 Изменить язык
Изменить языкКонвертирование книг¶
Calibre имеет очень простую в использовании систему конвертации. Обычно вы просто добавляете книгу в Calibre, нажимаете «конвертировать», и Calibre изо всех сил старается генерировать выходные данные, максимально приближенные к входным. Тем не менее, Calibre принимает очень большое количество входящих форматов, не все из которых подходят для конвертации в электронные книги. В случае таких входящих форматов или если вы просто хотите лучше контролировать систему конвертации, у Calibre есть много опций для точной настройки процесса конвертации. Однако обратите внимание, что система конвертации Calibre не заменяет полноценного редактора электронных книг. Чтобы редактировать электронные книги, я рекомендую сначала преобразовать их в EPUB или AZW3 с использованием Calibre, а затем с помощью функции Edit book, привести их в идеальную форму. Затем вы можете использовать отредактированную электронную книгу в качестве входящих данных для конвертации в другие форматы в Calibre.
Этот документ, в основном, будет ссылаться на настройки, находящиеся в диалоге конвертации, изображённом ниже. Все эти настройки также доступны через интерфейс командной строки для конвертации, задокументированный в ebook-convert. В calibre можно получить справку по любому отдельному параметру, удерживая над ним курсор мыши до появления подсказки с описанием.
Предисловие¶
Первое, что нужно понять о системе конвертации, это то, что она спроектирована как конвейер. Схематически это выглядит так:
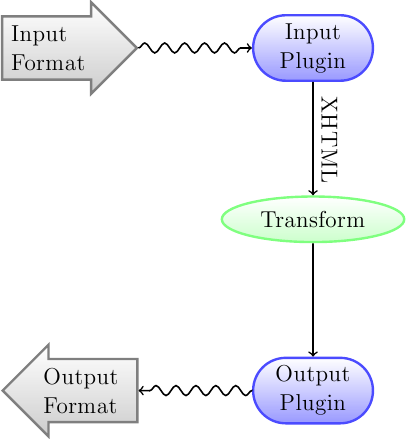
Формат ввода сначала конвертируется в XHTML с помощью соответствующего плагина ввода. Этот HTML затем трансформируется. На последнем шаге обработанный XHTML преобразуется в указанный формат вывода соответствующим плагином вывода. Результаты преобразования могут сильно различаться в зависимости от формата ввода. Список лучших исходных форматов для конвертации доступен: ref:here<best-source-formats>.
Конвертации, которые действуют на вывод XHTML, - это место, где происходит вся работа. Существуют различные конвертации: вставка метаданных книги в виде страницы в начало книги, обнаружение заголовков глав и автосоздание оглавления, пропорциональная настройка размеров шрифта и т. д. Все конвертации действуют на вывод XHTML с помощью плагина ввода, а не на сам входной файл. При конвертации calibre-ом RTF-файла в EPUB, сначала он конвертируется во внутренний XHTML, к XHTML применяются различные конвертации, а затем плагин Вывод создаёт файл EPUB, автоматически генерируя для файла все метаданные, оглавление и т. д.
Вы можете увидеть этот процесс в действии, используя параметр отладки  . Укажите путь к папке для вывода отладки. Во время конвертации calibre помещает XHTML, сгенерированный на различных этапах конвейера конвертации, в разные подпапки. Четыре подпапки:
. Укажите путь к папке для вывода отладки. Во время конвертации calibre помещает XHTML, сгенерированный на различных этапах конвейера конвертации, в разные подпапки. Четыре подпапки:
Папка |
Описание |
|---|---|
ввод |
Содержит HTML-вывод плагина ввода. Для отладки плагинов ввода. |
разобранный |
Результат предварительной обработки и конвертации в XHTML вывода из плагина ввода. Для отладки детектирования структуры. |
структура |
После обнаружения структуры, но перед сведением CSS и преобразованием размеров шрифта. Для отладки конвертации размера шрифта и преобразований CSS. |
обработано |
Перед тем как книга передается в плагин вывода. Для отладки плагинов вывода. |
Если вы хотите немного отредактировать входной документ до того, как calibre преобразовал его, лучше всего отредактировать файлы в подпапке input, затем заархивировать его и использовать ZIP-файл в качестве входного формата для последующих преобразований. Для этого используйте диалоговое окно Редактировать метаданные, чтобы добавить ZIP-файл в качестве формата для книги, а затем в верхнем левом углу диалогового окна конвертации выберите ZIP в качестве входного формата.
Этот документ будет посвящен главным образом различным преобразованиям, которые работают с промежуточным XHTML, и тому, как их контролировать. В конце приведены некоторые советы, специфичные для каждого формата ввода/вывода.
Оформление¶
Эта группа параметров контролирует различные аспекты внешнего вида конвертированной электронной книги.
Шрифты¶
Одной из самых приятных особенностей электронного чтения является возможность легко регулировать размеры шрифта под свои потребности и условия освещения. У calibre - сложные алгоритмы вывода, для гарантии одинаковых размеров шрифта книг, независимо от того, какие размеры шрифта указаны во входном документе.
Базовый размер шрифта документа - это наиболее распространенный размер шрифта в документе, т. е. размер основной части текста в этом документе. При указании: guilabel: Базовый размер шрифта, calibre пропорционально автоизменяет размеры всех шрифтов в документе, наиболее распространенный размер шрифта становится указанным базовым размером, а размеры других шрифтов отсчитываются от базового. Больший базовый размер шрифта - увеличение всех шрифтов в документе и наоборот. При установке базового размера шрифта также нужно установить ключ размера шрифта.
Обычно calibre автоматически выбирает основной размер шрифта, соответствующий выбранному вами выходному профилю (см .:ref:page-setup). Значение по умолчанию можно переопределить здесь.
