 மொழியை மாற்றவும்
மொழியை மாற்றவும்உங்களுக்கு பிடித்த செய்தி வலைத்தளத்தைச் சேர்ப்பது¶
இணையத்திலிருந்து செய்திகளைப் பதிவிறக்குவதற்கும் அதை மின் புத்தகமாக மாற்றுவதற்கும் காலிபர் ஒரு சக்திவாய்ந்த, நெகிழ்வான மற்றும் பயன்படுத்த எளிதான கட்டமைப்பைக் கொண்டுள்ளது. பல்வேறு வலைத்தளங்களிலிருந்து செய்திகளை எவ்வாறு பெறுவது என்பதை எடுத்துக்காட்டுகள் மூலம் பின்வருபவை உங்களுக்குக் காண்பிக்கும்.
கட்டமைப்பை எவ்வாறு பயன்படுத்துவது என்பது பற்றிய புரிதலைப் பெற, கீழே பட்டியலிடப்பட்டுள்ள வரிசையில் உள்ள எடுத்துக்காட்டுகளைப் பின்பற்றவும்:
முற்றிலும் தானியங்கி பெறுதல்¶
உங்கள் செய்தி மூலமானது போதுமான எளிமையானதாக இருந்தால், காலிபர் அதை முழுவதுமாக தானாகவே பெற முடியும், நீங்கள் செய்ய வேண்டியது URL ஐ வழங்குவதுதான். ஒரு செய்தி மூலத்தை பதிவிறக்கம் செய்ய தேவையான அனைத்து தகவல்களையும் காலிபர் சேகரிக்கிறார்: கால: ரெசிபி. ஒரு செய்தி மூலத்தைப் பற்றி காலிபருக்குச் சொல்ல, நீங்கள் ஒரு: காலத்தை உருவாக்க வேண்டும்: ரெசிபி அதற்காக. சில எடுத்துக்காட்டுகளைப் பார்ப்போம்:
காலிபர் வலைப்பதிவு¶
காலிபர் வலைப்பதிவு என்பது புதிய காலிபர் பயனர்களுக்கு எளிய மற்றும் அணுகக்கூடிய வகையில் பல பயனுள்ள திறனுள்ள அம்சங்களை விவரிக்கும் இடுகைகளின் வலைப்பதிவு. இந்த வலைப்பதிவை ஒரு மின் புத்தகத்தில் பதிவிறக்க, நாங்கள்: கால: rss வலைப்பதிவின் ஊட்டத்தை நம்பியிருக்கிறோம்
http://blog.calibre-ebook.com/feeds/posts/default
வலைப்பதிவு பக்கத்தின் கீழே "குழுசேர்" என்பதன் கீழ் பார்த்து RSS URL கிடைத்தது: கிலாபெல்: இடுகைகள்-> அணு. காலிபர் ஊட்டங்களை பதிவிறக்கம் செய்து அவற்றை மின் புத்தகமாக மாற்ற, நீங்கள் வலது கிளிக் செய்ய வேண்டும்: கிலாபெல்: செய்தி பொத்தானைப் பெறுங்கள்: பின்னர்: கிலாபெல்:` தனிப்பயன் செய்தி மூலத்தை சேர்க்கவும்` மெனு உருப்படியைச் சேர்க்கவும்: பின்னர்: ` புதிய செய்முறை` பொத்தான். கீழே காட்டப்பட்டுள்ளதைப் போன்ற ஒரு உரையாடல் திறக்கப்பட வேண்டும்.
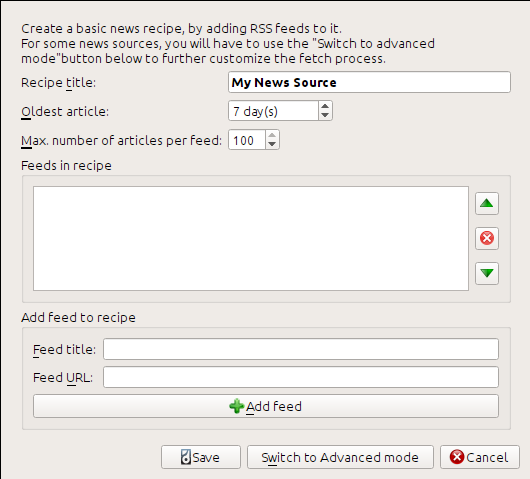
முதலில் `` காலிபர் வலைப்பதிவு`` இல் உள்ளிடவும்: கிலாபெல்: செய்முறை தலைப்பு புலம். இது மேற்கண்ட ஊட்டங்களில் உள்ள கட்டுரைகளிலிருந்து உருவாக்கப்படும் மின் புத்தகத்தின் தலைப்பாக இருக்கும்.
