 Змінити мову
Змінити мовуПеретворення даних електронних книг¶
Систему перетворення книг з одного формату на інший у calibre створено дуже простою у користуванні. Зазвичай, достатньо просто додати книгу до бібліотеки calibre, натиснути кнопку перетворення, і calibre зробить усе можливе, щоб книга у перетвореному форматі була якомога ближчою до тієї, яку ви передали для перетворення. Втім, calibre може працювати із дуже широким колом форматів вхідних даних, і не усі з цих форматів придатні для перетворення на електронні книги. Якщо ви маєте справу саме з таким незручним форматом або хочете отримати ширші можливості з керування процесом перетворення, у calibre передбачено багато параметрів, за допомогою яких ви зможете коригувати процес перетворення. Втім, слід зауважити, що система перетворення форматів книг у calibre не є повноцінною заміною справжнього редактора електронних книг. Для редагування книг ми рекомендуємо спочатку перетворити їх на книги у форматі EPUB або AZW3 за допомогою calibre, а вже потім скористатися вбудованим до програми редактором електронних книг, щоб надати їх довершеної форми. Після цього, ви зможете скористатися відредагованою книгою як вхідним форматом для перетворення даних у інші формати за допомогою calibre.
Цей документ, в основному, стосується параметрів перетворення, які можна знайти у діалоговому вікні перетворення, знімок якого наведено нижче. Доступ до усіх цих параметрів можна також отримати за допомогою інтерфейсу командного рядка для перетворення. Опис цього інтерфейсу можна знайти у розділі ebook-convert. У calibre ви можете отримати довідку щодо окремого параметра, навівши вказівник миші на відповідну частину інтерфейсу програми і трохи почекавши. Має з’явитися панель підказки із описом параметра.
Вступ¶
Перше, що слід зрозуміти про систему перетворення, — це те, що вона нагадує конвеєр. Схематично, вона виглядає так:
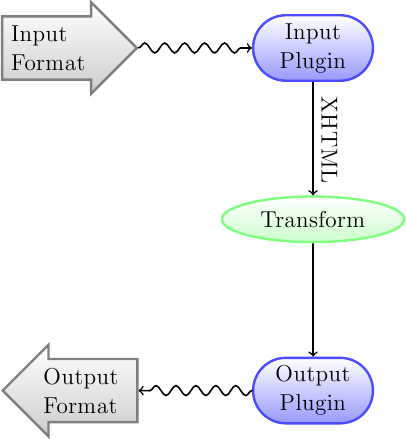
Вхідні дані спочатку перетворюються на XHTML за допомогою відповідного додатка вхідних даних. Отриманий код HTML далі перетворюється. На останньому кроці, оброблений код XHTML трансформується відповідно до правил вказаного формату виведення за допомогою відповідного додатка виведення. Якість результатів перетворення може бути зовсім різною — усе залежить від формату вхідних даних. Дані у деяких форматах перетворити набагато простіше ніж у інших. Список найкращих початкових форматів даних можна знайти тут.
Основна робота виконується під час перетворень виведених даних XHTML. Передбачено різноманітні перетворення, наприклад, для вставлення метаданих книги як сторінки на початку книги, для виявлення заголовків глав і автоматичного створення списку змісту, для пропорційного коригування розмірів шрифтів тощо. Важливо пам’ятати, що усі перетворення виконуються із даними XHTML, які є результатом роботи додатка вхідних даних, а не над вмістом початкового файла. Отже, наприклад, якщо ви накажете calibre перетворити файл RTF на EPUB, програма спочатку на внутрішньому рівні перетворить його на XHTML, виконає різноманітні перетворення коду XHTML, а потім вже додаток виведення створить файл EPUB, автоматично запише усі метадані, список змісту тощо.
Ви можете переглянути поступ обробки за допомогою параметра діагностики  . Достатньо просто вказати шлях до теки із діагностичними даними. Під час перетворення calibre зберігатиме XHTML, створені на різних етапах конвеєра перетворення, у різних підтеках. Цими чотирма підтеками є:
. Достатньо просто вказати шлях до теки із діагностичними даними. Під час перетворення calibre зберігатиме XHTML, створені на різних етапах конвеєра перетворення, у різних підтеках. Цими чотирма підтеками є:
Тека |
Опис |
|---|---|
input |
Цей каталог містить результати роботи додатка вхідних даних у форматі HTML. Використовується для діагностики додатка вхідних даних. |
parsed |
Результат попередньої обробки і перетворення на XHTML результатів роботи додатка вхідних даних. Використовується для діагностики роботи засобу визначення структури. |
structure |
Обробка після визначення структури, але перед спрощенням CSS та перетворенням розмірів шрифтів. Використовується для діагностики перетворення розмірів шрифтів та CSS. |
processed |
Дані перед передаванням електронної книги додатку виведення даних. Використовується для діагностики додатка виведення даних. |
Якщо ви хочете трохи змінити вхідний документ перед перетворенням даних за допомогою calibre, найкращим шляхом буде редагування файлів у підтеці input із наступним стисканням їх у форматі ZIP. Далі, файлом ZIP слід скористатися як вхідним форматом для наступного перетворення. Для цього скористайтеся діалоговим вікном Редагувати метаінформацію для додавання файла zip як формату книги, а потім у верхньому лівому куті діалогового вікна перетворення виберіть ZIP як формат вхідних даних.
У цьому документі, в основному, описано різноманітні перетворення, які виконуються над проміжним XHTML, і те, як керувати ними. Наприкінці наведено деякі підказки щодо кожного з форматів вхідних і вихідних даних.
Вигляд та поведінка¶
Ця група параметрів керує різноманітними аспектами вигляду перетвореної електронної книги.
Шрифти¶
Однією з найприємніших можливостей у читанні електронних книг є можливість простого коригування розмірів шрифтів для пристосування до індивідуальних потреб та умов освітлення. У calibre використано продумані алгоритми для забезпечення однорідності вигляду усіх книг, незалежно від того, які розміри шрифтів визначено у початковому документі.
Основним розміром шрифту документа є найуживаніший розмір шрифту, у цьому документі, тобто розмір шрифту в основному тексті документа. Коли ви вказуєте Основний розмір шрифту, calibre автоматично пропорційно змінює розмір усіх шрифтів у документі, отже цей найуживаніший розмір шрифту дорівнюватиме вказаному вами значенню, а інші розміри шрифтів буде скориговано відповідно до цього розміру. Вибравши більше значення основного розміру шрифту ви можете збільшити розміри усіх шрифтів у документі, і навпаки. Щоб отримати кращі результати, під час встановлення основного розміру шрифту вам слід також вказати ключ розмірів шрифту.
