 Změnit jazyk
Změnit jazykPřevod e-knihy¶
Calibre má systém převodu, který je navržen tak, aby se velmi snadno používal. Obyčejně stačí přidat knihu do Calibre, kliknout na převod a Calibre se pokusí vygenerovat výstup, který je co nejpodobnější vstupu. Calibre však přijímá velké množství vstupních formátů, z nichž ne všechny jsou stejně vhodné jako jiné pro převod na e-knihy. V případě takových vstupních formátů, nebo pokud pouze chcete větší kontrolu nad systémem převodu, Calibre má mnoho voleb pro jemné ladění procesu převodu. Pamatujte však, že systému převodu Calibre není náhradou za plnohodnotný editor e-knih. Pro úpravu e-knih je doporučuji nejdříve pomocí Calibre převést do formátu EPUB nebo AZW3, a pak použít funkci Upravit knihu, abyste je dostali do dokonalé podoby. Pak můžete použít upravenou e-knihu jako vstup pro převod do jiných formátů v Calibre.
Tento dokument bude odkazovat hlavně na nastavení převodu, které naleznete v dialogovém okně převodu, jak je zobrazeno níže. Všechna tato nastavení jsou také dostupná prostřednictvím rozhraní příkazového řádku pro převod zdokumentovaného v ebook-convert. V Calibre můžete získat nápovědu k jakémukoliv individuálnímu nastavení podržením myši nad ním, objeví se popisek tlačítka popisující nastavení.
Úvod¶
První věc, kterou musíte pochopit o systému převodu, je to, že je navržen jako řetězec. Schematicky to vypadá takto:
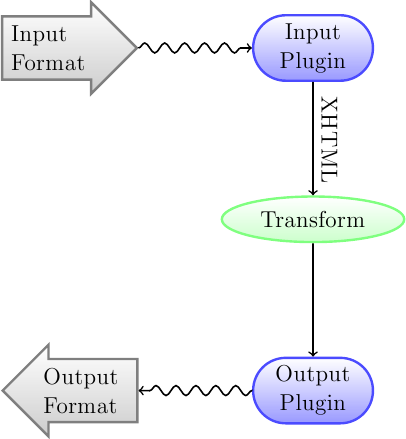
Vstupní formát se nejdříve převede na XHTML vhodným vstupním modulem. Toto HTML se pak transformuje. V posledním kroku se zpracované XHTML převede na zadaný výstupní formát vhodným výstupním modulem. Výsledky převodu se mohou značně lišit v závislosti na vstupním formátu. Některé formáty se převádějí mnohem lépe než ostatní. Seznam nejlepších zdrojových formátů pro převod je dostupný zde.
Transformace, které se provádějí na výstupu XHTML, je místo, kde se odehrává veškerá práce. Existují různé transformace, například pro vložení metadat knihy jako stránky na začátek knihy, pro rozpoznání nadpisů kapitol a automatického vytvoření obsahu, pro proporcionální změnu velikosti písma a tak dále. Je důležité si zapamatovat, že všechny transformace se provádějí na výstupním XHTML pomocí vstupního modulu, ne na samotném vstupním souboru. Takže například když požádáte Calibre, aby převedlo soubor RTF na EPUB, tak bude nejdříve vnitřně převeden na XHTML, na toto XHTML budou použity různé transformace, a pak výstupní modul vytvoří soubor EPUB, automaticky vygeneruje všechna metadata, obsah a tak dále.
Tento proces můžete vidět v akci použitím volby ladění  . Stačí zadat cestu ke složce pro výstup ladění. Během převodu Calibre umístí XHTML generované různými fázemi převodního řetězce do různých podsložek. Čtyři podsložky jsou:
. Stačí zadat cestu ke složce pro výstup ladění. Během převodu Calibre umístí XHTML generované různými fázemi převodního řetězce do různých podsložek. Čtyři podsložky jsou:
Složka |
Popis |
|---|---|
vstup |
Obsahuje výstup HTML ze vstupního modulu. Použijte pro ladění vstupního modulu. |
analyzováno |
Výsledek předzpracování a převodu na XHTML výstupu ze vstupního modulu. Použijte pro ladění rozpoznávání struktury. |
struktura |
Po rozpoznání struktury, ale před vyhlazením CSS a převodem velikosti písma. Použijte pro ladění převodu velikosti písma a transformace CSS. |
zpracováno |
Těsně před tím, než je e-kniha předána výstupnímu modulu. Použijte pro ladění výstupního modulu. |
Pokud chcete trochu upravit vstupní dokument před tím, než ho necháte Calibre převést, to nejlepší, co můžete udělat, je upravit soubory v podsložce vstup, pak je zazipovat a použít soubor ZIP jako vstupní formát pro následující převody. Abyste to udělali, použijte dialogové okno Upravit metadata pro přidání souboru ZIP jako formátu pro knihu, a pak v levém horním rohu dialogového okna převodu vyberte ZIP jako vstupní formát.
Tento dokument se bude zabývat hlavně různými transformacemi, které pracují na polotovaru XHTML, a jak je ovládat. Na konci je několik konkrétních tipů pro každý vstupní nebo výstupní formát.
Vzhled a chování¶
Tato skupina voleb určuje různé aspekty vzhledu a chování převedené e-knihy.
Písma¶
Jednou z nejpříjemnějších vlastností čtení e-knih je možnost snadno upravit velikost písma podle individuálních potřeb a světelných podmínek. calibre má propracované algoritmy, které zajišťují, že všechny knihy, které vytvoří, mají konzistentní velikosti písma bez ohledu na to, jaké velikosti písma jsou uvedeny ve vstupním dokumentu.
Základní velikost písma dokumentu je nejběžnější velikost písma v tomto dokumentu, t. j. velikost větší části textu v tomto dokumentu. Když zadáte Základní velikost písma, Calibre automaticky přiměřeně změní měřítko všech velikostí písma v dokumentu, takže nejběžnější velikost písma se stane zadanou základní velikostí písma a ostatním velikostem písma bude přiměřeně upraveno měřítko. Výběrem větší základní velikosti písma můžete písma v dokumentu zvětšit a naopak. Když nastavíte základní velikost písma, měli byste pro dosažení nejlepších výsledků také nastavit klíč velikosti písma.
Obyčejně Calibre automaticky zvolí základní velikost písma vhodnou pro výstupní profil, který jste zvolili (viz Nastavení stránky). Toto však zde můžete přepsat, pokud pro vás výchozí nastavení není vhodné.
