 언어 변경
언어 변경전자책 변환¶
캘리버는 매우 사용하기 쉽도록 설계된 변환 시스템을 가지고 있습니다. 보통은, 사용자가 캘리버에 책을 추가하고 변환을 클릭하기만 하면, 입력된 책에 가장 가까운 결과물을 만들기 위하여 캘리버가 최선을 다하게 됩니다. 하지만, 캘리버가 지원하는 매우 다양한 종류의 입력 형식들이 모두 전자책 변환에 적합한 것은 아닙니다. 만일 입력 형식이 이러한 경우이거나 또는 사용자가 변환 시스템에 더 많은 제어를 원하는 경우, 캘리버에는 변환 과정을 세부적으로 조정할 수 있는 아주 많은 옵션들이 있습니다. 하지만, 캘리버의 변환 시스템이 전용 전자책 편집기를 대체할 수 없다는 점은 항상 명심하시기 바랍니다. 전자책을 편집하는 방법으로는, 우선 캘리버를 사용하여 책을 EPUB이나 AZW3 형식으로 변환한 뒤, 책 편집 특정 기능을 사용하여 완벽한 형태로 다듬는 것을 추천합니다. 그런 다음 편집이 완료된 전자책을 입력으로 사용하여 캘리버에서 다른 형식들로 변환할 수 있습니다.
이 문서는 주로 아래 사진과 같이 변환 대화창에 있는 변환 설정을 참조합니다. 이러한 모든 설정은 명령줄 인터페이스를 통해 변환할 수도 있으며, 문서:doc:`generated/ko/ebook-convert`에 설명되어 있습니다. 캘리버에서 개별 설정에 대한 도움말을 얻을 수 있습니다. 마우스를 가져가면 설정을 설명하는 도구 설명이 나타납니다.
소개¶
가장 먼저 이해하여야 할 점은, 변환 시스템이 파이프라인(한 단계의 출력이 다음 단계의 입력이 이어지는 형태)으로 설계되었다는 점입니다. 도식적으로는 아래와 같습니다:
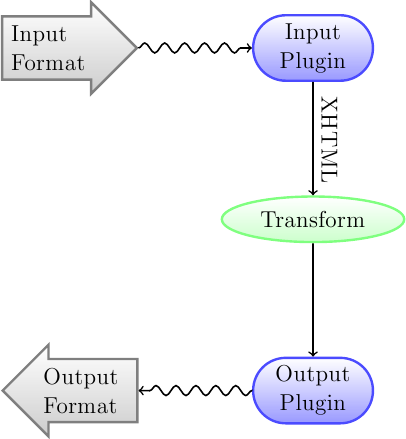
입력 형식(Input Format)은 우선 적절한 *입력 플러그인(Input Plugin)*에 의해 XHTML로 변환됩니다. 그런 다음 이 HTML이 *변형(Transformed)*됩니다. 마지막 단계에서 이 처리된 XHTML이 적절한 *출력 플러그인(Ouput Plugin)*에 의해 지정된 출력 형식(Output Format)으로 변환됩니다. 변환의 결과물을 입력 형식에 따라 큰 차이가 있을 수 있습니다. 몇몇 형식은 다른 형식들 보다 변환이 더 잘 이루어집니다. 변환용으로 가장 적절한 입력 형식 목록은 :ref:`이곳 <best-source-formats>`을 참조하세요.
작업의 대부분은 XHTML 출력에 대해 행해지는 변형 과정에서 일어납니다. 변형 과정에는 다양한 것들이 있는데, 예를 들어, 책 시작 부분에 메타데이터 페이지로 삽입하거나, 장(章) 제목을 감지하여 자동으로 목차를 만들고, 글꼴 크기를 비례적으로 조정하는 등 다양한 변환이 있습니다. 모든 변환은 입력 파일 자체가 아니라 *입력 플러그인*에 의해 XHTML 출력에 작용한다는 점을 기억해야 합니다. 예를 들어, RTF 파일을 EPUB로 변환하도록 cibre에 요청하면 먼저 내부적으로 XHTML로 변환되고 다양한 변환이 XHTML에 적용된 다음 *출력 플러그인*이 EPUB 파일을 생성하여 모든 메타데이터, 목차, 등등을 자동으로 생성합니다.
이 과정을 실제로 보려면 디버그 옵션  를 사용하면 된다. 디버그 출력용 폴더 경로만 지정하면 된다. 변환 중 calibre는 변환 파이프라인의 여러 단계에서 생성된 XHTML을 서로 다른 하위 폴더에 저장한다. 네 개의 하위 폴더는 다음과 같다:
를 사용하면 된다. 디버그 출력용 폴더 경로만 지정하면 된다. 변환 중 calibre는 변환 파이프라인의 여러 단계에서 생성된 XHTML을 서로 다른 하위 폴더에 저장한다. 네 개의 하위 폴더는 다음과 같다:
폴더 |
설명 |
|---|---|
input |
입력 플러그인의 HTML 출력을 담고 있습니다. 입력 플러그인을 디버깅하려면 이걸 사용하세요. |
parsed |
입력 플러그인의 출력에 대한 전처리와 XHTML로의 변환의 결과물입니다. 구조 탐지를 디버깅하는데 사용하세요. |
structure |
CSS flattening과 글꼴 크기 변환 이전의 사후 구조 탐지. 글꼴 크기 변환과 CSS 변형을 디버깅하는데 사용하세요. |
processed |
전자책이 출력 플러그인에 넘겨지기 직전의 단계. 출력 플러그인을 디버깅하는데 사용하세요. |
calibre가 변환하기 전에 입력 문서를 조금 수정하고 싶다면, 가장 좋은 방법은 input 하위 폴더의 파일을 편집한 다음 그것을 ZIP으로 묶고, 이후 변환에서 그 ZIP 파일을 입력 형식으로 사용하는 것이다. 이렇게 하려면 메타 정보 편집 대화상자에서 그 ZIP 파일을 책의 형식으로 추가한 뒤, 변환 대화상자의 왼쪽 위에서 입력 형식으로 ZIP을 선택하면 된다.