Зазвичай, автоматично вибирає розмір базового шрифту calibre відповідно до вибраного вами профілю виведення даних (див. Налаштування сторінки). Втім, ви можете перевизначити цей розмір тут, якщо типовий розмір вас не влаштовує.
За допомогою пункту Ключ розмірів шрифту ви можете керувати масштабуванням неосновних розмірів шрифту. Алгоритм масштабування шрифтів працює на основі ключа розмірів шрифту, який є простим списком розмірів, відокремлених комами. Ключ розмірів шрифту повідомляє calibre, на скільки «кроків» більшим або меншим має бути заданий розмір шрифту порівняно із основним розміром шрифту. Ідея полягає у тому, що у документі має бути обмежена кількість розмірів шрифту. Наприклад, один розмір для основного тексту, двійко розмірів для різних рівнів заголовків і двійко розмірів для верхніх і нижніх індексів, а також приміток. Ключ розміру шрифту надає calibre змогу поділити розміри шрифтів у вхідних документах на окремі «передачі», відповідно до різних логічних частин документа.
Проілюструємо викладене вище прикладом. Припустімо, що початковий документ, який ми перетворюємо, було створено кимось із ідеальним зором — у ньому вказано розмір шрифту у 8 пунктів. Це означає, що масив тексту у документі має розмір символів у 8 пунктів, а розмір символів у заголовка є дещо більшим (скажімо, 10 або 12 пунктів), а розмір підрядкових приміток є дещо меншим, скажімо, 6 пунктів. Тепер, якщо ми скористаємося такими параметрами:
Base font size : 12pt
Font size key : 7, 8, 10, 12, 14, 16, 18, 20
У виведеному документі основним шрифтом буде 12 пунктів, заголовки — 14 і 16 пунктів, а підрядкові примітки — 8 пунктів. Тепер припустімо, що нам потрібно зробити найбільші заголовки ще помітнішими і збільшити розмір шрифту підрядкових приміток. Щоб цього досягти, параметри шрифту слід змінити так:
New font size key : 7, 9, 12, 14, 18, 20, 22
Найбільші заголовки тепер буде показано шрифтом розміром у 18 пунктів, а підрядкові примітки — шрифтом розміром у 9 пунктів. Ви можете побавитися з цими параметрами, щоб визначити оптимальний для вас розмір, скориставшись майстром масштабування шрифтів, доступ до якого можна отримати за допомогою натискання маленької кнопки, розташованої поруч із пунктом Ключ розміру шрифту.
Тут також можна вимкнути будь-яку зміну розмірів шрифтів під час перетворення, якщо ви хочете зберегти розміри шрифтів початкового документа.
Пов’язаним параметром є Висота рядка. Параметр висоти рядка керує вертикальною висотою рядків. Типово, (значення висоти рядка 0) ніяких дій із висотою рядків не виконується. Якщо ви вкажете нетипове значення, висоту рядків буде змінено всюди, де її не вказано іншим чином. Втім, це доволі грубий інструмент, ним не слід зловживати. Якщо ви хочете змінити висоту рядків у якомусь розділі вхідних даних, краще скористатися інструментом Додаткові CSS.
За допомогою цього розділу ви можете також наказати calibre вбудувати усі використані шрифти до книги. Це надасть змогу користуватися шрифтами на пристроях для читання, на яких ці шрифти не встановлено.
Текст¶
Текст може бути вирівняним чи невирівняним. У вирівняному за шириною тексті будуть додаткові пробіли між словами для утворення рівномірного правого краю. Декому подобається вирівняний за шириною текст, декому — ні. Зазвичай, calibre зберігає вирівнювання початкового документа. Якщо ви хочете змінити параметри вирівнювання, скористайтеся пунктом Вирівнювання тексту у цьому розділі.
Ви також можете наказати calibre Обробити пунктуацію, тобто замінити звичайні лапки, дефіси та трикрапки на типографічно коректні варіанти. Зауважте, що алгоритм заміни не є ідеальним, отже, варто переглянути результати. Можна також скористатися і зворотною дією, Скасувати обробку пунктуації.
Нарешті, передбачено пункт Кодування вхідних даних. У застарілих форматах документів іноді не вказується кодування символів. Перетворення таких документів призводить до того, що кириличні символи та лапки перекодовуються із помилками. calibre намагається автоматично визначити кодування символів початкового документа, але робить це не завжди успішно. Типовим кодуванням документів, створених у Windows, є cp1251. Вам також слід ознайомитися із розділом Як перетворити файл, що містить нелатинські символи або теґи для позначення лапок?, щоб дізнатися більше про проблеми із кодуванням.
Форматування¶
Зазвичай, абзаци у XHTML позначаються порожнім рядком між ними без початкового відступу. У calibre передбачено декілька параметрів, які призначено для того, щоб змінити таку типову поведінку. Використання параметра Вилучати інтервали між абзацами призведе до примусового вилучення інтервалів між абзацами. Також буде встановлено відступ першого рядка тексту у 1.5em (можна змінити) для позначення абзаців. Параметр Додати порожній рядок між абзацами виконує прямо протилежну дію — забезпечує наявність точного одного порожнього рядка між усіма абзацами. Дія обох параметрів очевидна: вилучення інтервалу або його додавання до усіх абзаців (з технічної точки зору, до усіх теґів <p> і <div> у коді). Так зроблено для того, щоб ви могли просто позначити відповідний пункт і отримати потрібний результат, незалежно від того, наскільки поганим є коду у файлі вхідних даних. Єдиним виключенням є вхідні дані, у яких для реалізації інтервалів між абзацами використано жорсткі розриви рядків.
Якщо ви хочете вилучити інтервали між абзацами, окрім декількох вибраних, не використовуйте ці пункти. Замість цього, додайте такий код CSS до Додаткові CSS:
p, div { margin: 0pt; border: 0pt; text-indent: 1.5em }
.spacious { margin-bottom: 1em; text-indent: 0pt; }
Далі, у вашому початковому документі позначте абзаци, які слід відокремити інтервалами за допомогою class=»spacious». Якщо початковий документ не є документом HTML, скористайтеся параметром діагностики, описаним у «Вступі», щоб отримати HTML (скористайтеся підтекою input).
