 Cambiar idioma
Cambiar idiomaConversión de libros¶
calibre tiene un sistema de conversión diseñado para que sea fácil de usar. Normalmente no tiene más que añadir un libro a calibre, pulsar en convertir y calibre intentará generar una salida tan parecida como sea posible a la entrada. Sin embargo, calibre acepta un gran número de formatos de entrada, y no todos son tan adecuados como otros para convertirse a otros formatos. En el caso de los formatos menos adecuados, o si simplemente desea tener mayor control sobre el sistema de conversión, calibre tiene muchas opciones para ajustar los detalles del sistema de conversion. Tenga en cuenta que el sistema de conversión de calibre no es un sustituto para un editor completo de libros electrónicos. Para modificar libros le recomiendo que los convierta primero a EPUB o AZW3 con cailbre y luego use la función Modificar libro para darle la forma perfecta. Después puede usar el libro modificado como entrada para otros formatos en calibre.
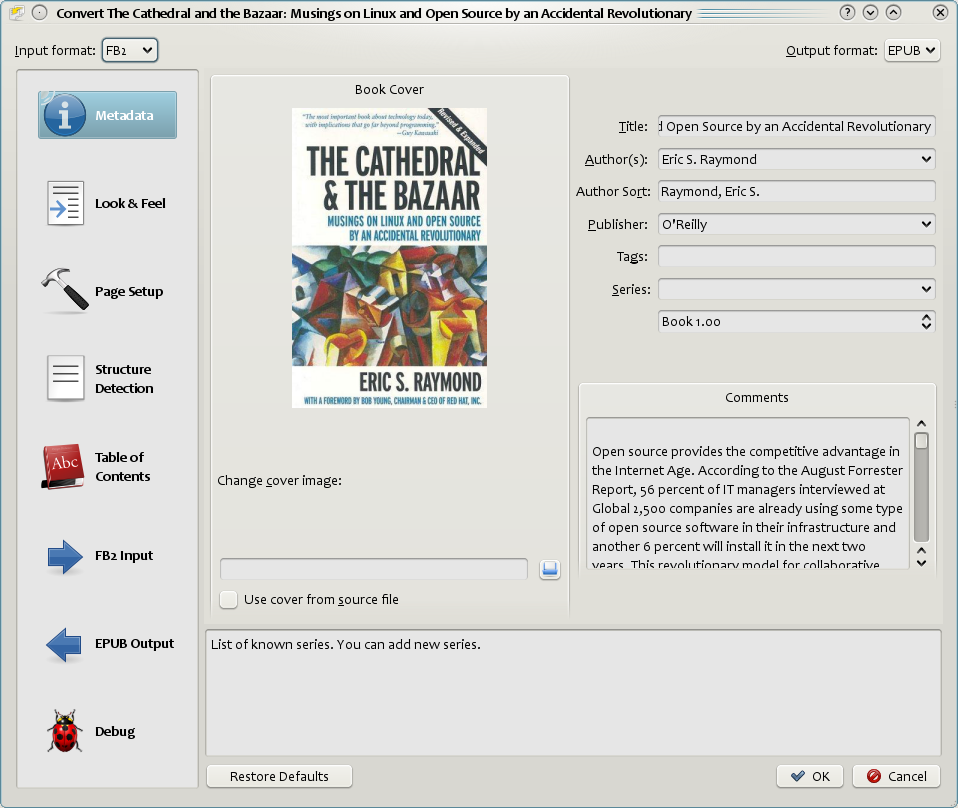
Este documento se referirá principalmente a las opciones de conversión que se encuentran en el cuadro de diálogo de conversión, mostrado a continuación. Todas estas opciones también están disponibles en la interfaz de línea de órdenes para la conversión, documentada en ebook-convert. En calibre, puede obtener ayuda sobre cualquier opción manteniendo el cursor sobre ella, aparecerá una ayuda emergente que describe la opción.
Introducción¶
Lo primero que debe comprender sobre el sistema de conversión es que está diseñado como una serie de operaciones. Esquemáticamente, es alg así:
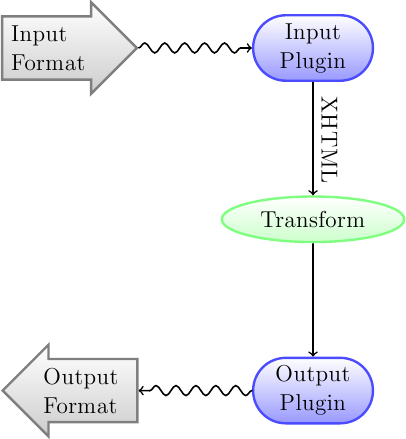
El formato de entrada se convierte primero a XHTML con el complemento de entrada apropiado. Después este HTML se transforma. En el último paso, el XHTML procesado se convierte al formato de salida especificado con el complemento de salida adecuado. Los resultados de la conversión pueden variar enormemente según el formato de entrada. Algunos formatos de entrada se convierten mucho mejorque otros. Una lista de los mejores formatos de origen para la conversión está disponible aquí.
Todo el trabajo tiene lugar en las transformaciones que operan sobre la salida XHTML. Hay varias transformaciones, por ejemplo, para insertar los metadatos del libro en una página al inicio del libro, para detectar encabezados de capítulo y crear un índice automáticamente, para ajustar los tamaños de letra proporcionalmente, etc. Es importante recordar que todas las transformaciones actúan sobre el XHTML creado por el complemento de entrada, no sobre el archivo de entrada en sí. Así, por ejemplo, si pide a calibre que convierta un archivo RTF a EPUB, primero lo convertirá a XHTML internamente, se aplicarán las distintas transformaciones sobre el XHTML y después el complemento de salida creará el archivo EPUB, generando automáticamente todos los metadatos, índice, etc.
