 Ändra språk
Ändra språkKonvertering av e-bok¶
calibre har ett konverteringssystem som är utmatningsformat för att vara mycket lätt att använda. Normalt lägger du bara till en bok till calibre, klicka på konvertera och calibre kommer att försöka skapa utmatning som är så nära inmatningen som möjligt. calibre accepterar dock ett mycket stort antal inmatningsformat, som inte alla som är lika lämpliga som andra för konvertering till e-böcker. När det gäller sådana inmatningsformat, eller om du bara vill ha större kontroll över konverteringssystemet, har calibre en hel del alternativ för att finjustera konverteringen. Observera dock att calibres konverteringssystem inte är en ersättning för en komplett e-bokredigerare. För att redigera e-böcker rekommenderar jag att du först konverterar dem till EPUB eller AZW3 med calibre och sedan använder funktionen Redigera bok för att få dem i perfekt form. Du kan sedan använda den redigerade e-boken som inmatning för konvertering till andra format i calibre.
Det här dokumentet kommer huvudsakligen att hänvisa till konverteringsinställningarna som finns i konverteringsdialogrutan, på bilden nedan. Alla dessa inställningar är även tillgängliga via kommandoradsgränssnittet för konvertering, dokumenterat i ebook-convert. I calibre kan du få hjälp med vilken enskild inställning som helst genom att hålla muspekaren över den, ett verktygstips kommer att visas som beskriver inställningen.
Introduktion¶
Det första att förstå om konverteringssystemet är att det är utformat som en process. Schematiskt ser det ut så här:
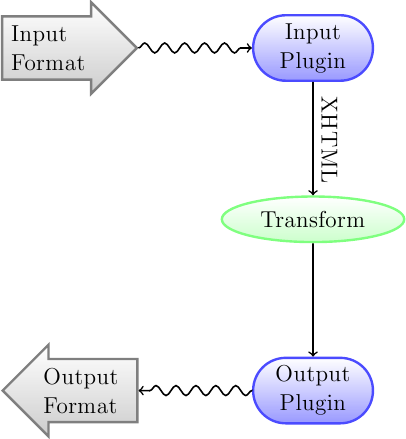
Inmatningsformatet konverteras först till XHTML med lämplig inmatningsinsticksmodul. Denna HTML omvandlas I det sista steget konverteras den bearbetade XHTML-en till det angivna utmatningsformatet med lämplig utmatningsinsticksmodul. Resultaten av konverteringen kan variera kraftigt, beroende på inmatningsformatet. Vissa format konverteras mycket bättre än andra. En lista med de bästa källformaten för konvertering finns här.
Omvandlingarna som verkar på XHTML-utmatningen är där allt arbete sker. Det finns olika omvandlingar, till exempel för att infoga bokens metadata som en sida i början av boken, för att upptäcka kapitelrubriker och automatiskt skapa en innehållsförteckning, för att proportionellt justera teckensnittsstorlekar, och så vidare. Det är viktigt att minnas att alla omvandlingar verkar på XHTML-utmatning av inmatningsinsticksmodulen, inte på själva inmatningsfilen. Så, till exempel, om du ber calibre att konvertera en RTF-fil till EPUB, kommer den först att konverteras till XHTML internt, de olika omvandlingarna kommer att tillämpas på XHTML och sedan kommer itmatningsinsticksmodulen att skapa EPUB-filen, vilket automatiskt skapar alla metadata, innehållsförteckning, och så vidare.
Du kan se den här processen i aktion genom att använda felsökningsalternativet  . Ange bara sökvägen till en mapp för felsökningsutmatning. Under konverteringen kommer calibre att placera XHTML som genereras av de olika stegen i konverteringsprocessen i olika undermappar. De fyra undermapparna är:
. Ange bara sökvägen till en mapp för felsökningsutmatning. Under konverteringen kommer calibre att placera XHTML som genereras av de olika stegen i konverteringsprocessen i olika undermappar. De fyra undermapparna är:
Mapp |
Beskrivning |
|---|---|
inmatning |
Den innehåller HTML-utmatning från inmatningsinsticksmodulen. Använd detta för att felsöka inmatningsinsticksmodulen. |
analyserad |
Resultatet av förbehandling och konvertering till XHTML-utmatning från inmatningsinsticksmodulen. Används för att felsöka strukturdetektering. |
struktur |
Efterstrukturell detektering, men innan CSS-utplattning och teckensnittsstorlekskonvertering. Används för att felsöka teckensnittsstorlekskonvertering och CSS-omvandlingar. |
bearbetad |
Precis innan e-boken passerar till Utmatningsinsticksmodulen. Används för att felsöka Utmatningsinsticksmodulen. |
Om du vill redigera inmatningsdokumentet lite innan calibre konverterar det, är det bästa att göra redigera filerna i input undermapp och sedan packa upp och använda ZIP-filen som inmatningsformat för efterföljande konverteringar. För att göra detta använder Edit meta information dialogrutan för att lägga ZIP-filen som ett format för boken och sedan, i det övre vänstra hörnet i konverteringsdialogrutan väljer ZIP som inmatningsformat.
Det här dokumentet kommer huvudsakligen att behandla de olika omvandlingarna som fungerar på mellanliggande XHTML och hur man anpassar dem. I slutet finns några tips som är specifika för varje in-/utmatningsformat.
Utseende & känsla¶
Denna grupp av alternativ anpassar olika aspekter av utseendet och känslan av den konverterade e-boken.
Teckensnitt¶
En av de trevligaste funktionerna med e-läsningsupplevelsen är möjligheten att enkelt justera teckenstorlekar för att passa individuella behov och ljusförhållanden. calibre har sofistikerade algoritmer för att säkerställa att alla böcker som matas ut har konsekventa teckenstorlekar, oavsett vilka teckenstorlekar som anges i inmatningsdokumentet.