Ще одним корисним пунктом є пункт Лінеаризувати таблиці. У деяких документах із поганим компонуванням для керування показом тексту на сторінці використовують таблиці. Перетворення таких документів призводить до виходу тексту за межі сторінки та інших викривлень компонування. За допомогою цього параметра можна наказати програмі видобути вміст з таблиць і представити його у лінійному форматі. Зауважте, що використання цього пункту призведе до лінеаризації усіх таблиць. Тому ним слід користуватися, лише якщо ви впевнені, що у початковому документі таблиці не використовуються там, де це справді потрібно, наприклад для показу табличних даних.
Стиль¶
За допомогою пункту Додатковий CSS ви можете вказати довільну таблицю стилів CSS, яку буде застосовано до усіх файлів HTML у вхідних даних. Цю таблицю стилів CSS буде застосовано із дуже високим пріоритетом, вона має перевизначити усе, що визначено у більшості таблиць CSS вхідного документа. Цим пунктом ви можете скористатися, наприклад, для користування представлення або компонування документа. Наприклад, якщо ви хочете, щоб усіх абзаци класу endnote було вирівняно праворуч, просто додайте такий код:
.endnote { text-align: right }
або, якщо ви хочете змінити відступи у всіх абзацах:
p { text-indent: 5mm; }
Параметр Додаткове CSS є дуже потужним, але для того, щоб скористатися ним повністю, потрібне розуміння того, як працює CSS. Ви можете скористатися пунктом конвеєра діагностики, описаним вище, щоб переглянути CSS, які є у початковому документі.
Простішим варіантом є використання пункту Фільтрувати інформацію щодо стилів. За його допомогою ви можете вилучити усі властивості CSS вказаних типів з документа. Наприклад, ви можете вилучити усе розфарбовування шрифтів.
Перетворити стилі¶
Це найпотужніша можливість зі зміни стилів. Ви можете скористатися нею для визначення правил зміни стилів на основі різноманітних умов. Наприклад, ви можете скористатися нею, щоб змінити зелений колір на синій або вилучити усі позначення шрифту напівжирним, або розфарбувати усі заголовки у певний колір тощо.
Перетворення HTML¶
Подібне до перетворення стилів, але надає вам змогу вносити зміни до коду HTML книги. Ви можете замінити один теґ іншим, додати класи або інші атрибути до теґів на основі їхнього вмісту тощо.
Налаштування сторінки¶
Параметри налаштовування сторінки керують компонуванням сторінки, зокрема полями та розмірами екрана. Передбачено параметри визначення полів сторінки, які буде використано додатком виведення даних, якщо у вибраному форматі виведення передбачено підтримку полів сторінки. Крім того, вам слід вибрати формат вхідних і вихідних даних. Обидва набори профілів, в основному, визначають спосіб обробки вимірів у вхідних або вихідних документа, розміри екрана та типові параметри масштабування шрифтів.
Якщо ви впевнені, що файл, який ви перетворюєте, було призначено для читання лише на певному пристрої із використанням певного програмного забезпечення, виберіть відповідний профіль вхідних даних. Якщо ви хочете створити файли, які призначено для певного типу пристроїв, виберіть відповідний профіль виведення. В інших випадках виберіть один із загальних профілів виведення. Якщо ви перетворюєте дані до формату MOBI або AZW3, вам майже безумовно слід вибрати один із профілів виведення на пристрої Kindle. В інших випадках для сучасних пристроїв для читання електронних книг варто вибрати профіль виведення Типове ел. чорнило, дуже велика.
Профіль виведення також визначає розмір екрана. Тобто, наприклад, розміри усіх зображень буде автоматично змінено так, щоб вони вміщалися на екрані у певних форматах виведення даних. Отже, вам слід вибрати профіль пристрою, екран якого подібний до екрана вашого пристрою для читання електронних книг.
Евристична обробка¶
У засобі евристичної обробки передбачено широкий спектр функцій, якими можна скористатися для виявлення і виправлення типових проблем, пов’язаних із помилковим форматуванням вхідних документів. Скористайтеся цими функціями, якщо маєте проблеми із форматуванням у вхідному документі. Оскільки при роботі ці функції покладаються на типові взірці, не забувайте, що іноді певні параметри можуть призвести до погіршення результатів, отже, будьте обережні. Наприклад, використання деяких параметрів призводить до вилучення усіх замінників нерозривних пробілів або може призводити до спрацьовування функції, коли у цьому немає потреби.
- Увімкнути евристичну обробку
За допомогою цього пункту можна задіяти крок Евристична обробка у конвеєрі перетворення. Для застосування різноманітних підфункцій слід позначити цей пункт.
- З’єднати рядки
Позначення цього пункту призводить до того, що calibre намагається виявити і виправити жорсткі перенесення рядків у документі за допомогою аналізу пунктуації та довжини рядків. Спочатку calibre спробує виявити, чи існують жорсткі розриви рядків. Якщо ознак таких розривів виявлено не буде, calibre не намагатиметься з’єднати розірвані рядки. Коефіцієнт з’єднування рядків можна зменшити, якщо ви хочете «примусити» calibre з’єднувати рядки.
- Коефіцієнт розбирання рядків
Цей параметр призначено для керування алгоритмом, який calibre використовує для усування жорстких розривів рядків. Наприклад, якщо значенням параметра є 0.4, calibre з’єднуватиме рядки з кінця рядків, чия довжина є меншою за 40% довжини усіх рядків документа. Якщо у вашому документі виправлення потребують лише декілька рядків, слід зменшити значення цього параметра до числа від 0.1 до 0.2.
- Виявити і розмітити неформатовані заголовки глав та розділів
Якщо у документі немає заголовків глав і заголовки оформлено якось інакше від решти тексту, calibre може скористатися цим пунктом для того, щоб спробувати виявити заголовки і використати для них теґи заголовків. Для заголовків глав використовуються теґи <h2>; теґи <h3> використовуються для усіх інших виявлених заголовків.
Ця функція не створюватиме списку вмісту, але у багатьох випадках допоможе типовому засобу виявлення глав calibre правильно виявити глави і побудувати список змісту. Скоригуйте вираз XPath у розділі «Виявлення структури», якщо список змісту не буде створено автоматично. Якщо у документі не використано інших заголовків, встановлення значення «//h:h2» у полі виявлення структури є найпростішими способом створення списку вмісту для документа.