Volba Klíč velikosti písma vám umožňuje určit, jak se mění nezákladní velikosti písma. Algoritmus změny velikosti písma funguje pomocí klíče velikosti písma, což je jednoduše čárkami oddělený seznam velikostí písma. Klíč velikost písma říká Calibre, o kolik „kroků“ větší nebo menší by měla daná velikost písma být v porovnání s základní velikostí písma. Předpokládá se, že by v dokumentu měl být omezený počet velikostí písma. Například jedna velikost pro základní text, několik velikostí pro různé úrovně nadpisů a několik velikostí pro horní nebo dolní indexy a poznámky pod čarou. Klíč velikosti písma umožňuje Calibre rozčlenit velikosti písma ve vstupních dokumentech do samostatných „košů“ odpovídajících různým logickým velikostem písem.
Vysvětleme si to na příkladu. Předpokládejme, že zdrojový dokument, který převádíme, byl vytvořen někým s vynikajícím zrakem a má základní velikost písma 8pt. To znamená, že větší část textu v dokumentu má velikost 8pt, zatímco nadpisy jsou o něco větší (řekněme 10 a 12pt) a poznámky pod čarou o něco menší 6pt. Takže pokud použijeme následující nastavení:
Base font size : 12pt
Font size key : 7, 8, 10, 12, 14, 16, 18, 20
výstupní dokument bude mít základní velikost písma 12pt, nadpisy 14 a 16pt a poznámky pod čarou 8pt. Nyní předpokládejme, že chceme, aby největší velikost nadpisu více vyčnívala a také aby poznámky pod čarou byly trochu větší. Abychom toho dosáhli, klíč písma by měl být změněn na:
New font size key : 7, 9, 12, 14, 18, 20, 22
Největší nadpisy budou mít nyní 18pt, zatímco poznámky pod čarou budou mít 9pt. Můžete si hrát s tímto nastavením, abyste se pokusili zjistit, co by pro vás bylo nejlepší pomocí průvodce změny měřítka písma, který můžete otevřít kliknutím na malé tlačítko vedle nastavení Klíč velikosti písma.
Může tu být také zakázána veškerá změna velikosti písma v převodu, pokud chcete zachovat velikost písma ve vstupním dokumentu.
Související nastavení je Výška řádku. Výška řádku určuje svislou výšku řádků. Ve výchozím nastavení (výška řádku 0) se neprovádí žádná manipulace s výškami řádků. Pokud zadáte nevýchozí hodnotu, budou výšky řádků nastaveny na všech místech, které nemají určenu vlastní výšky řádků. Toto je však taková tupá zbraň a mělo by to být používáno šetrně. Pokud chcete upravit výšky řádků pro nějaký oddíl vstupu, je lepší použít Dodatečné CSS.
V tomto oddíle můžete také říct Calibre, aby do knihy vložilo jakákoliv odkazovaná písma. To umožní, aby písma na čtecích zařízeních fungovala, i když nejsou v zařízení dostupná.
Text¶
Text může být buď zarovnaný, nebo ne. Zarovnaný text má dodatečné mezery mezi slovy, aby měl hladký pravý okraj. Někteří lidé upřednostňují zarovnaný text, jiní ne. Calibre obyčejně zachová zarovnání v původním dokumentu. Pokud ho chcete přepsat, můžete v tomto oddíle použít volbu Zarovnání textu.
Můžete také říct Calibre, aby Vylepšilo interpunkci, což nahradí prosté uvozovky, pomlčky a výpustky jejich typograficky správnými alternativami. Pamatujte, že tento algoritmus není dokonalý, takže stojí za to přezkoumat výsledky. Naopak je také dostupná Nevylepšená interpunkce.
Nakonec je zde Vstupní kódování znaků. Starší dokumenty někdy nezadávají své kódování znaků. Při převodu to může vést k neanglické znakům nebo speciálním znakům, jako je poškození chytrých uvozovek. Calibre zkouší automaticky rozpoznat kódování znaků zdrojového dokumentu, ale není vždy úspěšné. Pomocí tohoto nastavení můžete vynutit předpokládání konkrétního kódování znaků. cp1252 je běžné kódování pro dokumenty vytvořené pomocí softwaru Windows. Měli byste si také přečíst Jak převedu můj soubor obsahující neanglické znaky nebo chytré uvozovky? pro více informací o problematice kódování.
Rozložení¶
Obyčejně jsou odstavce v XHTML vykresleny s prázdným řádkem mezi nimi a bez úvodního odsazení textu. Calibre má pár voleb, jak toto určit. Odebrat mezery mezi odstavci vynutí zajištění, aby všechny odstavce neměly žádné vnitřní mezery mezi odstavci. Nastaví také odsazení textu na 1,5em (může být změněno) pro označení začátku každého odstavce. Vložit prázdný řádek dělá opak, což zaručuje, že je právě jeden prázdný řádek mezi každou dvojicí odstavců. Obě tyto volby jsou velice ucelené, odebírají mezery nebo je vkládají pro všechny odstavce (technicky vzato značky <p> a <div>). Je to proto, abyste mohli jen nastavit volbu a být si jistí, že se to provede tak, jak bylo ohlášeno bez ohledu na to, jak je neuspořádaný vstupní soubor. Jedinou výjimkou je případ, kdy vstupní soubor používá pevné konce řádků pro doplnění mezer mezi odstavce.
Pokud chcete odebrat mezery mezi všemi odstavci kromě pár vybraných, nepoužívejte tyto volby. Místo toho přidejte následující kód CSS do Dodatečné CSS:
p, div { margin: 0pt; border: 0pt; text-indent: 1.5em }
.spacious { margin-bottom: 1em; text-indent: 0pt; }
Pak ve zdrojovém dokumentu označte odstavce, které potřebují mezery class=“spacious“. Pokud váš vstupní dokument není v HTML, použijte volbu ladění popsanou v Úvodu, abyste získali HTML (použijte podsložku input).
Další užitečnou volbou je Linearizovat tabulky. Některé špatně navržené dokumenty používají tabulky k řízení rozvržení textu na stránce. Po převodu se v takových dokumentech často objevuje text přesahující mimo stránku a další artefakty. Tato volba extrahuje obsah z tabulek a předloží ho lineárně. Mějte na paměti, že tato volba linearizuje všechny tabulky, proto ji používejte jen tehdy, pokud jste si jistí, že vstupní dokument nepoužívá tabulky k legitimním účelům, například k prezentaci tabulkových informací.
