calibre assumirá o título do valor do atributo `` title`` na tag `` ``, pois a tag não possui texto.
Usando atributos de tag para fornecer o texto para entradas no Sumário¶
Se você possui títulos de capítulo particularmente longos e deseja versões reduzidas no Sumário, pode usar o atributo title para conseguir isso, por exemplo:
<html>
<body>
<h2 title="Chapter 1">Chapter 1: Some very long title</h2>
<p>chapter 1 text...</p>
<h2 title="Chapter 2">Chapter 2: Some other very long title</h2>
<p>chapter 2 text...</p>
</body>
</html>
Defina a configuração: guilabel: Nível 1 TOC como` // h: h2 / @ title`. Em seguida, o calibre assumirá o título do valor do atributo `` title`` nas tags `` , em vez de usar o texto dentro da tag. Observe o `` / @ title à direita na expressão XPath, você pode usar este formulário para dizer ao calibre para obter o texto de qualquer atributo que você desejar.
Modo como as opções são definidas/guardadas para a conversão¶
Existem dois locais onde as opções de conversão podem ser definidas no calibre. O primeiro está em Preferências-> Conversão. Essas configurações são os padrões para as opções de conversão. Sempre que você tentar converter um novo livro, as configurações definidas aqui serão usadas por padrão.
Você também pode alterar as configurações na caixa de diálogo de conversão para cada conversão de livro. Quando você converte um livro, o calibre lembra as configurações usadas para esse livro, de modo que, se você o converter novamente, as configurações salvas para o livro individual terão precedência sobre os padrões definidos em: guilabel: Preferências. Você pode restaurar as configurações individuais aos padrões usando o botão: guilabel: Restaurar padrões na caixa de diálogo de conversão de livros individual. Você pode remover as configurações salvas de um grupo de livros selecionando todos os livros e clicando no botão: guilabel: Editar metadados para abrir a caixa de diálogo de edição em massa de metadados. Na parte inferior da caixa de diálogo, há uma opção para remover a conversão armazenada. definições.
Quando você converte em massa um conjunto de livros, as configurações são feitas na seguinte ordem (a última vence):
Dos padrões definidos em Preferências-> Conversão
Nas configurações de conversão salvas para cada livro que está sendo convertido (se houver). Isso pode ser desativado pela opção no canto superior esquerdo da caixa de diálogo de conversão em massa.
Nas configurações definidas na caixa de diálogo Conversão em massa
Observe que as configurações finais de cada livro em uma conversão em massa serão salvas e reutilizadas se o livro for convertido novamente. Como a prioridade mais alta na conversão em massa é dada às configurações na caixa de diálogo Conversão em massa, elas substituem as configurações específicas de cada livro. Portanto, você deve converter em massa apenas livros que precisam de configurações semelhantes. As exceções são metadados e configurações específicas do formato de entrada. Como a caixa de diálogo de conversão em massa não possui configurações para essas duas categorias, elas serão retiradas das configurações específicas do livro (se houver) ou dos padrões.
Nota
Você pode ver as configurações reais usadas durante qualquer conversão clicando no ícone rotativo no canto inferior direito e clicando duas vezes no trabalho de conversão individual. Isso exibirá um log de conversão que conterá as configurações reais usadas, na parte superior.
Formatar dicas específicas¶
Aqui você encontrará dicas específicas para a conversão de formatos específicos. Opções específicas para um formato específico, se entrada ou saída, estão disponíveis na caixa de diálogo de conversão em sua própria seção, por exemplo, TXT input ou` EPUB output`.
Converter documentos do Microsoft Word¶
O calibre pode converter automaticamente arquivos `` .docx`` criados pelo Microsoft Word 2007 e mais recentes. Basta adicionar o arquivo ao calibre e clicar em converter.
Nota
Existe um :download_arquivo:`demo .docx arquivo <demos/demo.docx>` que demonstra as capacidades do mecanismo de conversão do Calibre. Basta baixá-lo e convertê-lo para EPUB ou AZW3 para ver o que o Calibre pode fazer.