Опция Font size key позволяет контролировать масштабирование размеров неосновных шрифтов. Алгоритм масштабирования шрифта работает с использованием ключа размера шрифта (просто список разделенных запятыми размеров шрифтов). Ключ размера шрифта сообщает calibre, на сколько «шагов» больше или меньше данного размера шрифта следует сравнивать с базовым размером шрифта. В документе должно быть ограниченное количество размеров шрифта. Один размер для основного текста, несколько размеров для разных уровней заголовков и несколько размеров для индексов super/sub и сносок. Ключ размера шрифта позволяет calibre разделить размеры шрифта во входных документах на отдельные «ячейки», соответствующие различным логическим размерам шрифта.
Давайте проиллюстрируем на примере. Предположим, исходный документ, который мы конвертируем, был создан кем-то с отличным зрением и имеет базовый размер шрифта 8pt. Это означает, что основная часть текста в документе имеет размер 8 пт, а заголовки несколько больше (скажем, 10 и 12 пт), а сноски несколько меньше - 6 пт. Теперь, если мы используем следующие настройки:
Base font size : 12pt
Font size key : 7, 8, 10, 12, 14, 16, 18, 20
Выходной документ будет иметь основной размер шрифта 12pt, заголовки 14 и 16pt и сноски 8pt. Теперь предположим, что мы хотим выделить самый большой размер заголовка и сделать сноски немного больше. Для этого ключ шрифта должен быть изменен на:
New font size key : 7, 9, 12, 14, 18, 20, 22
Самые большие заголовки теперь станут 18pt, а сноски - 9pt. Вы можете поиграть с этими настройками, чтобы попытаться выяснить, что будет оптимальным для вас, используя мастер изменения размера шрифта, к которому можно перейти, нажав маленькую кнопку рядом с настройкой guilabel:Font size key.
Здесь также можно отключить изменение размера шрифта при преобразовании, если вы хотите сохранить размеры шрифта во входном документе.
Связанная настройка Высота строки. Высота строки управляет вертикальной высотой строк. По умолчанию (высота строки 0) никакие манипуляции с высотой строки не выполняются. Если вы укажете значение, отличное от значения по умолчанию, высота строк будет установлена во всех местоположениях, которые не указывают свои собственные высоты строк. Тем не менее, это что-то вроде тупого оружия и должно использоваться с осторожностью. Если вы хотите настроить высоту строки для какого-то раздела ввода, лучше использовать Extra CSS.
В этом разделе вы также можете указать calibre встраивание любых ссылочных шрифтов в книгу. Это позволит работать со шрифтами на читалках, даже если их нет на устройстве.
Текст¶
Текст может быть выровненным или нет. Выровненный текст содерит избыточные пробелы между словами, чтобы получить ровный правый край. Некоторые люди предпочитают выровненный текст, другие нет. Обычно calibre сохраняет выравнивание в оригинальном документе. Если вы хотите переопределить его, вы можете использовать опцию Выравнивание текста в этом разделе.
Вы также можете сказать calibre :guilabel: Smarten пунктуация, который заменит простые кавычки, тире и многоточия их типографически правильными альтернативами. Обратите внимание, что этот алгоритм не идеален, поэтому стоит проверить результаты. Также доступно обратное, а именно: guilabel:Unsmarted пунктуация.
Наконец, есть Кодировка входящих символов. В старых документах иногда не указывается кодировка символов. При конвертировании это может привести к повреждению неанглийских символов или специальных символов, таких как смарт-кавычки. Calibre пытается автоматически определить кодировку символов исходного документа, но это не всегда удается. Вы можете заставить его принять определенную кодировку символов с помощью этого параметра. cp1252 - это обычная кодировка документов, созданных с использованием программного обеспечения Windows. Вы также должны прочитать Как конвертировать мой файл, если он включает не английские символы или «умные» кавычки?, чтобы узнать больше о проблемах кодирования.
Макет¶
Обычно абзацы в XHTML рендерятся с пустой строкой между ними без начального отступа текста. Calibre может конролировать это несколькими вариантами. Убрать интервалы между абзацами принудительно убедиться, что у всех абзацев нет интервала между абзацами. Также устанавливается отступ текста на 1,5em (можно изменить), чтобы отметить начало каждого абзаца. :guilabel: Вставить пустую строку делает противоположное, гарантируя, что между каждой парой абзацев ровно одна пустая строка. Обе эти опции всеобъемлющие, убирают пробел или вставляют его для всех абзацев (технически <p> и <div> тегов). Это делается для того, чтобы вы могли просто установить параметр и быть уверенным, что он работает так, как объявлено, независимо от того, насколько грязен входной файл. Единственное исключение - когда входной файл использует жесткие разрывы строк для реализации межпараграфного интервала.
Если вы хотите удалить интервал между всеми абзацами, кроме нескольких избранных, не используйте эти параметры. Вместо этого добавьте следующий код CSS в Extra CSS:
p, div { margin: 0pt; border: 0pt; text-indent: 1.5em }
.spacious { margin-bottom: 1em; text-indent: 0pt; }
Затем в исходном документе отметьте абзацы, требующие интервала, с помощью class=»spacious». Если ваш входной документ не в формате HTML, используйте опцию Debug, описанную во введении, чтобы получить HTML (используйте подпапку input).
Ещё одна полезная опция Линеаризовать таблицы. Некоторые плохо оформленные документы используют таблицы для управления макетом текста на странице. При преобразовании в этих документах часто появляется текст, который выходит за пределы страницы и другие артефакты. Эта опция будет извлекать содержимое из таблиц и представлять его в линеаризованной форме. Обратите внимание, что этот параметр линеаризует все таблицы, поэтому используйте его, только если вы уверены, что входной документ не использует таблицы для законных целей, таких как представление табличной информации.