Вставлені заголовки не буде форматовано. Для застосування форматування скористайтеся пунктом Додаткове CSS у параметра перетворення «Зовнішній вигляд». Наприклад, щоб мітки заголовків розташовувалися у центрі, скористайтеся таким кодом:
h2, h3 { text-align: center }
- Змінювати нумерацію у послідовностях теґів <h1> і <h2>
Деякі видавці форматують заголовки глав за допомогою декількох послідовних теґів <h1> або <h2>. Використання типових параметрів перетворення calibre призведе до поділу таких заголовків на частини. За допомогою цього пункту можна перенумерувати теґи заголовків для запобігання поділу.
- Вилучити порожні рядки між абзацами
За допомогою цього пункту можна наказати calibre аналізувати порожні рядки, включені до документа. Якщо усі абзаци відокремлено один від одного порожніми рядками, calibre вилучить усі такі порожні абзаци. Послідовність з декількох порожніх рядків буде вважатися розривом сцени і зберігатиметься як окремий абзац. Цей пункт відрізняється від пункту Вилучати інтервали між абзацами на вкладці Зовнішній вигляд тим, що його використання насправді змінює вміст HTML, а не стилі документа. Цей пункт може також бути використано для вилучення абзаців, які вставлено за допомогою пункту Вставити порожній рядок.
- Забезпечити належне форматування розривів сцен
Якщо буде позначено цей пункт, calibre спробує виявити типові позначки поділу сцен і вирівняє їх за центром сторінки. До «м’яких» позначок поділу сцен, тобто поділу сцен додатковими пробілами, буде застосовано стиль для забезпечення того, щоб їх не було показано у поєднанні із розривами сторінок.
- Замінити м’які розриви сцен
Якщо буде позначено цей пункт, calibre замінюватиме знайдені програмою позначки розриву сцен на вказаний користувачем текст-замінник. Будь ласка, зауважте, що не усі символи-роздільники може бути правильного показано на усіх пристроях для читання книг.
Загалом, вам слід уникати використання теґів HTML. Calibre відкине усі теґи і використовуватиме попередньо визначену розмітку. Теґи <hr />, тобто горизонтальні лінії, та теґи <img> є виключеннями з цього правила. Горизонтальні лінії може бути додаткового вказано за допомогою стилів. Якщо ви додаватимете власний стиль, не забудьте включити параметр «width», інакше дані стилю буде відкинуто. Теґами зображень можна користуватися, але calibre не надає можливостей із додавання зображень під час перетворення. Зображення має бути додано після перетворення за допомогою інструмента «Редагувати книгу».
- Приклад теґу зображення (зображення розташовуються у теці «Images» у EPUB після перетворення):
<img style=»width:10%» src=»../Images/scenebreak.png» />
- Приклад горизонтальної лінії зі стилями:
<hr style=»width:20%;padding-top: 1px;border-top: 2px ridge black;border-bottom: 2px groove black;»/>
- Вилучати непотрібні дефіси
Якщо буде позначено цей пункт, calibre виконає аналіз усього тексту з переносами у документі. Для аналізу буде використано сам текст документу. Це надає змогу calibre акуратно вилучити переноси у будь-яких документах будь-якою мовою, навіть у складених словах та наукових термінах. Основним недоліком цієї методики є те, що переноси у словах, які трапляються у документі лише один раз, не вилучатимуться. Аналіз виконується у два проходи. Під час першого проходу програма аналізує кінці рядків. Рядки об’єднуватимуться, лише якщо у документі є таке саме слово без переносу або з дефісом. Під час другого проходу програма аналізує усі слова з дефісами у документі і вилучає дефіси, якщо у іншій частині документа є те саме слово без дефіса.
- IПозначати курсивом загальні слова та взірці
Якщо позначено, calibre шукатиме загальні слова і взірці, які позначають курсив і форматуватиме курсивом відповідні частини тексту. Прикладами є загальні правила позначення курсивного тексту, зокрема ~слово~ або фрази, які зазвичай друкують курсивом, наприклад латинські вставки «etc.» або «et cetera».
- Замінити відступи за допомогою об’єктів відступами CSS
У деяких документах використовуються певні правила щодо визначення відступів у тексті за допомогою об’єктів-замінників нерозривних пробілів. Якщо позначено цей пункт, calibre намагатиметься виявити такого роду форматування і перетворити його на відступи у 3% ширини тексту за допомогою CSS.
Пошук і заміна¶
Ці параметри корисні, в основному, для перетворення документів PDF або результатів оптичного розпізнавання тексту, хоча ними можна також скористатися і для виправлення документів із відповідними проблемами. Наприклад, під час певних перетворень у тексті можуть залишитися верхні і нижні колонтитули сторінок. Для перетворень використовуються формальні вирази для пошуку і виявлення верхніх і нижніх колонтитулів та інших довільних фрагментів тексту з наступним їх вилученням або заміною. Не забувайте, що обробці підлягатиме проміжний документ XHTML, створений конвеєром перетворення. Передбачено майстер, який допоможе вам створити формальний вираз для документа. Натисніть кнопку із чарівною паличкою, розташовану поруч із полем для введення формального виразу, і натисніть кнопку Тест після створення вашого формального виразу. Відповідники у тексті буде підсвічено жовтим кольором.
Пошук працює на основі формального виразу Python. Увесь знайдений текст буде просто вилучено з документа або замінено за допомогою взірця. Взірець для заміни є необов’язковим, якщо його не вказано, знайдений за взірцем текст буде вилучено з документа. Дізнатися більше про формальні вирази та їхній синтаксис можна з розділу Все про використання формальних виразів в calibre.
Виявлення структури¶
Використовуючи засоби виявлення структури, calibre намагається вичленити структурні елементи у вхідному документі, якщо ці елементи не було належним чином вказано. Прикладами таких структурних елементів є заголовки глав, розриви сторінок, верхні і нижні колонтитули. Як ви могли здогадатися, процедура виявлення залежить від початкового стану тексту. На щастя, у calibre передбачено дуже потужні можливості для керування нею. Ця потужність, звичайно, ускладнює налаштовування, але якщо ви присвятите трохи часу вивченню цих можливостей, ваші знання заощадять вам дуже багато часу.
Поділ на глави і сторінки¶
У calibre є два набори параметрів для виявлення глав і вставляння розривів сторінок. Це іноді може збити з пантелику, оскільки типово calibre вставлятиме розриви сторінок перед виявленими главами, а також у місцях, які відповідатимуть параметрам розриву сторінок. Причиною цього є те, що часто місця, куди слід вставити розрив сторінки, не перебувають на межі глав. Крім того, виявлені глави може бути вставлено до автоматично створеного списку змісту.