이 문서는 주로 중간 단계의 XHTML에 행해지는 다양한 변형 과정과 그것들을 제어하는 방법에 대해 다룹니다. 마지막에는 각 입력/출력 형식에만 적용되는 몇몇 팁들이 있습니다.
모양새¶
이 옵션 그룹은 변환된 전자책의 모양새의 다양한 측면을 제어합니다.
글꼴¶
전자책 읽기의 가장 큰 장점 중 하나는 개인의 필요와 조명 환경에 맞게 글꼴 크기를 쉽게 조절할 수 있다는 점이다. calibre에는 입력 문서에 어떤 글꼴 크기가 지정되어 있든, 출력되는 모든 책의 글꼴 크기를 일관되게 맞춰 주는 정교한 알고리즘이 들어 있다.
문서의 기본 글꼴 크기는 그 문서에서 가장 흔하게 쓰이는 글꼴 크기, 즉 본문 대부분의 글자 크기를 뜻한다. :guilabel:`기본 글꼴 크기`를 지정하면 calibre는 문서 안의 모든 글꼴 크기를 비례적으로 자동 재조정하여, 가장 흔한 글꼴 크기가 지정한 기본 글꼴 크기가 되도록 하고 다른 글꼴 크기도 그에 맞게 조정한다. 기본 글꼴 크기를 크게 하면 문서의 글꼴도 커지고, 반대로 작게 하면 글꼴도 작아진다. 최상의 결과를 얻으려면 기본 글꼴 크기를 설정할 때 글꼴 크기 키도 함께 설정하는 것이 좋다.
보통 calibre는 선택한 출력 프로필에 맞는 기본 글꼴 크기를 자동으로 고른다(페이지 설정 참고). 하지만 기본값이 자신에게 맞지 않으면 여기에서 덮어쓸 수 있다.
글꼴 크기 키 옵션은 기본 글꼴이 아닌 다른 글꼴 크기를 어떻게 재조정할지 제어한다. 글꼴 재조정 알고리즘은 글꼴 크기 키를 사용하며, 이것은 단순히 쉼표로 구분한 글꼴 크기 목록이다. 글꼴 크기 키는 주어진 글꼴 크기가 기본 글꼴 크기에 비해 몇 “단계” 크거나 작은지를 calibre에 알려 준다. 핵심 개념은 문서 안의 글꼴 크기 수가 제한적이어야 한다는 것이다. 예를 들어 본문용 크기 하나, 여러 단계의 제목용 크기 몇 개, 위첨자/아래첨자와 각주용 크기 몇 개 정도가 있다. 글꼴 크기 키를 이용하면 calibre가 입력 문서의 다양한 글꼴 크기를 서로 다른 논리적 글꼴 크기에 대응하는 별도의 “구간”으로 분류할 수 있다.
예를 들어 보자. 지금 변환하려는 원본 문서가 시력이 매우 좋은 사람이 만든 것이라 기본 글꼴 크기가 8pt라고 하자. 즉 문서 본문 대부분은 8pt이고, 제목은 조금 더 큰 10pt와 12pt 정도이며, 각주는 6pt처럼 조금 더 작다는 뜻이다. 이제 다음 설정을 사용하면:
Base font size : 12pt
Font size key : 7, 8, 10, 12, 14, 16, 18, 20
출력 문서는 기본 글꼴 크기 12pt, 제목 14pt와 16pt, 각주 8pt가 된다. 이제 가장 큰 제목 크기를 좀 더 두드러지게 하고, 각주도 약간 더 크게 만들고 싶다고 하자. 그러려면 글꼴 키를 다음처럼 바꾸면 된다:
New font size key : 7, 9, 12, 14, 18, 20, 22
그러면 가장 큰 제목은 18pt가 되고, 각주는 9pt가 된다. 글꼴 크기 키 설정 옆의 작은 버튼을 눌러 접근할 수 있는 글꼴 재조정 마법사를 사용하면, 어떤 설정이 자신에게 가장 적합한지 시험해 볼 수 있다.
입력 문서의 글꼴 크기를 그대로 유지하고 싶다면, 여기에서 변환 시의 모든 글꼴 크기 재조정을 끌 수도 있다.
관련 설정으로 :guilabel:`줄 높이`가 있다. 줄 높이는 줄의 세로 높이를 제어한다. 기본값(줄 높이 0)에서는 줄 높이를 조작하지 않는다. 기본값이 아닌 값을 지정하면, 자체 줄 높이가 지정되지 않은 모든 위치에 그 줄 높이가 적용된다. 다만 이 기능은 다소 거친 도구이므로 신중하게 사용하는 것이 좋다. 입력의 일부 구간만 줄 높이를 조정하고 싶다면 :ref:`Extra CSS <extra-css>`를 사용하는 편이 낫다.
이 섹션에서는 참조된 글꼴을 책 안에 포함하도록 calibre에 지시할 수도 있다. 그러면 리더 장치에 그 글꼴이 설치되어 있지 않아도 해당 글꼴을 사용할 수 있다.
텍스트¶
텍스트는 양쪽 정렬이 될 수도 있고 그렇지 않을 수도 있습니다. 양쪽 정렬된 텍스트에는 부드러운 오른쪽 여백을 제공하기 위해 단어 사이에 추가 공백이 있습니다. 어떤 사람들은 양쪽 정렬된 텍스트를 선호하지만 다른 사람들은 그렇지 않습니다. 일반적으로 캘리버는 원본 문서의 자리 맞춤을 유지합니다. 재정의하려면 이 섹션에서 텍스트 자리 맞춤 옵션을 사용할 수 있습니다.
calibre에 :guilabel:`문장부호 다듬기`를 지시할 수도 있다. 그러면 일반 따옴표, 대시, 줄임표를 올바른 조판용 문자로 바꾼다. 이 알고리즘은 완벽하지 않으므로 결과를 검토하는 것이 좋다. 반대로 :guilabel:`다듬은 문장부호 되돌리기`도 사용할 수 있다.