Стилизация¶
Опция Extra CSS позволяет вам указать произвольный CSS, который будет применяться ко всем HTML-файлам во входных данных. Этот CSS-код применяется с очень высоким приоритетом и поэтому должен перекрывать большую часть CSS-кода, присутствующего во входном документе. Вы можете использовать этот параметр для точной настройки презентации/макета вашего документа. Например, если вы хотите, чтобы все абзацы класса endnote были выровнены по правому краю, просто добавьте
.endnote { text-align: right }
или если вы хотите изменить отступ всех абзацев:
p { text-indent: 5mm; }
Extra CSS - очень мощный вариант, но вам нужно понять, как работает CSS, чтобы использовать его в полной мере. Вы можете использовать опцию конвейера отладки, описанную выше, чтобы увидеть, какой CSS присутствует во входном документе.
Более простой вариант - использовать Фильтровать информацию о стиле. Это позволяет удалить все свойства CSS указанных типов из документа. Например, вы можете использовать его, чтобы удалить все цвета или шрифты.
Стили трансформации¶
Это самое мощное средство для стилизации. Вы можете использовать его для определения правил, которые меняют стили в зависимости от условий. Например, вы можете использовать его, чтобы изменить все входения зелёного цвета на синий, или удалить все полужирные стили из текста или раскрасить все заголовки определённым цветом и т.д.
Трансформировать HTML¶
Подобно стилям трансформации, но позволяет вносить изменения в HTML-содержимое книги. Вы можете заменить один тег другим, добавить классы или другие атрибуты к тегам в зависимости от их содержимого и т. д.
Настройка страницы¶
Параметры Page setup предназначены для управления макетом экрана, например, полями и размерами экрана. Существуют варианты настройки полей страницы, которые будут использоваться плагином вывода, если выбранный формат вывода поддерживает поля страницы. Кроме того, вы должны выбрать Входной профиль и Выходной профиль. Оба набора профилей в основном имеют дело с тем, как интерпретировать измерения в документах ввода/вывода, размеры экрана и стандартные ключи изменения масштаба шрифта.
Если вы знаете, что файл, который вы конвертируете, предназначен для использования на определённом устройстве/программной платформе, выберите соответствующий профиль ввода, в противном случае просто выберите профиль ввода по умолчанию. Если вы знаете, что создаваемые вами файлы предназначены для определённого типа устройства, выберите соответствующий выходной профиль. В противном случае выберите один из общих выходных профилей. Если вы конвертируете в MOBI или AZW3, выбирайте один из выходных профилей Kindle. В противном случае для современных устройств для чтения электронных книг лучше всего выбрать выходной профиль Generic e-ink HD.
Выходной профиль также контролирует размер экрана. Это приведет, например, к автоматическому изменению размера изображений, чтобы они соответствовали экрану в некоторых выходных форматах. Поэтому выберите профиль устройства, размер экрана которого соответствует вашему устройству.
Эвристическая обработка¶
Эвристическая обработка предоставляет множество функций, которые можно использовать для обнаружения и исправления типичных проблем в плохо отформатированных входных документах. Используйте эти функции, если ваш входной документ страдает от плохого форматирования. Поскольку эти функции основаны на общих шаблонах, имейте в виду, что в некоторых случаях один из вариантов может привести к худшим результатам, поэтому используйте его с осторожностью. В качестве примера, некоторые из этих опций будут удалять все объекты без пробелов или могут включать ложно-положительные совпадения, относящиеся к функции.
- Включить эвристическую обработку
Эта опция активирует Эвристическая обработка конвейера конвертирования. Должно быть включено для применения различных субфункций
- Развернуть строки
Включение этой опции приведет к тому, что calibre попытается обнаружить и исправить жесткие разрывы строк, существующие в документе, используя знаки препинания и длину строки. Calibre сначала попытается определить, существуют ли жесткие разрывы строк, если они, по-видимому, не существуют, calibre не будет пытаться развернуть строки. Коэффициент развертывания строки может быть уменьшен, если вы хотите «заставить» calibre развернуть строки.
- Коэффициент разворачивания строки
Эта опция контролирует алгоритм, используемый calibre для удаления жёстких разрывов строк. Например, если значение этого параметра равно 0,4, это означает, что calibre удалит жёсткие разрывы строк в конце строк, длина которых меньше, чем длина 40% всех строк в документе. Если в вашем документе есть только несколько разрывов строк, которые нуждаются в исправлении, то это значение следует уменьшить до значения между 0,1 и 0,2.
- Обнаружение и разметка неформатированных заголовков и подзаголовков глав
Если ваш документ не имеет заголовков и заголовков глав, отформатированных иначе, чем остальная часть текста, calibre может использовать эту опцию, чтобы попытаться обнаружить их и окружить их тегами заголовков. <h2> теги используются для заголовков глав; <h3> теги используются для любых обнаруженных заголовков.
Эта функция не будет создавать TOC, но во многих случаях она приведет к тому, что настройки обнаружения глав по умолчанию для calibre будут правильно определять главы и создавать TOC. Настройте XPath в разделе «Определение структуры», если оглавление не создается автоматически. Если в документе нет других заголовков, тогда настройка «//h:h2» в разделе «Определение структуры» будет самым простым способом создания оглавления для документа.
Вставленные заголовки не отформатированы, чтобы применить форматирование, используйте параметр Extra CSS в настройках преобразования Look and Feel. Например, чтобы центрировать теги заголовков, используйте следующее:
h2, h3 { text-align: center }
- Перенумеровать последовательности <h1> или <h2> теги
Некоторые издатели форматируют заголовки глав, используя несколько <h1> или <h2> тегов последовательно. Настройки конвертации по умолчанию приведут к тому, что такие заголовки будут разделены на две части. Эта опция будет перенумеровывать теги заголовков, чтобы предотвратить расщепление.