У calibre використовується XPath, потужна мова, яка надає змогу користувачеві вказувати місця меж глав та розривів сторінок. Можливо, спочатку XPath видасться вам трохи складною у користуванні. На щастя, у нас є підручник з XPath, який є частиною підручника для користувачів програми. Не забувайте, що засоби виявлення структури працюють із проміжним кодом XHTML, який створено під час обробки у конвеєрі перетворення. Скористайтеся параметром діагностики, описаним у розділі Вступ, щоб визначити відповідні параметри для вашої книги. Крім того, передбачено кнопку майстра створення виразів XPath, яка може допомогти вам зі створенням простих виразів XPath.
Типово, для виявлення глав у calibre використовується такий вираз:
//*[((name()='h1' or name()='h2') and re:test(., 'chapter|book|section|part\s+', 'i')) or @class = 'chapter']
Цей вираз є доволі складним, оскільки у ньому зроблено спробу одночасно обробити декілька типових випадків. Це означає, що calibre припускатиме, що глави починаються з теґів «<h1>» або «<h2>», які містять якесь із контрольних слів (chapter, book, section або part) або атрибут class=»chapter».
Пов’язаним пунктом налаштувань є пункт Позначка глави. За допомогою цього пункту ви можете визначити дію, яку має виконати calibre, коли виявить главу. Типово, програма вставляє розрив сторінки перед главою. Ви можете наказати програмі вставити горизонтальну лінію замість розриву або доповнити розрив горизонтальною лінією. Також можна наказати програмі не виконувати ніякого додаткового форматування тексту.
Типовими параметрами для виявлення розривів сторінок є:
//*[name()='h1' or name()='h2']
що означає, що calibre типово вставлятиме розриви сторінок перед кожним теґом <h1> і <h2>.
Примітка
Типові вирази можуть змінюватися, залежно від формату вхідних даних, які ви перетворюєте.
Різне¶
У цьому розділі є ще декілька пунктів.
- Вставити метадані як сторінку на початку книги
Однією із великих переваг calibre є те, що програма надає вам змогу зберігати повний спектр метаданих щодо усіх ваших книг. Зберігаються, наприклад, оцінка, мітки, коментарі тощо. За допомогою цього пункту можна створити окрему сторінку із усіма метаданими і вставити її до перетвореної електронної книги, типово, одразу після обкладинки. Можна вважати цю сторінку способом створення вашої нетипової суперобкладинки.
- Вилучити перше зображення
Іноді у початкових документах, які ви перетворюєте, обкладинку включать до самої книги, а не використовують окрему сторінку обкладинки. Якщо ви вкажете ще одну обкладинку у calibre, у перетвореній книзі буде дві обкладинки. За допомогою цього пункту можна вилучити перше зображення з початкового документа, таким чином забезпечивши існування у перетвореній книзі лише однієї обкладинки, тієї яку визначено у calibre.
Зміст¶
Якщо у вхідному документі список вмісту є частиною метаданих, calibre просто ним скористається. Втім, у багатьох старих форматах електронних книг або не передбачено підтримки списку змісту у метаданих, або у окремих документів немає такого списку змісту. У таки випадках пункти з цього розділу можуть допомогти вам в автоматичному створенні списку змісту у перетвореній електронній книзі на основі вмісту вхідного документа.
Примітка
Отримати ідеальний результат за допомогою цих пунктів іноді доволі непросто. Якщо ви надаєте перевагу створенню або редагуванню списку змісту вручну, виконайте перетворення даних у формат EPUB або AZW3 і позначте той пункт у нижній частині розділу «Зміст» діалогового вікна перетворення, який має мітку Після завершення перетворення виконати коригування змісту вручну. У результаті наприкінці процедури перетворення програма запустить інструмент редагування змісту. За його допомогою ви зможете створити записи у списку змісту простим клацанням у тому місці книги, куди має вказувати відповідний запис списку. Крім того, ви можете скористатися редактором змісту окремо, без виконання перетворення. Відкрийте сторінку Налаштування → Інтерфейс → Панелі інструментів і додайте кнопку редактора змісту на головну панель інструментів вікна програми. Далі, просто позначте пункт книги, яку хочете редагувати, і натисніть кнопку редактора змісту.
Першим пунктом є пункт Примусово використати автоматично створений зміст. Якщо ви позначите цей пункт, calibre перевизначить будь-який список змісту, який буде виявлено у метаданих вхідного документа, на автоматично створений програмою список змісту.
Типовим способом роботи засобу автоматичного створення списку змісту є такий спосіб: calibre спочатку намагається додати будь-які виявлені глави до створеного списку змісту. Дізнатися про те, як налаштувати виявлення глав, можна з розділу Виявлення структури наведеного вище. Якщо ви не хочете включати виявлені глави до створеного списку змісту, позначте пункт Не додавати виявлені глави.
Якщо буде виявлено меншу за вказану у пункті Поріг глав кількість глав, calibre додасть до списку змісту усі знайдені у документі гіперпосилання. Часто це дає добрий результат, оскільки багато початкових документів включають список змісту із гіперпосиланнями на початку. Керувати кількістю посилань можна за допомогою пункту Кількість посилань. Якщо встановити нульову кількість, посилання не додаватимуться. Якщо встановити додатну кількість посилань, до змісту буде додано не більше за вказану кількість посилань.
calibre автоматично усуває дублікати зі створеного списку змісту. Втім, якщо у списку все ж є додаткові небажані записи, ви можете усунути їх за допомогою пункту Фільтр змісту. Тут слід вказати формальний вираз, який відповідає заголовкам записів у створеному списку змісту. Якщо буде знайдено відповідники цього формального виразу, програма їх усуне. Наприклад, щоб усунути усі записи із заголовками «Next» або «Previous», скористайтеся таким формальним виразом:
Next|Previous
За допомогою пунктів Рівень 1,2,3 змісту ви можете створити багаторівневий список змісту. Значеннями у пунктах є вирази XPath, які відповідають теґами у проміжному документі XHTML, створеному конвеєром перетворення. Щоб дізнатися про те, як отримати доступ до цього документа XHTML, ознайомтеся із розділом Вступ. Також ознайомтеся із розділом Підручник з XPath, щоб дізнатися про те, як конструювати вирази XPath. Поряд із кожним пунктом є кнопка, натискання якої запускає майстер створення базових виразів XPath. Наведений нижче простий приклад ілюструє використання цих пунктів.