마지막으로 :guilabel:`입력 문자 인코딩`이 있다. 오래된 문서는 문자 인코딩을 지정하지 않는 경우가 있다. 이런 문서를 변환하면 비영어 문자나 스마트 따옴표 같은 특수 문자가 깨질 수 있다. calibre는 원본 문서의 문자 인코딩을 자동 감지하려고 하지만 항상 성공하는 것은 아니다. 이 설정을 사용하면 특정 문자 인코딩을 가정하도록 강제할 수 있다. `cp1252`는 Windows 소프트웨어로 만든 문서에서 흔히 쓰이는 인코딩이다. 인코딩 문제에 대해서는 :ref:`char-encoding-faq`도 읽어 보기 바란다.
배치¶
일반적으로 XHTML의 문단은 문단 사이에 빈 줄이 있고 문단 첫 줄 들여쓰기는 없다. calibre에는 이를 제어하는 옵션이 몇 가지 있다. :guilabel:`문단 사이 간격 제거`는 모든 문단 사이의 간격이 없도록 강제로 맞추고, 각 문단의 시작을 표시하기 위해 텍스트 들여쓰기를 1.5em으로 설정한다(변경 가능). :guilabel:`빈 줄 삽입`은 반대로 각 문단 쌍 사이에 정확히 한 줄의 빈 줄이 있도록 보장한다. 이 두 옵션은 매우 포괄적으로 동작하여 모든 문단(기술적으로는 <p> 와 <div> 태그)의 간격을 제거하거나 삽입한다. 입력 파일이 얼마나 지저분하든 옵션 이름 그대로 동작하도록 하기 위해서다. 유일한 예외는 입력 파일이 문단 간격을 만들기 위해 강제 줄바꿈을 사용하는 경우다.
선택한 일부만 제외하고 대부분 문단의 간격을 없애고 싶다면, 이 옵션을 사용하지 말고 대신 다음 CSS 코드를 :ref:`Extra CSS <extra-css>`에 추가하라:
p, div { margin: 0pt; border: 0pt; text-indent: 1.5em }
.spacious { margin-bottom: 1em; text-indent: 0pt; }
그런 다음 원본 문서에서 간격이 필요한 문단에 class=”spacious”`를 지정하면 된다. 입력 문서가 HTML이 아니라면, 서두에서 설명한 Debug 옵션을 사용해 HTML을 얻어라(:file:`input 하위 폴더 사용).
또 다른 유용한 옵션은 :guilabel:`표 선형화`이다. 잘못 설계된 일부 문서는 페이지의 텍스트 배치를 제어하기 위해 표를 사용한다. 이런 문서를 변환하면 텍스트가 페이지 밖으로 흘러나가거나 여러 가지 이상 현상이 생기곤 한다. 이 옵션은 표 안의 내용을 추출해서 선형 방식으로 표시한다. 다만 이 옵션은 모든 표를 선형화하므로, 입력 문서가 표를 실제 표 형식 데이터 표시 같은 정당한 목적으로 사용하지 않는다고 확신할 때만 사용해야 한다.
스타일¶
추가 CSS 옵션을 사용하면 입력의 모든 HTML 파일에 적용할 임의의 CSS를 지정할 수 있다. 이 CSS는 매우 높은 우선순위로 적용되므로 입력 문서 자체에 들어 있는 대부분의 CSS를 덮어쓴다. 이 설정을 사용하면 문서의 표시/배치를 세밀하게 조정할 수 있다. 예를 들어 endnote 클래스를 가진 모든 문단을 오른쪽 정렬하고 싶다면 다음을 추가하면 된다:
.endnote { text-align: right }
또는 모든 문단의 들여쓰기를 바꾸고 싶다면:
p { text-indent: 5mm; }
:guilabel:`추가 CSS`는 매우 강력한 옵션이지만, 최대한 활용하려면 CSS 동작 방식을 이해하고 있어야 한다. 위에서 설명한 디버그 파이프라인 옵션을 사용하면 입력 문서에 어떤 CSS가 들어 있는지 확인할 수 있다.
더 간단한 방법으로 :guilabel:`스타일 정보 필터`를 사용할 수 있다. 이 기능은 지정한 유형의 CSS 속성을 문서에서 모두 제거한다. 예를 들어 모든 색상이나 모든 글꼴을 제거하는 데 사용할 수 있다.
스타일 변형¶
이 기능은 스타일 관련 기능 중 가장 강력하다. 여러 조건에 따라 스타일을 바꾸는 규칙을 정의할 수 있다. 예를 들어 모든 녹색을 파란색으로 바꾸거나, 텍스트의 굵게 스타일을 모두 제거하거나, 모든 제목을 특정 색으로 칠하는 등의 작업을 할 수 있다.
HTML 변환¶
스타일 변환과 비슷하지만, 책의 HTML 내용 자체를 바꿀 수 있다. 태그를 다른 태그로 바꾸거나, 내용에 따라 태그에 클래스나 다른 속성을 추가하는 등의 작업이 가능하다.
페이지 설정¶
페이지 설정 옵션은 여백과 화면 크기처럼 화면 배치를 제어하기 위한 것이다. 선택한 출력 형식이 페이지 여백을 지원하면, 출력 플러그인이 사용할 페이지 여백을 설정할 수 있다. 또한 입력 프로필과 출력 프로필도 선택해야 한다. 이 두 프로필은 기본적으로 입력/출력 문서의 치수 해석 방식, 화면 크기, 기본 글꼴 재조정 키를 다룬다.
변환하려는 파일이 특정 장치/소프트웨어 플랫폼용으로 만들어졌다는 것을 알고 있다면 그에 맞는 입력 프로필을 선택하고, 아니면 기본 입력 프로필을 선택하면 된다. 만들어낼 파일이 특정 장치 유형용이라는 것을 알고 있다면 해당 출력 프로필을 선택하라. 그렇지 않다면 일반(Generic) 출력 프로필 중 하나를 선택하면 된다. MOBI나 AZW3로 변환하는 경우에는 거의 항상 Kindle 출력 프로필 중 하나를 선택하는 것이 좋다. 그 외의 최신 전자책 리더 장치라면 Generic e-ink HD 출력 프로필이 가장 무난하다.
출력 프로필은 화면 크기도 제어한다. 예를 들어 일부 출력 형식에서는 이미지가 화면에 맞도록 자동으로 크기 조정된다. 따라서 자신의 장치와 비슷한 화면 크기를 가진 장치의 프로필을 선택해야 한다.