- Удалить пустые строки между абзацами
Эта опция заставит calibre анализировать пустые строки, включенные в документ. Если каждый абзац перемежается пустой строкой, тогда calibre удалит все эти пустые абзацы. Последовательности из нескольких пустых строк будут считаться разрывами сцены и сохраняться как один абзац. Этот параметр отличается от параметра Удалить интервал между абзацами в разделе Look and Feel тем, что он фактически изменяет содержимое HTML, в то время как другой параметр изменяет стили документа. Эта опция также может удалить абзацы, которые были вставлены с помощью опции calibre Insert blank line.
- Убедиться, что разрывы сцен последовательно отформатированы
С помощью этой опции calibre попытается обнаружить общие маркеры разрыва сцены и убедиться, что они выровнены по центру. «Мягкие» маркеры разрыва сцены, т. е. Разрывы сцены, определяемые только дополнительным пробелом, имеют стиль, гарантирующий, что они не будут отображаться вместе с разрывами страниц.
- Replace scene breaks
Если эта опция настроена, то calibre заменит найденные маркеры разрыва сцены на текст замены, указанный пользователем. Обратите внимание, что некоторые декоративные символы могут поддерживаться не всеми устройствами чтения.
В общем, вы должны избегать использования тегов HTML, calibre отбрасывает любые теги и использует предопределенную разметку. <hr /> теги, то есть горизонтальные линейки, и <img> теги являются исключениями. Горизонтальные линейки можно опционально указывать с помощью стилей, если вы решите добавить свой собственный стиль, обязательно включите параметр „width“, иначе информация о стиле будет отброшена. Теги изображений могут использоваться, но calibre не предоставляет возможность добавлять изображение во время преобразования, это необходимо сделать после, используя функцию «Редактировать книгу».
- Пример тега изображения (поместите изображение в папку „Images“ внутри EPUB после преобразования):
<img style=»width:10%» src=»../Images/scenebreak.png» />
- Пример горизонтальной линейки со стилями:
<hr style=»width:20%;padding-top: 1px;border-top: 2px ridge black;border-bottom: 2px groove black;»/>
- Remove unnecessary hyphens
calibre будет анализировать весь контент со знаками переноса в документе, когда эта опция включена. Сам документ используется в качестве словаря для анализа. Это позволяет точно удалять дефисы для любых слов в документе на любом языке, наряду с вымышленными и неясными научными словами. Основной недостаток - слова, появляющиеся только один раз в документе, не будут изменены. Анализ происходит в два прохода, первый проход анализирует окончания строки. Строки развертываются только в том случае, если в документе есть слово с дефисом или без него. Во втором проходе анализируются все дефисные слова по всему документу, дефисы удаляются, если слово существует в другом месте документа без совпадения.
- Выделять общие слова и шаблоны курсивом
Когда включено, calibre будет искать общие слова и образцы, которые обозначают курсив и выделять их курсивом. Примерами являются обычные текстовые соглашения, такие как ~слово~ или фразы, которые обычно должны быть выделены курсивом, например латинские фразы типа „etc.“ или „et cetera“.
- Заменить существующие отступы CSS-отступами
В некоторых документах используется соглашение об определении отступов текста с использованием неразрывных пробелов. Когда эта опция включена, calibre будет пытаться обнаружить этот вид форматирования и преобразовать их в 3% текстовый отступ, используя CSS.
Поиск и замена¶
Эти параметры полезны главным образом для конвертирования документов PDF или преобразования OCR, хотя их также можно использовать для устранения многих специфических проблем документов. Например, некоторые преобразования могут оставлять верхние и нижние колонтитулы в тексте. Эти параметры используют регулярные выражения, чтобы попытаться обнаружить заголовки, нижние колонтитулы или другой произвольный текст и удалить или заменить их. Помните, что они работают на промежуточном XHTML, созданном конвейером конвертации. Существует мастер, который поможет вам настроить регулярные выражения для вашего документа. Нажмите волшебную палочку рядом с полем выражения и нажмите кнопку «Тест» после составления поискового выражения. Успешные совпадения будут выделены желтым цветом.
Поиск работает с использованием регулярных выражений Python. Весь подобранный текст просто удаляется из документа или заменяется с помощью шаблона замены. Шаблон замены является необязательным, если оставить его пустым, текст, соответствующий шаблону поиска, будет удален из документа. Вы можете узнать больше о регулярных выражениях и их синтаксисе по адресу Всё об использования регулярных выражений в calibre.
Определение структуры¶
Обнаружение структуры заставляет calibre, пытаться обнаружить структурные элементы во входном документе, когда они не определены должным образом. Например, главы, разрывы страниц, верхние и нижние колонтитулы и т. д. Как вы можете себе представить, этот процесс сильно варьируется от книги к книге. К счастью, у calibre есть очень мощные возможности для управления этим. С силой приходит сложность, но если вы потратите время на изучение сложности, вы найдете, что она того стоит.
Главы и разрывы страниц¶
calibre имеет два набора параметров для определение главы и вставка разрывов страниц. Иногда это может немного сбивать с толку, так как по умолчанию calibre вставляет разрывы страниц перед обнаруженными главами, а также местоположения, определяемые параметром разрывов страниц. Причиной этого является то, что часто есть места, где следует вставлять разрывы страниц, которые не являются границами глав. Кроме того, обнаруженные главы могут быть дополнительно вставлены в автоматически сгенерированное оглавление.
calibre использует XPath, мощный язык, позволяющий пользователю определять границы глав/разрывы страниц. Поначалу XPath может показаться немного сложным, к счастью, в руководстве пользователя есть Учебник по XPath. Помните, что определение структуры работает на промежуточном XHTML, созданном конвейером конвертации. Используйте опцию отладки, описанную в Предисловие, чтобы выяснить значение соответствующих настроек для вашей книги. Существует также кнопка для мастера XPath, которая поможет с генерацией простых выражений XPath.