Puede ver este proceso en acción usando la opción de depuración  . Simplemente especifique la ruta de acceso a una carpeta para la salida de depuración. Durante la conversión, calibre guardará el XHTML generado por las distintas etapas del proceso de conversión en subcarpetas separadas. Las cuatro subcarpetas son:
. Simplemente especifique la ruta de acceso a una carpeta para la salida de depuración. Durante la conversión, calibre guardará el XHTML generado por las distintas etapas del proceso de conversión en subcarpetas separadas. Las cuatro subcarpetas son:
Carpeta |
Descripción |
|---|---|
input |
Contiene el HTML creado por el complemento de entrada. Úselo para depurar el complemento de entrada. |
parsed |
El resultado del preprocesado y conversión a XHTML de la salida del complemento de entrada. Úselo para depurar la detección de estructura. |
structure |
Posterior a la detección de estructura, pero anterior al aplanado de CSS y conversión de tamaños de letra. Úselo para depurar la conversión de tamaños de letra y las transformaciones de CSS. |
processed |
Justo antes de que el libro pase al complemento de salida. Úselo para depurar el complemento de salida. |
Si desea modificar el documento de salida antes de que calibre lo convierta, lo mejor es modificar los archivos en la subcarpeta input, comprimirlos en un archivo ZIP y usar éste como formato de entrada para las subsiguientes conversiones. Para hacer esto use el cuadro de diálogo Modificar metadatos para añadir el ZIP como formato para el libro y entonces, en la esquina superior izquierda del cuadro de diálogo de conversión, seleccione ZIP como formato de entrada.
Este documento se ocupará principalmente de las distintas transformaciones que operan sobre el XHTML intermedio y cómo controlarlas. Al final hay algunos consejos específicos para cada formato de entrada o salida.
Apariencia¶
Las opciones de este grupo controlan varios aspectos del aspecto del libro electrónico convertido.
Tipos de letra¶
Una de las características más agradables de la experiencia de lectura electrónica es la capacidad de ajustar fácilmente el tamaño de las fuentes para adaptarse a las necesidades individuales y las condiciones de iluminación. Calibre tiene algoritmos sofisticados para garantizar que todos los libros que produce tengan tamaños de fuente consistentes, sin importar qué tamaños de fuente se especifiquen en el documento de entrada.
El tamaño de letra base de un documento es el tamaño de letra más común en el documento, es decir, el tamaño del texto principal del documento. Cuando especifica un Tamaño de letra base, calibre redimensiona automáticamente todos los tamaños de letra del documento proporcionalmente, de manera que el tamaño más común pasa a ser el tamaño base especificado y el resto de los tamaños de letra se redimensionan adecuadamente. Si elige un tamaño de letra base mayor hará que todos los textos del documento sean mayores. Al establecer un tamaño de letra base, para obtener mejores resultados debe establecer también la clave de tamaño de letra.
Normalmente calibre elegirá automáticamente un tamaño de letra base adecuado para el perfil de salida que haya seleccionado (ver Configuración de página). Si el tamaño predeterminado no le satisface, puede especificar otro aquí.
La opción Clave de tamaño de letra le permite especificar cómo se redimensionan los tamaños de letra que no son el base. El algoritmo de redimensionado funciona usando una clave de tamaño de letra, que no es más que una lista de tamaños de letra separados por comas. La clave de tamaño de letra le dice a calibre cuántos «escalones» mayor o menor debe ser un tamaño determinado comparado con el tamaño de letra base. La idea es que debe haber un número limitado de tamaños de letra en un documento. Por ejemplo, un tamaño para el texto principal, un par de tamaños para distintos niveles de encabezados, y un par de tamaños para subíndices o superíndices, o notas a pie de página. La clave de tamaño de letra le permite a calibre clasificar los tamaños de letra en los documentos de entrada en distintas «casillas» que corresponden a los distintos tamaños de letra lógicos.
Veámoslo con un ejemplo. Supongamos que el documento de origen que estamos convirtiendo lo produjo alguien con una vista excelente y tiene un tamaño de letra base de 8pt. Esto significa que el texto principal del documento tiene un tamaño de 8 pt, mientras que los encabezados son algo mayores (digamos 10pt y 12pt) y las notas a pie de página algo menores (6pt). Si usamos las siguientes configuraciones:
Base font size : 12pt
Font size key : 7, 8, 10, 12, 14, 16, 18, 20
El documento de salida tendrá un tamaño de letra base de 12pt, encabezados de 14pt y 16pt y notas a pie de página de 8pt. Ahora supongamos que queremos que los encabezados mayores destaquen más y hacer las notas a pie de página algo mayores también. Para conseguir esto, debemos cambiar la clave de tamaño de letra a:
New font size key : 7, 9, 12, 14, 18, 20, 22
Los encabezados mayores serán ahora de 18pt, mientras que las notas a pie de página serán de 9pt. Puede ajustar estos valores para tratar de optimizarlos usando el asistente de redimensionado de tamaños de letra, al que se puede acceder pulsando en el pequeño botón junto a la opción Clave de tamaño de letra.
También puede desactivarse aquí todo el redimensionado de tamaños de letra en la conversión, si dese mantener los tamaños de letra del documento de entrada.
Una opción relacionada es Altura de línea. La altura de línea controla la separación vertical entre renglones. De manera predeterminada (una altura de línea de 0), no se realiza ninguna manipulación de alturas de línea. Si especifica otro valor, se incluirá una altura de línea en todos los lugares que no especifique su propia altura de línea. Esto es una herramienta bastante tosca y debería usarla en contadas ocasiones. Si quiere ajustar la altura de línea en alguna sección particular de la entrada, es mejor usar el CSS adicional.
En esta sección también puede hacer que calibre incruste los tipos de letra a los que se hace referencia en el libro. Esto permitirá que los tipos de letra funcionen en los dispositivos de lectura incluso si no están disponibles en el dispositivo.
Texto¶
El texto puede estar justificado o no. El texto justificado tiene espacios adicionales entre las palabras para obtener un margen derecho continuo. Algunas personas prefieren texto justificado, otras no. Normalmente, calibre mantiene la justificación del documento original. Si quiere modificarlo, utilice la opción Justificación del texto en esta sección.
Tambien pude usar la opción Mejorar puntuación de calibre, que sustituirá las comillas rectas, guiones y puntos suspensivos por sus variantes tipográficamente correctas. Tenga en cuenta que este algoritmo no es perfecto, por lo que debería revisar el resultado. La operación inversa, Simplificar puntuación, también está disponible.