Grundteckensnittsstorleken för ett dokument är den vanligaste teckensnittsstorleken i det dokumentet, dvs. storleken på den största delen av texten i dokumentet. När du anger en Grundteckensnittsstorlek, skalar calibre automatiskt om alla teckensnittsstorlekar i dokumentet proportionellt, så att den vanligaste teckensnittsstorleken blir den angivna grundteckensnittsstorleken och andra teckensnittsstorlekar skalas på lämpligt sätt. Genom att välja en större grundteckensnittsstorlek kan du göra teckensnitten i dokumentet större och vice versa. När du ställer in grundteckensnittsstorleken, för bästa resultat, bör du också ställa in teckensnittsstorleksnyckeln.
Normalt väljer calibre automatiskt en grundteckensnittsstorlek som är lämplig för utmatningsprofilen du har valt (se Sidinställning). Du kan dock åsidosätta detta här om standardvärdet inte är lämplig för dig.
Med alternativet Teckensnittsstorleksnyckel kan du anpassa hur icke-grundteckensnittsstorlekar skalas om. Teckensnittets omskalningsalgoritm fungerar med hjälp av en teckensnittsstorleksnyckel, vilket helt enkelt är en kommaseparerad lista över teckensnittsstorlekar. Teckensnittsstorleksnyckel anger för calibre hur många ”steg” större eller mindre en given teckensnittsstorlek bör jämföras med grundteckensnittsstorleken. Tanken är att det ska finnas ett begränsat antal teckensnittsstorlekar i ett dokument. Till exempel en storlek för huvudtext, ett par storlekar för olika nivåer av rubriker och ett par storlekar för upphöjd/nersänkt teckensnitt och fotnoter. Teckensnittsstorleksnyckeln tillåter calibre att dela upp de teckensnittsstorlekar i inmatningsdokumenten i separata ”fack” som motsvarar de olika logiska teckensnittsstorlekarna.
Låt oss illustrera med ett exempel. Antag att källdokumentet vi konverterar producerades av någon med utmärkt syn och har en grundteckensnittsstorlek på 8 punkter. Det innebär att huvuddelen av texten i dokumentet är dimensionerad för 8 punkter medan rubriker är något större (säg 10 och 12 punkter) och fotnoter något mindre på 6 punkter. Nu om vi använder följande inställningar:
Base font size : 12pt
Font size key : 7, 8, 10, 12, 14, 16, 18, 20
Utmatningsdokumentet kommer att ha en grundteckensnittsstorlek på 12 punkter, rubrikerna 14 och 16 punkter och fotnoter 8 punkter. Anta nu att vi vill göra att den största rubrikstorleken sticker ut mer och göra fotnoter lite större också. För att uppnå detta bör teckensnittsnyckeln ändras till:
New font size key : 7, 9, 12, 14, 18, 20, 22
De största rubrikerna blir nu 18 punkter, medan sidnoter blir 9 punkter. Du kan spela med dessa inställningar för att försöka lista ut vad som skulle vara optimalt för dig med hjälp av tecken omskalningsguiden som kan nås genom att klicka på den lilla knappen bredvid Teckensnittsstorleksnyckel.
Alla omskalningar av teckensnittsstorleken i konverteringen kan även stängas av här, om du vill bevara teckensnittsstorlekar i inmatningsdokumentet.
En relaterad inställning är Radavstånd. Radavstånd styr den vertikala höjden på raderna. Som standard utför (ett radavstånd av 0) ingen manipulation av radavstånd. Om du anger ett icke-standardvärde, kommer radavstånd ställas in på alla platser som inte anger sina egna radavstånd. Det här är dock något av ett trubbigt vapen och bör användas sparsamt. Om du vill justera radavstånd för vissa avsnitt av inmatning, är det bättre att använda Extra CSS.
I det här avsnittet kan du också berätta för calibre att bädda in några refererade teckensnitt i boken. Detta gör det möjligt för teckensnitten att fungera på läsarenheter, även om de inte är tillgängliga på enheten.
Text¶
Text kan antingen justeras eller inte. Justerad text har extra blanksteg mellan ord för att ge en jämn högermarginal. Vissa människor föredrar justerad text, andra gör det inte. Normalt kommer calibre bevara justeringen i originaldokuemtet. Om du vill åsidosätta det kan du använda alternativet Textjustering i det här avsnittet.
Du kan också be calibre att Förbättra skiljeteckenhantering vilket kommer att ersätta vanliga citattecken, bindestreck och ellipser med deras typografiskt korrekta alternativ. Observera att den här algoritmen inte är perfekt så det är värt att granska resultaten. Det omvända, Avförbättra skiljeteckenhantering, är också tillgänglig.
Slutligen finns det Inmatningsteckenkodning. Äldre dokument anger ibland inte deras teckenkodning. Vid konvertering kan detta leda till att icke-engelska tecken eller specialtecken som typografiska citattecken skadas. calibre försöker att automatiskt upptäcka källdokumentets teckenkodning, men det lyckas inte alltid. Du kan tvinga den att anta en viss teckenkodning med den här inställningen. cp1252 är en vanlig kodning för dokument som produceras med Windows-programvara. Du bör också läsa Hur konverterar jag min fil som innehåller icke-engelska tecken eller typografiska citattecken? för mer om kodningsfrågor.
Layout¶
Normalt återges stycken i XHTML med en blnakrad mellan dem och inget inledande textindrag. calibre har ett par alternativ för att anpassa detta. Ta bort avstånd mellan stycken ser till att alla stycken inte har något avstånd mellan stycken. Den ställer också in textindraget till 1.5em (kan ändras) för att markera början på varje stycke. Infoga tom rad gör det motsatta och garanterar att det finns exakt en tom rad mellan varje par av stycken. Båda dessa alternativ är mycket omfattande, tar bort avstånd eller infogar det för alla stycken (tekniska <p>- och <div>-taggar). Detta är så att du bara kan ställa in alternativet och vara säker på att den fungerar som utlovat, oavsett hur rörig inmatningsfilen är. Det enda undantaget är när inmatningsfilen använder hårda radbrytningar för att implementera avstånd mellan stycken.
Om du vill ta bort avstånd mellan alla stycken, förutom några få utvalda, använd inte dessa alternativ. Lägg istället till följande CSS-kod i Extra CSS:
p, div { margin: 0pt; border: 0pt; text-indent: 1.5em }
.spacious { margin-bottom: 1em; text-indent: 0pt; }
Markera sedan styckena i ditt källdokument som behöver avstånd med class=”spacious”. Om ditt inmatningsdokument inte är i HTML, använd alternativet Felsökning, som beskrivs i inledningen för att hämta HTML (använd undermappen input).