Stylování¶
Volba Dodatečné CSS vám umožňuje zadat libovolné CSS, které bude použito na všechny soubory HTML na vstupu. Toto CSS je použito s velice vysokou prioritou, a proto by mělo přepsat většinu CSS přítomného v samotném vstupním dokumentu. Toto nastavení můžete použít pro jemné ladění prezentace nebo rozložení dokumentu. Například pokud chcete, aby všechny odstavce třídy endnote byly zarovnány vpravo, stačí přidat:
.endnote { text-align: right }
nebo pokud chcete změnit odsazení všech odstavců:
p { text-indent: 5mm; }
Dodatečné CSS je velice výkonná volba, ale potřebujete pochopit, jak CSS funguje, pro použití jejího plného potenciálu. Můžete použít volbu ladění řetězce popsanou výše, abyste viděli, jaké CSS je přítomné ve vstupním dokumentu.
Jednodušší volbou je použít Filtrovat informace o stylu. To vám umožňuje odebrat všechny vlastnosti CSS zadaných typů z dokumentu. Můžete to například použít k odebrání všech barev nebo písem.
Převod stylů¶
Toto je nejvýkonnější vybavení související se stylováním. Můžete ho použít k definování pravidel, které mění styly na základě různých podmínek. Můžete ho například použít ke změně všech zelených barev na modré nebo k odebrání všech tučných stylů z textu nebo obarvení všech záhlaví určitou barvou apod.
Převod HTML¶
Podobné převodu stylů, ale umožňuje provádět změny v obsahu knihy ve formátu HTML. Můžete nahradit jednu značku jinou, přidat značkám třídy nebo jiné atributy na základě jejich obsahu atd.
Nastavení stránky¶
Volby Nastavení stránky jsou pro ovládání rozložení obrazovky, jako jsou okraje a velikosti obrazovky. Existují volby pro nastavení okrajů stránky, které budou použity Výstupním modulem, pokud vybraný Výstupní formát podporuje okraje stránky. Kromě toho byste měli vybrat Vstupní profil a Výstupní profil. Obě sady profilů se v podstatě zabývají tím, jak interpretovat rozměry ve vstupních a výstupních dokumentech, velikosti obrazovky a klíče úpravy měřítka výchozího písma.
Pokud víte, že soubor, který převádíte, byl zamýšlen k použití na konkrétním zařízení nebo softwarové platformě, zvolte odpovídající vstupní profil, jinak prostě zvolte výchozí vstupní profil. Pokud víte, že soubory, které vytváříte, jsou určeny pro konkrétní typ zařízení, zvolte odpovídající výstupní profil. Pokud víte, že soubory, které vytváříte, jsou určeny pro konkrétní typ zařízení, zvolte odpovídající výstupní profil. V opačném případě zvolte jeden z obecných výstupních profilů. Pokud převádíte na MOBI nebo AZW3, budete téměř vždy chtít zvolit jeden z výstupních profilů Kindle. V opačném případě je nejlepším řešením pro moderní zařízení pro čtení e-knih zvolit výstupní profil Obecné HD zařízení e-ink.
Výstupní profil také určuje velikost obrazovky. To například způsobí, že v některých výstupních formátech bude u obrázků automaticky změněna velikost, aby se přizpůsobily obrazovce. Takže zvolte profil zařízení, které má podobnou velikost obrazovky vašemu zařízení.
Heuristické zpracování¶
Heuristické zpracování poskytuje celou řadu funkcí, které mohou být použity pro pokus o rozpoznání a opravu běžných problémů ve špatně formátovaných vstupních dokumentech. Použijte tyto funkce, pokud váš vstupní dokument trpí špatným formátování Protože tyto funkce spoléhají na běžné vzory, uvědomte si, že v některých případech může volba vést k horším výsledkům, tak to používejte opatrně. Například několik z těchto voleb odebere všechny entity pevných mezer, nebo mohou zahrnovat falešně pozitivní shody souvisejících s funkcí.
- Povolit heuristické zpracování
Tato volba aktivuje fázi Heuristického zpracování převodního řetězce Calibre. Musí to být povoleno, aby byly použity různé dílčí funkce.
- Zrušit zalomení řádků
Povolení této volby způsobí, že se Calibre pokusí rozpoznat a opravit tvrdé pevné konce řádků existujících v dokumentu pomocí interpunkčních vodítek a délky řádku. Calibre se nejdříve pokusí rozpoznat, zda pevné konce řádků existují, pokud se zdá, že neexistují, Calibre se nepokusí zrušit zalomení řádků. Koeficient zrušení zalomení řádku může být zmenšen, pokud chcete ‚vynutit‘, aby Calibre zrušilo zalomení řádků.
- Koeficient zrušení zalomení řádku
Tato volba určuje algoritmus, který Calibre používá k odebrání pevných konců řádků. Například pokud je hodnota této volby 0,4, znamená to, že Calibre odebere pevné konce řádků z konců řádků, jejichž délky jsou menší než délka 40 % všech řádků v dokumentu. Pokud má váš dokument pouze několik konců řádků, které potřebují opravu, pak by tato hodnota měla být snížena někam mezi 0,1 a 0,2.
- Rozpoznat a označit neformátované nadpisy a podnadpisy kapitol
Pokud váš dokument neobsahuje nadpisy kapitol a názvy formátované odlišně od zbytku textu, Calibre může použít tuto volbu, aby se je pokusilo rozpoznat a obklopit je značkami nadpisů. Značky <h2> se používají pro nadpisy kapitol; značky <h3> se používají pro jakékoliv rozpoznané názvy.
Tato funkce nevytvoří obsah, ale v mnoha případech způsobí, že výchozí nastavení rozpoznání kapitol Calibre správně rozpozná kapitoly a sestaví obsah. Upravte XPath v Rozpoznávání struktury, pokud není obsah automaticky vytvořen. Pokud v dokumentu nejsou použity žádné další nadpisy, pak nastavení „//h:h2“ v Rozpoznávání struktury bude nejsnadnější způsob, jak vytvořit obsah pro dokument.