அடுத்த இரண்டு புலங்கள் (: கிலாபெல்: பழமையான கட்டுரை மற்றும்: கிலாபெல்:` மேக்ஸ்.
செய்முறையில் ஊட்டங்களைச் சேர்க்க, தீவன தலைப்பு மற்றும் தீவன URL ஐ உள்ளிட்டு: கிலாபெல்: ஊட்டத்தைச் சேர்க்கவும் பொத்தானைக் கிளிக் செய்க. நீங்கள் ஊட்டத்தைச் சேர்த்தவுடன்,: கிலாபெல்: சேமி பொத்தானைக் கிளிக் செய்க, நீங்கள் முடித்துவிட்டீர்கள்! உரையாடலை மூடு.
உங்கள் புதியதைச் சோதிக்க: கால: ரெசிபி, என்பதைக் கிளிக் செய்க: கிலாபெல்:` செய்தி` பொத்தானைப் பெறுங்கள். ஓரிரு நிமிடங்களுக்குப் பிறகு, புதிதாக பதிவிறக்கம் செய்யப்பட்ட வலைப்பதிவு இடுகைகளின் புத்தகம் பிரதான நூலகக் காட்சியில் தோன்றும் (உங்கள் வாசகர் இணைக்கப்பட்டிருந்தால், அது நூலகத்திற்கு பதிலாக வாசகரில் வைக்கப்படும்). அதைத் தேர்ந்தெடுத்து அதை அழுத்தவும்: கிலாபெல்: காண்க பொத்தானை!
இது மிகவும் சிறப்பாக செயல்பட்டதற்கான காரணம், மிகக் குறைந்த முயற்சியுடன், வலைப்பதிவு * முழு உள்ளடக்கத்தை *: கால: rss ஊட்டங்களை வழங்குகிறது, அதாவது, கட்டுரை உள்ளடக்கம் ஊட்டத்தில் உட்பொதிக்கப்பட்டுள்ளது. இந்த பாணியில் செய்திகளை வழங்கும் பெரும்பாலான செய்தி ஆதாரங்களுக்கு, * முழு உள்ளடக்க * ஊட்டங்களுடன், அவற்றை மின் புத்தகங்களாக மாற்ற உங்களுக்கு கூடுதல் முயற்சி தேவையில்லை. இப்போது முழு உள்ளடக்க ஊட்டங்களை வழங்காத செய்தி மூலத்தைப் பார்ப்போம். இத்தகைய ஊட்டங்களில், முழு கட்டுரை ஒரு வலைப்பக்கமாகும், மேலும் கட்டுரையின் குறுகிய சுருக்கத்துடன் வலைப்பக்கத்திற்கான இணைப்பை மட்டுமே ஊட்டத்தில் கொண்டுள்ளது.
bbc.co.uk¶
*பிபிசி *இலிருந்து பின்வரும் இரண்டு ஊட்டங்களை முயற்சிப்போம்:
செய்தி முதல் பக்கம்: https://newsrss.bbc.co.uk/rss/newsonline_world_edition/front_page/rss.xml
அறிவியல்/இயற்கை: https://newsrss.bbc.co.uk/rss/newsonline_world_edition/science/nature/rss.xml
கோடிட்டுக் காட்டப்பட்டுள்ள நடைமுறையைப் பின்பற்றவும்: ref: calibre_blog மேலே * பிபிசி * க்கான செய்முறையை உருவாக்க (மேலே உள்ள ஊட்டங்களைப் பயன்படுத்துதல்). பதிவிறக்கம் செய்யப்பட்ட மின் புத்தகத்தைப் பார்க்கும்போது, ஒவ்வொரு கட்டுரையின் வலைப்பக்கத்திலிருந்தும் நீங்கள் விரும்பும் உள்ளடக்கத்தை மட்டுமே பிரித்தெடுக்கும் ஒரு நம்பகமான வேலையை காலிபர் செய்திருப்பதைக் காண்கிறோம். இருப்பினும், பிரித்தெடுத்தல் செயல்முறை சரியானதல்ல. சில நேரங்களில் இது மெனுக்கள் மற்றும் வழிசெலுத்தல் எய்ட்ஸ் போன்ற விரும்பத்தகாத உள்ளடக்கத்தில் வெளியேறுகிறது அல்லது கட்டுரை தலைப்புகளைப் போல தனியாக இருக்க வேண்டிய உள்ளடக்கத்தை இது நீக்குகிறது. சரியான உள்ளடக்க பிரித்தெடுத்தலைக் கொண்டிருக்க, அடுத்த பகுதியில் விவரிக்கப்பட்டுள்ளபடி, பெறும் செயல்முறையைத் தனிப்பயனாக்க வேண்டும்.