Por último está la Codificación de entrada. Los documentos antiguos a veces no especifican la codificación de caracteres. Al convertirlos esto puede resultar en la corrupción de caracteres no ASCII, como las letras acentuadas o las comillas tipográficas. calibre intenta detectar automáticamente la codificación de caracteres del documento de entrada, pero no siempre tiene éxito. Puede forzar una codificación concreta con esta opción. cp1252 es una codificación frecuente en documentos creados con software de Windows. También debería leer ¿Cómo convierto un archivo que contiene caracteres «exóticos» (acentuados, no latinos, comillas tipográficas, etc.)? para saber más sobre posibles problemas de codificación.
Distribución¶
Normalmente, los párrafos en XHTML se muestran con un espacio entre ellos y sin sangría en el primer renglón. calibre tiene un par de opciones para controlar esto. Eliminar el espacio entre párrafos fuerza que no haya separación entre párrafos. También establece la sangría en 1.5em (se puede cambiar) para indicar el inicio de cada párrafo. Insertar una línea en blanco entre párrafos hace lo contrario, asegurándose de que los párrafos están separados por el espacio correspondiente a un renglón. Ambas opciones son my generales, añaden o eliminan el espacio para todos los párrafos (técnicamente, para las etiquetas <p> y <div>). Esto es así para que pueda activar la opción y tener la seguridad de que hace lo que anuncia, sin importar lo enrevesado que pueda ser el archivo de entrada. La única excepción es cuando el archivo de entrada usa saltos de línea como espacio entre párrafos.
Si desea eliminar los espaciados entre todos los párrafos, exceptuando algunos, no utilice estas opciones. En lugar de ello añada el siguiente código CSS en CSS adicional:
p, div { margin: 0pt; border: 0pt; text-indent: 1.5em }
.spacious { margin-bottom: 1em; text-indent: 0pt; }
Después, en el documento de origen, marque los párrafos que necesitan espaciado con class=»spacious». Si el documento de entrada no está en formato HTML, use la opción de depuración, mencionada en la Introducción para obtener HTML (use la subcarpeta input).
Otra opción útil es Linearizar tablas. Algunos documentos mal diseñados utilizan tablas para controlar la disposición del texto en la página. Al convertirlos, estos documentos suelen presentar texto que se sale de la página y otros artefactos. Esta opción extraerá el contenido de las tablas y lo presentará de forma lineal. Tenga en cuenta que esta opción linealiza todas las tablas, así que úsela solo si está seguro de que el documento de entrada no utiliza tablas para fines legítimos, como presentar información tabular.
Estilos¶
La opción CSS adicional le permite especificar código CSS arbitrario que se aplicará a todos los archivos HTML de la entrada. Este código CSS se aplica con muy alta prioridad, por lo que puede reemplazar la mayor parte del código CSS en el documento de entrada. Puede usar esta opción para refinar la presentación o dsiposición del documento. Por ejemplo, si desea que todos los párrafos de la clase endnote estén alineados a la derecha, añada:
.endnote { text-align: right }
o si desea cambiar la sangría de todos los párrafos:
p { text-indent: 5mm; }
CSS adicional es una opción muy potente, pero necesita entender cómo funciona el código CSS para sacarle el máximo partido. Puede utilizar la opción de depuración mencionada anteriormente para ver el código CSS presente en el documento de entrada.
Una opción más sencilla es usar Filtrar información de estilo. Esto le permite eliminar todas las propiedades CSS de los tipos especificados del documento. Por ejemplo, puede eliminar todos los colores o tipos de letra.
Transformar estilos¶
Esta es la función más potente relacionada con los estilos. Puede usarla para definir reglas que modificarán los estilos según distintas condiciones. Por ejemplo, puede cambiar todo el color verde a azul, o eliminar todas las negritas del texto o asignar un color determinado a todos los encabezados, etc.
Transformar HTML¶
Parecido a la transformación de estilos, pero le permite hacer cambios en el código HTML del libro. Puede sustituir una etiqueta por otra, añadir clases u otros atributos a etiquetas según su contenido, etc.
Configuración de página¶
Las opciones de configuración de página son para controlar la disposición en la pantalla, como márgenes y tamaño de pantalla. Hay opciones para establecer márgenes de página, que usará el complemento de salida si el formato de salida especificado admite márgenes de página. Además, debería seleccionar un perfil de entrada y un perfil de salida. Ambos perfiles se encargan básicamente de interpretar las dimensiones en los documentos de entrada o salida, los tamaños de pantalla y las claves predeterminadas de tamaño de letra.
Si sabe que el archivo concreto que va a convertir está pensado para un dispositivo o programa particular, elija el correspondiente perfil de entrada, en caso contrario elija simplemente el perfl de entrada predeterminado. Si sabe que los archivos producidos van a usarse con un tipo de dispositivo específico, elija el perfil de salida correspondiente. En caso contrario, elija el perfil de salida genérico. Si está convirtiendo a MOBI o AZW3, casi siempre querrá usar uno de los perfiles de salida Kindle. Si no, lo mejor para los lectores modernos suele ser elegir el perfil de salida Tinta electrónica genérico alta definición.
El perfil de salida también controla el tamaño de pantalla. Esto causará, por ejemplo, que las imágenes se redimensionen automáticamente para adaptarse a la pantalla en algunos formatos de salida. Por lo tanto elija el perfil de un dispositivo que tenga una pantalla de tamaño similar a su dispositivo.
Procesado heurístico¶
El procesado heurístico suministra una variedad de funciones que pueden utilizarse para detectar y corregir problemas usuales en documentos con formato deficiente. Utilice estas funciones si el documento de entrada tiene este problema. Puesto que estas funciones se basan en patrones comunes, sea consciente de que en algunos casos una opción puede degenerar en peores resultados, así que úselas con precaución. Como ejemplo, varias de estas opciones eliminarán todos los espacios duros, o puede incluir falsos positivos relativos a la función.