По умолчанию calibre использует следующее выражение для определения глав:
//*[((name()='h1' or name()='h2') and re:test(., 'chapter|book|section|part\s+', 'i')) or @class = 'chapter']
Это выражение довольно сложное, потому что оно пытается обрабатывать несколько общих случаев одновременно. Это означает, что calibre будет предполагать, что главы начинаются с тегов <h1> или <h2>, в которых есть любое из слов (глава, книга, раздел или часть) chapter, book, section or part или которые имеют атрибут class=»chapter».
Связанная опция Метка главы, которая позволяет вам контролировать, что делает calibre при обнаружении главы. По умолчанию он вставляет разрыв страницы перед главой. Вы можете добавить вставленную линию вместо этого или в дополнение к разрыву страницы. Вы также можете этого не делать.
Настройка по умолчанию для обнаружения разрывов страниц:
//*[name()='h1' or name()='h2']
это означает, что calibre будет вставлять разрывы страниц перед каждым тегом <h1> и <h2> по умолчанию.
Примечание
Выражения по умолчанию могут меняться в зависимости от формата ввода, который вы конвертируете.
Разное¶
В этом разделе есть еще несколько опций.
- Вставить метаданные как страницу в начале книги
Одна из замечательных особенностей calibre заключается в том, что он позволяет вам хранить полные метаданные обо всех ваших книгах, например, оценку, теги, комментарии и т. д. Эта опция создаст одну страницу со всеми этими метаданными и вставит ее в сконвертированную электронную книгу, как правило, сразу после обложки. Думайте об этом как о способе создать свою собственную настроенную обложку книги.
- Удалить первое изображение
Иногда исходный документ, который вы конвертируете, включает обложку как часть книги, а не как отдельную обложку. Если вы также укажете обложку calibre, то в конвертированной книге будет две обложки. Эта опция просто удалит первое изображение из исходного документа, тем самым гарантируя, что конвертированная книга имеет только одну обложку, ту, которая указана в calibre.
Содержание¶
Когда входной документ содержит оглавление в своих метаданных, calibre просто использует его. Однако некоторые старые форматы либо не поддерживают оглавление на основе метаданных, либо отдельные документы не имеют такового. В этих случаях параметры в этом разделе могут помочь вам автоматически сгенерировать оглавление в сконвертированной электронной книге на основе фактического содержания во входном документе.
Примечание
Использование этих опций может быть немного сложным, чтобы получилось абсолютно правильно. Если вы предпочитаете создавать/редактировать оглавление вручную, преобразуйте его в форматы EPUB или AZW3 и установите флажок в нижней части раздела «Оглавление» диалогового окна преобразования, которое гласит :guilabel: «Вручную настроить таблицу содержания после конвертации`. Запустится редактор таблицы содержания после конвертации. Он позволит вам создавать записи в оглавлении, просто щёлкнув место в книге, на которое будет указывать запись. Вы также можете использовать Редактор оглавления самостоятельно, без конвертации. Перейдите по адресу Настройки → Интефейс → Панели инструментов и добавьте ToC редактор на главную панель инструментов. Затем просто выберите книгу, которую вы хотите отредактировать, и нажмите кнопку ToC редактор.
Первый вариант Принудительно использовать автосгенерированное оглавление. Отметив эту опцию, вы можете перезаписать любое оглавление, найденное в метаданных входного документа автоматически сгенерированным.
Способ создания автоматически сгенерированного оглавления по умолчанию заключается в том, что calibre сначала попытается добавить любые обнаруженные главы в сгенерированное оглавление. Вы можете узнать, как настроить обнаружение глав в разделе Определение структуры выше. Если вы не хотите включать обнаруженные главы в сгенерированное оглавление, отметьте опцию Не добавлять обнаруженные главы.
Если было обнаружено меньше глав, чем число Порог главы, то calibre добавит любые гиперссылки, найденные во входном документе, в оглавление. Это часто хорошо работает, многие входные документы включают в себя содержание с гиперссылкой в самом начале. Опция Количество ссылок может использоваться для управления этим поведением. Если установлено в ноль, ссылки не добавляются. Если установлено значение больше нуля, добавляется самое большое количество ссылок.
calibre будет автоматически фильтровать дубликаты из сгенерированного содержания. Однако, если есть некоторые дополнительные нежелательные записи, вы можете отфильтровать их, используя опцию TOC Filter. Это регулярное выражение, которое будет соответствовать заголовку записей в сгенерированном оглавлении. Всякий раз, когда совпадение найдено, оно будет удалено. Например, чтобы удалить все записи заголовков «Next» или «Previous», используйте:
Next|Previous
Опции Уровень 1,2,3 TOC позволяют вам создавать сложные многоуровневые оглавления. Это выражения XPath, которые соответствуют тегам в промежуточном XHTML, созданном конвейером преобразования. Чтобы узнать, как получить доступ к этому XHTML, смотрите Предисловие. Также прочитайте Учебник по XPath, чтобы узнать, как создавать выражения XPath. Рядом с каждым параметром находится кнопка, которая запускает мастер, помогающий создавать основные выражения XPath. В следующем простом примере показано, как использовать эти параметры.
Предположим, у вас есть входной документ с XHTML, который выглядит следующим образом:
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<title>Sample document</title>
</head>
<body>
<h1>Chapter 1</h1>
...
<h2>Section 1.1</h2>
...