பெறும் செயல்முறையைத் தனிப்பயனாக்குதல்¶
பதிவிறக்க செயல்முறையை நீங்கள் முழுமையாக்க விரும்பினால் அல்லது குறிப்பாக சிக்கலான வலைத்தளத்திலிருந்து உள்ளடக்கத்தைப் பதிவிறக்கும்போது, நீங்கள் அனைத்து சக்தி மற்றும் நெகிழ்வுத்தன்மையைப் பெறலாம்: கால: ரெசிபி கட்டமைப்பின். அதைச் செய்ய,: கிலாபெல்: தனிப்பயன் செய்தி ஆதாரங்களைச் சேர் உரையாடலில்,: கிலாபெல்:` மேம்பட்ட பயன்முறைக்கு மாறவும்` பொத்தானைக் கிளிக் செய்க.
ஆன்லைன் கட்டுரைகளின் அச்சு பதிப்பைப் பயன்படுத்துவதே எளிதான மற்றும் பெரும்பாலும் உற்பத்தி தனிப்பயனாக்குதல். அச்சு பதிப்பு பொதுவாக மிகக் குறைவான க்ரூஃப்ட் மற்றும் ஒரு மின் புத்தகத்திற்கு மிகவும் சீராக மொழிபெயர்க்கிறது. *பிபிசி *இலிருந்து கட்டுரைகளின் அச்சு பதிப்பைப் பயன்படுத்த முயற்சிப்போம்.
BBC.CO.UK இன் அச்சு பதிப்பைப் பயன்படுத்துதல்¶
முதல் படி, நாங்கள் முன்பு பதிவிறக்கம் செய்த மின் புத்தகத்தைப் பார்ப்பது: குறிப்பு: பிபிசி. ஒவ்வொரு கட்டுரையின் முடிவிலும், மின் புத்தகத்தில் கட்டுரை எங்கிருந்து பதிவிறக்கம் செய்யப்பட்டது என்பதைக் கூறுகிறது. அந்த URL ஐ உலாவியில் நகலெடுத்து ஒட்டவும். இப்போது கட்டுரையில் வலைப்பக்கத்தில் "அச்சிடக்கூடிய பதிப்பு" ஐ சுட்டிக்காட்டும் இணைப்பைத் தேடுங்கள். கட்டுரையின் அச்சு பதிப்பைக் காண அதைக் கிளிக் செய்க. இது மிகவும் நேர்த்தியாகத் தெரிகிறது! இப்போது இரண்டு URL களையும் ஒப்பிடுங்கள். என்னைப் பொறுத்தவரை அவர்கள்:
எனவே அச்சு பதிப்பைப் பெறுவது போல் தெரிகிறது, ஒவ்வொரு கட்டுரை URL ஐ நாம் முன்னொட்ட வேண்டும்:
newsvote.bbc.co.uk/mpapps/pagetools/print/
இப்போது: கிலாபெல்: தனிப்பயன் செய்தி ஆதாரங்களின் உரையாடலின் மேம்பட்ட பயன்முறை இதைப் போன்ற ஒன்றைக் காண வேண்டும் (மேம்பட்ட பயன்முறைக்கு மாறுவதற்கு முன்பு * பிபிசி * செய்முறையைத் தேர்ந்தெடுக்க நினைவில் கொள்ளுங்கள்):
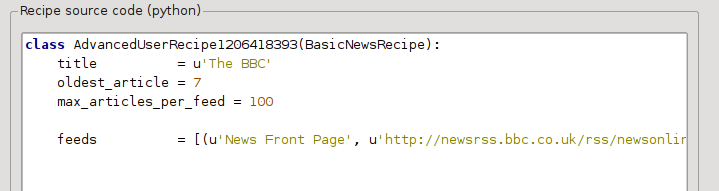
: கிலாபெல்: அடிப்படை பயன்முறை பைதான் குறியீட்டிற்கு நேரடியான முறையில் மொழிபெயர்க்கப்பட்டுள்ளதை நீங்கள் காணலாம். கட்டுரைகளின் அச்சு பதிப்பைப் பயன்படுத்த இந்த செய்முறைக்கு வழிமுறைகளைச் சேர்க்க வேண்டும். பின்வரும் இரண்டு வரிகளைச் சேர்ப்பதே தேவை:
def print_version(self, url):
return url.replace('https://', 'https://newsvote.bbc.co.uk/mpapps/pagetools/print/')
இது பைதான், எனவே உள்தள்ளல் முக்கியமானது. நீங்கள் வரிகளைச் சேர்த்த பிறகு, அது போல் இருக்க வேண்டும்:
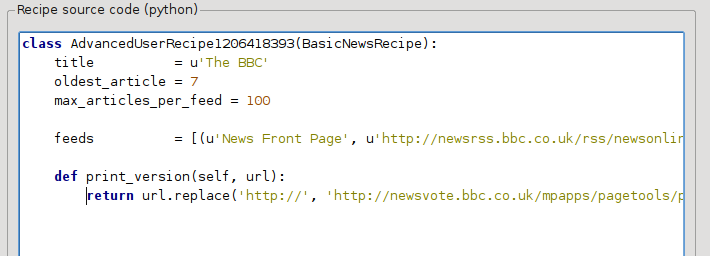
மேலே உள்ளவற்றில், `` DEF Print_version (சுய, URL) `` ஒவ்வொரு கட்டுரைக்கும் காலிபர் என்று அழைக்கப்படும் ஒரு * முறையை * வரையறுக்கிறது. `` url`` என்பது அசல் கட்டுரையின் URL ஆகும். `` Print_version`` என்ன செய்கிறது அந்த URL ஐ எடுத்து, கட்டுரையின் அச்சு பதிப்பை சுட்டிக்காட்டும் புதிய URL உடன் மாற்றவும். பைதான் <https://www.python.org> _ _ டுடோரியலைப் பார்க்கவும் <https://docs.python.org/tutorial/> _.