Tyto vložené nadpisy nejsou naformátovány, pro použití formátování použijte volbu Dodatečné CSS pod Vzhledem a chováním v nastavení převodu. Například pro značky zarovnání nadpisů na střed použijte následující:
h2, h3 { text-align: center }
- Přečíslovat sekvence značek <h1> nebo <h2>
Někteří vydavatelé formátují nadpisy kapitol pomocí více značek <h1> nebo <h2> postupně. Výchozí nastavení převodu Calibre způsobí, že takové nadpisy budou rozděleny na dvě části. Tato volba přečísluje značky nadpisů, aby se zabránilo rozdělení.
- Odstranit prázdné řádky mezi odstavci
Tato volba způsobí, že Calibre analyzuje prázdné řádky obsažené v dokumentu. Pokud je každý odstavec proložený prázdným řádkem, pak Calibre odebere všechny tyto prázdné odstavce. Sekvence více prázdných řádků budou považovány za přerušení příběhu a budou zachovány jako jeden odstavec. Tato volba se liší od volby Odebrat mezery mezi odstavci pod Vzhled a chování v tom, že skutečně mění obsah HTML, zatímco druhá volba mění styly dokumentu. Tato volba může také odebrat odstavce, které byly vloženy pomocí volby Calibre Vložit prázdný řádek.
- Zajistit konzistentní formátování přerušení příběhu
Pomocí této volby se Calibre pokusí rozpoznat běžné značky přerušení příběhu a zajistit, aby byly zarovnané na střed. Značkám ‚měkkého‘ přerušení příběhu, tj. přerušení příběhu definované pouze dodatečnými prázdnými znaky, jsou změněny styly, aby se zajistilo, že nebudou zobrazeny ve spojení s konci stránek.
- Nahradit přerušení příběhu
Pokud je tato volba konfigurována, pak Calibre nahradí značky přerušení příběhu, které najde, nahrazovacím textem zadaným uživatelem. Pamatujte, prosím, že některé ozdobné znaky nemusí být podporovány na všech čtecích zařízení.
Obecně byste se měli vyhnout používání značek HTML, Calibre zahodí jakékoliv značky a použije předem definované značení. Značky <hr />, tj. vodorovné čáry, a značky <img> jsou výjimky. Vodorovné čáry mohou být volitelně zadány styly, pokud se rozhodnete přidat vlastní styl, nezapomeňte zahrnout nastavení šířky ‚width‘, jinak bude informace stylu zahozena. Můžete použít značky obrázků, ale Calibre neposkytuje možnost přidat obrázek během převodu, to musí být provedeno po faktickém použití funkce ‚Upravit knihu‘.
- Příklad značky obrázku (po převodu umístí obrázek do složky ‚Images‘ uvnitř souboru EPUB):
<img style=“width:10%“ src=“../Images/scenebreak.png“ />
- Příklad vodorovné čáry se styly:
<hr style=“width:20%;padding-top: 1px;border-top: 2px ridge black;border-bottom: 2px groove black;“/>
- Odebrat nadbytečné spojovníky
Calibre analyzuje veškerý obsah rozdělený spojovníky v dokumentu, když je tato volba povolena. Samotný dokument je použit jako slovník pro analýzu. To umožňuje Calibre přesně odebrat spojovníky pro jakákoliv slova v dokumentu v jakémkoliv jazyce, společně s vymyšlenými a neznámými vědeckými slovy. Primární nevýhodou je, že slova objevující se v dokumentu pouze jednou nebudou změněna. Analýza probíhá ve dvou průchodech, první průchod analyzuje konce řádků. Řádkům je zrušeno zalomení, pouze pokud v dokumentu slovo existuje s nebo bez spojovníku. Druhý průchod analyzuje všechna slova rozdělená spojovníky v celém dokumentu, spojovníky jsou odebrány, pokud slovo existuje někde jinde v dokumentu bez shody.
- Převést na kurzívu obecná slova a vzory
Pokud je povoleno, bude Calibre hledat obecná slova a vzory, které označují kurzívu a převede je na kurzívu. Příkladem jsou obecné textové zásady, jako je ~slovo~, nebo fráze, které by obecně měly být kurzívou, např. latinské fráze, jako jsou ‚etc.‘ nebo ‚et cetera‘.
- Nahradit odsazení entitami pomocí odsazeními CSS
Některé dokumenty používají zásadu definování odsazení textu pomocí entit pevných mezer. Když je tato volba povolena, Calibre se pokusí rozpoznat tento druh formátování a převést je na 3% odsazení textu pomocí CSS.
Hledat a nahradit¶
Tyto volby jsou užitečné především při převodu dokumentů PDF nebo při převodech z OCR, lze je však použít i k opravě mnoha problémů specifických pro konkrétní dokument. Některé převody mohou například v textu zanechat záhlaví a zápatí stránek. Tyto volby používají regulární výrazy k pokusu o rozpoznání záhlaví, zápatí nebo jiného libovolného textu a jejich odstranění nebo nahrazení. Pamatujte, že pracují s mezilehlým XHTML vytvořeným převodním řetězcem. K dispozici je průvodce, který vám pomůže upravit regulární výrazy pro váš dokument. Klikněte na kouzelnou hůlku vedle pole výrazu a po sestavení vyhledávacího výrazu klikněte na tlačítko „Test“. Úspěšné shody budou zvýrazněny žlutě.
Vyhledávání funguje pomocí regulárního výrazu Pythonu. Všechny odpovídající texty jsou jednoduše odebrány z dokumentu nebo nahrazeny pomocí vzoru nahrazení. Vzor nahrazení je nepovinný, pokud zůstane prázdný, pak text odpovídající hledanému vzoru bude z dokumentu odstraněn. Další informace o regulárních výrazech a jejich syntaxi můžete zjistit v Vše o používání regulárních výrazů v Calibre.
Rozpoznávání struktury¶
Rozpoznávání struktury zahrnuje to, že se Calibre pokouší co nejlépe rozpoznat strukturální prvky ve vstupním dokumentu, pokud nejsou správně zadány. Například kapitoly, konce stránek, záhlaví, zápatí atd. Jak si dokážete představit, tento proces se velice liší knihu od knihy. Naštěstí má Calibre velice mocné možnosti, aby toto určilo. S mocí přichází složitost, ale pokud si jednou uděláte čas na to naučit se to složité, zjistíte, že to stálo za námahu.