합리적 추측에 의한(Heuristic) 처리¶
휴리스틱 처리는 서식이 좋지 않은 입력 문서에서 흔히 발생하는 문제를 감지하고 수정하기 위해 사용할 수 있는 여러 기능을 제공한다. 입력 문서 제작자가 서식 처리를 충분히 하지 않은 경우에 이 기능을 사용하라. 이런 옵션들은 때때로 문서를 훼손할 수도 있으므로 주의해서 써야 한다. 예를 들어 여기 있는 몇몇 옵션은 줄바꿈 불가 공백(non-breaking-space) 엔티티를 모두 제거하거나, 기능과 관련된 오탐지를 포함할 수 있다.
- 휴리스틱 처리 활성화
이 옵션은 변환 파이프라인에서 calibre의 휴리스틱 처리 단계를 활성화한다. 여러 하위 기능이 적용되려면 이 옵션이 반드시 켜져 있어야 한다.
- 줄 펼치기
이 옵션을 켜면 calibre가 문서 안에 있는 강제 줄바꿈을 문장부호 단서와 줄 길이를 이용해 감지하고 수정하려고 시도한다. calibre는 먼저 강제 줄바꿈이 실제로 존재하는지 확인하며, 없어 보이면 줄 펼치기를 시도하지 않는다. 줄 펼치기 계수를 낮추면 calibre가 더 적극적으로 줄을 펼치도록 “강제”할 수 있다.
- 줄 펼치기 계수
이 옵션은 calibre가 강제 줄바꿈을 제거할 때 사용하는 알고리즘을 제어한다. 예를 들어 이 값이 0.4이면, 문서의 모든 줄 길이 중 40%보다 짧은 길이의 줄 끝에 있는 강제 줄바꿈을 calibre가 제거한다는 뜻이다. 수정이 필요한 줄바꿈이 몇 개만 있다면, 이 값은 0.1~0.2 정도로 낮추는 것이 좋다.
- 서식 없는 장 제목과 부제목 감지 및 마크업
문서에서 장 제목과 타이틀이 본문과 다른 서식으로 표시되어 있지 않다면, calibre는 이 옵션을 사용해 그것들을 감지하고 제목 태그로 감쌀 수 있다. 장 제목에는 <h2> 태그를, 감지된 타이틀에는 <h3> 태그를 사용한다.
이 기능 자체가 TOC를 만들지는 않지만, 많은 경우 calibre의 기본 장 감지 설정이 장을 올바르게 감지하여 TOC를 만들도록 도와준다. TOC가 자동으로 생성되지 않으면 구조 감지의 XPath를 조정하라. 문서에 다른 제목이 없다면 구조 감지에서 “//h:h2”를 설정하는 것이 TOC를 만드는 가장 쉬운 방법이다.
삽입된 제목은 서식이 적용되지 않으므로, 서식을 주려면 모양새 변환 설정 아래의 추가 CSS 옵션을 사용해야 한다. 예를 들어 제목 태그를 가운데 정렬하려면 다음을 사용하라:
h2, h3 { text-align: center }
- <h1> 또는 <h2> 태그 연속 번호 다시 매기기
일부 출판사는 장 제목을 여러 개의 <h1> 또는 <h2> 태그를 연속해서 사용해 서식 지정한다. calibre의 기본 변환 설정을 사용하면 이런 제목은 두 조각으로 나뉠 수 있다. 이 옵션은 제목 태그의 번호를 다시 매겨 분할을 방지한다.
- 문단 사이 빈 줄 삭제
이 옵션을 켜면 calibre가 문서 안에 들어 있는 빈 줄을 분석한다. 모든 문단 사이에 빈 줄이 하나씩 끼어 있다면, calibre는 그 빈 문단을 모두 제거한다. 여러 개의 빈 줄이 연속된 경우에는 장면 전환(scene break)으로 간주하여 하나의 문단으로 유지한다. 이 옵션은 모양새 아래의 문단 간격 제거`와 달리 HTML 내용 자체를 수정하고, 다른 옵션은 문서의 스타일만 수정한다. 또한 이 옵션은 calibre의 :guilabel:`빈 줄 삽입 옵션으로 삽입된 문단도 제거할 수 있다.
- 장면 전환이 일관된 서식이 되도록 보장
이 옵션을 사용하면 calibre가 흔한 장면 전환 표시를 감지하여 가운데 정렬되도록 맞추려고 시도한다. ‘부드러운’ 장면 전환 표시, 즉 추가 공백만으로 정의된 장면 전환은 페이지 나눔과 함께 표시되지 않도록 스타일이 조정된다.
- 장면 나누기 교체
이 옵션을 설정하면 calibre는 발견한 장면 전환 표시를 사용자가 지정한 대체 텍스트로 바꾼다. 다만 장식용 문자는 일부 리더 장치에서 지원되지 않을 수 있다는 점에 유의하라.
일반적으로 HTML 태그는 사용하지 않는 것이 좋다. calibre는 태그를 버리고 미리 정의된 마크업을 사용한다. 예외는 <hr /> 태그, 즉 가로줄과 <img> 태그이다. 가로줄에는 선택적으로 스타일을 지정할 수 있는데, 직접 스타일을 추가한다면 반드시 ‘width’ 설정을 포함해야 하며 그렇지 않으면 스타일 정보가 버려진다. 이미지 태그도 사용할 수 있지만, calibre는 변환 중 이미지를 추가하는 기능을 제공하지 않으므로, 나중에 ‘책 편집’ 기능으로 추가해야 한다.
- 이미지 태그 예시(변환 후 EPUB 내부의 ‘Images’ 폴더 안에 이미지를 넣어 두어야 함):
<img style=”width:10%” src=”../Images/scenebreak.png” />
- 스타일이 적용된 가로줄 예시:
<hr style=”width:20%;padding-top: 1px;border-top: 2px ridge black;border-bottom: 2px groove black;”/>
- 불필요한 하이픈 제거하기
이 옵션을 켜면 calibre는 문서의 모든 하이픈 연결 내용을 분석한다. 분석에는 문서 자체를 사전처럼 사용한다. 덕분에 어떤 언어의 단어든, 심지어 조어와 생소한 과학 용어까지도 정확하게 하이픈을 제거할 수 있다. 주요 단점은 문서에 한 번만 나오는 단어는 바뀌지 않는다는 점이다. 분석은 두 번에 걸쳐 이루어진다. 첫 번째 단계에서는 줄 끝을 분석하며, 문서 안에 하이픈이 있거나 없는 형태가 둘 다 존재하는 경우에만 줄을 펼친다. 두 번째 단계에서는 문서 전체의 하이픈 단어를 분석하며, 같은 단어가 문서 다른 곳에 하이픈 없이 존재하면 하이픈을 제거한다.