O calibre gerará automaticamente um Sumário com base nos títulos, se você os marcar com os estilos `` Título 1 ‘’, `` Título 2 ‘’ etc. no Microsoft Word. Abra o e-book de saída no visualizador de e-books de calibre e clique no botão: guilabel: Table of Contents para visualizar o Table of Contents gerado.
Arquivos .doc mais antigos¶
Para arquivos .doc mais antigos, é possível salvar o documento como HTML com o Microsoft Word e, em seguida, converter o arquivo HTML resultante com o -*Calibre``. Ao salvar como HTML, use a opção “Salvar como página da Web filtrada”, pois isso produzirá HTML limpo e com boa conversão. Observe que o Word produz um HTML muito confuso, convertê-lo pode demorar muito tempo, portanto, seja paciente. Se você tiver uma versão mais recente do Word disponível, poderá salvá-la diretamente como .docx.
Outra alternativa é usar o LibreOffice gratuito. Abra seu arquivo .doc no LibreOffice e salve-o como .docx, que pode ser convertido diretamente no Calibre.
converter documentos em TXT¶
Os documentos TXT não têm uma maneira bem definida de especificar a formatação, como negrito, itálico, etc., ou a estrutura do documento, como parágrafos, títulos, seções e assim por diante, mas há uma variedade de convenções comumente usadas. Por padrão, o calibre tenta a detecção automática da formatação e marcação corretas com base nessas convenções.
A entrada TXT suporta várias opções para diferenciar como os parágrafos são detectados.
- : guilabel: Estilo de parágrafo: Automático
Analisa o arquivo de texto e tenta determinar automaticamente como os parágrafos são definidos. Essa opção geralmente funciona bem, se você obtiver resultados indesejáveis, tente uma das opções manuais
- : guilabel: Estilo de parágrafo: Bloco
Assume que uma ou mais linhas em branco são um limite de parágrafo:
This is the first. This is the second paragraph.- : guilabel: Estilo de parágrafo: Único
Assume que toda linha é um parágrafo
This is the first. This is the second. This is the third.- : guilabel: Estilo do parágrafo: Imprimir
Supõe que todo parágrafo comece com um recuo (uma guia ou mais de 2 espaços). Os parágrafos terminam quando a próxima linha que começa com um recuo é atingida
This is the first. This is the second. This is the third.- Paragraph style: Unformatted
Supõe que o documento não tenha formatação, mas usa quebras de linha rígida. A pontuação e o comprimento médio da linha são usados para tentar recriar parágrafos.
- : guilabel: Estilo de formatação: Automático
Tenta detectar o tipo de marcação de formatação que está sendo usada. Se nenhuma marcação for usada, a formatação heurística será aplicada.
- : guilabel: Estilo de formatação: Heurístico
Analisa o documento em busca de títulos de capítulos comuns, quebras de cena e palavras em itálico e aplica a marcação HTML apropriada durante a conversão.
- : guilabel: Estilo de formatação: Markdown
O calibre também suporta a entrada TXT em execução através de um pré-processador de transformação conhecido como Markdown. O Markdown permite que a formatação básica seja adicionada aos documentos TXT, como negrito, itálico, títulos de seção, tabelas, listas, um Sumário etc. Marcando os títulos dos capítulos com um número inicial e definindo a expressão de detecção XPath do capítulo como “// h: h1 “é a maneira mais fácil de obter um índice adequado gerado a partir de um documento TXT. Você pode aprender mais sobre a sintaxe do Markdown em daringfireball <https://daringfireball.net/projects/markdown/syntax> _.
- : guilabel: Estilo de formatação: Nenhum
Não aplica formatação especial ao texto, o documento é convertido em HTML sem outras alterações.
Converter documentos PDF¶
Documentos PDF são um dos piores formatos para converter. Eles são um tamanho de página fixo e formato de posicionamento de texto. Ou seja, é muito difícil determinar onde termina um parágrafo e começa outro. O calibre tentará desembrulhar parágrafos usando um fator configurável, :guilabel:’Line un-wrapping factor’. Esta é uma escala usada para determinar o comprimento no qual uma linha deve ser desembrulhada. Os valores válidos são decimais entre 0 e 1. O padrão é 0,45, logo abaixo do comprimento médio da linha. Diminua esse valor para incluir mais texto na desquebragem. Aumentar para incluir menos. Você pode ajustar esse valor nas configurações de conversão em :guilabel:’PDF Input’.