- Activar el procesado heurístico
Esta opción activa la etapa de procesado heurístico de calibre en el proceso de conversión. Debe estar habilitada para que se apliquen varias subfunciones
- Unir líneas
Si activa esta opción, calibre intentará detectar y corregir saltos de línea forzados en el documento usando pistas como la puntuación y la longitud del renglón. calibre primero intentará detectar si existen saltos de línea forzados, si no es así calibre no intentará unir renglones. Puede reducir el factor de unión de líneas si quiere «forzar» a calibre a unir renglones.
- Factor de unión de líneas
Esta opción controla el algoritmo que usa calibre para eliminar los saltos de línea forzados. Por ejemplo, si el valor de esta opción es 0.4, eso significa que calibre eliminará los saltos de línea de los renglones cuya longitud sea menor del 40% de todos los renglones del documento. Si el documento tiene sólo algunos saltos de línea que necesitan la corrección, este valor debería reducirse a algo entre 0.1 y 0.2.
- Detectar y marcar cabeceras y subcabeceras de capítulos sin formato
Si el documento no posee cabeceras de capítulo y títulos con un formato diferente del resto del texto, calibre puede usar esta opción para intentar detectarlos e incluirlos en etiquetas de encabezado. Las etiquetas <h2> se usan para cabeceras de capítulo; las etiquetas <h3> se usan para cualquier título que se detecte.
Esta función no creará un índice, pero en muchos casos hará que la detección automática de capítulos predeterminada de calibre detecte los capítulos correctamente y cree un índice. Ajuste la expresión XPath en Detección de estructura si no se crea automáticamente un índice. Si no se usan otras cabeceras en el documento, especificar
//h:h2como expresión XPath será la forma más fácil de crear un índice para el documento.Las cabeceras insertadas no poseen formato, para aplicarle uno utilice la opción CSS adicional en la sección de configuración :guilabel`Apariencia`. Por ejemplo, para centrar las etiquetas de cabecera, utilice lo siguiente:
h2, h3 { text-align: center }
- Renumerar secuencias de etiquetas <h1> o <h2> para evitar divisiones
Algunas editoriales utilizan varias etiquetas <h1> o <h2> consecutivas par dar formato a las cabeceras de capítulo. La configuración de conversión predeterminada de calibre hará que tales títulos se divididan en varias partes. Esta opción renumerará las etiquetas de cabecera para evitar la división.
- Borrar líneas en blanco entre párrafos
Esta opción hace que calibre analice las líneas en blanco incluidas en el documento. Si todos los párrafos están separados por líneas en blanco, calibre eliminará todos esos párrafos en blanco. Varias líneas en blanco consecutivas se considerarán como saltos de escena y se mantendrán como un único párrafo. Esta opción se diferencia de Eliminar el espacio entre párrafos en Apariencia en que introduce cambios en el código HTML, mientras que la otra opción sólo modifica los estilos del documento. Esta opción también puede eliminar párrafos que se introdujeron con la opción de calibre Insertar líneas en blanco.
- Asegurar que los cambios de escena tienen un formato consistente
Con esta opción calibre intentará detectar marcadores de cambio de escena comunes y se asegurará de que estén centrados. A los marcadores de cambio de escena «implícitos», es decir, cambios de escena definidos sólo por espacio adicional, se les aplica un estilo para evitar que coincidan con saltos de página.
- Sustituir cambios de escena
Si esta opción está activada, calibre sustituirá los marcadores de cambio de escena con el texto de sustitución especificado por el usuario. Tenga en cuenta que algunos caracteres ornamentales pueden no ser compatibles con todos los dispositivos de lectura.
En general, debería evitar usar etiquetas HTML, calibre ignorará cualquier etiqueta y usará marcas predefinidas. Las etiquetas <hr/> (líneas horizontales) e <img> son excepciones. Las líneas horizontales pueden especificarse también con estilos, si decide incluir un estilo, asegurése de que tenga la opción «width», en caso contrario la información de estilo será ignorada. Las etiquetas de imagen pueden usarse, pero calibre no ofrece la posibilidad de añadir imágenes durante la conversión, esto debe hacerse posteriormente usando la función Modificar libro.
- Ejemplo de etiqueta de imagen (guarda la imagen dentro de la carpeta «Images» dentro del EPUB después de la conversión):
<img style=»width:10%» src=»../Images/scenebreak.png» />
- Ejemplo de barra horizontal con estilos:
<hr style=»width:20%;padding-top: 1px;border-top: 2px ridge black;border-bottom: 2px groove black;»/>
- Eliminar los guiones innecesarios
calibre analizará todo el contenido con guiones en el documento si se activa esta opción. El propio documento se usa como diccionario para el análisis. Esto permite a calibre eliminar guiones en el documento con precisión para cualquier palabra en cualquier idioma, incluso en palabras inventadas u oscuros términos científicos. La principal desventaja es que las palabras que aparezcan una sola vez en el documento no se cambiarán. El análisis tienen lugar en dos pasadas, la primera pasada analiza los finales de línea. Las líneas se unirán sólo si la palabra existe en el documento con o sin guión. La segunda pasada analiza todas las palabras con guión en el documento, los guiones se eliminan si la palabra existe sin guión en algún otro lugar del documento.
- Poner en cursiva palabras y patrones habituales
Si se activa, calibre buscará palabras y patrones habituales que marcan las cursivas, y los pondrá en cursiva. Algunos ejemplos son convenciones comutes de texto com ~palabra~ o frases que generalmente (en inglés) van en cursiva, como «etc.» o «et cetera».
- Sustituir el sangrado mediante caracteres por sangrado CSS
Algunos documentos establecen las sangrías mediante espacios duros. Cuando se activa esta opción, calibre intenta detectar este tipo de formato y lo convierte a una sangría del 3% usando CSS.
Buscar y sustituir¶
Estas opciones son útiles principalmente para la conversión de documentos PDF o de OCR, aunque también pueden utilizarse para solucionar muchos problemas específicos del documento. Por ejemplo, algunas conversiones pueden dejar encabezados y pies de página en el texto. Estas opciones utilizan expresiones regulares para intentar detectar encabezados, pies de página u otro texto arbitrario y eliminarlos o reemplazarlos. Recuerde que operan sobre el XHTML intermedio generado por el proceso de conversión. Hay un asistente para ayudarle a personalizar las expresiones regulares para su documento. Haga clic en la varita mágica junto al cuadro de expresión y, después de crear la expresión de búsqueda, en el botón «Probar». Las coincidencias correctas se resaltarán en amarillo.