Припустімо, що ви маєте вхідний документ, який дає код XHTML, що виглядає так:
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<title>Sample document</title>
</head>
<body>
<h1>Chapter 1</h1>
...
<h2>Section 1.1</h2>
...
<h2>Section 1.2</h2>
...
<h1>Chapter 2</h1>
...
<h2>Section 2.1</h2>
...
</body>
</html>
Отже, ми встановимо такі значення параметрів:
Level 1 TOC : //h:h1
Level 2 TOC : //h:h2
Це призведе до автоматичного створення такої дворівневої таблиці змісту:
Chapter 1
Section 1.1
Section 1.2
Chapter 2
Section 2.1
Попередження
Підтримку багаторівневих таблиць змісту передбачено не в усіх форматах виведення даних. Спочатку варто спробувати виведення до EPUB. Якщо дані буде виведено вдало, спробуйте вибрати інший бажаний для вас формат.
Використання зображень як заголовків глав під час перетворення вхідних документів HTML¶
Припустімо, ви хочете скористатися зображенням як заголовком глави, але хочете, щоб програма calibre змогла автоматично створити список змісту на основі заголовків глав. Скористайтеся таким кодом HTML, щоб досягти цього:
<html>
<body>
<h2>Chapter 1</h2>
<p>chapter 1 text...</p>
<h2 title="Chapter 2"><img src="chapter2.jpg" /></h2>
<p>chapter 2 text...</p>
</body>
</html>
Вкажіть у полі Рівень 1 змісту значення //h:h2. Тоді, для другого розділу calibre візьме заголовок зі значення атрибута title теґу <h2>, оскільки у тезі немає тексту.
Використання атрибутів теґів для текстових записів у таблиці змісту¶
Якщо маєте доволі довгі заголовки глав і хочете скоротити їх для списку змісту, можете скористатися для цього атрибутом заголовка, ось так:
<html>
<body>
<h2 title="Chapter 1">Chapter 1: Some very long title</h2>
<p>chapter 1 text...</p>
<h2 title="Chapter 2">Chapter 2: Some other very long title</h2>
<p>chapter 2 text...</p>
</body>
</html>
Вкажіть у полі Рівень 1 змісту значення //h:h2/@title. Тоді calibre візьме назву зі значення атрибута title у теґах <h2>, замість використання тексту у тезі. Зверніть увагу на кінцеве /@title у виразі XPath. Ви можете скористатися подібною формою запису для того, щоб повідомити calibre, що текст слід брати із будь-якого визначеного вами атрибута.
Як встановлюються та зберігаються параметри для перетворення¶
Передбачено два місця, у яких можна встановити параметри перетворення у calibre. Першим є сторінка Налаштування → Перетворення. Ці параметри є типовими для перетворення. Якщо ви спробуєте перетворити якусь нову книгу, встановлені за допомогою цієї сторінки параметри буде використано як типові.
Ви також можете змінити параметри перетворення у діалоговому вікні перетворення окремої книги. Під час перетворення книги calibre запам’ятовує використані для цієї книги значення параметрів, отже, якщо ви захочете перетворити книгу знову, збережені параметри матимуть пріоритет перед типовим набором параметрів, які визначено у вікні налаштувань програми. Ви можете відновити типові значення параметрів перетворення окремої книги за допомогою натискання кнопки Відновити типові у діалоговому вікні перетворення окремої книги. Ви можете вилучити збережені значення параметрів для групи книг: позначте усі книги групи, а потім натисніть кнопку редагування метаданих, щоб відкрити вікно пакетного редагування метаданих. У нижній частині цього вікна є пункт для вилучення збережених значень параметрів перетворення.
Якщо ви пакетно перетворюєте набір книг, параметри буде використано у такому порядку (останній має пріоритет):
З типового набору Налаштування -> Перетворення
Зі збережених параметрів перетворення для кожної з книг (якщо такі визначено). Використання цих параметрів може бути вимкнено за допомогою пункту у верхньому лівому куті діалогового вікна пакетного перетворення.
З набору параметрів у діалоговому вікні пакетного перетворення
Зауважте, що остаточні параметри для кожної книги під час пакетного перетворення буде збережено і повторно використано для наступних перетворень книги. Оскільки найвищий пріоритет при пакетному перетворенні мають значення параметрів, які визначено у діалоговому вікні пакетного перетворення, ці значення параметрів перевизначать будь-які специфічні для книги значення параметрів. Отже, засіб пакетного перетворення слід використовувати лише для перетворення книг, які потребують подібних значень параметрів. Виключеннями є метадані і специфічні для вхідних форматів параметри. Оскільки у діалоговому вікні пакетного перетворення немає пунктів, які пов’язано із цими двома категоріями параметрів, значення цих параметрів буде запозичено зі списку специфічних для книги значень параметрів (якщо такі визначено) або типових значень параметрів.
Примітка
Переглянути параметри перетворення, які використовуватимуться для будь-якого перетворення, можна натисканням піктограми обертання у нижньому правому куті вікна з наступним подвійним клацанням на пункті окремого завдання з перетворення. У відповідь на ці дії програма відкриє журнал перетворення, де у верхній частині міститимуться дані щодо використаних параметрів.
Підказки для окремих форматів¶
У цьому розділі наведено підказки щодо специфіки перетворення певних форматів даних. Параметри, які є специфічними для певного формату, як вхідних, так і вихідних даних, доступні у діалоговому вікні перетворення у власних розділах. Наприклад, Вхідні дані TXT або Вивід в EPUB.
Перетворення документів Microsoft Word¶
calibre може автоматично перетворювати файли .docx, які створено у Microsoft Word 2007 та новіших версіях. Просто додайте файл у calibre і натисніть кнопку перетворення.
Примітка
Існує демонстраційний файл .docx, за допомогою якого можна ознайомитися із можливостями рушія перетворення calibre. Достатньо зберегти цей файл на вашому комп’ютері і перетворити його на EPUB або AZW3, щоб побачити, на що здатна програма.
calibre автоматично створить таблицю змісту на основі заголовків, якщо ви позначити заголовки стилями Заголовок 1, Заголовок 2 тощо у Microsoft Word. Для перегляду створеної таблиці змісту відкрийте отриману у результаті перетворення електронну книгу у засобі перегляду книг calibre і натисніть кнопку Зміст.