Além disso, eles geralmente têm cabeçalhos e rodapés como parte do documento que será incluído com o texto. Use o painel :guilabel:’Pesquisar e substituir’ para remover cabeçalhos e rodapés para atenuar esse problema. Se os cabeçalhos e rodapés não forem removidos do texto, ele poderá descartar a desquebra do parágrafo. Para saber como usar as opções de remoção de cabeçalho e rodapé, leia :ref:’regexptutorial’.
Algumas limitações do processamento de PDF são:
Documentos complexos, multi colunares e baseados em imagens não são suportados.
Extração de imagens vetorizadas e tabelas de dentro do documento também não são suportadas.
Alguns PDFs usam glifos especiais para representar ll ou ff ou fi, etc. A conversão destes pode ou não funcionar, dependendo de como eles são representados internamente no PDF.
Links e Índices não são suportados
PDFs que usam fontes não-Unicode incorporadas para representar caracteres que não estejam em inglês resultarão em saída distorcida para esses caracteres
Alguns PDFs são compostos de fotografias da página com texto OCR por trás deles. Nesses casos, o calibre usa o texto OCR, que pode ser muito diferente do que você vê ao exibir o arquivo PDF
PDFs usados para exibir texto complexo, como idiomas da direita para a esquerda e tipografia matemática, não serão convertidos corretamente
Reiterar ** PDF é um formato muito, muito ruim ** para ser usado como entrada. Se você precisar absolutamente usar o PDF, esteja preparado para uma saída que varia de decente a inutilizável, dependendo do PDF de entrada.
Coleções de quadrinhos¶
Uma coleção de quadrinhos é um arquivo .cbc. Um arquivo .cbc é um arquivo ZIP que contém outros arquivos CBZ / CBR. Além disso, o arquivo .cbc deve conter um arquivo de texto simples chamado comics.txt, codificado em UTF-8. O arquivo comics.txt deve conter uma lista dos arquivos de quadrinhos dentro do arquivo .cbc, no formato filename: title, como mostrado abaixo:
one.cbz:Chapter One
two.cbz:Chapter Two
three.cbz:Chapter Three
O arquivo .cbc conterá:
comics.txt
one.cbz
two.cbz
three.cbz
calibre will automatically convert this .cbc file into an e-book with a Table of Contents pointing to each entry in comics.txt.
Exemplo de formatação avançada de um EPUB¶
Várias formatações avançadas para arquivos EPUB são demonstradas neste :d ownload_file:’demo file <demos/demo.epub>’. O arquivo foi criado a partir de HTML codificado à mão usando calibre e destina-se a ser usado como um modelo para seus próprios esforços de criação de EPUB.
O HTML de origem a partir do qual ele foi criado está disponível :d ownload_file:’demo.zip <demos/demo.zip>’. As configurações usadas para criar o EPUB a partir do arquivo ZIP são:
ebook-convert demo.zip .epub -vv --authors "Kovid Goyal" --language en --level1-toc '//*[@class="title"]' --disable-font-rescaling --page-breaks-before / --no-default-epub-cover
Observe que, como esse arquivo explora o potencial do EPUB, a maior parte da formatação avançada não funciona em leitores menos capazes que o visualizador EPUB integrado do calibre.
Converter documentos ODT¶
O calibre pode converter diretamente arquivos ODT (OpenDocument Text). Você deve usar estilos para formatar seu documento e minimizar o uso da formatação direta. Ao inserir imagens no documento, você precisa ancorá-las ao parágrafo, as imagens ancoradas em uma página acabam na frente da conversão.
Para permitir a detecção automática de capítulos, você precisa marcá-los com os estilos internos chamados :guilabel:’Heading 1’, :guilabel:’Heading 2’, …, :guilabel:’Heading 6’ (:guilabel:’Heading 1’ equivale à tag HTML ‘’<h1>’’, :guilabel:’Posições 2’ a ‘’<h2>’’, etc). Quando você converte em calibre, você pode inserir qual estilo você usou na caixa :guilabel:’Detectar capítulos em’. Exemplo:
If you mark Chapters with style Heading 2, you have to set the ‘Detect chapters at’ box to
//h:h2Para um sumário aninhado com Seções marcadas com :guilabel:’Título 2’ e os Capítulos marcados com :guilabel:’Título 3’, você precisa digitar ‘’//h:h2|//h:h3’’. Na página Converter - sumário, defina a caixa :guilabel:’Level 1 TOC’ como ‘’//h:h2’’ e a caixa :guilabel:’Level 2 TOC’ como ‘’//h:h3’’.
