 言語を変更
言語を変更電子書籍変換¶
calibre には、非常に使いやすいように設計された変換システムがあります。通常、本を calibre に追加し、変換をクリックすると、calibre はできるだけ入力に近い出力を生成しようとします。ただし calibre は数多くの入力形式を受け付けますが、そのすべてが電子書籍への変換に適しているわけではありません。このような入力形式の場合、または変換システムをより細かく制御したい場合、calibreには変換プロセスを微調整するための多くのオプションがあります。ただし、calibreの変換システムは、本格的な電子書籍エディタの代わりにはならないことに注意してください。電子書籍を編集するには、まず calibre を使用して EPUB または AZW3 に変換し、次に 本の編集 機能を使って完璧に仕上げることをお勧めします。それが終われば編集した電子書籍を入力として、calibre の他の形式に変換するために利用できます。
このドキュメントでは主に、下の図に示す変換ダイアログの変換設定について説明します。これらの設定はすべて、コマンドラインインターフェイスからの変換にも使用できます。これについては、ebook-convert に記載されています。calibreでは、それぞれの設定項目の上にマウスを置くと、その設定に関するヘルプがツールチップで表示されます。
はじめに¶
変換システムについて最初に理解すべきは、パイプラインとして設計されているということです。図にすると、次のようになっています:
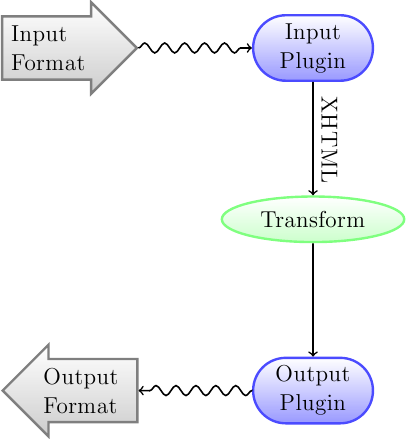
入力形式は、まず適切な 入力プラグイン によってXHTMLに変換されます。このHTMLは次に 変形 されます。最後のステップで、この処理された XHTML が、適切な 出力プラグイン によって指定された出力形式に変換されます。変換の結果は、入力形式によって大きく異なる可能性があります。一部の形式は、他の形式よりもずっとうまく変換されます。変換にあたりソースとして最適な形式の一覧は こちら にあります。
XHTML 出力に作用する変形こそが、すべての作業が行われる場所です。変形にはさまざまなものがありますが、たとえば、書誌を本の冒頭にページとして挿入したり、章の見出しを探して目次を自動的に作成したり、フォントサイズを比例的に調整したりするなど、といったことを行います。ただしこうした変形はすべて、入力ファイルそのものではなく、入力プラグイン から出力される XHTML に対して作用します。したがって、たとえば、calibre に RTF ファイルを EPUB に変換するよう求めると、まず内部で XHTML に変換され、さまざまな変形が XHTML に適用されてから、出力プラグイン がすべての書誌や目次などを自動的に生成して EPUB ファイルを作成します。
デバッグオプション  を使用すると、この処理が動いているところを確認できます。デバッグ出力用のフォルダへのパスを指定するだけで使用できます。変換中、calibre は変換パイプラインのさまざまな段階で生成された XHTML を別々のサブフォルダに配置します。この 4つのサブフォルダは次のものです:
を使用すると、この処理が動いているところを確認できます。デバッグ出力用のフォルダへのパスを指定するだけで使用できます。変換中、calibre は変換パイプラインのさまざまな段階で生成された XHTML を別々のサブフォルダに配置します。この 4つのサブフォルダは次のものです:
フォルダ |
説明 |
|---|---|
input |
これには入力プラグインによる HTML 出力が含まれています。入力プラグインをデバッグするには、これを使用します。 |
parsed |
入力プラグインからの出力を前処理して XHTML に変換した結果。構造検出をデバッグするために使用します |
structure |
構造検出後、ただし CSS フラット化とフォントサイズ変換の前。フォントサイズ変換と CSS 変形をデバッグするために使用します。 |
processed |
電子書籍が出力プラグインに渡される直前。出力プラグインをデバッグするために使用します。 |
calibre で変換する前に入力ドキュメントを少し編集したい場合、最善なのは input サブフォルダ内のファイルを編集してから圧縮し、その ZIP ファイルを変換の入力として使用することです。これを行うには、書誌の編集 ダイアログを使用して、書籍の形式に ZIP ファイルを追加し、変換ダイアログの左上端で、入力形式として ZIP を選択します。
このドキュメントでは、主に中間XHTMLに対して行うさまざまな変形と、それを制御する方法について説明します。最後に、各入出力形式に固有のヒントをいくつか記載します。
外観¶
このオプションのグループは、変換した電子書籍の見た目をさまざまな側面から制御します。
フォント¶
電子読書体験において最もすばらしい機能のひとつは、個々のニーズや照明条件に合わせてフォントサイズを簡単に調整できることです。calibre には高度なアルゴリズムがあり、入力ドキュメントでどのようなフォントサイズが指定されていようとも、出力される本ではどれもフォントサイズがそのままであることを保証します。
ドキュメントの基本フォントサイズとは、そのドキュメントで最もよく使われているフォントサイズ、つまりそのドキュメントのテキストの大部分で使われるサイズのことです。 基本フォントサイズ を指定すると、calibreはドキュメント内のすべてのフォントサイズを比例して自動的に再スケーリングします。これにより、最もよく使われているフォントサイズが指定された基本フォントサイズになり、他のフォントは適宜サイズ調整されます。基本フォントサイズを大きくすれば、ドキュメント内の他のフォントも大きくなりますし、逆もまた同じです。基本フォントサイズを設定する場合には、最良の結果を得るために、フォントサイズのキーも設定するとよいでしょう。
通常、calibreは、選択した出力プロファイルに適した基本フォントサイズを自動的に選択します (ページ設定 を参照)。ただしデフォルトが適切でない場合は、ここで上書きできます。