- 일반적인 단어와 패턴을 이탤릭체로 표시
활성화하면 calibre는 이탤릭체를 의미하는 일반적인 단어와 패턴을 찾아 이탤릭체로 바꾼다. 예를 들어 ~word~ 같은 흔한 텍스트 관례나, 일반적으로 이탤릭체로 써야 하는 표현(예: ‘etc.’ 또는 ‘et cetera’ 같은 라틴어 구절)을 처리한다.
- 엔티티 들여쓰기를 CSS 들여쓰기로 바꾸기
일부 문서는 줄바꿈 불가 공백 엔티티를 사용해 텍스트 들여쓰기를 표현하는 관례를 사용한다. 이 옵션을 켜면 calibre가 이런 서식을 감지해 CSS의 3% 텍스트 들여쓰기로 변환하려고 시도한다.
검색 & 교체¶
이 옵션들은 주로 PDF 문서나 OCR 변환물을 변환할 때 유용하지만, 문서마다 존재하는 여러 문제를 고치는 데도 사용할 수 있다. 예를 들어 어떤 변환물은 페이지 머리글과 바닥글이 본문 안에 남는다. 이 옵션들은 정규식을 사용해 머리글, 바닥글 또는 다른 임의의 텍스트를 감지하고 제거하거나 바꾸려고 시도한다. 이 기능은 변환 파이프라인이 생성한 중간 XHTML에 작동한다는 점을 기억하라. 문서에 맞는 정규식을 만드는 데 도움이 되는 마법사도 있다. 식 상자 옆의 마법봉을 눌러 검색식을 작성한 뒤 ‘시험’ 버튼을 누르면 된다. 일치에 성공한 부분은 노란색으로 강조된다.
검색은 Python 정규식을 사용해 수행된다. 일치한 텍스트는 문서에서 단순히 제거되거나 대체 패턴을 사용해 바뀐다. 대체 패턴은 선택 사항이며, 비워 두면 검색 패턴과 일치한 텍스트는 문서에서 삭제된다. 정규식과 그 문법에 대해서는 :ref:`regexptutorial`에서 더 자세히 배울 수 있다.
구조 탐지¶
구조 감지는 입력 문서에 구조 요소가 제대로 지정되어 있지 않을 때, calibre가 장, 페이지 나눔, 머리글, 바닥글 같은 요소를 최대한 감지하려고 시도하는 과정이다. 짐작할 수 있듯이 이 과정은 책마다 크게 다르다. 다행히 calibre에는 이를 제어할 수 있는 매우 강력한 옵션이 있다. 강력한 만큼 복잡하지만, 그 복잡함을 익히는 데 시간을 들이면 충분히 그만한 가치가 있다.
장과 페이지 나눔¶
calibre에는 :guilabel:`장 감지`와 :guilabel:`페이지 나눔 삽입`을 위한 두 세트의 옵션이 있다. 기본적으로 calibre는 감지된 장 앞에도 페이지 나눔을 넣고, 페이지 나눔 옵션으로 감지된 위치에도 페이지 나눔을 넣기 때문에 약간 헷갈릴 수 있다. 그 이유는 페이지 나눔이 필요하지만 장 경계는 아닌 위치가 자주 있기 때문이다. 또한 감지된 장은 자동 생성된 목차에 선택적으로 삽입할 수도 있다.
calibre는 장 경계/페이지 나눔을 지정할 수 있도록 XPath 라는 강력한 언어를 사용한다. XPath는 처음에는 다소 어렵게 느껴질 수 있지만, 다행히 사용자 설명서에 :ref:`XPath tutorial <xpath-tutorial>`이 있다. 구조 감지는 변환 파이프라인이 만들어 낸 중간 XHTML에 대해 동작한다는 점을 기억하라. 자신의 책에 맞는 설정을 찾으려면 :ref:`conversion-introduction`에서 설명한 디버그 옵션을 사용하라. 간단한 XPath 식을 만드는 데 도움을 주는 XPath 마법사 버튼도 있다.
기본적으로 calibre는 장 감지에 다음 식을 사용한다:
//*[((name()='h1' or name()='h2') and re:test(., 'chapter|book|section|part\s+', 'i')) or @class = 'chapter']
이 식은 여러 흔한 경우를 동시에 처리하려고 하기 때문에 꽤 복잡하다. 의미는 calibre가 (chapter, book, section 또는 part)`라는 단어 중 하나를 포함하거나 `class=”chapter” 속성을 가진 <h1> 또는 <h2> 태그에서 장이 시작된다고 가정한다는 것이다.
관련 옵션으로 :guilabel:`장 표시`가 있다. 이 옵션은 calibre가 장을 감지했을 때 무엇을 할지 제어한다. 기본값은 장 앞에 페이지 나눔을 삽입하는 것이다. 페이지 나눔 대신, 또는 페이지 나눔과 함께 구분선을 넣게 할 수도 있고, 아무것도 하지 않게 할 수도 있다.
페이지 나눔 감지의 기본 설정은 다음과 같다:
//*[name()='h1' or name()='h2']
즉 기본적으로 calibre는 모든 <h1> 및 <h2> 태그 앞에 페이지 나눔을 삽입한다는 뜻이다.
참고
기본 식은 변환하는 입력 형식에 따라 달라질 수 있다.
기타¶
이 섹션에는 몇 가지 옵션이 더 있다.
- 책 시작 부분에 메타데이터를 페이지로 삽입
calibre의 큰 장점 중 하나는 평점, 태그, 주석 등 책에 대한 매우 완전한 메타데이터를 관리할 수 있다는 것이다. 이 옵션은 이러한 메타데이터를 모두 담은 단일 페이지를 만들어 변환된 전자책에 삽입한다. 보통은 표지 바로 뒤에 들어간다. 자신만의 맞춤 책 재킷을 만드는 방법이라고 생각하면 된다.