La búsqueda funciona utilizando una expresión regular Python. Todo el texto de la coincidencia se elimina del documento o se stituye utilizando el patrón de sustitución. El patrón de sustitución es opcional, si se deja en blanco el texto de la coincidencia se borrará del documento. Puede aprender más acerca de las expresiones regulares y su sintaxis en Todo acerca de cómo utilizar expresiones regulares en calibre.
Detección de estructura¶
La detección de estructura significa que calibre hace lo que puede para detectar elementos estructurales en el documento de entrada, cuando no tienen una especificación apropiada. Por ejemplo, capítulos, saltos de página, encabezados, pies de página, etc. Como puede imaginar, este proceso varía mucho de un libro a otro. Por fortuna, calibre tiene opciones potentes para controlarlo. Con la potencia viene la complejidad, pero si se toma el tiempo de aprender la complejidad, encontrará que bien vale el esfuerzo.
Capítulos y saltos de página¶
Calibre cuenta con dos conjuntos de opciones para la detección de capítulos y la inserción de saltos de página. Esto puede resultar un poco confuso, ya que, por defecto, calibre inserta los saltos de página antes de los capítulos detectados, así como en las ubicaciones detectadas por la opción de saltos de página. Esto se debe a que a menudo hay ubicaciones donde se deben insertar saltos de página que no son los límites de los capítulos. Además, los capítulos detectados se pueden insertar opcionalmente en la tabla de contenido generada automáticamente.
calibre usa XPath, un potente lenguaje que permite al usuario especificar límites de capítulo o saltos de página. XPath puede ser un poco intimidante al principio, pero por suerte existe un Cursillo de XPath en el Manual de usuario. Recuerde que la detección de estructura actúa sobre el XHTML intermedio producido durante el proceso de conversión. Use la opción de depuración descrita en Introducción para deducir la configuración adecuada para un libro concreto. También hay un botón para un asistente de XPath que le ayudará a generar expresiones XPath sencillas.
De manera predeterminada, calibre utiliza la siguiente expresión detectar capítulos:
//*[((name()='h1' or name()='h2') and re:test(., 'chapter|book|section|part\s+', 'i')) or @class = 'chapter']
La expresión es algo compleja, porque intenta tener en cuenta distintos casos comunes simultáneamente. Lo que significa es que calibre supondrá que los capítulos empiezan en etiquetas <h1> o <h2> que contengan alguna de las palabras chapter, book, section o part o que tengan el atributo class=»chapter».
Una opción relacionada es Marca de capítulo, que le permite controlar lo que hace calibre cuando detecta un capítulo. De manera predeterminada, insertará un salto de página antes del capítulo. Puede hacer que inserte una linea horizontal además o en lugar del salto de página. También puede hacer que no haga nada.
La configuración predeterminada para la detección de saltos de página es:
//*[name()='h1' or name()='h2']
lo que significa que, de manera predeterminada, calibre insertará saltos de página antes de cada etiqueta <h1> y <h2>.
Nota
Las expresiones predeterminadas pueden cambiar, dependiendo del formato de entrada de la conversión.
Miscelánea¶
Hay algunas opciones más en esta sección.
- Insertar metadatos en una página al principio del libro
Uno de los mejores detalles de calibre es que permite mantener metadatos muy completos en todos los libros, por ejemplo, una calificación, etiquetas, comentarios, etc. Esta opción creará una página con todos estos metadatos y la insertará en el libro electrónico convertido, normalmente después de la portada. Piénse en ello como una forma de crear una sobrecubierta personalizada.
- Eliminar la primera imagen
Algunas veces, el documento de origen que está convirtiendo incluye la portada como parte del libro, en lugar de como una portada separada. Si además especifica una portada en calibre, el libro convertido tendrá dos portadas. Esta opción simplemente eliminará la primera imagen del documento de origen, asegurando que el libro convertido posea una sola portada, la especificada en calibre.
Índice¶
Cuando el documento de entrada tiene un índice en los metadatos, calibre lo usará sin más. Sin embargo, algunos formatos antiguos no admiten índices basados en metadatos y algunos documentos no lo contienen. En estos casos, las opciones de esta sección pueden ayudarle a generar un índice automáticamente en el libro convertido, basado en el contenido del documento de entrada.
Nota
Puede ser un poco complicado obtener exactamente el resultado correcto con estas opciones. Si prefiere crear o modificar el índice a mano, convierta el libro al formato EPUB o AZW3 y marque la casilla en la parte inferior de la sección Índice del cuadro de dialogo de conversión que dice Ajustar manualmente el índice al finalizar la conversión. Esto ejecutará la herramienta de modificación de índice después de la conversión. Esta herramienta le permite crear entradas en el índice sin más que pulsar en la ubicación del libro adonde quiere que apunte la entrada. También puede usar el Editor del índice sin realizar ninguna conversión. Vaya a Preferencias > Interfaz > Barras de herramientas y añada Modificar el índice a la barra de herramientas principal. Despues seleccione el libro que quiera modificar y pulse en el botón Modificar el índice.
La primera opción es Forzar el uso del índice generado automáticamente. Si activa esta opción calibre reemplazará cualquier índice que encuentre en los metadatos del documento de entrada por uno generado automáticamente.
De manera predeterminada, para la creación automática del índice, calibre comienza añadiendo los capítulos detectados. Puede aprender cómo personalizar la detección de capítulos en la sección Detección de estructura más arriba. Si no quiere incluir los capítulos detectados en el índice generado, marque la opción No añadir capítulos detectados al índice.