フォントサイズのキー オプションを使用すると、基本フォントサイズ以外のフォントをサイズ調整する方法を制御できます。フォントサイズ調整アルゴリズムは、フォントサイズのキーを使用して機能します。フォントサイズのキーは、フォントサイズのコンマ区切りのリストです。フォントサイズのキーは、特定のフォントサイズを基本フォントサイズと比較して、いくつの「ステップ」を大きくしたり小さくしたりするかを calibre に指示します。大事なのは、ドキュメント内のフォントサイズの数を制限する必要があるということです。たとえば、本文テキスト用に 1 個のサイズ、さまざまなレベルの見出し用に 2、3 個のサイズ、上付き/下付き文字と脚注用に 2、3 個のサイズがあります。フォントサイズのキーを使用すれば、calibre が入力ドキュメントのフォントサイズを、さまざまな論理フォントサイズに対応する個別の「ビン」に区分することができるようになります。
例を挙げて説明しましょう。変換しようとしているソースドキュメントが、視力に優れた人によって作成されているため、基本フォントサイズが 8pt であるとします。つまり、ドキュメント内のテキストの大部分のサイズが 8 ポイントで、見出しはやや大きく (たとえば、10 および 12 ポイント)、脚注は 6 ポイントでやや小さくなっています。ここで、次の設定を使用するとします:
Base font size : 12pt
Font size key : 7, 8, 10, 12, 14, 16, 18, 20
出力ドキュメントの基本フォントサイズは 12pt、見出しは 14 および 16pt、脚注は 8pt になります。ここで、最も大きな見出しサイズをより目立たせ、脚注も少し大きくしたいとします。これを実現するには、フォントのキーを次のように変更する必要があります:
New font size key : 7, 9, 12, 14, 18, 20, 22
最大の見出しが 18pt になり、脚注は 9pt になります。これらの設定を試して、フォントサイズ調整ウィザードを使用して最適なものを見つけてください。このウィザードには フォントサイズのキー 設定の横にある小さなボタンをクリックすると利用できます。
入力ドキュメントのフォントサイズをそのまま使いたい場合は、変換でフォントのサイズ調整を行わないよう、ここで設定できます。
関連する設定は 行の高さ です。行の高さは、行の垂直方向の高さを制御します。デフォルトでは (行の高さは0)、行の高さの操作は実行されません。デフォルト以外の値を指定すると、行の高さは、独自の行の高さを指定しないすべての場所に設定されます。ただしこれは鈍器のようなものであり、控えめに使用する必要があります。入力の一部のセクションの行の高さを調整する場合は、追加 CSS を使用することをお勧めします。
このセクションでは、参照されているフォントを本に埋め込むように calibre に指示することもできます。これにより、そのフォントがデバイス上にない場合でも、リーダーデバイスで機能するようになります。
テキスト¶
テキストは両端揃えにする場合としない場合があります。両端揃えのテキストには、単語の間に余分な空白があり、右マージンが滑らかになります。両端揃えのテキストを好む人もいれば、好まない人もいます。通常、calibre は元のドキュメントのテキスト揃えの状態をそのまま使用します。これを上書きしたい場合は、このセクションの テキスト揃え オプションを使用できます。
また、calibreに 句読点をスマート化 を指定することもできます。指定すると、プレーンな引用符、ダッシュ、省略記号が、活字で正しい代替記号に置き換えられます。ただしアルゴリズムは完全ではないため、結果を確認する価値があります。逆、つまり スマート化されていない句読点 も使用できます。
最後に、入力文字コード があります。古いドキュメントでは、文字コードが指定されていないことがあります。これを変換すると、英語以外の文字やスマート引用符などの特殊文字が破損する可能性があります。calibre はソースドキュメントの文字コードの自動検出を試みますが、常に成功するとは限りません。この設定を使用すれば、特定の文字コードを前提とするように強制できます。 cp1252は、Windowsソフトウェアを使用して作成されたドキュメントの一般的な文字コードです。文字コードの問題について詳しくは 英語以外の文字やスマート引用符を含むファイルを変換するにはどうすればよいですか? もお読みください。
レイアウト¶
通常、XHTML の段落は、段落の間に空白行があり、先頭にテキストのインデントがない状態でレンダリングされます。calibre には、これを制御するためのいくつかのオプションがあります。 段落間の空白を削除 は、すべての段落に段落間の間隔がないことを強制的に保証します。また、テキストのインデントを 1.5em (変更可能) に設定して、すべての段落の開始をマークします。 空行を挿入 は逆のことを行い、段落の各ペアの間に正確に 1 つの空白行があることを保証します。これらのオプションはどちらも非常に包括的で、空白の削除や挿入は すべての 段落に対して行われます (技術的には <p> タグと <div> タグ)。これは入力ファイルがどれほど乱雑であろうとも、オプションを設定するだけで、宣伝どおりに機能することを保証できるようにするためです。唯一の例外は、入力ファイルが段落間の間隔を実装するためにハード改行を使用している場合です。
すべての段落間の間隔を削除したい場合は、一部の例外を除き、これらのオプションを使用しないでください。代わりに、次の CSS コードを 追加 CSS に追加します:
p, div { margin: 0pt; border: 0pt; text-indent: 1.5em }
.spacious { margin-bottom: 1em; text-indent: 0pt; }
次にソースドキュメントで、間隔が必要な段落に class="spacious" とマークします。入力ドキュメントが HTML でない場合は、HTML を取得するための入門部分で説明されているデバッグオプションを使用します (input サブフォルダを使用します)。
もうひとつの便利なオプションは、 表を展開 です。不適切に設計されたドキュメントの中には、表を使ってページ上のテキストのレイアウトを制御するものがあります。このようなドキュメントを変換すると、ページからはみ出すテキストやその他の歪みが含まれていることがよくあります。このオプションは、表からコンテンツを抽出し、線形に表示します。ただしこのオプションは すべて の表を線形化するため、入力ドキュメントが表形式の情報の表示などの正当な目的でテーブルを使用していないことが確実な場合にのみ使用してください。