Ett annat användbart alternativ är Linearisera tabeller. Vissa dåligt utformade dokument använder tabeller för att styra textlayouten på sidan. När dessa dokument konverteras har de ofta text som löper utanför sidan och andra artefakter. Det här alternativet extraherar innehållet från tabellerna och presenterar det linjärt. Observera att det här alternativet linjäriserar alla tabeller, så använd det bara om du är säker på att inmatningsdokumentet inte använder tabeller för legitima syften, som att presentera tabellinformation.
Formgivning¶
Alternativet Extra CSS låter dig ange godtycklig CSS som kommer att tillämpas på alla HTML-filer i inmatningen. Denna CSS appliceras med mycket hög prioritet och bör åsidosätta de flesta CSS närvarande i själva inmatningsdokumentet. Du kan använda denna inställning för att finjustera presentation/utformningen av ditt dokument. Till exempel om du vill att alla stycken i klassen slutnotering att vara högerställda, lägg bara till:
.endnote { text-align: right }
eller om du vill ändra indraget för alla stycken:
p { text-indent: 5mm; }
Extra CSS är ett mycket kraftfullt alternativ, men du behöver en förståelse för hur CSS fungerar för att använda den till sin fulla potential. Du kan använda alternativet felsök processalternativet som beskrivs ovan för att se vad CSS finns i ditt inmatningsdokument.
Ett enklare alternativ är att använda Filtrera formatinformation. Det här låter dig ta bort alla CSS-egenskaper för de angivna typerna från dokumentet. Du kan till exempel använda den för att ta bort alla färger eller teckensnitt.
Omvandla format¶
Detta är den mest kraftfulla formatrelaterade bekvämligheten. Du kan använda den för att definiera regler som ändrar format baserat på olika villkor. Till exempel kan du använda den för att ändra alla gröna färger till blåa, eller ta bort alla feta stilar från text eller färga alla rubriker en viss färg, etc.
Omvandla HTML¶
Liknar att omvandla format, men låter dig göra ändringar i HTML-innehållet i boken. Du kan ersätta en tagg med en annan, lägga till klasser eller andra attribut till taggar baserat på deras innehåll, etc.
Sidinställning¶
Alternativen för sidinställningar är till för att anpassa skärmutformning, som marginaler och skärmstorlekar. Det finns alternativ till sidmarginalsinställningar, som kommer att användas av utmatning insticksmodulen, om det valda utmatningsformatet stödjer sidmarginaler. Dessutom bör du välja en inmatningsprofil och en utskriftsprofil. Båda uppsättningarna av profiler i princip behandlar hur man ska tolka mått i dokumentets inmatning/utmatning, skärmstorlekar och standardteckensnitts omskalningsnycklar.
Om du vet att filen du konverterar var avsedd att användas på en viss enhet/mjukvaruplattform väljer du motsvarande inmatningsprofil, annars väljer du bara standardinmatningsprofilen. Om du vet att filerna du producerar är avsedda för en viss enhetstyp väljer du motsvarande utmatningsprofil. Annars väljer du en av de generiska utmatningsprofilerna. Om du konverterar till MOBI eller AZW3 vill du nästan alltid välja en av Kindle-utmatningsprofilerna. Annars är det bästa alternativet för moderna e-bokläsenheterna att välja utmatningsprofilen Generisk e-bläck HD.
Utmatningsprofilen styr även skärmstorleken. Detta kommer att orsaka, till exempel bilder som automatiskt storleksändras vara tjänliga till skärmen i vissa utmatningsformat. Så välj en profil av en enhet som har en skärmstorlek som liknar din enhet.
Heuristisk bearbetning¶
Heuristisk bearbetning erbjuder en mängd olika funktioner som kan användas för att försöka upptäcka och åtgärda vanliga problem i dåligt formaterade inmatningsdokument. Använd dessa funktioner om ditt inmatningsdokument lider av dålig formatering. Eftersom dessa funktioner är beroende av gemensamma mönster, var medveten om att ett alternativ i vissa fall kan leda till sämre resultat, så använd med försiktighet. Som ett exempel, kommer flera av dessa alternativ ta bort alla icke-blankstegsbrytande enheter, eller kan innefatta falska positiva resultat avseende funktionen.
- Aktivera heuristisk bearbetning
Det här alternativet aktiverar calibres :guilabel:`heuristiska bearbetnings`steg för konverteringsprocessen. Det här måste vara aktiverat för att olika underfunktioner ska kunna tillämpas
- Radbrytningar
Aktivering av det här alternativet gör att calibre försöker upptäcka och korrigera hårda radbrytningar som finns i ett dokument med ledtrådar som skiljetecken och radlängd. calibre försöker först att upptäcka om hårda radbrytningar finns, om de inte verkar finnas kommer calibre inte att försöka att bryta rader. Radbrytningsfaktorn kan minskas om man vill ”tvinga” calibre att bryta rader.
- Faktor för radbrytningar
Det här alternativet styr algoritmen calibre använder för att ta bort hårda radbrytningar. Till exempel, om värdet av det här alternativet är 0,4, innebär det att calibre tar bort hårda radbrytningar från slutet av rader vars längd är mindre än längden på 40% av alla rader i dokumentet. Om ditt dokument bara har några radbrytningar som behöver korrigering, bör detta värde minskas till någonstans mellan 0,1 och 0,2.
- Identifiera och markera oformaterade kapitelrubriker och underrubriker
Om ditt dokument inte har kapitelrubriker och titlar formaterade annorlunda än resten av texten kan calibre använda det här alternativet för att försöka upptäcka dem och omge dem med rubriktaggar. <h2>taggar används för kapitelrubriker; <h3>taggar används för eventuella titlar som upptäcks.
Den här funktionen skapar inte en innehållsförteckning, men i många fall kommer den att orsaka calibres standardinställningar för kapiteldetektering att korrekt detektera kapitel och bygga en innehållsförteckning. Justera XPath under Strukturdetektering om en innehållsförteckning inte skapas automatiskt. Om det inte finns några andra rubriker i dokumentet skulle det vara det enklaste sättet att skapa en innehållsförteckning för dokumentet att ställa in ”//h:h2” under strukturdetektering.