Застарілі файли .doc¶
Файли у старому форматі .doc можна зберегти як HTML за допомогою Microsoft Word, а потім перетворити отриманий файл HTML за допомогою calibre. Під час збереження даних у форматі HTML вам слід вибрати варіант «Зберегти як вебсторінку, з фільтруванням» («Save as Web Page, Filtered»), оскільки так можна отримати простий код HTML, який буде просто перетворити. Зауважте, що Word створює доволі невдалий код HTML, перетворення якого може бути доволі довгим. Тому вам доведеться потерпіти. Якщо ж у вашій системі встановлено новішу версію Word, ви можете зберегти дані і у форматі docx.
Іншим варіантом дій є використання вільного LibreOffice. Відкрийте ваш файл .doc у LibreOffice і збережіть його у форматі .docx, який можна безпосередньо перетворювати у calibre.
Перетворення документів TXT¶
У документах TXT немає стандартного способу для позначення форматування тексту, зокрема напівжирного написання, курсиву тощо, або структури документа, зокрема абзаців, заголовків та розділів, але поширеними є деякі правила щодо цих питань. Типово, calibre намагається виконати автоматичне виявлення належного форматування та розмітки на основі цих загальновживаних правил.
Для вхідних даних у форматі TXT передбачено підтримку декількох варіантів обробки, які відрізняються способом виявлення розбиття тексту на абзаци.
- Стиль абзацу: Авто
Аналізує текстовий файл і намагається автоматично виявити спосіб задання абзаців. Зазвичай, цей варіант працює добре. Якщо ви отримуєте незадовільні результати, спробуйте один із варіантів із визначенням вручну.
- Стиль абзацу: Блок
Припускати, що один або декілька порожніх рядків є межами абзацу:
This is the first. This is the second paragraph.- Стиль абзацу: Одинарний
Припускати, що кожен окремий рядок є абзацом:
This is the first. This is the second. This is the third.- Стиль абзацу: Друк
Припускає, що усі абзаци починаються з відступів (одної табуляції або 2 пробілів). Абзаци закінчуються там, де наступний рядок починається із відступу:
This is the first. This is the second. This is the third.- Стиль абзацу: Неформатований
Припускає, що у документі немає форматування, але використано жорстке розбиття на рядки. Для відтворення абзаців буде використано пунктуацію і середню довжину рядків.
- Стиль форматування: Авто
Спробувати визначити тип форматування автоматично. Якщо у даних немає розмітки, буде застосовано евристичне форматування.
- Стиль форматування: Евристичний
Шукає у документі типові заголовки глав, розбиття на сцени та слова, які виокремлено курсивом, і застосовує відповідну розмітку HTML під час перетворення.
- Стиль форматування: Розмітка
Крім того, у calibre передбачено підтримку використання для вхідних даних у форматі TXT засобу попередньої обробки відомого як Markdown. Markdown забезпечує додавання базового форматування до документів TXT, зокрема позначення жирним і курсивом тексту, заголовки розділів, таблиці, списки, зміст тощо. Позначення заголовків глав за допомогою початкового # і встановлення виразу XPath для виявлення глав «//h:h1» є найпростішим способом створення належного змісту на основі початкових даних документа TXT. Більше про синтаксис markdown можна дізнатися з сайта daringfireball.
- Стиль форматування: Немає
Не застосовує спеціального форматування до тексту. Документ буде перетворено на HTML без будь-яких інших змін.
Перетворення документів PDF¶
Документи PDF є одним з найгірших початкових форматів для перетворення. У таких документах передбачено фіксований розмір сторінки та фіксоване розташування тексту. Це означає, що програмі дуже важко встановити місце, де завершується один абзац і починається інший. Calibre намагатиметься з’єднати розірвані рядки у абзацах за допомогою змінюваного параметра Коефіцієнт збирання рядків. Це параметр масштабування, який визначає довжину частин рядка, які слід з’єднувати з попередніми. Коректними значеннями цього параметра є десяткові дроби між 0 і 1. Типовим є значення 0.45, трохи менше за половину довжини рядка. Зменште це значення, щоб розширити сферу дії інструмента з’єднування рядків. Збільште значення, щоб звузити сферу його використання. Ви можете скоригувати це значення у вікні параметрів перетворення, вкладка Вхідні дані PDF.
Крім того, у документах PDF часто є верхні і нижні колонтитули, які є частиною документа, яку програма може автоматично включити до тексту документа. Скористайтеся панеллю Пошук з заміною, щоб вилучити такі верхні і нижні колонтитули і усунути пов’язані із ними проблеми. Якщо не усунути верхні і нижні колонтитули, вони можуть завадити нормальній роботі засобу з’єднування рядків абзаців. Щоб дізнатися про те, як скористатися інструментами вилучення верхніх і нижніх колонтитулів, прочитайте розділ Все про використання формальних виразів в calibre.
Деякі обмеження щодо вхідних даних PDF:
Не передбачено підтримки складних документів, документів із декількома стовпцями тексту та документів, що складаються із зображень.
Також не передбачено підтримки видобування векторних зображень і таблиць з документа.
У деяких PDF використовуються спеціальні гліфи для відтворення комбінацій літер ll, ff, fi тощо. Такі комбінації символів не завжди вдається перетворити, — усе залежить від внутрішнього представлення цих символів у PDF.
Не передбачено підтримки посилань та таблиці змісту.
Якщо у PDF використано вбудовані шрифти без Unicode для представлення символів поза латиницею, відповідні символи буде показано неправильно
Деякі файли PDF складаються з фотографій сторінок із оптично розпізнаним текстовим шаром під фотографіями. calibre використає лише текстовий шар, який може значно відрізнятися від того, що ви бачите під час перегляду файла PDF.
Файли PDF, які використовуються для показу складного тексту, зокрема мов із записом справа ліворуч і математичними формулами, не буде перетворено належним чином.
Ще раз: PDF — дуже, дуже невдалий формат для вхідних даних. Якщо немає альтернативи використанню PDF, варто приготуватися до того, що отримані у результаті перетворення дані матимуть якість від пристойної до непридатної до використання, залежно від початкового PDF.