スタイル¶
追加 CSS オプションを使用すると、入力内のすべての HTML ファイルに適用される任意のCSSを指定できます。このCSSは非常に高い優先度で適用されるため、 入力ドキュメント 自体に存在するほとんどの CSS を上書きします。この設定を使用すれば、ドキュメントのプレゼンテーション/レイアウトを微調整できます。たとえば、クラスの文末脚注のすべての段落を右揃えにしたい場合は、次を追加します:
.endnote { text-align: right }
または、すべての段落のインデントを変更したい場合には次のようにします:
p { text-indent: 5mm; }
追加 CSS は非常に強力なオプションですが、CSS を最大限に活用するには、CSS がどのように機能するかを理解する必要があります。上記のデバッグパイプラインオプションを使用すると、入力ドキュメントに存在する CSS を確認できます。
より簡単なオプションは、スタイル情報を絞り込み を使用することです。これを使うと、指定したタイプのすべての CSS プロパティをドキュメントから削除できます。たとえば、すべての色またはフォントの削除に利用できます。
スタイルの変形¶
これは、最も強力なスタイリング関連の機能です。これを使用すると、さまざまな条件に基づいてスタイルを変更するルールを定義できます。たとえば、すべての緑色を青色に変更したり、テキストからすべての太字のスタイルを削除したり、すべての見出しを特定の色に着色したりするのに利用できます。
HTML の変形¶
変換スタイルに似た機能で、本の HTML コンテンツに変更を加えることができます。あるタグを別のタグに置き換えたり、コンテンツに基づいてクラスやその他の属性をタグに追加したりできます。
ページ設定¶
ページ オプションは、余白や画面サイズなどの画面レイアウトを制御するためのものです。選択した出力形式がページ余白をサポートしている場合に出力プラグインによって使用される、ページ余白を設定するオプションがあります。さらに、入力プロファイルと出力プロファイルを選択する必要があります。プロファイルのセットは両方とも基本的には、入力/出力ドキュメント、画面サイズ、およびデフォルトのフォントサイズ調整のキーの寸法をどのように解釈するかを扱います。
変換しようとしているファイルが特定のデバイス/ソフトウェアプラットフォームでの使用を目的としていることがわかっている場合は、対応する入力プロファイルを選択します。それ以外の場合は、デフォルトの入力プロファイルを選択します。作成しているファイルが特定のデバイスタイプ用であることがわかっている場合は、対応する出力プロファイルを選択してください。それ以外の場合は、汎用出力プロファイルのひとつを選択します。MOBI または AZW3 に変換するのであれば、ほとんどの場合、Kindle の出力プロファイルのひとつを選択したいと思うでしょう。そうでなければ、最新の電子書籍リーダーデバイスに最善なのは、汎用電子ペーパー HD` 出力プロファイルを選択することです。
出力プロファイルは、画面サイズも制御します。これにより、たとえば一部の出力形式では、画像が画面に収まるように自動的にサイズ変更されることになります。ですから、デバイスと同じような画面サイズを持つデバイスのプロファイルを選択してください。
ヒューリスティック処理¶
ヒューリスティック処理は、書式のくずれた入力ドキュメントにありがちな問題を検出して修正するためのさまざまな機能を提供します。入力ドキュメントの書式がくずれている場合は、これらの関数を使用してください。ただしこれらの関数は一般的なパターンに頼っているため、オプションによっては結果が悪化する可能性があります。例を挙げると、これらのオプションのいくつかは、すべてのノンブレークスペースエンティティを削除したり、関数に関連して誤検知することがあります。
- ヒューリスティック処理を行う
このオプションは、calibreの 変換パイプラインの ヒューリスティック処理 ステージを有効にします。さまざまなサブ機能を適用するには、これが有効になっている必要があります。
- 行折り返し解除
このオプションを有効にすると、calibre は句読点の手がかりと行の長さを使用して、ドキュメント内に存在するハード改行を検出して修正しようとします。 calibreは、まずハード改行が存在するかどうかを検出しようとします。存在しないように見える場合、calibreは行の折り返しを解除しようとはしません。calibre に行の折り返しを解除するように強制したい場合には、行折り返し解除係数を減らすことができます。
- 行折り返し解除係数
このオプションは、calibre がハード改行の削除に使用するアルゴリズムを制御します。たとえばこのオプションの値が 0.4 の場合、ドキュメント内のすべての行の長さの 40% より短ければ、その行の末尾から calibre がハード改行を削除することを意味します。ドキュメントに修正が必要な改行が数個しかない場合は、この値を 0.1 〜 0.2 の範囲に減らす必要があります。
- 書式のない章見出しとサブ見出しを探してマークアップ
ドキュメントの中に、他のテキストと書式が異なる章見出しとタイトルが存在しない場合、このオプションを使用すると calibre はそれを探して見出しタグで囲むことができます。 <h2> タグは、章見出しに使用されます。 <h3> タグは、見つかったすべてのタイトルに使用されます。
この機能が目次を作成するわけではありませんが、たいていの場合はこれによって calibre のデフォルトの章検出設定が正しく章を探して目次を作成するようになります。目次が自動的に作成されない場合は、構造検出で XPath を調整してください。ドキュメント内で他に見出しが使用されていなければ、目次を作成する最も簡単な方法は、構造検出で "//h:h2" を設定することです。
挿入される見出しには書式がありません。書式を適用するには、変換設定の外観の下にある 追加 CSS オプションを使用します。たとえば見出しタグを中央に配置するには、次のようにします:
h2, h3 { text-align: center }
- <h1> や <h2> タグ順を再割り当て
一部の出版社は、複数の <h1> または <h2> タグを順番に使用して章の見出しの書式を設定します。 calibre のデフォルトの変換設定では、このようなタイトルは 2 つに分割されます。このオプションは、分割を防ぐために見出しタグに番号を付け直します。