- 첫 번째 이미지 제거
변환하려는 원본 문서에 표지가 별도의 표지가 아니라 책 본문의 일부로 포함되어 있는 경우가 있다. 이때 calibre에서 따로 표지를 지정하면 변환된 책에는 표지가 두 번 들어갈 수 있다. 이 옵션을 켜면 첫 번째 이미지를 제거해 이런 문제를 막을 수 있다.
목차¶
입력 문서의 메타데이터에 목차(Table of Contents)가 있으면 calibre는 그것을 그대로 사용한다. 하지만 오래된 형식 중에는 메타데이터 기반 목차를 지원하지 않거나, 지원하더라도 항목이 충분하지 않은 경우가 있다. 이런 경우 calibre가 자동 생성한 목차를 사용해야 한다.
참고
이 옵션들을 정확히 맞추는 일은 다소 까다로울 수 있다. 목차를 직접 만들거나 수정하는 쪽이 더 편하다면 EPUB 또는 AZW3 형식으로 변환한 뒤, 책 편집 기능에서 수동으로 목차를 편집하면 된다.
첫 번째 옵션은 :guilabel:`자동 생성 목차 강제 사용`이다. 이 옵션을 체크하면 calibre가 입력 문서의 메타데이터에서 찾은 목차를 무시하고 자동 생성된 목차를 사용하게 할 수 있다.
자동 생성 목차의 기본 동작 방식은 calibre가 먼저 감지한 장을 생성된 목차에 추가하는 것이다. 그런 다음 생성된 목차에 너무 적은 항목만 있으면 다른 항목을 찾아 추가한다.
감지된 장 수가 :guilabel:`장 임계값`보다 적으면, calibre는 입력 문서에서 발견한 모든 하이퍼링크를 목차에 추가한다. 입력 문서 전체에 걸친 링크는 대개 많기 때문에, 이 기능을 켜면 지나치게 긴 목차가 생길 수 있다는 점에 유의하라.
calibre는 생성된 목차에서 중복 항목을 자동으로 걸러낸다. 하지만 여전히 원하지 않는 항목이 있다면 목차 필터 옵션을 사용해 걸러낼 수 있다.
Next|Previous
수준 1,2,3 TOC 옵션을 사용하면 정교한 다단계 목차를 만들 수 있다. 이것들은 변환 과정에서 생성된 중간 XHTML의 태그와 일치하는 XPath 식이다. 해당 태그에 매핑된 텍스트가 목차 항목이 된다.
예를 들어, 입력 문서가 변환된 뒤 다음과 같은 XHTML이 나온다고 하자:
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<title>Sample document</title>
</head>
<body>
<h1>Chapter 1</h1>
...
<h2>Section 1.1</h2>
...
<h2>Section 1.2</h2>
...
<h1>Chapter 2</h1>
...
<h2>Section 2.1</h2>
...
</body>
</html>
그러면 옵션을 다음처럼 설정한다:
Level 1 TOC : //h:h1
Level 2 TOC : //h:h2
이렇게 하면 자동 생성된 2단계 목차가 다음과 같이 만들어진다:
Chapter 1
Section 1.1
Section 1.2
Chapter 2
Section 2.1
경고
모든 출력 형식이 다단계 목차를 지원하는 것은 아니다. 먼저 EPUB 출력으로 시험해 보고, 잘 되면 원하는 형식에서도 시도하라.
HTML 입력 문서를 변환할 때 이미지를 장 제목으로 사용하기¶
장 제목으로 이미지를 사용하고 싶지만, 동시에 calibre가 장 제목을 바탕으로 자동으로 목차를 생성할 수 있게 하려면 다음과 같이 하라:
<html>
<body>
<h2>Chapter 1</h2>
<p>chapter 1 text...</p>
<h2 title="Chapter 2"><img src="chapter2.jpg" /></h2>
<p>chapter 2 text...</p>
</body>
</html>
수준 1 TOC 설정을 //h:h2``로 지정하라. 그러면 두 번째 장의 경우 calibre는 ``<h2> 태그의 title 속성 값을 제목으로 사용한다. 태그 자체의 텍스트가 비어 있기 때문이다.
목차 항목의 텍스트를 태그 속성으로 제공하기¶
장 제목이 너무 길어서 목차에는 더 짧은 버전을 넣고 싶다면 title 속성을 사용하면 된다. 예를 들면 다음과 같다:
<html>
<body>
<h2 title="Chapter 1">Chapter 1: Some very long title</h2>
<p>chapter 1 text...</p>
<h2 title="Chapter 2">Chapter 2: Some other very long title</h2>
<p>chapter 2 text...</p>
</body>
</html>
수준 1 TOC 설정을 //h:h2/@title``로 지정하라. 그러면 calibre는 ``<h2> 태그의 텍스트를 쓰는 대신 title 속성 값을 제목으로 사용한다.
변환 옵션의 설정/저장 방식¶
calibre에서 변환 옵션을 설정할 수 있는 곳은 두 군데다. 첫 번째는 환경설정->변환이다. 여기의 설정은 변환 옵션의 기본값이다. 새 책을 변환할 때마다 이 설정이 사용된다.
각 책 변환마다 변환 대화상자에서 설정을 바꿀 수도 있다. calibre는 책을 변환할 때 그 책에 사용한 설정을 기억하므로, 나중에 같은 책을 다시 변환하면 그 저장된 책별 설정이 사용된다.
여러 권의 책을 일괄 변환할 때는 설정이 다음 순서로 적용된다(나중 것이 우선한다):
환경설정->변환에서 설정한 기본값
변환 중인 각 책에 저장된 변환 설정(있는 경우). 이 동작은 일괄 변환 대화상자 왼쪽 위의 옵션으로 끌 수 있다.