Збірки коміксів¶
Збірки коміксів записуються у форматі файла .cbc. Файл .cbc є файлом ZIP, який містить інші файли CBZ/CBR. Крім того, у файлі .cbc має міститися простий текстовий файл і назвою comics.txt і кодуванням вмісту UTF-8. Файл comics.txt має містити список файлів коміксів у файлі .cbc у форматі назва_файла:назва_коміксу, як це показано нижче:
one.cbz:Chapter One
two.cbz:Chapter Two
three.cbz:Chapter Three
Файл .cbc міститиме:
comics.txt
one.cbz
two.cbz
three.cbz
calibre автоматично перетворить цей файл .cbc на електронну книгу з таблицею змісту, що вказуватиму не усі записи у comics.txt.
Демонстрація розширеного форматування EPUB¶
Різноманітні додаткові засоби форматування у файлах EPUB продемонстровано у цьому файлі. Файл було створено на основі коду HTML, який було написано вручну, за допомогою calibre і призначено для використання як шаблона для ваших власних спроб створити EPUB.
Початковий код HTML, з якого його було створено, можна знайти у demo.zip. Параметри, використані для створення EPUB з ZIP є такими:
ebook-convert demo.zip .epub -vv --authors "Kovid Goyal" --language en --level1-toc '//*[@class="title"]' --disable-font-rescaling --page-breaks-before / --no-default-epub-cover
Зауважте, що оскільки цей файл використовує увесь потенціал EPUB, більшість додаткового форматування не працюватиме у програмах для читання електронних книг, які є менш досконалими за вбудовану до calibre програму для перегляду EPUB.
Перетворення документів ODT¶
calibre може безпосередньо перетворювати файли ODT (текстові документи OpenDocument). Вам слід використовувати стилі для форматування вашого документа і мінімізувати використання безпосереднього форматування. Вставляючи зображення до вашого документа, ви маєте прив’язувати їх до абзаців. Зображення, які буде прив’язано до сторінок, опиняться на перших сторінках книги під час перетворення.
Щоб уможливити автоматичне визначення глав книги, вам слід позначати їх вбудованими стилями, які мають назви Заголовок 1, Заголовок 2, …, Заголовок 6 (Заголовок 1 відповідає теґу HTML <h1>, Заголовок 2 — теґу <h2> тощо). Під час перетворення у calibre ви можете вказати, який саме стиль ви використали для заголовків за допомогою поля Виявляти глави за. Приклад:
Якщо ви позначите глави стилем Заголовок 2, вам слід вказати у полі «Виявляти глави за» рядок
//h:h2Для багаторівневого змісту із розділами, які позначено стилем Заголовок 2, і главами, які позначено стилем Заголовок 3, вам слід вказати
//h:h2|//h:h3. На сторінці перетворення змісту вкажіть у полі Рівень 1 змісту//h:h2, а у полі Рівень 2 змісту —//h:h3.
Відомі властивості документа (Заголовок, ключові слова, опис, автор) буде розпізнано. Крім того, calibre використає перше зображення з книги (те, яке не є маленьким і має належне співвідношення розмірів) як зображення обкладинки.
Також передбачено режим розширеного перетворення властивостей, який можна задіяти за допомогою встановлення нетипової властивості opf.metadata (типу «Так чи ні») у значення «Так» у вашому документі ODT (Файл → Властивості → Нетипові властивості). Якщо calibre буде виявлено цю властивість, програма розпізнаватиме такі нетипові властивості (opf.authors перевизначає властивість автора документа):
opf.titlesort
opf.authors
opf.authorsort
opf.publisher
opf.pubdate
opf.isbn
opf.language
opf.series
opf.seriesindex
Окрім цього, ви можете вказати зображення, яке слід використати для обкладинки, назвавши його opf.cover (клацання правою кнопкою на зображенні, :Зображення → Параметри → Назва) у ODT. Якщо зображення з такою назвою не буде знайдено, буде використано «кмітливий» метод визначення зображення. Оскільки виявлення зображення обкладинки для деяких форматів виведення даних може призвести до подвійних обкладинок, процедурою обробки буде вилучено абзац (лише якщо єдиним його вмістом є зображення) з документа. Але усе це працює лише із іменованим зображенням!
Щоб вимкнути виявлення зображень обкладинки, встановіть для нетипової властивості opf.nocover (типу «Так чи ні») значення «Так» у розширеному режимі.
Перетворення на PDF¶
Першим, і найважливішим, параметром, який слід визначити при перетворенні даних у формат PDF, є розмір сторінки. Типово, calibre використовує розмір сторінки «U.S. Letter». Ви можете змінити його на інший стандартний розмір або вказати нетиповий розмір у розділі Вивід у PDF діалогового вікна перетворення. Якщо ви створюєте PDF для використання на певному пристрої, ви можете позначити пункт використання розмір у сторінки у профілі виведення. Отже, якщо встановлено профіль виведення на Kindle, calibre створюватиме PDF із розміром сторінки, який є зручним для перегляду на малому екрані Kindle.
Придатний до друку список змісту¶
Ви також можете додати придатний до друку список змісту наприкінці файла PDF, де буде наведено дані щодо номера сторінки для кожного з розділів. Це буде доволі корисно, якщо ви захочете надрукувати PDF на папері. Якщо ви маєте намір читати PDF на електронному пристрої, зміст типово буде створено автоматично, потреби у додаткових сторінках немає.
Ви можете скоригувати вигляд створеного списку змісту за допомогою параметра перетворення «Додаткове CSS» у розділі «Вигляд та поведінка» діалогового вікна перетворення. Типову використану CSS наведено нижче, просто скопіюйте її і внесіть потрібні вам зміни.
.calibre-pdf-toc table { width: 100%% }
.calibre-pdf-toc table tr td:last-of-type { text-align: right }
.calibre-pdf-toc .level-0 {
font-size: larger;
}
.calibre-pdf-toc .level-1 td:first-of-type { padding-left: 1.4em }
.calibre-pdf-toc .level-2 td:first-of-type { padding-left: 2.8em }
Нетипові поля сторінок для окремих файлів HTML¶
Якщо ви виконуєте перетворення до формату EPUB або AZW3 із декількома окремими файлами HTML всередині і хочете змінити поля сторінок для окремого файла HTML, ви можете додати такий стильовий блок до файла HTML за допомогою редактора книг calibre:
<style>
@page {
margin-left: 10pt;
margin-right: 10pt;
margin-top: 10pt;
margin-bottom: 10pt;
}
</style>
Далі, у розділі виведення до PDF діалогового вікна перетворення позначте пункт Використовувати поля сторінок з перетворюваного документа. Тепер усі сторінки, які буде створено з цього файла HTML, матимуть поля у 10pt (10 пунктів).