<h2>Section 1.2</h2>
...
<h1>Chapter 2</h1>
...
<h2>Section 2.1</h2>
...
</body>
</html>
Затем мы устанавливаем параметры как:
Level 1 TOC : //h:h1
Level 2 TOC : //h:h2
Это приведет к автоматически сгенерированному двухуровневому оглавлению, которое выглядит следующим образом:
Chapter 1
Section 1.1
Section 1.2
Chapter 2
Section 2.1
Предупреждение
Не все выходные форматы поддерживают многоуровневое оглавление. Сначала вы должны попробовать с выходом EPUB. Если это работает, попробуйте ваш формат выбора.
Использование изображений в качестве заголовков глав при преобразовании входных документов HTML¶
Предположим, вы хотите использовать изображение в качестве названия главы, но все же хотите, чтобы calibre мог автоматически генерировать для вас оглавление из названий глав. Для этого используйте следующую разметку HTML:
<html>
<body>
<h2>Chapter 1</h2>
<p>chapter 1 text...</p>
<h2 title="Chapter 2"><img src="chapter2.jpg" /></h2>
<p>chapter 2 text...</p>
</body>
</html>
Установите для Уровень 1 TOC значение //h:h2. Затем, во второй главе, calibre получит заголовок из значения атрибута title тега <h2>, поскольку у тега нет текста.
Использование атрибутов тега для предоставления текста для записей в оглавлении¶
Если у вас особенно длинные заголовки глав и вам нужны сокращенные версии в оглавлении, вы можете использовать атрибут title для достижения этого, например:
<html>
<body>
<h2 title="Chapter 1">Chapter 1: Some very long title</h2>
<p>chapter 1 text...</p>
<h2 title="Chapter 2">Chapter 2: Some other very long title</h2>
<p>chapter 2 text...</p>
</body>
</html>
Установите для Level 1 TOC значение //h:h2/@title. Тогда calibre получит заголовок из значения атрибута title в тегах <h2> вместо использования текста внутри тега. Обратите внимание на завершающий /@title в выражении XPath, вы можете использовать эту форму, чтобы указать calibre, что нужно получить текст из любого понравившегося вам атрибута.
Как параметры устанавливаются/сохраняются для конвертации¶
Есть два места, где параметры конвертации могут быть установлены в calibre. Первый находится в Предпочтения-> Конверсия. Эти настройки являются настройками по умолчанию для параметров конвертации. Всякий раз, когда вы пытаетесь сконвертировать новую книгу, настройки, установленные здесь, будут использоваться по умолчанию.
Вы также можете изменить настройки в диалоге конвертации для каждой конвертации книги. Когда вы конвертируете книгу, calibre запоминает настройки, которые вы использовали для этой книги, так что если вы конвертируете её снова, сохраненные настройки для отдельной книги будут иметь приоритет над значениями по умолчанию, установленными в Настройки. Вы можете восстановить отдельные настройки по умолчанию, используя кнопку Восстановить настройки по умолчанию в диалоге конвертации отдельной книги. Вы можете удалить сохраненные настройки для группы книг, выбрав все книги и нажав кнопку Редактировать метаданные, чтобы открыть диалоговое окно массового редактирования метаданных, в нижней части диалогового окна есть опция для удаления настроек сохраненной конвертации.
Когда вы массово конвертируете набор книг, настройки берутся в следующем порядке (выигрывает последняя):
Из значений по умолчанию, установленных в Настройки->Конвертация
Из сохраненных настроек конвертации для каждой конвертируемой книги (если есть). Это можно отключить с помощью параметра в верхнем левом углу диалогового окна «Массовая конвертация».
Из настроек, установленных в диалоговом окне Массовая конвертация
Обратите внимание, что окончательные настройки для каждой книги в Массовой конвертации будут сохранены и использованы повторно, если книга будет преобразована снова. Так как наивысший приоритет в массовой конвертации преобразовании отдается настройкам в диалоговом окне «Массовая конвертация», они переопределяют любые параметры, специфичные для книги. Таким образом, вы должны конвертировать только те книги, которые нуждаются в похожих настройках. Исключение составляют метаданные и специфичные для входного формата настройки. Поскольку в диалоговом окне «Массовая конвертация» нет настроек для этих двух категорий, они будут взяты из настроек книги (если они есть) или значений по умолчанию.
Примечание
Вы можете увидеть фактические настройки, использованные во время любой конвертации, щелкнув вращающийся значок в правом нижнем углу, а затем дважды щёлкнув на отдельном задании конвертации. Это вызовет журнал конвертаций, который будет содержать фактические используемые настройки в верхней части.
Формат-специфичные советы¶
Здесь вы найдете советы, касающиеся конвертации определенных форматов. Параметры, специфичные для конкретного формата, независимо от того, доступны ли вход или выход в диалоге преобразования в их собственном разделе, например, TXT input или` EPUB output`.
Конвертация документов Microsoft Word¶
calibre может автоматически конвертировать файлы .docx, созданные в Microsoft Word 2007 и новее. Просто добавьте файл в calibre и нажмите «Конвертировать».
Примечание
Существует :download_file:`demo .docx file <demos/demo.docx>, демонстрирующий возможности механизма конвертации calibre. Просто скачайте его и конвертируйте в EPUB или AZW3, чтобы узнать на что способен calibre.
calibre автоматически сгенерирует оглавление на основе заголовков, если вы пометите свои заголовки стилями «Заголовок 1», «Заголовок 2» и т. д. в Microsoft Word. Откройте выходную электронную книгу в просмотрщике электронных книг calibre и нажмите кнопку Оглавление, чтобы просмотреть сгенерированное оглавление.