Konce kapitol a stránek¶
calibre má dvě sady voleb pro rozpoznání kapitol a vkládání zalomení stránek. To může být někdy trochu matoucí, protože ve výchozím nastavení vloží zalomení stránky před rozpoznané kapitoly i na místa rozpoznaná volbou pro zalomení stránek. Důvodem je, že často existují místa, kde by se mělo vložit zalomení stránky, i když nejde o hranice kapitol. Rozpoznané kapitoly lze také volitelně vložit do automaticky vygenerovaného obsahu.
Calibre používá XPath, výkonný jazyk, který umožňuje uživateli zadat hranice kapitol nebo konce stránek. XPath se může zdát nejdříve trochu skličující pro používání, naštěstí je zde kurz XPath v uživatelské příručce. Nezapomeňte, že Rozpoznávání struktury pracuje na polotovaru XHTML vytvořeného převodním řetězcem. Použijte možnost ladění popsanou v Úvod, abyste určili vhodné nastavení pro svou knihu. Je zde také tlačítko pro Průvodce XPath, aby pomohl s generováním jednoduchých výrazů XPath.
Ve výchozím nastavení používá Calibre následující výraz pro rozpoznávání kapitol:
//*[((name()='h1' or name()='h2') and re:test(., 'chapter|book|section|part\s+', 'i')) or @class = 'chapter']
Tento výraz je poměrně složitý, protože se snaží zpracovat velký počet běžných případů souběžně. To znamená, že Calibre bude předpokládat, že kapitoly začínají buď značkou <h1> nebo <h2>, které obsahují kterékoliv z těchto slov (kapitola, kniha, oddíl nebo část), nebo které mají atribut class=“kapitola“.
Související možností je Označení kapitol, který vám umožní určit, co Calibre udělá, když rozpozná kapitolu. Ve výchozím nastavení vloží konec stránky před kapitolu. Můžete ho nechat vložit linku namísto nebo navíc ke konci stránky. Můžete ho také nechat nedělat nic.
Výchozí nastavení pro rozpoznávání konců stránek je:
//*[name()='h1' or name()='h2']
což znamená, že Calibre ve výchozím nastavení vloží konce stránek před každou značku <h1> a <h2>.
Poznámka
Výchozí výrazy se mohou měnit v závislosti na vstupním formátu, který převádíte.
Různé¶
V tomto oddílu je několik dalších voleb.
- Vložit metadata jako stránku na začátek knihy
Jednou ze skvělých věcí na Calibre je to, že vám umožňuje udržovat velice kompletní metadata o všech vašich knihách, například hodnocení, štítky, komentáře atd. Tato možnost vytvoří jednoduchou stránku se všemi těmito metadaty a vloží ji do převedené e-knihy, obvykle hned za obálku. Berte to jako způsob, jak si vytvořit svůj vlastní přizpůsobený přebal knihy.
- Odebrat první obrázek
Někdy zdrojový dokument, který převádíte, obsahuje obálku jako součást knihy namísto samostatné obálky. Pokud jste také zadali obálku v Calibre, pak bude mít převedená kniha dvě obálky. Tato možnost jednoduše odebere první obrázek ze zdrojového dokumentu, čímž zajistí, že převedená kniha má pouze jednu obálku, tu zadanou v Calibre.
Obsah¶
Když má vstupní dokument ve svých metadatech obsah, Calibre ho prostě použije. Nicméně velké množství starších formátů buď nepodporuje obsah založený na metadatech nebo ho jednotlivé dokumenty nemají. V těchto případech vám volby v tomto oddílu mohou pomoct automaticky vygenerovat obsah v převáděné e-knize založený na skutečném obsahu ve vstupním dokumentu.
Poznámka
Používání těchto voleb může být trochu složitější, abyste získali přesně to pravé. Pokud upřednostňujete vytváření nebo úpravu obsahu ručně, převeďte na formáty EPUB nebo AZW3 a vyberte zaškrtávací políčko v dolní oddílu Obsah v dialogovém okně převodu, která říká: Ručně jemně ladit obsah po dokončení převodu. Tímto se po převodu spustí nástroj Upravit obsah. Umožní vám vytvářet položky v obsahu jednoduše kliknutím na místo v knize, kam chcete, aby položka ukazovala. Můžete také použít samotný nástroj Upravit obsah, aniž byste prováděli převod. Přejděte na Předvolby → Rozhraní → Panely nástrojů a přidejte Upravit obsah na hlavní panel nástrojů. Pak stačí vybrat knihu, kterou chcete upravit, a kliknout na tlačítko Upravit obsah.
První volba je Vynutit použití automaticky generovaného obsahu. Zaškrtnutím této volby můžete nechat Calibre přepsat jakýkoliv nalezený obsah v metadatech vstupního dokumentu automaticky vygenerovaným.
Výchozí způsob, jakým vytvoření automaticky vygenerovaného obsahu funguje, je ten, že Calibre nejdříve zkusí přidat všechny rozpoznané kapitoly do vygenerovaného obsahu. Jak přizpůsobit rozpoznávání kapitol můžete zjistit ve výše uvedeném oddílu Rozpoznávání struktury. Pokud nechcete zahrnout rozpoznané kapitoly do vygenerovaného obsahu, zaškrtněte volbu Nepřidávat rozpoznané kapitoly do obsahu.
Pokud bylo rozpoznáno méně kapitol, než je hodnota Mezní hodnota kapitol, Calibre pak přidá do obsahu všechny hypertextové odkazy, které najde ve vstupním dokumentu. Toto často funguje dobře na mnoha vstupních dokumentech, které obsahují hypertextové odkazy obsahu hned na začátku. Volba Počet odkazů může být použita k ovládání tohoto chování. Pokud je nastavena na nulu, nejsou přidány žádné odkazy. Pokud je nastavena na číslo větší než nula, je přidán nanejvýše tento počet odkazů.
Calibre automaticky vyfiltruje duplicity z generovaného obsahu. Pokud však jsou zde nějaké další nežádoucí položky, můžete je vyfiltrovat pomocí volby Filtr obsahu. To je regulární výraz, který porovná názvy položek ve vygenerovaném obsahu. Kdykoliv je nalezena shoda, bude odebrána. Například pro odebrání všech názvů položek „Další“ nebo „Předchozí“ použijte:
Next|Previous
Volby Obsah 1., 2. a 3. úrovně vám umožní vytvořit propracovaný víceúrovňový obsah. Jsou to výrazy XPath, které porovnají značky v polotovaru XHTML vytvořeného převodním řetězcem. Podívejte se na Úvod, jak získat přístup k tomuto XHTML. Přečtěte si také Kurz XPath, abyste zjistili, jak vytvářet výrazy XPath. Vedle každé volby je tlačítko, které spustí průvodce, který vám pomůže s vytvořením základních výrazů XPath. Následující jednoduchý příklad vysvětluje, jak používat tyto volby.