De insatta rubriker är inte formaterad, för att tillämpa formatering använd Extra CSS alternativet under konverteringsinställningar under Utseende och känsla. Till exempel för att centrera rubriktaggar, använd följande:
h2, h3 { text-align: center }
- Numrera om sekvenser av <h1> eller <h2> taggar
Vissa utgivare formaterar kapitelrubriker som använder flera <h1> eller <h2> taggar sekventiellt. calibres standardkonverteringsinställningar kommer orsaka att sådana titlar delas upp i två delar. Det här alternativet kommer att numrera rubriktaggarna för att undvika delning.
- Ta bort tomma rader mellan stycken
Detta alternativ gör att calibre analyserar tomma rader som ingår i dokumentet. Om varje stycke är sammanflätat med en tom rad, tar calibre bort alla de tomma styckena. Sekvenser av flera tomma rader betraktas som scenbrytningar och behålls som ett enda stycke. Det här alternativet skiljer sig från alternativet Ta bort avstånd mellan stycken under Utseende och känsla genom att det faktiskt ändrar HTML-innehållet, medan det andra alternativet ändrar dokumentformaten. Det här alternativet kan också ta bort stycken som infogades med calibres alternativ Infoga tom rad.
- Se till att scenavbrytning är konsekvent formaterade
Med det här alternativet kommer calibre att försöka upptäcka vanliga scen-brytmarkörer och se till att de är centrerad. ”Mjuka” scenavbrytningsmarkörer, dvs. scenavbrytning definieras endast av extra tomrum, är utformade för att säkerställa att de inte kommer att visas i samband med sidbrytningar.
- Ersätta scenbrytningar
Om det här alternativet är anpassat kommer calibre att ersätta scenbrytningsmarkörer som den hittar med den ersättningstext som användaren angett. Observera att vissa prydnadstecken kanske inte stöds på alla läsenheter.
I allmänhet bör du undvika att använda HTML-taggar, calibre kommer att bortse från alla taggar och använda fördefinierad markering. <hr /> taggar, dvs. horisontella regler och <img> taggar är undantag. Horisontella regler kan valfritt anges med format, om du väljer att lägga till ditt eget format måste du inkludera inställningen ”width”, annars kommer formatinformationen att kasseras. Bildtaggar kan användas, men calibre ger inte möjlighet att lägga till bilden under konvertering, detta måste göras efter att ha använt funktionen ”Redigera bok”.
- Exempel bildtagg (placera bilden i en ”Images”-mapp inne i EPUB:en efter konvertering):
<img style=”width:10%” src=”../Images/scenebreak.png” />
- Exempel horisontell linje med format:
<hr style=”width:20%;padding-top: 1px;border-top: 2px ridge black;border-bottom: 2px groove black;”/>
- Ta bort onödiga bindestreck
calibre analyserar allt bindestreckinnehåll i dokumentet när detta alternativ är aktiverat. Själva dokumentet används som en ordbok för analys. Detta gör det möjligt för calibre att noggrant ta bort bindestreck för alla ord i dokumentet på vilket språk som helst, tillsammans med påhittade och dunkla vetenskapliga ord. Den främsta nackdelen är att ord som bara visas en gång i dokumentet inte kommer att ändras. Analys sker i två pass, det första passet analyserar radslut. Rader bryts endast om ordet finns med eller utan bindestreck i dokumentet. Det andra passet analyserar alla ord med bindestreck i hela dokumentet, bindestreck tas bort om ordet finns någon annanstans i dokumentet utan matchning.
- Kursivera vanliga ord och mönster
När det är aktiverat kommer calibre att leta efter vanliga ord och mönster som betecknar kursiv stil och kursiverar dem. Exempel är vanliga textkonventioner som ~ord~ eller fraser som generellt bör kursiveras, t.ex. latinska fraser som ’etc.’ eller ’et cetera’.
- Ersätta enhetsindrag med CSS-indrag
Vissa dokument använder en konvention för att definiera textindrag med icke-brytande blanksteg. När det här alternativet är aktiverat försöker calibre att upptäcka den här typen av formatering och konvertera dem till en 3% textindragning med CSS.
Söka & ersätta¶
Dessa alternativ är främst användbara för konvertering av PDF-dokument eller OCR-konverteringar, men de kan också användas för att åtgärda många dokumentspecifika problem. Som ett exempel kan vissa konverteringar lämna kvar sidhuvuden och sidfötter i texten. Dessa alternativ använder reguljära uttryck för att försöka upptäcka sidhuvuden, sidfötter eller annan godtycklig text och ta bort eller ersätta dem. Kom ihåg att de fungerar på den mellanliggande XHTML som produceras av konverteringspipelinen. Det finns en guide som hjälper dig att anpassa de reguljära uttrycken för ditt dokument. Klicka på trollstaven bredvid uttrycksrutan och klicka på knappen ”Testa” efter att du har skrivit ditt sökuttryck. Framgångsrika träffar markeras med gult.
Sökningen fungerar med hjälp av ett Python-reguljärt uttryck. All matchad text tas helt enkelt bort från dokumentet eller ersätt med hjälp av ersättningsmönstret. Ersättningsmönster är valfritt, om det lämnas tomt kommer text som matchar sökbegreppet kommer att tas bort från dokumentet. Du kan läsa mer om reguljära uttryck och deras syntax på Allt om att använda reguljära uttryck i calibre.
Struktrurdetektering¶
Strukturdetektering innebär att calibre försöker sitt bästa för att upptäcka strukturella element i inmatningsdokumentet, när de inte är korrekt angivet. Till exempel kapitel, sidbrytningar, rubriker, sidfot etc. Som ni kan föreställa er, varierar denna process mycket från bok till bok. Lyckligtvis har calibre mycket kraftfulla alternativ för att hantera detta. Med makt kommer komplexitet, men om när du tar dig tid att lära sig komplexiteten, upptäcker du att det väl värt ansträngningen.