Well-known document properties (Title, Keywords, Description, Creator) are recognized and calibre will use the first image (not too small, and with good aspect-ratio) as the cover image.
Há também um modo avançado de conversão de propriedades, que é ativado ao definir a propriedade personalizada `` opf.metadata`` (tipo ‘Sim ou Não’) como Sim no seu documento ODT (Arquivo-> Propriedades-> Propriedades Personalizadas). Se essa propriedade for detectada pelo calibre, as seguintes propriedades personalizadas serão reconhecidas (`` opf.authors`` substitui o criador do documento)
opf.titlesort
opf.authors
opf.authorsort
opf.publisher
opf.pubdate
opf.isbn
opf.language
opf.series
opf.seriesindex
Além disso, você pode especificar a imagem a ser usada como capa, nomeando-a como `` opf.cover`` (clique com o botão direito do mouse em Imagem-> Opções-> Nome) na ODT. Se nenhuma imagem com esse nome for encontrada, o método ‘inteligente’ será usado. Como a detecção de capa pode resultar em capas duplas em determinados formatos de saída, o processo removerá o parágrafo (somente se o único conteúdo for a capa!) Do documento. Mas isso funciona apenas com a imagem nomeada!
Para desativar a detecção de capa, você pode definir a propriedade personalizada `` of.no cover`` (tipo ‘Yes or No’) para Yes no modo avançado.
Convertendo para PDF¶
A primeira configuração, mais importante, para decidir ao converter para PDF é o tamanho da página. Por padrão, o calibre usa um tamanho de página de “U.S. Letter”. Você pode alterar isso para outro tamanho de página padrão ou um tamanho completamente personalizado na seção :guilabel:’PDF Output’ da caixa de diálogo de conversão. Se você estiver gerando um PDF para ser usado em um dispositivo específico, poderá ativar a opção para usar o tamanho da página a partir do perfil :guilabel:’output profile’. Portanto, se o seu perfil de saída estiver definido como Kindle, o calibre criará um PDF com tamanho de página adequado para visualização na pequena tela do Kindle.
Índice imprimível¶
Você também pode inserir um Índice imprimível no final do PDF que lista os números de página para cada seção. Isso é muito útil se você pretende imprimir o PDF em papel. Se você deseja usar o PDF em um dispositivo eletrônico, o Esboço do PDF fornece essa funcionalidade e é gerado por padrão.
É possível personalizar a aparência do Sumário gerado usando a configuração de conversão CSS extra na parte Aparência da caixa de diálogo de conversão. O CSS padrão usado está listado abaixo, basta copiá-lo e fazer as alterações desejadas.
.calibre-pdf-toc table { width: 100%% }
.calibre-pdf-toc table tr td:last-of-type { text-align: right }
.calibre-pdf-toc .level-0 {
font-size: larger;
}
.calibre-pdf-toc .level-1 td:first-of-type { padding-left: 1.4em }
.calibre-pdf-toc .level-2 td:first-of-type { padding-left: 2.8em }
Margens de página personalizadas para arquivos HTML individuais¶
Se você estiver convertendo um arquivo EPUB ou AZW3 com vários arquivos HTML individuais dentro dele e quiser alterar as margens da página para um arquivo HTML específico, é possível adicionar o seguinte bloco de estilo ao arquivo HTML usando o editor de E-book do calibre:
<style>
@page {
margin-left: 10pt;
margin-right: 10pt;
margin-top: 10pt;
margin-bottom: 10pt;
}
</style>
Em seguida, na seção de saída em PDF da caixa de diálogo de conversão, ative a opção para: guilabel: Use as margens da página do documento que está sendo convertido. Agora todas as páginas geradas a partir deste arquivo HTML terão margens `` 10pt``.