- 段落間の空行を削除
このオプションを設定すると、calibreはドキュメントに含まれる空白行を分析します。すべての段落に空白行がとじ込みされている場合、calibre はその空白の段落をすべて削除します。連続した複数行の空白はシーン区切りと見なされ、ひとつの段落としてそのまま保持されます。このオプションは 外観 の下の 段落間の空白を削除 オプションとは HTML コンテンツ自体を変更する点が異なります。段落間の空白を削除 オプションはドキュメントスタイルを変更します。このオプションでは、calibreの 空行を挿入 オプションを使って挿入された段落を削除することもできます。
- シーン区切りの書式を変更しない
このオプションを使用すると、calibre は一般的なシーン区切りマーカーを探して中央に配置します。 「ソフト」シーン区切りマーカー、つまり余分な空白によってのみ定義されるシーン区切りが、改ページと同時に表示されることのないようにスタイルを設定します。
- シーン区切りを置換
このオプションが設定されていると、calibreは検出したシーン区切りマーカーをユーザが指定した置換テキストに置き換えます。ただし一部の装飾用文字は、読み取りデバイスによっては表示できないこともあります。
全般的に HTML タグの使用は避けてください。calibre はタグをすべて破棄し、事前に定義したマークアップを使用します。 <hr /> タグ、つまり水平線、および <img> タグは例外です。オプションで水平線のスタイルを指定できます。自分でスタイルを追加する場合には、必ず '幅' 設定を含めてください。そうしないと、スタイル情報が破棄されます。画像タグは使用可能ですが、calibre は変換中に画像を追加する機能を提供していません。これは、'本の編集' 機能を使用して事後に行う必要があります。
- 画像タグの例 (変換後に EPUB 内部の 'Images' フォルダに画像を配置)
<img style="width:10%" src="../Images/scenebreak.png" />
- 書式つき水平線の例:
<hr style="width:20%;padding-top: 1px;border-top: 2px ridge black;border-bottom: 2px groove black;"/>
- 不要なハイフンを削除
このオプションを有効にすると、calibre はドキュメント内のハイフンでつながれたすべてのコンテンツを分析します。ドキュメントそのものが、分析用の辞書として使われます。これのオプションを使用すれば、calibre は文書内の言語が何であれ、造語であろうとあいまいな科学用語であろうと正しくハイフンを削除できます。主な欠点は、ドキュメントに 1 回しか表示されない単語は変更できないことです。分析は 2 つの工程で行われ、最初の工程では行末を分析します。その単語がドキュメント内にハイフンの有無にかかわらず存在する場合にのみ、行の折り返しが解除されます。 2 番目の工程では、ドキュメント全体でハイフンが付けられたすべての単語が分析されます。単語がマッチすることなくドキュメント内の他の場所に存在する場合、ハイフンは削除されます。
- 常用句やパターンをイタリック体にする
有効にすると、calibre は一般的にイタリックとする単語やパターンを探し、それらをイタリック体にします。例としては、~word~ のようによく使われているテキスト慣習や、'etc.' や 'et cetera' などのラテン語の語句のように一般的にイタリック体にされるものが挙げられます。
- 要素のインデントを CSS のインデントに置換
一部のドキュメントでは、ノンブレークスペースを使用してテキストインデントを定義する手法をとっています。このオプションを有効にすると、calibre はこのような書式を探し出し、CSS を用いて 3% のテキストインデントに変換しようとします。
検索と置換¶
これらのオプションは、主に PDF ドキュメントの変換や OCR 変換に役立つものですが、多くのドキュメント固有の問題を修正するためにも使用できます。例として、一部の変換では、テキストにページのヘッダとフッタが残る場合があります。これらのオプションは、正規表現を使用して、ヘッダ、フッタ、またはその他の任意のテキストを探し、削除したり置換したりします。ただしこれが操作する対象は、変換パイプラインによって生成された中間 XHTML です。ウィザードを使うと、ドキュメントの正規表現のカスタマイズを手助けしてくれます。式ボックスの横にある魔法の杖をクリックし、検索式を作成した後、'テスト' ボタンをクリックしてください。マッチに成功したものは黄色で強調表示されます。
検索は、Python 正規表現を使用して機能します。マッチしたテキストはすべて、ドキュメントから削除されるか、置換パターンを使用して置換されます。置換パターンはオプションです。空白にしておくと、検索パターンにマッチするテキストがドキュメントから削除されます。正規表現とその構文について詳しくは calibre で正規表現を利用するにあたって重要なこと を参照してください。
構造検出¶
構造検出は、入力ドキュメント内の構造要素が適切に指定されていない場合に、calibre がそれ検出するのに最善を尽くすことに関わります。たとえば、章、ページ分割、ヘッダ、フッタなどです。容易に想像できることですが、この処理は本ごとに大きく異なります。幸い、calibre にはこれを制御するための非常に強力なオプションがあります。強力さには複雑さが伴うものですが、時間をかけて複雑さを学んでみれば、努力するだけの価値が十分にあるとわかるでしょう。
章と改ページ¶
calibreには、 章の検出 と 改ページの挿入 という 2 つのオプションセットがあります。デフォルトでは、calibre は検出された章の前に改ページを挿入した上に、改ページオプションによって検出された場所にも挿入するため、少々混乱する場合があります。こうする理由は、しばしば章の境界ではない場所に改ページを挿入する必要があるためです。検出された章は、オプションで自動生成された目次に挿入することもできます。