Si el número de capítulos detectados es menor que Umbral de capítulos, calibre añadirá los enlaces que encuentre en el documento de entrada al índice. Esto suele funcionar porque muchos documentos incluyen un índice con enlaces al principio. La opción Número de enlaces para añadir al índice puede usarse para controlar este comportamiento. Si se pone a cero, no se añadirá ningún enlace. Si es un número mayor que cero, ése será el número máximo de enlaces que se añada.
calibre filtrará automáticamente duplicados del índice generado. Sin embargo, hay algunas otras entradas que puede querer eliminar del índice, lo que puede conseguir usando la opción Filtro para el índice. Se trata de una expresión regular que se comparará con las entradas del índice generado. Cualquier entrada que coincida se eliminará. Por ejemplo, para eliminar todas las entradas con título «Next» o «Previous» use:
Next|Previous
Las opciones Índice de nivel 1, 2, 3 le permiten crear un índice sofisticado con varios niveles. Son expresiones XPath que se comparan con el XHTML intermedio producido por el proceso de conversión. Vea Introducción para saber cómo acceder a este XHTML. Lea también el Cursillo de XPath para aprender como construir expresiones XPath. Junto a cada opción hay un botón que ejecuta un asistente para ayudarle a crear expresiones XPath básicas. El siguiente ejemplo sencillo muestra cómo usar estas opciones.
Supongamos que tiene un documento de entrada que da como resultado XHTML que se ve así:
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<title>Sample document</title>
</head>
<body>
<h1>Chapter 1</h1>
...
<h2>Section 1.1</h2>
...
<h2>Section 1.2</h2>
...
<h1>Chapter 2</h1>
...
<h2>Section 2.1</h2>
...
</body>
</html>
Entonces configuramos las opciones como:
Level 1 TOC : //h:h1
Level 2 TOC : //h:h2
Esto dará lugar a un índice de dos niveles generado automáticamente que tendrá esta estructura:
Chapter 1
Section 1.1
Section 1.2
Chapter 2
Section 2.1
Advertencia
No todos los formatos de salida admiten un índice con varios niveles. Pruebe primer con el formato de salida EPUB. Si funciona, intente con su formato de elección.
Usar imágenes como títulos de capítulo al convertir documentos de entrada HTML¶
Supongamos que quiere utilizar una imagen como título de capítulo, pero también desea que calibre pueda generar automáticamente un índice a partir de los títulos de capítulo. Use el siguiente código HTML para lograrlo:
<html>
<body>
<h2>Chapter 1</h2>
<p>chapter 1 text...</p>
<h2 title="Chapter 2"><img src="chapter2.jpg" /></h2>
<p>chapter 2 text...</p>
</body>
</html>
Configure Primer nivel del índice como //h:h2. Entonces, para el capítulo dos, calibre tomará el título del valor del atributo title de la etiqueta <h2>, dado que ésta no posee texto.
Usar atributos de etiquetas para suministrar el texto de las entradas del índice¶
Si los capítulos tienen títulos especialmente largos y quiere versiones más cortas en el Índice, puede usar el atributo «title» para ello, por ejemplo:
<html>
<body>
<h2 title="Chapter 1">Chapter 1: Some very long title</h2>
<p>chapter 1 text...</p>
<h2 title="Chapter 2">Chapter 2: Some other very long title</h2>
<p>chapter 2 text...</p>
</body>
</html>
Establezca la opción Índice de nivel 1 en //h:h2/@title. Entonces calibre tomará el título a partir del valor del atributo title de las etiquetas <h2>, en lugar de usar el texto dentro de la etiqueta. Fíjese en la terminación /@title de la expresión XPath, puede usar esta forma para indicarle a calibre que tome el texto del atributo que desee.
Cómo se establecen y guardan las opciones de conversión¶
Existe dos lugares donde en calibre donde se pueden especificar las opciones de conversión. El primer es en :guilabel!`Preferencias > Conversión`. Estos valores son los predeterminados para las opciones de conversión. Cada vez que intente convertir un nuevo libro, las opciones especificadas aquí serán las predeterminadas.
También puede modificar la configuración en el cuadro de diálogo de conversión para cada libro. Cuando convierte un libro, calibre recuerda la configuración que usó para ese libro, de manera que si vuelve a convertirlo, la configuración almacenada tendrá prioridad sobre la predeterminada en las Preferencias. Puede restablecer la configuración individual a la predeterminada usando el botón Restaurar valores predeterminados en el cuadro de diálogo de conversión individual. Puede eliminar las configuraciones almacenadas para un grupo de libros seleccionando los libros y pulsando el botón Modificar metadatos para mostrar el cuadro de diálogo de modificar metadatos en masa, en la parte inferior hay una opción para eliminar las configuraciones de conversión guardadas.
Al convertir en masa un conjunto de libros, las configuraciones se toman en el siguiente orden (el último prevalece):
De la configuración predeterminada en Preferencias > Conversión
A partir de las opciones de conversión guardadas para cada libro que se convierte (si existen). Esto puede desactivarse con la opción en la parte superior izquierda del cuadro de diálogo de conversión en masa.
De la configuración establecida en el cuadro de diálogo Convertir en masa
Tenga en cuenta que las configuraciones finales para cada libro en una conversión en masa se guardarán y se volverán a usar si el libro se convierte de nuevo. Puesto que en una conversión en masa se da máxima prioridad a las configuraciones especificadas en el cuadro de diálogo, éstas reemplazaran cualquier configuración específica de un libro. Las excepciones son los metadatos y las configuraciones específicas de formatos de entrada. El cuadro de diálogo de conversión en masa no tiene configuraciones para estas dos categorías, así que se tomarán de las configuraciones específicas de cada libro (si existen) o de las predeterminadas.
Nota
Puede ver las opciones usadas realmente en la conversión pulsando sobre el icono rotatorio en la esquina inferior derecha y luego pulsando dos veces sobre cada tarea de conversión. Esto mostrará un registro de conversión que contiene las opciones usadas finalmente, en la parte superior.
Consejos para formatos específicos¶
Aquí encontrará consejos específicos para la conversión de formatos particulares. En el cuadro de diálogo de conversión hay opciones específicas para cada formato, ya sea de entrada o salida, en su propia sección, por ejemplo Entrada TXT o Salida EPUB.