Předpokládejme, že máte vstupní dokument, jehož výsledkem je XHTML vypadající takto:
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<title>Sample document</title>
</head>
<body>
<h1>Chapter 1</h1>
...
<h2>Section 1.1</h2>
...
<h2>Section 1.2</h2>
...
<h1>Chapter 2</h1>
...
<h2>Section 2.1</h2>
...
</body>
</html>
Potom nastavíme možnosti jako:
Level 1 TOC : //h:h1
Level 2 TOC : //h:h2
Toto bude mít za výsledek automaticky generovaný dvouúrovňový obsah, který vypadá jako:
Chapter 1
Section 1.1
Section 1.2
Chapter 2
Section 2.1
Varování
Ne všechny formáty podporují víceúrovňové obsahy. Nejdříve byste to měli zkusit s výstupem EPUB. Pokud to funguje, zkuste formát vlastního výběru.
Požití obrázku jako názvu kapitol pří konverzi HTML vstupních dokumentů¶
Předpokládejme, že chcete použít obrázek jako název kapitoly, ale stále chcete, aby Calibre bylo pro vás schopno automaticky generovat obsah z názvů kapitol. Použijte následující značení HTML, abyste toho dosáhli:
<html>
<body>
<h2>Chapter 1</h2>
<p>chapter 1 text...</p>
<h2 title="Chapter 2"><img src="chapter2.jpg" /></h2>
<p>chapter 2 text...</p>
</body>
</html>
Nastavte Obsah 1. úrovně na //h:h2. Pak pro druhou kapitolu Calibre vezme název z hodnoty atributu title značky <h2>, protože značka nemá žádný text.
Používání atributů značek pro dodání textu pro položky v obsahu¶
Pokud máte obzvlášť dlouhé názvy kapitol a chcete mít v obsahu zkrácené verze, můžete použít atribut názvu, abyste toho dosáhli, například:
<html>
<body>
<h2 title="Chapter 1">Chapter 1: Some very long title</h2>
<p>chapter 1 text...</p>
<h2 title="Chapter 2">Chapter 2: Some other very long title</h2>
<p>chapter 2 text...</p>
</body>
</html>
Nastavte Obsah 1. úrovně na //h:h2/@title. Pak Calibre vezme názvy z hodnot atributů title značek <h2>, namísto použití textu uvnitř značky. Pamatujte na koncové /@title ve výrazu XPath, tento formulář můžete použít, abyste řekli Calibre, aby získalo text z jakéhokoliv atributu chcete.
Jak jsou nastaveny nebo uloženy volby pro převod¶
V Calibre jsou dvě místa, kde mohou být nastaveny volby převodu. První je v Nastavení->Převod. Tato nastavení jsou výchozí pro volby převodu. Kdykoliv se pokusíte převést novou knihu, zde zadaná nastavení budou použita jako výchozí.
Můžete také změnit nastavení v dialogovém okně převodu pro převod každé knihy. Když převádíte nějakou knihu, Calibre si pamatuje nastavení použité pro tuto knihu, takže pokud ji převedete znovu, bude mít přednost uložené nastavení pro jednotlivou knihu před výchozími hodnotami nastavenými v předvolbách. Jednotlivé nastavení můžete obnovit na výchozí hodnoty pomocí tlačítka Obnovit výchozí nastavení v dialogovém okně převodu jednotlivé knihy. Uložené nastavení pro skupinu knih můžete odebrat výběrem všech knih a klepnutím na tlačítko Upravit metadata, které vyvolá dialogové okno hromadné úpravy metadat, v blízkosti spodní části dialogového okna je volba odebrat uložené nastavení převodu.
Když hromadně převádíte sadu knih, nastavení jsou brána v následujícím pořadí (poslední vyhrává):
Z výchozího nastavení v Předvolby->Převod
Z uloženého nastavení převodu pro každou převáděnou knihu (pokud existuje). Toto lze vypnout pomocí volby v levém horním rohu dialogového okna Hromadný převod.
Z nastavení v dialogovém okně Hromadný převod
Pamatujte, že konečné nastavení pro každou knihu v Hromadném převodu bude uloženo a znovu použito, pokud je kniha znovu převáděna. Vzhledem k tomu, že nejvyšší priorita v Hromadném převodu je dána nastavením v dialogovém okně Hromadný převod, budou mít přednost před všemi konkrétními nastaveními knihy. Takže byste měli společně hromadně převádět pouze knihy, které potřebují podobná nastavení. Výjimkou jsou metadata a konkrétní nastavení formátu vstupu. Vzhledem k tomu, že dialogové okno Hromadný převod nemá nastavení pro tyto dvě kategorie, budou převzaty z konkrétního nastavení knihy (pokud existuje), nebo z výchozího nastavení.
Poznámka
Aktuální nastavení použité během jakéhokoliv převodu můžete zobrazit kliknutím na otáčející se ikonu v pravém dolním rohu a pak dvojitým kliknutím na jednotlivou úlohu převodu. Tím se zobrazí protokol převodu, který bude nahoře obsahovat skutečně použitá nastavení.
Tipy pro konkrétní formáty¶
Zde najdete konkrétní tipy pro převod určitých formátů. Konkrétní volby pro určitý formát, zda je vstup nebo výstup dostupný v dialogovém okně převodu pod vlastním oddílem, například Vstup TXT nebo Výstup EPUB.
Převod dokumentů Microsoft Word¶
Calibre umí automaticky převést soubory .docx vytvořené v Microsoft Word 2007 a novějším. Stačí přidat soubor do Calibre a kliknout na tlačítko Převést.
Poznámka
Zde je ukázkový soubor .docx, který ukazuje schopnosti převodního modulu Calibre. Stačí ho stáhnout a převést do formátu EPUB nebo AZW3, abyste viděli, co Calibre umí.
Calibre automaticky vygeneruje Obsah na základě nadpisů, pokud označíte nadpisy ve Wordu pomocí stylů Nadpis 1, Nadpis 2 atd. Otevřete výstupní e-knihu v prohlížeči Calibre a klikněte na tlačítko Obsah pro zobrazení vygenerovaného obsahu.