일괄 변환 대화상자에서 지정한 설정
일괄 변환에서 각 책에 최종 적용된 설정은 저장되며, 그 책을 다시 변환할 때 재사용된다는 점에 유의하라. 일괄 변환에서는 일괄 변환 대화상자의 설정 우선순위가 가장 높기 때문에, 일괄 변환을 수행하면 기존에 저장되어 있던 책별 설정을 덮어쓰게 되는 경우가 많다.
참고
오른쪽 아래의 회전하는 아이콘을 클릭한 다음 개별 변환 작업을 두 번 클릭하면, 어떤 변환에서 실제로 사용된 설정을 확인할 수 있다. 그러면 로그와 함께 변환에 사용된 정확한 옵션이 표시된다.
형식별 팁¶
여기서는 특정 형식을 변환할 때 유용한 팁을 소개한다. 특정 형식에만 해당하는 옵션은 입력이든 출력이든 변환 대화상자의 해당 섹션에서 사용할 수 있다.
Microsoft Word 문서 변환¶
calibre는 Microsoft Word 2007 이상에서 만든 .docx 파일을 자동으로 변환할 수 있다. 파일을 calibre에 추가한 뒤 변환을 클릭하면 된다.
참고
calibre 변환 엔진의 기능을 보여 주는 :download_file:`데모 .docx 파일 <demos/demo.docx>`도 있다. 내려받아 EPUB이나 AZW3로 변환해 보면 된다.
Microsoft Word에서 제목에 제목 1, 제목 2 등의 스타일을 지정해 두면 calibre는 이를 바탕으로 목차를 자동 생성한다. 출력 결과를 더 잘 제어하려면 Word에서 스타일과 문서 구조를 올바르게 사용하는 것이 중요하다.
오래된 .doc 파일¶
오래된 .doc 파일의 경우 Microsoft Word에서 문서를 HTML로 저장한 뒤, 생성된 HTML 파일을 calibre로 변환할 수 있다. HTML로 저장할 때는 반드시 “웹 페이지, 필터링됨” 저장 옵션을 사용하라. 그러면 불필요한 Word 전용 마크업이 많이 줄어든다.
또 다른 방법으로 무료 LibreOffice를 사용할 수도 있다. LibreOffice에서 .doc 파일을 열어 .docx로 저장하면 calibre에서 바로 변환할 수 있다.
TXT 문서 변환¶
TXT 문서에는 굵게, 이탤릭체 같은 서식이나 문단, 제목, 절 같은 문서 구조를 명확히 지정하는 표준적인 방법이 없다. 하지만 실제로는 여러 가지 규칙과 관례가 사용되며, calibre는 이를 처리할 수 있는 다양한 옵션을 제공한다.
TXT 입력은 문단을 어떻게 감지할지 구분하기 위한 여러 옵션을 지원한다.
- 문단 스타일: 자동
텍스트 파일을 분석하여 문단이 어떻게 정의되어 있는지 자동으로 판단하려고 시도한다. 일반적으로는 잘 작동하지만 원하는 결과가 나오지 않으면 아래의 다른 문단 스타일 중 하나를 시도해 보라.
- 문단 스타일: 블록
하나 이상의 빈 줄을 문단 경계로 가정한다:
This is the first. This is the second paragraph.- 문단 스타일: 단일
모든 줄을 하나의 문단으로 가정한다:
This is the first. This is the second. This is the third.- 문단 스타일: 인쇄본
모든 문단이 들여쓰기(탭 또는 공백 2칸 이상)로 시작한다고 가정한다. 다음 들여쓰기 줄이 나오면 이전 문단이 끝난 것으로 본다:
This is the first. This is the second. This is the third.- 문단 스타일: 무서식
문서에 서식은 없지만 강제 줄바꿈은 사용한다고 가정한다. 문장부호와 평균 줄 길이를 이용해 문단을 다시 만들어 내려고 시도한다.
- 서식 스타일: 자동
사용 중인 서식 마크업 유형을 감지하려고 시도한다. 아무 마크업도 사용되지 않았다면 휴리스틱 서식이 적용된다.
- 서식 스타일: 휴리스틱
문서에서 흔한 장 제목, 장면 전환, 이탤릭체 단어를 분석하여 변환 중 적절한 HTML 마크업을 적용한다.
- 서식 스타일: Markdown
calibre는 Markdown이라는 변환 전처리기를 거쳐 TXT 입력을 처리하는 것도 지원한다. Markdown을 사용하면 굵게, 이탤릭체, 제목, 목록 등과 같은 기본 서식을 TXT 문서에 추가할 수 있다.
- 서식 스타일: 없음
텍스트에 특별한 서식을 적용하지 않는다. 문서는 다른 변경 없이 HTML로 변환된다.
PDF 문서 변환¶
PDF 문서는 변환 원본으로는 최악의 형식 중 하나다. PDF는 고정 페이지 크기와 고정 텍스트 배치 형식이기 때문이다. 즉, 어느 지점에서 한 문단이 끝나고 다음 문단이 시작되는지 판단하기가 매우 어렵다.
또한 머리글과 바닥글이 문서 일부로 포함되어 있는 경우가 많아서 본문과 함께 들어가 버리기도 한다. 머리글과 바닥글을 제거하려면 검색 및 바꾸기 패널을 사용하라.
PDF 입력의 몇 가지 제한 사항은 다음과 같다:
복잡한 다단 문서와 이미지 기반 문서는 지원되지 않는다.
문서 안에 있는 벡터 이미지와 표의 추출도 지원되지 않는다.
일부 PDF는 ll, ff, fi 등을 표현하기 위해 특수 글리프를 사용한다. 이런 경우의 변환이 제대로 될지는 PDF 내부에서 그것들이 어떻게 표현되어 있는지에 달려 있다.
링크와 목차는 지원되지 않는다.
비영어 문자를 표현하기 위해 내장된 비유니코드 글꼴을 사용하는 PDF는 해당 문자가 깨진 출력으로 변환된다.
일부 PDF는 페이지 사진 위에 OCR 텍스트를 얹어 만든다. 이런 경우 calibre는 OCR된 텍스트를 사용하며, 이는 화면에서 보이는 내용과 상당히 다를 수 있다.
오른쪽에서 왼쪽으로 쓰는 언어 또는 수식 조판처럼 복잡한 텍스트를 표시하는 데 사용되는 PDF는 올바르게 변환되지 않는다.