Convertir documentos de Microsoft Word¶
calibre puede convertir automáticamente archivos .docx creados por Microsoft Word 2007 y versiones posteriores. Sólo tiene que añadir el archivo a calibre y pulsar en Convertir.
Nota
Hay un archivo .docx de demostración que muestra las capacidades del motor de conversión de calibre. Descárguelo y conviértalo a EPUB o AZW3 para ver lo que calibre puede hacer.
calibre generará automáticamente un índice basado en las cabeceras si éstas están marcadas con los estilos de Microsoft Word Título 1, Título 2, etc. Abra el libro resultante en el visor de calibre y pulse el botón de Índice para ver el índice generado.
Archivos .doc antiguos¶
Para los archivos .doc más antiguos, puede guardar el documento como HTML con Microsoft Word y luego convertir el HTML resultante con calibre. Al guardar como HTML, asegúrese de usar la opción «Guardar como página web, filtrada», ya que esto producirá un HTML más limpio que se convertirá mejor. Tenga en cuenta que Word produce un HTML realmente intrincado, y convertirlo puede llevar tiempo, así que sea paciente. Si tiene disponible una versión de Word más reciente, también puede guardarlo directamente como .docx.
Otra posibilidad es utilizar el paquete ofimático libre LibreOffice. Abra el archivo .doc en LibreOffice y guárdelo como .docx., que calibre puede convertir directamente.
Convertir documentos TXT¶
Los documentos TXT no tienen una manera definida de especificar formato como cursiva, negrita, etc., o estructura del documento com párrafos, cabeceras, secciones y demás, pero existen varias convenciones usadas normalmente. De manera predeterminada calibre intenta detectar automáticamente el formato y marcado correcto basándose en estas convenciones.
La entrada TXT admite una serie de opciones para distinguir cómo se detectan los párrafos.
- Estilo de párrafo: auto
Analiza el archivo de texto e intenta determinar automáticamente cómo están definidos los párrafos. Esta opción generalmente funcionará bien, si no obtiene resultados satisfactorios pruebe con las opciones manuales.
- Estilo de párrafo: block
Asume que los párrafos están separados por una o más líneas en blanco:
This is the first. This is the second paragraph.- Estilo de párrafo: single
Asume que cada línea es un párrafo:
This is the first. This is the second. This is the third.- Estilo de párrafo: print
Asume que cada párrafo se inicia con una sangría (ya sea una tabulación o más de un espacio). Los párrafos terminan cuando se alcanza la siguiente línea que empieza con una sangría:
This is the first. This is the second. This is the third.- Estilo de párrafo: unformatted
Asume que el documento no posee formato, pero usa saltos de línea forzados. La puntuación y la mediana de la longitud de renglón se emplean para intentar restaurr los párrafos.
- Estilo de formato: auto
Intenta detectar el tipo de marcado de formato que se emplea. Si no se encuentra uno, se aplicará el formato heurístico.
- Estilo de formato: heuristic
Analiza el documento para detectar cabeceras de capítulo comunes, cambios de escena y palabras en cursiva, y aplica las etiquetas HTML adecuadas durante la conversión.
- Estilo de formato: markdown
calibre también admite pasar la entrada TXT por un preprocesador llamado Markdown. Markdown permite añadir formato básico a documentos TXT, como negritas, cursivas, encadezados de secciones, tablas, listas, índice, etc. La manera más sencilla de obtener un índice a partir de un documento TXT es marcar las cabeceras de capítulo con «#» y establecer la expresión XPath para detección de capítulos en «//h:h1». Puede aprender más sobre la sintaxis Markdown en daringfireball (en inglés).
- Estilo de formato: none
No aplica ningún formato especial al texto, el documento se convierte a HTML sin ningún otro cambio.
Convertir documentos PDF¶
Los documentos PDF son uno de los peores orígenes para la conversión. Se trata de un formato con tamaño de página y posición de texto fijos. Esto significa que es muy difícil determinar dónde acaba un párrafo y empieza el siguiente. calibre intentará unir los párrafos usando un Factor de unión de líneas configurable. Esto es una escala usada para determinar la longitud requerida para unir los renglones. Los valores válidos son decimales entre 0 y 1. El valor predeterminado es 0,45, algo por debajo de la longitud de renglón mediana. Reduzca el valor para incluir más texto en la unión, auméntelo para incluir menos. Puede ajustar este valor en las opciones de conversión bajo Entrada PDF.
Además, muchas veces tienen encabezados y pies de página como parte del documento, que aparece incluido con el texto. Use el panel de Buscar y sustituir para eliminar encabezados y pies de página y solucionar este problema. Si los encabezados y pies de página no se eliminan del texto pueden afectar a la unión de párrafos. Para aprender cómo usar las opciones de eliminación de encabezados y pies de página, vea Todo acerca de cómo utilizar expresiones regulares en calibre.
Algunas limitaciones de la entrada de PDF son:
No soporta documentos complejos, con columnas múltiples o basados en imágenes.
Tampoco soporta la extracción de imágenes vectoriales y tablas incluidos en el documento.
Algunos PDF usan glifos especiales para representar «ll», «ff», «fi», etc. La conversión de éstos puede o no funcionar dependiendo de cómo se representant internamente en el PDF.
No soporta enlaces e índices
Los PDF que utilizan tipos de letra incrustados que no son Unicode para representar caracteres no ingleses darán un resultado incorrecto para dichos caracteres
Algunos PDF están hechos de fotografías de la página con el texto resultante del OCR (reconocimiento óptico de caracteres) oculto tras la imagen. En tales casos calibre utiliza el texto del OCR, que puede ser muy diferente de lo que se ve al visualizar el archivo PDF
Los PDF usados para mostrar texto complejo, como idiomas que se leen de derecha a izquierda y expresiones matemáticas, no se convertirán correctamente
Insisto, PDF es un formato muy, muy malo para usarlo como entrada. Si de todas formas tiene que usar PDF, esté preparado para obtener una salida entre decente e inservible, según cómo sea el PDF de entrada.