Starší soubory .doc¶
U starších souborů .doc můžete v Microsoft Word uložit dokument jako HTML a pak převést výsledný soubor HTML pomocí Calibre. Při ukládání jako HTML je nutné použít volbu „Uložit jako webovou stránku, zjednodušený formát“, protože to vytvoří čisté HTML, které se bude dobře převádět. Pamatujte, že Word vytváří opravdu chaotické HTML, jehož převod může trvat dlouho, takže buďte trpěliví. Pokud máte k dispozici novější verzi Wordu, můžete ho také přímo uložit jako .docx.
Jinou alternativou je využít bezplatné LibreOffice. Otevřete v LibreOffice svůj soubor .doc a uložte ho jako .docx, který může být přímo převeden v Calibre.
Převod dokumentů TXT¶
Dokumenty TXT nemají dobře definovaný způsob, jak zadávat formátování, jako je tučné, kurzíva atd, nebo strukturu dokumentu, jako jsou odstavce, nadpisy, oddíly a tak dále, ale existuje celá řada běžně používaných zásad. Ve výchozím nastavení se Calibre pokusí o automatické rozpoznání správného formátování a značení na základě těchto zásad.
Vstup TXT podporuje celou řadu voleb k odlišení, jak jsou rozpoznány odstavce.
- Styl odstavců: Automaticky
Analyzuje textový soubor a pokusí se automaticky určit, jak jsou definovány odstavce. Tato volba bude obvykle fungovat dobře, pokud dosáhnete nežádoucí výsledky, zkuste jednu z ručních voleb.
- Styl odstavců: Blok
Předpokládá, že jeden nebo více prázdných řádků jsou hranice odstavce:
This is the first. This is the second paragraph.- Styl odstavců: Jednoduchý
Předpokládá, že každý řádek je odstavec:
This is the first. This is the second. This is the third.- Styl odstavců: Tisk
Předpokládá, že každý odstavec začíná odsazením (buď tabulátor nebo 2 a více mezer). Odstavec končí, když je dosaženo dalšího řádku, který začíná odsazením:
This is the first. This is the second. This is the third.- Styl odstavců: Neformátovaný
Předpokládá, že dokument nemá žádné formátování, ale používá pevné konce řádků. Pro pokus o znovu vytvoření odstavců je použita interpunkce a střední délka řádku.
- Styl formátování: Automaticky
Pokusí se rozpoznat použitý typ značek formátování. Pokud nejsou požity žádné značky, bude použito heuristické formátování.
- Styl formátování: Heuristiké
Analyzuje v dokumentu běžné nadpisy kapitol, přerušení příběhu a slova kurzívou a použije příslušné značky HTML během převodu.
- Styl formátování: Značkování
Calibre také podporuje průběh vstupu TXT transformačním předzpracováním známým jako Značkování. Značkování umožňuje přidání základního formátování do dokumentů TXT, jako je tučné, kurzíva, nadpisy oddílů, tabulky, seznamy, obsahy, atd. Označení nadpisů kapitol úvodním znakem # a nastavení výrazu XPath pro rozpoznání kapitol na „//h:h1“ je nejjednodušší způsob, jak získat řádný obsah vygenerovaný z dokumentu TXT. Více o Syntaxi značkování se můžete dozvědět na daringfireball.
- Styl formátování: Žádný
Nepoužije na text žádné zvláštní formátování, dokument je převeden na HTML bez žádných dalších změn.
Převod dokumentů PDF¶
Dokumenty PDF jsou jedním z nejhorších formátů, ze kterého převádět. Mají pevný formát velikosti stránky a umístění textu. To znamená, že je velice obtížné určit, kde končí jeden odstavec a začíná další. Calibre se pokusí zrušit zalomení odstavců pomocí konfigurovatelného Koeficientu nezalamování řádků. Je to měřítko použité k určení délky, při které by měl být řádek nezalomený. Platné hodnoty jsou desetinná čísla mezi 0 a 1. Výchozí hodnota je 0,45, těsně pod střední délkou řádku. Snižte tuto hodnotu pro zahrnutí více textu do nezalamování. Zvyšte pro zahrnutí méně. Tuto hodnotu můžete upravit v nastavení převodu pod Vstup PDF.
Často také mají záhlaví a zápatí jako součást dokumentu, které se zahrnou do textu. Použijte panel Najít a nahradit pro odebrání záhlaví a zápatí ke zmírnění tohoto problému. Pokud záhlaví a zápatí nejsou odebrány z textu, mohou rozhodit zrušení zalamování odstavců. Abyste se naučili, jak používat volbu odebírání záhlaví a zápatí, přečtěte si regexptutorial`.
Některá omezení vstupu PDF jsou:
Nejsou podporovány dokumenty, které jsou složité, vícesloupcové a založené na obrázcích.
Také není podporována extrakce vektorových obrázků a tabulek zevnitř dokumentu.
Některá PDF používají speciální glyfy zastupující ll, ff nebo fi, atd. Jejich převod může nebo nemusí fungovat v závislosti na tom, jak jsou zastoupeny vnitřně v PDF.
Nejsou podporovány odkazy a obsahy.
PDF, která používají vložená písma nepodporující kód Unicode pro zastupování neanglických znaků, způsobí zkomolený výstup pro tyto znaky.
Některá PDF jsou tvořena fotografiemi stránky s opticky rozpoznaným textem (OCR) za nimi. V takových případech Calibre použije opticky rozpoznaný text, což může být velice odlišné od toho, co vidíte, když si prohlížíte soubor PDF.
PDF, která jsou použita pro zobrazení složitého textu, jako jsou jazyky zprava doleva a matematické vzorce, nebudou správně převedena.
Znovu opakujeme, že PDF je opravdu, ale opravdu špatný formát pro použití jako vstupu. Pokud musíte naprosto nutně použít PDF, pak buďte připraveni na výstup kdekoliv v rozmezí od slušného po nepoužitelný, v závislosti na vstupním PDF.
Sbírky komiksů¶
Sbírka komiksů je soubor .cbc. Soubor .cbc je soubor ZIP, který obsahuje jiné soubory CBZ nebo CBR. Soubor .cbc musí navíc obsahovat jednoduchý textový soubor nazvaný comics.txt kódovaný v UTF-8. Soubor comics.txt musí obsahovat seznam souborů komiksů uvnitř souboru .cbc v podobě názevsouboru:název, jak je zobrazeno níže:
one.cbz:Chapter One
two.cbz:Chapter Two
three.cbz:Chapter Three
Soubor .cbc pak bude obsahovat:
comics.txt
one.cbz
two.cbz
three.cbz
calibre tento soubor .cbc automaticky převede na e-knihu s obsahem odkazujícím na každou položku v souboru comics.txt.