Старые файлы .doc¶
Для старых файлов .doc вы можете сохранить документ в формате HTML с помощью Microsoft Word, а затем преобразовать полученный HTML-файл в calibre. При сохранении в формате HTML обязательно используйте параметр «Сохранить как веб-страницу, отфильтрованный», поскольку при этом будет получен чистый HTML, который будет хорошо конвертироваться. Обратите внимание, что Word создает грязный HTML, его преобразование может занять много времени, так что наберитесь терпения. Если у вас есть более новая версия Word, вы также можете напрямую сохранить файл в формате docx.
Другой альтернативой является использование бесплатного OpenOffice/LibreOffice. Откройте файл .doc в OpenOffice/LibreOffice и сохраните его в формате .docx, которыей может напрямую конвертироваться в calibre
Конвертировать TXT документы¶
Документы TXT не имеют четко определенного способа задания форматирования, такого как полужирный шрифт, курсив и т. д., или структуры документа, такой как абзацы, заголовки, разделы и т. д., но существует множество общепринятых соглашений. По умолчанию calibre пытается автоматически определить правильное форматирование и разметку на основе этих соглашений.
Ввод TXT поддерживает ряд опций, позволяющих различать способы обнаружения абзацев.
- Стиль абзаца: Авто
Анализировать текстовый файл и пытаться автоматически определить, как определяются абзацы. Этот параметр обычно работает нормально, если вы достигнете нежелательных результатов, попробуйте один из вариантов вручную.
- Стиль абзаца: Блок
Предположить, что одна или несколько пустых строк являются границей абзаца:
This is the first. This is the second paragraph.- Стиль абзаца: Одиночный
Предположить, что каждая строка - абзац:
This is the first. This is the second. This is the third.- Стиль абзаца: Печать
Предположить, что каждый абзац начинается с отступа (либо табуляция, либо 2+ пробелов). Абзацы заканчиваются, когда достигается следующая строка, начинающаяся с отступа:
This is the first. This is the second. This is the third.- Стиль абзаца: Неформатированный
Предположить, что документ не имеет форматирования, но использует жесткие переносы строк. Пунктуация и средняя длина строки используются для воссоздания абзацев.
- Стиль форматирования: Авто
Попытаться определить тип используемой разметки форматирования. Если разметка не используется, будет применено эвристическое форматирование.
- Стиль форматирования: Эвристика
Анализировать документ на наличие общих заголовков глав, разрывов сцен и выделенных курсивом слов и применить соответствующую разметку HTML во время конвертирования.
- Стиль форматирования: Markdown
calibre также поддерживает запуск ввода TXT через препроцессор преобразования, известный как Markdown. Markdown позволяет добавлять базовое форматирование в документы TXT, такие как полужирный шрифт, курсив, заголовки разделов, таблицы, списки, оглавление и т. д. Пометить заголовки глав начальным # и установить для выражения обнаружения XPath главы значение «//h:h1 «- это самый простой способ получить правильное оглавление, сгенерированное из документа TXT. Вы можете узнать больше о синтаксисе Markdown в daringfireball.
- Стиль форматирования: Нет
К тексту не применяется никакого специального форматирования, документ конвертируется в HTML без каких-либо других изменений.
Преобразование PDF документов¶
PDF документы - один из худших форматов для конвертации. Они имеют фиксированный размер страницы и формат размещения текста. То есть очень трудно определить, где заканчивается один абзац и начинается другой. calibre попытается развернуть абзацы с помощью настраиваемого Line Un-Wrapping Factor. Это шкала, используемая для определения длины, на которой должна быть развернута строка. Допустимые значения: десятичное число от 0 до 1. Значение по умолчанию - 0,45, чуть меньше длины средней строки. Уменьшите это значение, чтобы включать больше текста в развертывание. Увеличьте, чтобы включать меньше. Вы можете отрегулировать это значение в настройках преобразования в разделе PDF Input.
Кроме того, их верхние и нижние колонтитулы часто включаются в основной текст документа. Используйте панель Поиск и замена для удаления верхних и нижних колонтитулов, чтобы смягчить эту проблему. Если верхние и нижние колонтитулы не удалены из текста, это может привести к разворачиванию абзаца. Чтобы узнать, как использовать параметры удаления верхнего и нижнего колонтитула, прочитайте Всё об использования регулярных выражений в calibre.
Некоторые ограничения ввода с PDF:
Сложные документы с несколькими столбцами и изображениями не поддерживаются.
Извлечение векторных изображений и таблиц из документа также не поддерживается
В некоторых PDF-файлах используются специальные глифы для обозначения ll или ff или fi и т. д. Конвертация может их обработать или не обработать в зависимости от того, как они внутренне представлены в PDF.
Ссылки и оглавления не поддерживаются
PDF-файлы, в которых для представления неанглоязычных символов используются встроенные шрифты, отличные от Юникода, приведут к искажённому выводу этих символов.
Некоторые PDF-файлы состоят из фотографий страницы с распознанным текстом OCR позади них. В таких случаях calibre использует распознанный текст, который может сильно отличаться от того, что вы видите при просмотре файла PDF.
PDF-файлы, которые используются для отображения сложного текста, такого как языки с письмом справа налево и математические наборы, не будут правильно сконвертированы
Повторяю PDF - это действительно очень плохой формат для использования в качестве входных данных. Если вам абсолютно необходимо использовать PDF, будьте готовы к выводу в диапазоне от приличного до непригодного для использования, в зависимости от входного PDF.