calibreは XPath を使用しています。これはユーザーが章の境界/改ページを指定できるようにする、強力な言語です。最初のうち XPath は使い方が難しく感じるかもしれませんが、ありがたいことにユーザーマニュアルの中には XPath チュートリアル があります。構造検出が処理するのは、変換パイプラインによって生成された中間 XHTML です。書籍に適した設定を探すには はじめに に説明されているデバッグオプションを使用してください。簡単な XPath 式の生成を支援するために、XPath ウィザードのボタンも用意されています。
デフォルトでは、calibre は章を探すのに次の式を使用します:
//*[((name()='h1' or name()='h2') and re:test(., 'chapter|book|section|part\s+', 'i')) or @class = 'chapter']
この式はかなり複雑です。数多くの一般的なケースを同時に処理しようとしているためです。どういう意味かと言うと、calibreは、章が <h1> または <h2> タグのいずれかで始まり、その中に単語 (chapter, book, section または part) のうちいずれかが含まれている、または class="chapter" 属性がつけられているものと想定しています。
関連するオプションに 章のマーク があります。これを使用すると、章を見つけたときの calibre の動作を制御できます。デフォルトでは、章の前に改ページが挿入されます。改ページの代わりに、または改ページに加えて、罫線を挿入することができます。何もしないようにすることもできます
改ページを探すためのデフォルトの設定は次のようになっています:
//*[name()='h1' or name()='h2']
これは、デフォルトで、calibreがすべての <h1> および <h2> タグの前に改ページを挿入することを意味します。
注釈
変換する入力形式によっては、デフォルトの式が変わることがあります。
その他¶
このセクションにはさらにいくつかのオプションがあります。
- 本の最初のページに書誌を挿入
calibreの優れた点のひとつに、書籍に関するまさに完璧な書誌を管理できることが挙げられます。評価、タグ、コメントなど、すべてを管理できます。このオプションは、こうした書誌を含むひとつのページを作成し、変換した電子書籍に挿入します。通常は表紙の直後に挿入します。自分でカスタマイズした表紙を作成する方法のひとつと考えてください。
- 最初の画像を削除
時として変換するソースドキュメントには、表紙として分離されたものではなく、表紙が本の一部に含まれていることがあります。calibre でも表紙を指定した場合、変換された本は 2 つの表紙を持つことになります。このオプションは、単にソースドキュメントから最初の画像を削除します。その結果、変換された本の表紙は calibre によって指定されたものだけになります。
目次¶
入力ドキュメントの書誌に目次があれば、calibre はそれを使用します。しかし古い形式の多くは書誌ベースの目次をサポートしていなかったり、個々のドキュメントが書誌を持たなかったりします。こうした場合にこのセクションのオプションを使えば、入力ドキュメントの実際のコンテンツに基づいて、変換された電子書籍の中に自動的に目次を生成してくれます。
注釈
このオプションの使い方を正確に理解するのには、少々手こずるかもしれません。目次を手作業で作成/編集したい場合は、EPUB または AZW3 形式に変換し、変換ダイアログの目次セクションの下部にある 変換完了後に目次を手動で調整 にチェックします。こうすると、変換後に目次編集ツールが起動するようになります。このツールを使えば、本の中の目次に入れたい場所をクリックするだけで目次に項目を作成できます。変換せずに目次エディタを単独で使用することもできます。環境変数 → インタフェース → ツールバー へ行き、目次エディタ をメインツールバーに追加してください。それから編集する本を選択して、目次エディタ ボタンをクリックします。
最初のオプションは 自動生成された目次を強制的に使用 です。このオプションをチェックすると、入力ドキュメントの書誌にある目次を自動生成された目次で上書きできます。
自動生成される目次はデフォルトでは、calibreはまず、見つかった章を生成される目次に追加しようとします。章の検出をカスタマイズする方法については、上の 構造検出 の章で詳しく説明しています。見つかった章を生成される目次に含めたくない場合は、見つかった章を目次に追加しない オプションをチェックしてください。
見つけた章の数が 章のしきい値 より少ない場合、calibreは入力ドキュメントで見つかったハイパーリンクを目次に追加します。たいていの場合はこれでうまくいきます。入力ドキュメントには、先頭にハイパーリンクつきの目次が含まれていることが多いからです。リンク数 オプションを使うと、この動作を制御できます。ゼロを設定すれば、リンクは追加されません。ゼロより大きい数を設定した場合には、最大でその数までのリンクが追加されます。
calibre は、生成された目次から重複を自動的に取り除きます。もしそれ以外にも望ましくない項目があれば、目次を除去 オプションを使って取り除くことができます。ここに指定するのは、生成される目次のタイトルとマッチさせる正規表現です。マッチするものが見つかれば、削除します。たとえば "Next" または "Previous" というタイトルをすべて削除するには、次のようにします:
Next|Previous
レベル 1,2,3 目次 オプションを使用すると、洗練されたマルチレベルの目次を作成できます。ここに XPath 式を指定して、変換パイプラインによって生成された中間 XHTML のタグとマッチさせます。この XHTML にアクセスする方法については、はじめに を参照してください。XPath 式の作成方法については、XPath のチュートリアル もお読みください。各オプションの横には、基本的な XPath 式の作成を支援するウィザードを起動するためのボタンがついています。これらのオプションの使用方法を、次の簡単な例で示します。
次のような XHTML を生成する入力ドキュメントがあるとします:
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<title>Sample document</title>
</head>
<body>
<h1>Chapter 1</h1>
...