Ukázka rozšířeného formátování EPUB¶
V tomto ukázkovém souboru je znázorněno různé rozšířené formátování pro soubory EPUB. Soubor byl vytvořen z ručně kódovaného HTML pomocí Calibre a je určen pro použití jako šablony pro vaše vlastní úsilí o vytváření EPUB.
Zdrojové HTML, ze kterého byl vytvořen, je dostupné v demo.zip. Nastavení použitá pro vytvoření EPUB ze souboru ZIP jsou:
ebook-convert demo.zip .epub -vv --authors "Kovid Goyal" --language en --level1-toc '//*[@class="title"]' --disable-font-rescaling --page-breaks-before / --no-default-epub-cover
Pamatujte, že protože tento soubor prozkoumává potenciál EPUB, většina rozšířeného formátování nebude fungovat ve čtečkách méně schopných, než je vestavěný prohlížeč EPUB Calibre.
Převod dokumentů ODT¶
Calibre umí přímo převést soubory ODT (OpenDocument Text). Pro formátování dokumentu byste měli používat styly a minimalizovat použití přímého formátování. Při vkládání obrázků do dokumentu je musíte ukotvit k odstavci, obrázky ukotvené ke stránce skončí všechny na začátku převodu.
Pro povolení automatického rozpoznání kapitol je musíte označit vestavěnými styly nazvanými Nadpis 1, Nadpis 2, …, Nadpis 6 (Nadpis 1 se rovná značce HTML <h1>, Nadpis 2 se rovná <h2> atd.). Při převodu v Calibre můžete zadat, který styl jste použili, do pole Rozpoznat kapitoly v. Příklad:
Pokud označíte kapitoly stylem Nadpis 2, musíte nastavit pole ‚Rozpoznat kapitoly v‘ na
//h:h2Pro vnořený obsah s oddíly označenými Nadpis 2 a kapitolami označenými ‚Nadpis 3 musíte zadat
//h:h2|//h:h3. Na stránce Převod - Obsah nastavte pole Obsah 1. úrovně na//h:h2a pole Obsah 2. úrovně na//h:h3.
Rozpoznávají se známé vlastnosti dokumentu (Title, Keywords, Description, Creator) a calibre použije první obrázek, který není příliš malý a má dobrý poměr stran, jako obrázek obálky.
K dispozici je také převodní režim rozšířených vlastností, který je aktivován nastavením vlastní vlastnosti opf.metadata (typ ‚Ano nebo ne‘) na Ano ve vašem dokumentu ODT (Soubor->Vlastnosti->Vlastní vlastnosti). Pokud Calibre tuto vlastnost rozpozná, jsou rozpoznány následující vlastní vlastnosti (opf.authors přepíše autora dokumentu):
opf.titlesort
opf.authors
opf.authorsort
opf.publisher
opf.pubdate
opf.isbn
opf.language
opf.series
opf.seriesindex
Kromě toho můžete zadat obrázek, který se použije jako obálka, jeho pojmenováním opf.cover (klikněte pravým tlačítkem myši, Obrázek->Volby->Název) v ODT. Pokud není nalezen žádný obrázek s tímto názvem, použije se ‚chytrá‘ metoda. Protože rozpoznávání obálky může u určitých výstupních formátů vést ke dvěma obálkám, zpracování odebere odstavec (pouze pokud jediný obsah je obálka!) z dokumentu. Ale funguje to pouze s pojmenovaným obrázkem!
Pro zakázání rozpoznávání obálky můžete v rozšířeném režimu nastavit vlastní vlastnost opf.nocover (typ ‚Ano nebo Ne‘) na Ano.
Převádění do PDF¶
První, nejdůležitější nastavení, o kterém musíte rozhodnout při převodu na PDF, je velikost stránky. Ve výchozím nastavení Calibre používá velikost stránky „US Letter“. Toto můžete změnit na jinou standardní velikost stránky nebo zcela vlastní velikost v oddílu Výstup PDF dialogového okna převodu. Pokud generujete PDF, které má být použito na konkrétním zařízení, můžete namísto toho zapnout volbu použít velikost stránky z výstupního profilu . Takže pokud je váš výstupní profil nastaven na Kindle, Calibre vytvoří PDF s velikostí stránky vhodné pro zobrazení na malé obrazovce Kindle.
Tisknutelný obsah¶
Na konec PDF můžete také vložit tisknutelný obsah, který vypíše čísla stránek pro každý oddíl. To je velmi užitečné, pokud zamýšlíte vytisknout PDF na papír. Pokud si přejete použít PDF na elektronickém zařízení, pak Osnova PDF poskytuje tuto funkci a je generována ve výchozím nastavení.
Vzhled generovaného obsahu můžete přizpůsobit pomocí nastavení Dodatečné CSS pod částí Vzhled a chování dialogového okna převodu. CSS použité ve výchozím nastavení je uvedeno níže, jednoduše ho zkopírujte proveďte v něm libovolné změny.
.calibre-pdf-toc table { width: 100%% }
.calibre-pdf-toc table tr td:last-of-type { text-align: right }
.calibre-pdf-toc .level-0 {
font-size: larger;
}
.calibre-pdf-toc .level-1 td:first-of-type { padding-left: 1.4em }
.calibre-pdf-toc .level-2 td:first-of-type { padding-left: 2.8em }
Vlastní okraje stránky pro jednotlivé soubory HTML¶
Pokud převádíte soubor EPUB nebo AZW3 s více jednotlivými soubory HTML uvnitř a chcete změnit okraje stránek pro konkrétní soubor HTML, můžete pomocí Editoru e-knih Calibre přidat do souboru HTML následující blok stylu:
<style>
@page {
margin-left: 10pt;
margin-right: 10pt;
margin-top: 10pt;
margin-bottom: 10pt;
}
</style>
Pak v oddílu výstupu PDF v dialogovém okně převodu zapněte volbu na Použít okraje stránek z převáděného dokumentu. Nyní budou mít všechny stránky generované z tohoto souboru HTML okraje 10pt.