Коллекции комиксов¶
Коллекция комиксов - это файл .cbc. Файл .cbc представляет собой ZIP-файл, содержащий другие файлы CBZ/CBR. Кроме того, файл .cbc должен содержать простой текстовый файл с именем comics.txt, закодированный в UTF-8. Файл comics.txt должен содержать список файлов комиксов в файле .cbc в форме имя файла:заголовок, как показано ниже:
one.cbz:Chapter One
two.cbz:Chapter Two
three.cbz:Chapter Three
Файл .cbc будет содержать:
comics.txt
one.cbz
two.cbz
three.cbz
calibre автоматически преобразует этот файл .cbc в электронную книгу с оглавлением, указывающим на каждую запись в comics.txt.
Демоверсия расширенного форматирования EPUB¶
Различное расширенное форматирование для файлов EPUB демонстрируется в этом демофайле demo file. Файл был создан из HTML-кода, написанного вручную в calibre, это - шаблон для создания ваших собственных EPUB.
Исходный HTML-код, из которого он был создан, здесь demo.zip. Настройки, используемые для создания EPUB из файла ZIP:
ebook-convert demo.zip .epub -vv --authors "Kovid Goyal" --language en --level1-toc '//*[@class="title"]' --disable-font-rescaling --page-breaks-before / --no-default-epub-cover
Обратите внимание, что, так как этот файл раскрывает потенциал EPUB, большая часть расширенного форматирования не будет работать на читалках, с меньшими возможностями, чем встроенный в calibre EPUB просмотрщик.
Конвертировать ODT документы¶
calibre может напрямую конвертировать файлы ODT (OpenDocument Text). Вы должны использовать стили для форматирования вашего документа и минимизировать использование прямого форматирования. При вставке изображений в документ необходимо привязать их к абзацу, изображения, привязанные к странице, в конечном итоге окажутся в начале преобразования.
Чтобы включить автоматическое определение глав, вам необходимо пометить их встроенными стилями Heading 1, Heading 2, …, Heading 6 (Heading 1 соответствует HTML tag <h1>, Heading 2 - <h2>, и т.д.). При конвертировании в calibre вы можете указать стиль, который вы использовали, в поле Определить главы в. Пример:
Если вы помечаете главы стилем Heading 2, установите для поля „Определить главы по“ значение
//h:h2`Для вложенного оглавления с разделами, помеченными как Heading 2 и разделами, помеченными как Heading 3, необходимо ввести
//h:h2|//h:h3. На странице «Преобразование - ТОС» установите для поля Level 1 TOC значение//h:h2, а для поля Level 2 TOC -//h:h3.
Хорошо известные свойства документа (Название, Ключевые слова, Описание, Создатель) распознаются, и calibre будет использовать первое изображение (не слишком маленькое и с хорошим соотношением сторон) в качестве изображения обложки.
Существует также расширенный режим преобразования свойств, который активируется установкой настраиваемого свойства opf.metadata (тип „Yes или No“) на Yes в вашем документе ODT (Файл->Свойства->Пользовательские свойства). Если это свойство обнаружено calibre, распознаются следующие пользовательские свойства (opf.authors переопределяет создателя документа):
opf.titlesort
opf.authors
opf.authorsort
opf.publisher
opf.pubdate
opf.isbn
opf.language
opf.series
opf.seriesindex
В дополнение к этому вы можете указать изображение для использования в качестве обложки, назвав его opf.cover (щелкните правой кнопкой мыши, Изображение->Опции->Имя) в ODT. Если изображение с таким именем не найдено, используется «умный» метод. Поскольку обнаружение обложки может привести к двойным обложкам в определённых выходных форматах, процесс удалит абзац (только если содержит только обложку!) из документа. Но это работает только с именованным изображением!
Чтобы отключить обнаружение обложки, вы можете установить для настраиваемого свойства opf.nocover (тип «Yes или No») значение «Yes» в расширенном режиме.
Конвертация в PDF¶
Первое и наиболее важное решение для преобразования в PDF — настройка размера страницы. По умолчанию в calibre используется размер «U.S. Letter». Вы можете изменить его на другой стандартный или полностью произвольный размер страницы в разделе PDF Output диалога преобразования. Если вы создаёте PDF для определённого устройства, вместо этого можно включить опцию использования размера страницы из output profile. Так, если выходной профиль — Kindle, calibre создаст PDF-файл с размером страницы, подходящим для просмотра на маленьком экране.
Оглавление для печати¶
Вы также можете вставить печатное оглавление в конец PDF-файла, в котором перечислены номера страниц для каждого раздела. Это очень полезно, если вы собираетесь распечатать PDF на бумаге. Если вы хотите использовать PDF на электронном устройстве, PDF Outline предоставляет эту функцию и создается по умолчанию.
Вы можете настроить внешний вид сгенерированного оглавления с помощью параметра «Дополнительное преобразование CSS» в разделе «Внешний вид» диалогового окна конвертации. Используемый css по умолчанию приведен ниже, просто скопируйте его и внесите все необходимые изменения.
.calibre-pdf-toc table { width: 100%% }
.calibre-pdf-toc table tr td:last-of-type { text-align: right }
.calibre-pdf-toc .level-0 {
font-size: larger;
}
.calibre-pdf-toc .level-1 td:first-of-type { padding-left: 1.4em }
.calibre-pdf-toc .level-2 td:first-of-type { padding-left: 2.8em }
Пользовательские поля страницы для отдельных файлов HTML¶
Если вы конвертируете файл EPUB или AZW3 с несколькими отдельными файлами HTML внутри него и хотите изменить поля страницы для определённого файла HTML, вы можете добавить следующий блок стилей в файл HTML с помощью редактора calibre:
<style>
@page {
margin-left: 10pt;
margin-right: 10pt;
margin-top: 10pt;
margin-bottom: 10pt;
}
</style>
Затем в разделе вывода PDF диалогового окна конвертации включите параметр Использовать поля страницы из преобразовываемого документа. Теперь все страницы, сгенерированные из этого HTML-файла, будут иметь поля 10pt.