<h2>Section 1.1</h2>
...
<h2>Section 1.2</h2>
...
<h1>Chapter 2</h1>
...
<h2>Section 2.1</h2>
...
</body>
</html>
次に、オプションを次のように設定します:
Level 1 TOC : //h:h1
Level 2 TOC : //h:h2
これにより、次のような 2 レベルの目次が自動的に生成されます。
Chapter 1
Section 1.1
Section 1.2
Chapter 2
Section 2.1
警告
すべての出力形式がマルチレベルの目次をサポートしているわけではありません。最初に EPUB 出力を試してみてください。それがうまくいったら、実際に使いたい形式を試してください。
HTML入力ドキュメントを変換するときに章のタイトルとして画像を使用¶
章タイトルとして画像を使用したいが、それでも calibre に章タイトルから目次を自動的に生成させたいとします。これを実現するには、次の HTML マークアップを使用します:
<html>
<body>
<h2>Chapter 1</h2>
<p>chapter 1 text...</p>
<h2 title="Chapter 2"><img src="chapter2.jpg" /></h2>
<p>chapter 2 text...</p>
</body>
</html>
レベル 1 目次 に //h:h2 を設定します。そうすると第 2 章ではタグにテキストがないため、calibre は <h2> タグの title 属性の値からタイトルを取得します。
目次項目のテキストとしてタグの属性を使用¶
著しく長い章のタイトルがあり、目次用にはそれを短くしたものを使用したい場合は、title 属性を使用すれば実現できます。たとえば次のようにします:
<html>
<body>
<h2 title="Chapter 1">Chapter 1: Some very long title</h2>
<p>chapter 1 text...</p>
<h2 title="Chapter 2">Chapter 2: Some other very long title</h2>
<p>chapter 2 text...</p>
</body>
</html>
レベル 1 目次 に //h:h2/@title を設定します。そうするとタグ内のテキストを使用する代わりに、calibre は <h2> タグの title 属性の値からタイトルを取得します。 XPath 式の末尾の /@title に注目してください。この形式を使えば、任意の属性からテキストを取得するように calibre に指示できます。
変換のためにオプションを設定/保存する方法¶
calibre で変換オプションを設定できる場所は2つあります。 1 つ目は、環境設定->変換 にあります。これらの設定は、変換オプションのデフォルトです。新しい本を変換しようとするとき、ここで設定したものがデフォルトとして使用されます。
本の変換ごとに、変換ダイアログで設定を変更することもできます。本を変換するとき、calibre はその本に使用した設定を記憶します。次にまた変換するときには、環境設定 で設定されたデフォルトよりも、それぞれの本に保存された設定を優先します。本の変換ダイアログの デフォルトに戻す ボタンを使用すれば、個別の設定をデフォルトに戻すことができます。本のグループに保存されている設定を削除するには、すべての本を選択して 書誌を編集 ボタンをクリックし、書誌の一括編集ダイアログを表示します。ダイアログの下部に、保存されている変換を削除するオプションがあります。
本のセットを一括変換する場合、設定は次の順に取得します (最後のものが優先されます)。
環境設定->変換で設定したデフォルトから
変換されるそれぞれの本の保存された変換設定から (もしあれば)。これは、一括変換ダイアログの左上隅にあるオプションで無効にできます。
一括変換ダイアログで設定した内容から
一括変換するそれぞれの本の最終設定は保存され、再びその本が変換されたときには再利用されます。一括変換では、一括変換ダイアログの設定が最も優先されるため、個別の本の設定を上書きします。したがって、一括変換する本は同じような設定が必要な本に限る必要があります。例外は書誌と、入力形式に固有の設定です。一括変換ダイアログにはこれら 2 つのカテゴリの設定がないため、個別の本の設定 (もしあれば) またはデフォルトから取得されます。
注釈
右下端にある回転アイコンをクリックしてから、個々の変換ジョブをダブルクリックすると、変換中に使用された実際の設定を確認できます。これは使用された実際の設定を含む変換ログを上部に表示します。
形式固有のヒント¶
ここでは特定の形式の変換に固有な情報を記載します。特定の形式に特有なオプションや、TXT 入力 や EPUB 出力 のような入力と出力がそれぞれの変換ダイアログのもとで利用可能かどうか、といったことです。
Microsoft Word ドキュメントの変換¶
calibre は、Microsoft Word 2007 以降で作成された .docx ファイルを自動的に変換できます。ファイルを calibre に追加し、変換をクリックするだけです。
注釈
calibre 変換エンジンの機能を示す デモ用 .docx ファイル があります。ダウンロードして EPUB または AZW3 に変換するだけで、calibre で何ができるかを確認できます。
Microsoft Wordで Heading 1, Heading 2 などのスタイルで見出しをマークすると、calibre は見出しをもとにして目次を自動的に生成します。出力された電子書籍を calibre の電子書籍ビューアで開き、目次 ボタンをクリックして、生成された目次を表示してください。
古い .doc ファイル¶
古い .doc ファイルの場合には、Microsoft Word を使用してドキュメントを HTML として保存し、その HTML ファイルを calibre を使って変換できます。 HTML として保存するときは、必ず "Webページ (フィルター後)" を選択してください。こうすると、適切に変換できるクリーンな HTML が生成されます。ただし Wordは非常に厄介なHTMLを生成するため、変換には長い時間がかかる可能性があります。気長に待ちましょう。新しいバージョンの Word を利用できる場合は、それを .docx として直接保存することもできます。