Kapitel och sidbrytningar¶
calibre har två uppsättningar alternativ för kapiteldetektering och infogning av sidbrytningar. Detta kan ibland vara lite förvirrande, eftersom calibre som standard infogar sidbrytningar före upptäckta kapitel såväl som de platser som upptäcks av alternativet för sidbrytningar. Anledningen till detta är att det ofta finns platser där sidbrytningar ska infogas som inte är kapitelgränser. Dessutom kan upptäckta kapitel valfritt infogas i den automatiskt genererade innehållsförteckningen.
calibre använder XPath, ett kraftfullt språk för att göra det möjligt för användaren att specificera kapitelgränser/sidbrytningar. XPath kan verka lite skrämmande att använda till en början, lyckligtvis finns det en XPath-handledning i användarmanualen. Kom ihåg att strukturdetektering fungerar på den mellanliggande XHTML produceras av konverteringsprocessen. Använd felsökningsalternativet som beskrivs i Introduktion för att ta reda på lämpliga inställningar för din bok. Det finns också en knapp för en XPath-guide som hjälper till med skapande av enkla XPath-uttryck.
Som standard använder calibre följande uttrycker för att upptäcka kapitel:
//*[((name()='h1' or name()='h2') and re:test(., 'chapter|book|section|part\s+', 'i')) or @class = 'chapter']
Detta uttryck är ganska komplicerat, eftersom det försöker hantera ett antal gemensamma fall samtidigt. Vad det betyder är att calibre antar att kapitel börjar på antingen <h1> eller <h2> taggar som har något av orden (chapter, book, section eller part) i dem eller som har class = ”chapter” attribut.
Ett relaterat alternativ är Kapitelmarkering, som låter dig anpassa vad calibre gör när det upptäcker ett kapitel. Som standard kommer det att infoga en sidbrytning före kapitlet. Du kan låta den infoga en uppmätt rad istället för eller utöver sidbrytningen. Du kan också låta den göra ingenting.
Standardinställningen för att upptäcka sidbrytningar är:
//*[name()='h1' or name()='h2']
vilket innebär att calibre kommer att infoga sidbrytningar före varje <h1> och <h2> tagg som standard.
Anteckning
Standarduttryck kan ändras beroende på inmatningsformat du konverterar.
Diverse¶
Det finns några fler alternativ i det här avsnittet.
- Infoga metadata som en sida i början av boken
En av de bästa sakerna med calibre är att det tillåter dig att behålla mycket kompletta metadata om alla dina böcker, till exempel ett betyg, taggar, kommentarer etc. Det här alternativet skapar en enda sida med alla dessa metadata och infogar dem i den konverterade e-boken, vanligtvis precis efter omslaget. Se det som ett sätt att skapa egna anpassade bokomslag.
- Ta bort första bilden
Ibland innehåller källdokumentet du konverterar omslaget som en del av boken, istället för som ett separat omslag. Om du också ange ett omslag i calibre, den då konverterade boken kommer att ha två omslag. Det här alternativet kommer att helt enkelt ta bort den första bilden från källdokumentet, vilket säkerställer att den konverterade boken har bara ett omslag, det som anges i calibre.
Innehållsförteckning¶
När inmatningsdokumentet har en innehållsförteckning i dess metadata, kommer calibre att använda det. Men ett antal äldre format stöder antingen inte en metadata baserade innehållsförteckning, eller så har inte enskilda dokument en. I dessa fall kan alternativen i det här avsnittet hjälp dig att automatiskt skapa en innehållsförteckning i den konverterade e-boken, baserat på det faktiska innehållet i inmatningsdokumentet.
Anteckning
Att använda dessa alternativ kan vara lite utmanande att få helt rätt. Om du föredrar att skapa/redigera innehållsförteckningen för hand, konvertera till EPUB- eller AZW3-formaten och välja kryssrutan längst ner i avsnittet innehållsförteckning i konverteringsdialogrutan som heter Finjustera innehållsförteckningen manuellt efter att konverteringen är klar. Detta kommer att starta redigeringsverktyget för innehållsförteckningar efter konverteringen. Det låter dig skapa poster i innehållsförteckningen genom att helt enkelt klicka på platsen i boken du vill att posten ska hänvisa till. Du kan också använda redigeraren för innehållsförteckningar för sig själv, utan att göra en konvertering. Gå till Inställningar → Gränssnitt → Verktygsfält och lägg till Redigerare för innehållsförteckningar i huvudverktygsfältet. Välj sedan bara boken du vill redigera och klicka på knappen Redigerare för innehållsförteckningar.
Det första alternativet är Tvinga användning av automatiskt genererad innehållsförteckning. Genom att markera det här alternativet kan du få calibre att åsidosätta innehållsförteckningar som finns i metadata för inmatningsdokumentet med den automatiskt genererade.
Standardsättet som skapandet av den automatiskt genererade innehållsförteckningen fungerar är att calibre först försöker lägga till eventuella upptäckta kapitel till den genererade innehållsförteckningen. Du kan lära dig hur du anpassar upptäckten av kapitel i avsnittet Struktrurdetektering ovan. Om du inte vill inkludera upptäckta kapitel i den genererade innehållsförteckningen, markera alternativet Lägg inte till upptäcka kapitel.
Om mindre kapitel än Kapiteltröskel upptäcktes kommer calibre att lägga till alla hyperlänkar som hittas i inmatningsdokumentet till innehållsförteckningen. Detta fungerar ofta bra: många inmatningsdokument inkluderar en hyperlänkad innehållsförteckning direkt i början. Alternativet Antal länkar kan användas för att anpassa detta beteende. Om värdet är noll läggs inga länkar till. Om det är inställt på ett tal som är större än noll läggs högst det antalet länkar till.
calibre kommer automatiskt att filtrera dubbletter från den genererade innehållsförteckningen. Men om det finns några ytterligare oönskade poster kan du filtrera dem med alternativet Innehållsförteckningsfilter. Detta är ett reguljärt uttryck som söker titeln på posterna i den genererade innehållsförteckningen. När en träff hittas kommer den att tas bort. Om du till exempel vill ta bort alla poster med titlarna ”Nästa” eller ”Föregående” använder du:
Next|Previous
Alternativen Nivå 1,2,3 innehållsförteckning låter dig skapa en sofistikerad innehållsförteckning på flera nivåer. De är XPath-uttryck som matchar taggar i den mellanliggande XHTML som produceras av konverteringsprocessen. Se Introduktion för hur du får tillgång till denna XHTML. Läs också XPath-handledning, för att lära dig hur man konstruerar XPath-uttryck. Bredvid varje alternativ finns en knapp som startar en guide som hjälper dig att skapa grundläggande XPath-uttryck. Följande enkla exempel illustrerar hur du använder de här alternativen.