Colecciones de libros de historietas¶
Una colección de libros de historietas es un archivo .cbc. Un archivo .cbc es un archivo ZIP que contiene otros archivos CBZ o CBR. Además el archivo .cbc debe contener un archivo de texto llamado comics.txt, codificado en UTF-8. El archivo comics.txt debe contener un listado de los archivos de historieta dentro del archivo .cbc, de la forma nombredearchivo:titulo, como se muestra a continuación:
one.cbz:Chapter One
two.cbz:Chapter Two
three.cbz:Chapter Three
El archivo .cbc contendrá:
comics.txt
one.cbz
two.cbz
three.cbz
calibre convertirá automáticamente este archivo .cbc en un libro electrónico con una tabla de contenido que apunta a cada entrada en comics.txt.
EPUB de demostración de formato avanzado¶
Algunos formatos avanzados para archivos EPUB se muestran en este archivo de demostración. Este archivo ha sido creado a partir de HTML codificado manualmente con calibre, y está destinado a servir como plantilla para crear otros EPUB.
El archivo HTML que se usó par crearlo está disponible demo.zip. La configuración usada para crear el EPUB a partir del archivo ZIP es:
ebook-convert demo.zip .epub -vv --authors "Kovid Goyal" --language en --level1-toc '//*[@class="title"]' --disable-font-rescaling --page-breaks-before / --no-default-epub-cover
Tenga en cuenta que debido a que este archivo explora el potencial del formato EPUB, la mayor parte del formato avanzado no va a funcionar en lectores menos capacitados que el visor incorporado de calibre.
Convertir documentos ODT¶
calibre puede convertir directamente archivos ODT (OpenDocument Text). Es recomendable que use estilos para dar formato al documento, manteniendo al mínimo el uso de formato directo. Al insertar imágenes en el documento debe anclarlas al párrafo. Las imágenes ancladas a la página acabarán todas al inicio de la conversión.
Para permitir la detección automática de capítulos, debe marcarlos con los estilos incorporados llamados Encabezado 1, Encabezado 2, …, Encabezado 6 (Encabezado 1 equivale a la etiqueta HTML <h1>, Encabezado 2 a <h2>, etc.). Cuando convierta en calibre puede indicar qué estilo ha usado en el cuadro Detectar capítulos en. Ejemplo:
Si ha marcado los capítulos con estilo Encabezado 2, debe establecer :guilabel`Detectar capítulos en` como
//h:h2Para obtener un índice anidado con las secciones marcadas con Encabezado 2 y los capítulos con Encabezado 3, tendrá que introducir
//h:h2|//h:h3. En el apartado Índice del cuadro de diálogo de conversión ponga//h:h2en Primer nivel del índice y//h:h3en Segundo nivel del índice.
Se reconocen las propiedades conocidas del documento (título, palabras clave, descripción, creador) y calibre utilizará la primera imagen (no demasiado pequeña y con una buena relación de aspecto) como imagen de portada.
También hay modo avanzado de conversión de propiedades, que se activa estableciendo la propiedad personalizada opf.metadata (de tipo «Sí o no») en Sí en el documento ODT (Archivo > Propiedades > Propiedades personalizadas). Si calibre detecta esta popiedad, se reconocen las siguientes propiedades personalizadas (opf.authors sustituye al creador del documento):
opf.titlesort
opf.authors
opf.authorsort
opf.publisher
opf.pubdate
opf.isbn
opf.language
opf.series
opf.seriesindex
Además de esto, puede especificar la imagen que se usará como portada dándole el nombre opf.cover (pulse con el botón derecho, Imagen > Opciones > Nombre) en el ODT. Si no se encuentra una imagen con este nombre, se usa el método «inteligente». Como la detección de portada puede dar lugar a doble portada en algunos formatos, el proceso eliminará el párrafo (sólo si su único contenido es la imagen) del documento. ¡Pero esto sólo funciona con la imagen con nombre!
Para deshabilitar la detección de portadas puede establecer la propiedad personalizada opf.nocover (de tipo «sí o no») en Yes en el modo avanzado.
Convertir a PDF¶
La primera y más importante decisión al convertir a PDF es el tamaño de página. De manera predeterminada, calibre usa una página de tamaño «carta norteamericana». Puede cambiarlo a cualquier otro tamaño usual o personalizado en la sección Salida PDF del cuadro de diálogo de conversión. Si va a generar un PDF para usarlo en un dispositivo específico, puede activar la opción para usar el tamaño de página del perfil de salida en su lugar. De esta forma, si el perfil de salida es Kindle, calibre creará un PDF con un tamaño de página adecuado para una pantalla de Kindle.
Índice imprimible¶
También puede incluir un índice imprimible al final del PDF que muestra los números de página de cada sección. Esto es muy útil si va a imprir el PDF en papel. Si va a usar el PDF en un dispositivo electrónico, el Esquema del PDF cumple esta función y se genera de manera predeterminada.
Se puede personalizar el aspecto de los índices generados usando la opción CSS adicional en la sección Apariencia del cuadro de diálogo de conversión. El código CSS usado de manera predeterminada se muestra debajo, cópielo y modifíquelo a su gusto.
.calibre-pdf-toc table { width: 100%% }
.calibre-pdf-toc table tr td:last-of-type { text-align: right }
.calibre-pdf-toc .level-0 {
font-size: larger;
}
.calibre-pdf-toc .level-1 td:first-of-type { padding-left: 1.4em }
.calibre-pdf-toc .level-2 td:first-of-type { padding-left: 2.8em }
Márgenes de página específicos para archivos HTML individuales¶
Si está convirtiendo un archivo EPUB o AZW3 que contiene varios archivos HTML y quiere cambiar los márgenes de página de un archivo HTML concreto, puede añadir el siguiente bloque de estilo al archivo HTML usando el editor de libros electrónicos de calibre:
<style>
@page {
margin-left: 10pt;
margin-right: 10pt;
margin-top: 10pt;
margin-bottom: 10pt;
}
</style>
Después en la sección de salida PDF del cuadro de diálogo de conversión, desactive la opción Usar los márgenes de página del documento de origen. Ahora todas las páginas generadas a partir de este archivo HTML tendrán márgenes de 10pt.