もうひとつの方法は、無料の LibreOffice を使用することです。 LibreOfficeで.docファイルを開き、.docxとして保存します。これは、calibreで直接変換できます。
テキストドキュメントの変換¶
テキストドキュメントには、太字、斜体などの書式設定や、段落、見出し、セクションなどのドキュメント構造を指定する明確な方法はありませんが、一般的に使用されるさまざまな慣習があります。デフォルトでは calibreは、これらの慣習をもとにして、正しい書式とマークアップの自動検出を試みます。
テキスト入力は、段落の検出方法を差別化するためのいくつかのオプションをサポートしています。
- 段落スタイル: 自動
テキストファイルを分析し、段落がどのように定義されているかを自動的に判断しようとします。このオプションはたいていうまくいきますが、望ましい結果が得られない場合は手動オプションを試してください。
- 段落スタイル: ブロック
ひとつ以上の空白行が段落境界であると想定します:
This is the first. This is the second paragraph.- 段落スタイル: 一行
すべての行を段落とみなします:
This is the first. This is the second. This is the third.- 段落スタイル: 印刷
すべての段落がインデント (タブまたは2 つ以上のスペース) で始まると想定します。その次にインデントで始まる行に到達すると、段落は終了します。
This is the first. This is the second. This is the third.- 段落スタイル: 書式なし
ドキュメントには書式設定がないものとみなしますが、ハード改行は使用します。段落の再現を試みるために、句読点と行の平均長を使用します
- 書式スタイル: 自動
使用されている書式マークアップのタイプを検出しようとします。マークアップが使用されていない場合は、ヒューリスティックな書式が適用されます。
- 書式スタイル: ヒューリスティック
一般的な章の見出し、シーン区切り、イタリック体の単語がないかドキュメントを解析し、変換中に適切な HTML マークアップを適用します。
- 書式スタイル: Markdown
calibre は、Markdownと呼ばれる変換プリプロセッサを介した TXT 入力の実行もサポートしています。Markdown を使用すると、太字、斜体、セクション見出し、表、リスト、目次などの基本的な書式を TXTドキュメントに追加できます。章の見出しには先頭に#を付けて、章のXPath検出式を "//h:h1" に設定するのが、TXTドキュメントから適切な目次を生成するための最も簡単な方法です。Markdown 構文の詳細については、 daringfireball を参照してください。
- 書式スタイル: なし
テキストに特別な書式を適用せず、ドキュメントが HTML に変換される以外の変更は加えられません。
PDF ドキュメントの変換¶
PDFドキュメントは、変換元としては最悪の形式のひとつです。ページサイズは固定で、テキスト配置形式です。つまり、ある段落がどこで終わり、別の段落がどこから始まるかを判断するのが非常に困難なのです。 calibre は、設定変更可能な 行折り返し解除係数 を使って段落の行折り返し解除を試みます。この係数は、どの長さで行の折り返しを解除をするか判断するために使用する尺度です。有効な値は 0 から 1 までの小数です。デフォルトは 0.45 で、行の平均長より少し小さい値です。この値を下げると、折り返し解除した行により多くのテキストが含まれます。増やすとテキストが少なくなります。この値は、PDF 入力 の下の変換設定で調整できます。
また多くの場合、ドキュメントの一部であるヘッダとフッタがテキストに含まれるような形になっています。 検索と置換 パネルを使用してヘッダとフッタを削除し、この問題を緩和してください。ヘッダとフッタがテキストから削除されていないと、段落の行折り返し解除を放棄する可能性があります。ヘッダとフッタの削除オプションの使い方については calibre で正規表現を利用するにあたって重要なこと を参照してください。
PDF 入力での制約の一部を挙げると:
複雑なドキュメント、マルチカラムなドキュメント、画像ベースのドキュメントをサポートしていません。
ドキュメントからのベクタ画像の抽出と、表の抽出もサポートしていません。
一部のPDFは、ll、ff、fiなどを表すのに特別なグリフを使用してます。PDF内部での表現方法次第で、これらのテキストの変換が機能する場合と機能しない場合があります。
リンクと目次をサポートしていません。
埋め込みの非 Unicode フォントを使って英語以外の文字を表現している PDF は、それらの文字の出力が文字化けします。
一部の PDF は、ページを写真に写したものに OCR で読み取ったテキストを裏につけたものでできています。このような場合に calibre は OCR で読み取ったテキストを使用しますが、そうすると PDF ファイルを表示したときの見た目とは大きく異なってしまう可能性があります。
右から左へ流れる言語や数式のような、複雑なテキストを表示する PDF は正しく変換されません。
何度も繰り返しますが、入力として PDF は本当に、本当にダメな 形式です。何が何でも PDF を使わざるを得ない場合、入力 PDF によっては、まともなものから使い物にならないものまで出力の幅が大きいことを覚悟してください。
コミック本のコレクション¶
コミック本コレクションとは .cbc ファイルのことです。 .cbc ファイルは、他の CBZ/CBR ファイルを含む ZIP ファイルです。さらに .cbc ファイルには、UTF-8 でエンコードされた comics.txt という簡単ななテキストファイルが含まれている必要があります。comics.txt ファイルには、次のように .cbc ファイル内のコミックスファイルのリストが filename:title の形式で含まれていなくてはなりません:
one.cbz:Chapter One
two.cbz:Chapter Two
three.cbz:Chapter Three
そして .cbc ファイルには次のものが含まれます:
comics.txt
one.cbz
two.cbz
three.cbz
calibreは、この .cbc ファイルを comics.txt の各項目を指す目次付きの電子書籍に自動的に変換します。
EPUB の優れた書式のデモ¶