Anta att du har ett inmatningsdokument som resulterar i XHTML och ser ut så här:
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<title>Sample document</title>
</head>
<body>
<h1>Chapter 1</h1>
...
<h2>Section 1.1</h2>
...
<h2>Section 1.2</h2>
...
<h1>Chapter 2</h1>
...
<h2>Section 2.1</h2>
...
</body>
</html>
Sedan anger vi alternativ som:
Level 1 TOC : //h:h1
Level 2 TOC : //h:h2
Detta kommer att resultera i en automatiskt genererad innehållsförteckning på två nivåer som ser ut som:
Chapter 1
Section 1.1
Section 1.2
Chapter 2
Section 2.1
Varning
Inte alla utmatningsformat stöder en innehållsförteckning med flera nivåer. Du bör först försöka med EPUB-utmatning. Om det fungerar, testa sedan ditt val av format.
Använda bilder som kapitelrubriker vid konvertering av HTML-inmatningsdokument¶
Anta att du vill använda en bild som din kapitelrubrik, men ändå vill att calibre automatiskt ska kunna skapa en innehållsförteckning åt dig från kapitelrubrikerna. Använd följande HTML-markering för att uppnå detta:
<html>
<body>
<h2>Chapter 1</h2>
<p>chapter 1 text...</p>
<h2 title="Chapter 2"><img src="chapter2.jpg" /></h2>
<p>chapter 2 text...</p>
</body>
</html>
Ställ in inställningen Nivå 1 innehållsförteckning till //h:h2. Då, i kapitel två, tar calibre titeln från värdet av attributet title på <h2>-taggen, eftersom taggen inte har någon text.
Använda taggattribut för att leverera texten för posterna i innehållsförteckningen¶
Om du har särskilt långa kapiteltitlar och vill ha förkortade versioner i innehållsförteckningen kan du använda attributet title för att uppnå detta, till exempel:
<html>
<body>
<h2 title="Chapter 1">Chapter 1: Some very long title</h2>
<p>chapter 1 text...</p>
<h2 title="Chapter 2">Chapter 2: Some other very long title</h2>
<p>chapter 2 text...</p>
</body>
</html>
Ändra Nivå 1 TOC inställning till //h:h2/@title. Då tar calibre titeln från värdet på titel attribut på <h2> taggar, istället för att använda texten i taggen. Observera den avslutande /@title på XPath-uttryck kan du använda den här formen för att ange att calibre ska hämta texten från valfritt attribut.
Hur alternativ ställs in/sparas för konvertering¶
Det finns två ställen där konverteringsalternativ kan ställas in i calibre. Den första är i Inställningar->Konvertering. Dessa inställningar är standardinställningarna för konverteringsalternativen. Varje gång du försöker konvertera en ny bok kommer inställningarna här att användas som standard.
Du kan också ändra inställningar i konverteringsdialogrutan för varje bokkonvertering. När du konverterar en bok kommer calibre att komma ihåg inställningarna som du använde för den bok, så att om du konverterar den igen, kommer de sparade inställningarna för den enskilde boken att ha företräde framför standardinställningarna som anges i Inställningar. Du kan återställa de enskilda inställningarna till standardvärdena genom att använda knappen Återställ till standardvärden i enskilda bokkonverteringsdialogrutan. Du kan ta bort de sparade inställningarna för en grupp av böcker genom att välja alla böcker och sedan klicka på knappen Redigera metadata för att ta fram redigeringsdialogrutan för att massändra metadata, nära botten av dialogrutan är ett alternativ att ta bort lagrade konverteringsinställningar.
När du masskonverterar en uppsättning böcker, tas inställningarna i följande ordning (sista vinner):
Från standardinställningarna i Inställningar->Konvertering
Från de sparade konverteringsinställningarna för varje bok som konverteras (om någon). Detta kan stängas av alternativ i det övre vänstra hörnet av dialogrutan Masskonvertering.
Från inställningarna i masskonverteringsdialogrutan
Observera att de slutliga inställningar för varje bok i en masskonvertering kommer att sparas och återanvändas om boken konverteras igen. Eftersom högsta prioritet av masskonvertering ges till inställningarna av dialogrutan Masskonvertering kommer dessa åsidosätta bokens specifika inställningar. Så du ska bara masskonvertera böcker tillsammans som behöver liknande inställningar. Undantaget är metadata och specifika inställningar för inmatningsformat. Eftersom dialogrutan Masskonvertering inte har inställningar för dessa två kategorier, kommer de att tas från boken specifika inställningar (om någon) eller standardvärdena.
Anteckning
Du kan se de faktiska inställningarna som används under en konvertering genom att klicka på den roterande ikonen i det nedre högra hörnet och sedan dubbelklicka på det enskilda konverteringsjobbet. Detta kommer att ta upp en konverteringslogg som innehåller de faktiska inställningarna som används, nära toppen.
Formatspecifika tips¶
Här hittar du tips som är specifika för konvertering av vissa format. Alternativ specifika för visst format, oavsett inmatning eller utmatning finns i dialogrutan konvertering under eget avsnitt, till exempel TXT-inmatning eller EPUB-utmatning.
Konvertera Microsoft Word-dokument¶
calibre kan automatiskt konvertera .docx-filer som skapats av Microsoft Word 2007 och nyare. Lägg bara till filen i calibre och klicka på konvertera.