다시 한 번 강조하지만 PDF는 입력 형식으로 정말, 정말 좋지 않다. 꼭 PDF를 사용해야 한다면, 원본 PDF의 구조에 따라 괜찮은 수준에서 거의 사용할 수 없는 수준까지 결과가 크게 달라질 수 있다는 점을 각오해야 한다.
만화책 묶음¶
만화책 묶음은 .cbc 파일이다. .cbc 파일은 다른 CBZ/CBR 파일을 담고 있는 ZIP 파일이다. 또한 .cbc 파일에는 각 만화책 제목을 한 줄에 하나씩 적은 comics.txt라는 간단한 텍스트 파일이 반드시 들어 있어야 한다.
one.cbz:Chapter One
two.cbz:Chapter Two
three.cbz:Chapter Three
그러면 .cbc 파일에는 다음이 들어가게 된다:
comics.txt
one.cbz
two.cbz
three.cbz
calibre는 이 .cbc 파일을 자동으로 각 comics.txt 항목을 가리키는 목차가 포함된 전자책으로 변환한다.
EPUB 고급 서식 데모¶
다양한 EPUB 고급 서식은 이 :download_file:`데모 파일 <demos/demo.epub>`에서 확인할 수 있다. 이 파일은 calibre를 이용해 손으로 작성한 HTML에서 만들어졌으며, EPUB이 지원할 수 있는 여러 고급 기능을 보여 주기 위한 것이다.
이 파일을 만든 원본 HTML은 :download_file:`demo.zip <demos/demo.zip>`에서 받을 수 있다. ZIP 파일에서 EPUB을 만들 때 사용한 설정은 다음과 같다:
ebook-convert demo.zip .epub -vv --authors "Kovid Goyal" --language en --level1-toc '//*[@class="title"]' --disable-font-rescaling --page-breaks-before / --no-default-epub-cover
이 파일은 EPUB의 잠재력을 보여 주기 위한 것이므로, 대부분의 고급 서식은 calibre 내장 EPUB 뷰어보다 기능이 떨어지는 리더에서는 작동하지 않을 수 있다는 점에 유의하라.
ODT 문서 변환¶
calibre는 ODT(OpenDocument Text) 파일을 직접 변환할 수 있다. 문서 서식에는 스타일을 사용하고 직접 서식 지정의 사용은 최소화하는 것이 좋다. 문서에 이미지를 삽입할 때도 배치를 단순하게 유지하는 편이 좋다.
장을 자동으로 감지하려면 제목 1, 제목 2, …, 제목 6 (Heading 1 ~ Heading 6)이라 불리는 기본 제공 스타일로 장을 표시해야 한다.
장을 제목 2 스타일로 표시했다면 ‘장에서 감지’ 상자에 ``//h:h2``를 설정해야 한다.
제목 2`로 표시한 절과 :guilabel:`제목 3`으로 표시한 장이 있는 중첩 TOC를 만들려면 `//h:h2|//h:h3``를 입력해야 한다. 변환 - TOC 페이지에서는 해당 수준 1/수준 2 설정에 맞게 값을 넣어라.
잘 알려진 문서 속성(제목, 키워드, 설명, 작성자)은 인식되며, calibre는 첫 번째 이미지(너무 작지 않고 가로세로 비율이 적당한 것)를 표지로 사용한다.
고급 속성 변환 모드도 있다. ODT 문서의 사용자 정의 속성(File->Properties)에 opf.metadata 사용자 속성(‘예/아니오’ 형식)을 Yes로 설정하면 활성화된다.
opf.titlesort
opf.authors
opf.authorsort
opf.publisher
opf.pubdate
opf.isbn
opf.language
opf.series
opf.seriesindex
이와 함께 ODT 안에서 표지로 사용할 그림의 이름을 ``opf.cover``로 지정할 수도 있다(오른쪽 클릭, 그림->옵션->이름). 이 이름의 그림을 찾지 못하면 일반 표지 감지 방식이 사용된다.
고급 모드에서 표지 감지를 끄려면 opf.nocover 사용자 속성(‘예/아니오’ 형식)을 Yes로 설정하면 된다.
PDF로 변환하기¶
PDF로 변환할 때 가장 먼저, 그리고 가장 중요하게 결정해야 할 설정은 페이지 크기다. 기본적으로 calibre는 “U.S. Letter” 페이지 크기를 사용한다. 필요에 따라 A4 같은 다른 표준 크기로 바꿀 수 있다. 독자의 용도와 인쇄 환경에 맞는 크기를 선택하라.
인쇄용 목차¶
각 절의 페이지 번호를 나열하는 인쇄용 목차를 PDF 끝에 삽입할 수도 있다. PDF를 실제 종이에 인쇄하려는 경우 특히 유용하다.
생성된 목차의 모양은 변환 대화상자의 모양새 부분에 있는 추가 CSS 설정을 사용해 사용자화할 수 있다. 기본으로 사용되는 CSS는 다음과 같다:
.calibre-pdf-toc table { width: 100%% }
.calibre-pdf-toc table tr td:last-of-type { text-align: right }
.calibre-pdf-toc .level-0 {
font-size: larger;
}
.calibre-pdf-toc .level-1 td:first-of-type { padding-left: 1.4em }
.calibre-pdf-toc .level-2 td:first-of-type { padding-left: 2.8em }
개별 HTML 파일에 대한 사용자 지정 페이지 여백¶
여러 개의 개별 HTML 파일이 들어 있는 EPUB 또는 AZW3 파일을 변환할 때 특정 HTML 파일의 페이지 여백만 바꾸고 싶다면, 그 HTML 파일의 <head> 섹션에 다음 CSS를 추가할 수 있다:
<style>
@page {
margin-left: 10pt;
margin-right: 10pt;
margin-top: 10pt;
margin-bottom: 10pt;
}
</style>
그런 다음 변환 대화상자의 PDF 출력 섹션에서 변환 중인 문서의 페이지 여백 사용 옵션을 켜라. 그러면 이 HTML 파일에서 생성된 모든 페이지에는 지정한 사용자 지정 여백이 적용되고, 나머지 페이지는 PDF 출력 설정에서 지정한 여백을 사용한다.