この デモファイル では、EPUBファイルのさまざまな優れた書式を紹介しています。このファイルは calibre を使用して手書きの HTML から作成しました。自分で EPUB を作成するときのテンプレートとして使えるよう作られています。
これを作成した元となる HTMLは demo.zip です。この ZIP ファイルから EPUB を作成するにあたって使用した設定は次のとおりです:
ebook-convert demo.zip .epub -vv --authors "Kovid Goyal" --language en --level1-toc '//*[@class="title"]' --disable-font-rescaling --page-breaks-before / --no-default-epub-cover
ただしこのファイルでは EPUB の可能性を追求しているため、優れた書式のうちかなりの部分は、calibre のビルトイン EPUBビューアに比べて能力の劣るリーダーでは機能しません。
ODT ドキュメントの変換¶
calibreは、ODT (OpenDocument Text) ファイルを直接変換できます。ドキュメントの書式にはスタイルを使用し、書式を直接使用するのは最小限に抑えるとよいでしょう。ドキュメントに画像を挿入する場合、画像は段落に固定する必要があります。ページに固定した画像はすべて、変換したものの先頭に置かれてしまいます。
章の自動検出を有効にするには、ビルトインスタイルで Heading 1, Heading 2, ..., Heading 6 (Heading 1 は HTML タグ <h1>, Heading 2 は <h2> という具合に相当します) でマークする必要があります。calibre で変換するときには、使用したスタイルを 章を検出 ボックスに入力できます。例:
章をスタイル Heading 2 でマークする場合、'章を検出' ボックスは
//h:h2セクションが Heading 2 でマーク、章を Heading 3 でマークしている階層化された目次には、
//h:h2|//h:h3と入力する必要があります。変換の目次ページでは レベル 1 目次 ボックスに//h:h2を、そして レベル 2 目次 ボックスには//h:h3を入力します。
よく知られているドキュメントのプロパティ (タイトル、キーワード、説明、著者) が認識され、calibre は最初の画像 (小さすぎず、縦横比が良好) を表紙画像として使用します。
優れたプロパティ変換モードもあり、このモードを有効にするには ODT ドキュメントでカスタムプロパティ opf.metadata (Yes/No タイプ) を Yesに設定します (ファイル->プロパティ->カスタムプロパティ)。calibre がこのプロパティを検出すると、次のカスタムプロパティが認識されます (opf.authors はドキュメント作成者を上書きします):
opf.titlesort
opf.authors
opf.authorsort
opf.publisher
opf.pubdate
opf.isbn
opf.language
opf.series
opf.seriesindex
これに加え、表紙として使用する画像を指定することも可能です。それには ODTで表紙画像に opf.cover と名前を付けます (右クリックして画像->オプション->名前)。この名前の画像が見つからない場合は、スマート方式が使用されます。表紙の検出のせいで特定の出力形式では表紙が二重になってしまう可能性があるため、この処理はその段落をドキュメントから削除します (ただし中身が表紙しかない場合に)。これが機能するのは名前付きの画像に限られます。
表紙検出を無効にするには、上級者モードでカスタムプロパティ opf.nocover (Yes/No タイプ) に Yes を設定します。
PDF への変換¶
PDF に変換するときに決めなくてはならない最初の、最も重要な設定は、ページサイズです。デフォルトでは calibreは "U.S. Letter" のページサイズを使用します。変換ダイアログの PDF 出力 のセクションで、これを別の標準ページサイズにしたり、または完全にカスタムなサイズに変更したりすることが可能です。特定のデバイス用に PDF を生成しようとしている場合には、その代わりに 出力プロファイル に設定したページサイズを使用するオプションを有効にしてもかまいません。つまり出力プロファイルが Kindle に設定されていれば、calibre は小さな Kindle 画面での表示に適したページサイズの PDF を作成します。
印刷可能な目次¶
PDFの最後に、すべてのセクションのページ番号を一覧にした、印刷可能な目次を挿入することもできます。PDFを紙に印刷する場合に、非常に便利です。電子デバイスでPDFを使用する場合は、PDFアウトラインがこの機能を提供し、デフォルトで生成されます。
変換ダイアログの外観セクションにある 追加 CSS 変換設定を使用して、生成される目次の見た目をカスタマイズできます。デフォルトの CSS を次に示すので、これをコピーして必要な変更を加えてください。
.calibre-pdf-toc table { width: 100%% }
.calibre-pdf-toc table tr td:last-of-type { text-align: right }
.calibre-pdf-toc .level-0 {
font-size: larger;
}
.calibre-pdf-toc .level-1 td:first-of-type { padding-left: 1.4em }
.calibre-pdf-toc .level-2 td:first-of-type { padding-left: 2.8em }
HTML ファイルごとのカスタムページ余白¶
複数の HTML ファイルを含む EPUB または AZW3 ファイルを変換していて、特定の HTML ファイルのページ余白を変更したい場合には、calibre の電子書籍エディタを使用して HTML ファイルに次のスタイルブロックを追加できます:
<style>
@page {
margin-left: 10pt;
margin-right: 10pt;
margin-top: 10pt;
margin-bottom: 10pt;
}
</style>
次に、変換ダイアログの PDF 出力セクションで、変換するドキュメントのページマージンを使用 オプションを有効にします。ここうすると、この HTML ファイルから生成されたすべてのページに 10pt の余白ができます。