Anteckning
Det finns en demo .docx-fil som demonstrerar förmågorna hos calibres konverteringsmotor. Bara hämta den och konvertera den till EPUB eller AZW3 för att se vad calibre kan göra.
calibre kommer att automatiskt generera en innehållsförteckning som baseras på rubriker om du markerar dina rubriker med formaten Rubrik 1, Rubrik 2 etc. i Microsoft Word. Öppna utmatnings-e-boken i calibres e-bokvisare och klicka på knappen Innehållsförteckning för att visa den genererade innehållsförteckningen.
Äldre .doc-filer¶
För äldre .doc-filer kan du spara dokumentet som HTML med Microsoft Word och sedan konvertera den resulterande HTML-filen med calibre. När du sparar som HTML, se till att använda alternativet ”Spara som webbplats, filtrerad” eftersom detta kommer att producera ren HTML som kommer att konverteras bra. Observera att Word producerar en riktigt rörig HTML, att konvertera den kan ta lång tid, så ha tålamod. Om du har en nyare version av Word tillgänglig kan du också spara den direkt som .docx.
Ett annat alternativ är att använda gratis LibreOffice. Öppna din .doc-fil i LibreOffice och spara den som .docx, som direkt kan konverteras i calibre.
Konvertera TXT-dokument¶
TXT-dokument har inget väl definierat sätt att specificera formatering som fetstil, kursiv, etc., eller dokumentstruktur som stycken, rubriker, avsnitt och så vidare, men det finns en mängd konventioner som vanligtvis används. Som standard försöker calibre automatisk upptäcka korrekt formatering och markering baserat på dessa konventioner.
TXT-inmatning stöder ett antal alternativ för att differentiera hur stycken upptäcks.
- Styckeformat: automatisk
Analyserar textfilen och försök att automatiskt avgöra hur styckena är definierade. Detta val kommer i allmänhet fungerar bra, om du uppnår oönskade resultat testa ett av de manuella alternativen.
- Styckeformat: blockera
Förutsätter en eller flera tomma rader är en styckesgräns:
This is the first. This is the second paragraph.- Styckeformat: ensamstående
Förutsätter att varje rad är ett stycke:
This is the first. This is the second. This is the third.- Styckeformat: skriv ut
Förutsätter att varje stycke börjar med en indragning (antingen en tabulering eller 2+ blanksteg). Styckena avslutas när nästa rad som börjar med en indragning nås:
This is the first. This is the second. This is the third.- Styckeformat: oformaterad
Förutsätter att dokumentet inte har någon formatering, men använder hårda radbrytningar. Skiljetecken och medianradslängd används för att försöka återskapa stycken.
- Formateringsformat: automatisk
Försöker hitta den typ av formateringsmarkering som används. Om ingen markering används kommer heuristisk formatering att tillämpas.
- Formateringsformat: heuristisk
Analyserar dokumentet för vanliga kapitelrubriker, scenbrytningar och kursiverade ord och tillämpar lämplig HTML-markering under konvertering.
- Formateringsformat: Markdown
calibre stöder också körning av TXT-inmatning genom en omvandlingsförbehandlare känd som Markdown. Markdown gör att grundläggande formatering kan läggas till i TXT-dokument, såsom fetstil, kursiv stil, avsnittsrubriker, tabeller, listor, en innehållsförteckning etc. Markera kapitelrubriker med en ledande # och ställ in XPath-kapiteldetekteringsuttrycket till ”//h:h1” är det enklaste sättet att generera en korrekt innehållsförteckning från ett TXT-dokument. Du kan läsa mer om Markdown-syntaxen på daringfireball.
- Formateringsformat: ingen
Använder ingen speciell formatering av texten, dokumentet konverteras till HTML utan några ändringar.
Konvertera PDF-dokument¶
PDF-dokument är en av de värsta format att konvertera från. De är ett fast sidstorleks- och textplaceringsformat. Det betyder att det är mycket svårt att avgöra var ett stycke slutar och ett annat börjar. calibre kommer att försöka dela upp stycken med en anpassningsbar Radbrytningsfaktor. Detta är en skala som används för att bestämma längden för var en rad ska radbrytas. Giltiga värden är ett decimaltal mellan 0 och 1. Standard är 0,45, precis under medianradslängden. Sänk detta värde för att inkludera mer text i radbrytningen. Öka för att inkludera mindre. Du kan justera detta värde i konverteringsinställningarna under PDF-inmatning.
Dessutom har de ofta sidhuvuden och sidfötter som en del av dokumentet som kommer att bli inkluderat med texten. Använd panelen Sök och ersätt för att ta bort sidhuvuden och sidfötter för att mildra problemet. Om sidhuvuden och sidfötterna inte tas bort från texten kan kasta bort avsnittsuppdelning. För att lära dig hur du tar bort alternativ för sidhuvud och sidfot, läs Allt om att använda reguljära uttryck i calibre.
Vissa begränsningar på PDF-inmatning är:
Komplexa, flerkolumn- och bildbaserade dokument stöds inte.
Extrahering av vektorbilder och tabeller från inuti dokumentet stöds inte heller.
Vissa PDF-filer använder speciella glyfer för att representera ll eller ff eller fi etc. Konvertering av dessa kanske eller kanske inte fungerar beroende på hur de representeras internt i PDF:en.
Länkar och innehållsförteckning stöds inte
PDF-filer med inbäddade icke-Unicode-teckensnitt för att representera icke-engelska tecken kommer att resultera i förvrängt utmatning för dessa tecken
Vissa PDF-filer är uppbyggda av fotografier av sidan med OCR-text bakom dem. I sådana fall använder calibre OCR-texten, vilket kan vara mycket annorlunda från vad du ser när du visar PDF-filen
PDF-filer som används för att visa komplex text, som höger till vänster språk och matematisk typsättning kommer inte att konverteras korrekt
För att återiterera är PDF ett riktigt, riktigt dålig format att använda som inmatning. Om du absolut måste använda PDF, var beredd på en utmatning som sträcker sig allt från anständig till oanvändbar, beroende på den inmatade PDF-filen.
Serietidningssamlingar¶
En serietidningssamling är en .cbc-fil. En .cbc-fil är en ZIP-fil som innehåller andra CBZ-/CBR-filer. Dessutom måste .cbc-filen innehålla en enkel textfil som heter comics.txt, kodade i UTF-8. comics.txt-filen måste innehålla en förteckning över de comics-filerna inuti .cbc-filen i formen filename:title, enligt nedan:
one.cbz:Chapter One
two.cbz:Chapter Two
three.cbz:Chapter Three
.cbc-filen kommer då innehålla:
comics.txt
one.cbz
two.cbz
three.cbz
calibre kommer automatiskt att konvertera denna .cbc-fil till en e-bok med en innehållsförteckning som pekar på varje post i comics.txt.
Demonstration av avancerad EPUB-formatering¶
Olika avancerad formatering för EPUB-filer demonstreras i den här demofilen. Filen skapades från handkodad HTML med calibre och är tänkt att användas som en mall för dina egna EPUB skapande insatser.
HTML-källan som den skapades från är tillgänglig demo.zip. Inställningarna som används för att skapa EPUB:en från ZIP-filen är:
ebook-convert demo.zip .epub -vv --authors "Kovid Goyal" --language en --level1-toc '//*[@class="title"]' --disable-font-rescaling --page-breaks-before / --no-default-epub-cover
Observera att eftersom den här filen utforskar potentialen i EPUB, kommer inte de flesta av de avancerade formatering att fungera på läsenheter mindre kapabla än calibres inbyggda EPUB-visare.
Konvertera ODT-dokument¶
calibre kan direkt konvertera ODT (Opendocument Text)-filer. Du bör använda format för att formatera ditt dokument och minimera användningen av direkt formatering. När bilder infogas i ditt dokument måste du förankra dem till stycke, förankrade bilder till en sida kommer alla hamna på framsidan av konverteringen.
För att möjliggöra automatisk identifiering av kapitel måste du markera dem med de inbyggda formaten som heter Rubrik 1, Rubrik 2, …, Rubrik 6 (Rubrik 1 motsvarar HTML-taggen <h1>, Rubrik 2 till <h2> etc.). När du konverterar i calibre kan du ange vilket format du använde i Identifiera kapitel i rutan. Exempel:
Om du markerar kapitel med formatet Rubrik 2 måste du ställa in rutan ”Upptäck kapitel i” till
//h:h2För en kapslad innehållsförteckning med avsnitt markerad med Rubrik 2 och de kapitel som är markerade med Rubrik 3 måste du ange
//h:h2|//h:h3. I konvertera - innehållsförteckningssidan ställ in rutan Nivå 1 Innehållsförteckning till//h:h2och rutan nivå 2 innehållsförteckning till//h:h3.
Välkända dokumentegenskaper (titel, nyckelord, beskrivning, skapare) känns igen och calibre kommer att använda den första bilden (inte för liten och med bra bildförhållande) som omslagsbild.
Det finns också ett avancerat egenskapskonverteringsläge, som aktiveras genom att ställa in den anpassade egenskapen opf.metadata (av ”Ja eller Nej” typ) till Ja i ditt ODT-dokument (Arkiv->Egenskaper->Anpassa egenskaper). Om den här egenskapen upptäcks av calibre känns följande anpassade egenskaper igen (opf.authors åsidosätter dokumentets skapare):
opf.titlesort
opf.authors
opf.authorsort
opf.publisher
opf.pubdate
opf.isbn
opf.language
opf.series
opf.seriesindex
Utöver detta kan du ange vilken bild som ska användas som omslaget genom att namnge den opf.cover (högerklicka, Bild-> Alternativ-> Namn) i ODT. Om ingen bild med detta namn hittas, används den ”smarta” metoden. Eftersom omslagsupptäckt kan leda till dubbla omslag i vissa utmatningsformat, kommer processen att ta bort stycken (endast om det enda innehållet är omslaget!) från dokumentet. Men detta fungerar bara med namngiven bild!
För att inaktivera omslagsupptäckt kan du ställa in den anpassade egenskapen opf.nocover (’Ja eller Nej’-typ) till Ja i avancerat läge.
Konvertera till PDF¶
Den första, viktigaste inställningen att bestämma när man konverterar till PDF är sidstorleken. Som standard använder calibre en sidstorlek för ”U.S. Letter”. Du kan ändra detta till en annan standard sidstorlek eller en helt anpassad storlek i avsnittet PDF-utmatning sektionen i konverteringsdialogrutan. Om du skapar en PDF som ska användas på en viss enhet kan du slå på alternativet för att använda sidstorleken från utmatningsprofilen istället. Så om din utskriftsprofil är inställd på Kindle, kommer calibre att skapa en PDF med sidstorlek som är lämplig för visning på den lilla Kindle-skärmen.
Utskrivbar innehållsförteckning¶
Du kan också infoga en utskrift/tryckbar innehållsförteckning i slutet av PDF som listar sidnummer för varje avsnitt. Detta är mycket användbart om du tänker skriva ut PDF till papper. Om du vill använda PDF på en elektronisk produkt, ger PDF Outline denna funktionalitet och är genererad som standard.
Du kan anpassa utseendet på den genererade innehållsförteckningen genom att använda extra CSS-konverteringsinställningen under Utseende & känsla-delen i konverteringsdialogrutan. Standard CSS som används är listade nedan, helt enkelt kopiera den och gör de ändringar du vill.
.calibre-pdf-toc table { width: 100%% }
.calibre-pdf-toc table tr td:last-of-type { text-align: right }
.calibre-pdf-toc .level-0 {
font-size: larger;
}
.calibre-pdf-toc .level-1 td:first-of-type { padding-left: 1.4em }
.calibre-pdf-toc .level-2 td:first-of-type { padding-left: 2.8em }
Anpassade sidmarginaler för enskilda HTML-filer¶
Om du konverterar en EPUB- eller AZW3-fil med flera enskilda HTML-filer inuti den och du vill ändra sidmarginalerna för en viss HTML-fil kan du lägga till följande formatblock i HTML-filen med calibre e-bokredigeraren:
<style>
@page {
margin-left: 10pt;
margin-right: 10pt;
margin-top: 10pt;
margin-bottom: 10pt;
}
</style>
Aktivera sedan alternativet Använd sidmarginaler från dokumentet som konverteras i PDF-utmatningsavsnittet av konverteringsdialogrutan. Nu kommer alla sidor som genereras från denna HTML-fil att ha 10pt marginaler.