இப்போது,: கிலாபெல்: சேர்/புதுப்பிப்பு செய்முறை பொத்தானைக் கிளிக் செய்க, உங்கள் மாற்றங்கள் சேமிக்கப்படும். மின் புத்தகத்தை மீண்டும் ஏற்றவும். உங்களிடம் மிகவும் மேம்பட்ட மின் புத்தகம் இருக்க வேண்டும். புதிய பதிப்பில் உள்ள சிக்கல்களில் ஒன்று, அச்சு பதிப்பு வலைப்பக்கத்தில் உள்ள எழுத்துருக்கள் மிகச் சிறியவை. இது ஒரு மின் புத்தகமாக மாற்றும்போது தானாகவே நிர்ணயிக்கப்படுகிறது, ஆனால் சரிசெய்தல் செயல்முறைக்குப் பிறகும், மெனுக்கள் மற்றும் வழிசெலுத்தல் பட்டியின் எழுத்துரு அளவு கட்டுரை உரையுடன் ஒப்பிடும்போது மிகப் பெரியதாகிறது. இதை சரிசெய்ய, அடுத்த பகுதியில், இன்னும் சில தனிப்பயனாக்கலை செய்வோம்.
கட்டுரை பாணிகளை மாற்றுகிறது¶
முந்தைய பிரிவில், * பிபிசி * இன் அச்சு பதிப்பிலிருந்து கட்டுரைகளுக்கான எழுத்துரு அளவு மிகவும் சிறியது என்பதைக் கண்டோம். பெரும்பாலான வலைத்தளங்களில், * பிபிசி * சேர்க்கப்பட்டுள்ளது, இந்த எழுத்துரு அளவு இதன் மூலம் அமைக்கப்பட்டுள்ளது: கால: CSS ஸ்டைல்ஷீட்கள். வரியைச் சேர்ப்பதன் மூலம் அத்தகைய நடைதாள்களைப் பெறுவதை நாம் முடக்கலாம்
no_stylesheets = True
செய்முறை இப்போது தெரிகிறது:
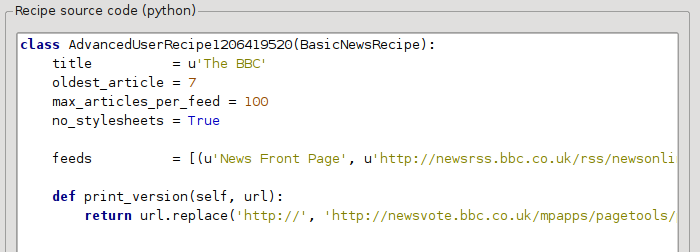
புதிய பதிப்பு மிகவும் நன்றாக இருக்கிறது. நீங்கள் ஒரு பரிபூரணவாதி என்றால், அடுத்த பகுதியைப் படிக்க விரும்புவீர்கள், இது பதிவிறக்கம் செய்யப்பட்ட உள்ளடக்கத்தை மாற்றியமைப்பதைக் கையாள்கிறது.
வெட்டுதல் மற்றும் டைசிங்¶
பதிவிறக்கம் செய்யப்பட்ட உள்ளடக்கத்தை கையாளும்போது காலிபர் மிகவும் சக்திவாய்ந்த மற்றும் நெகிழ்வான திறன்களைக் கொண்டுள்ளது. இவற்றில் சிலவற்றைக் காட்ட, எங்கள் பழைய நண்பரைப் பார்ப்போம்: குறிப்பு: பிபிசி <பிபிசி 1> மீண்டும் செய்முறை. ஓரிரு கட்டுரைகளின் (: சொல்: html) மூலக் குறியீட்டைப் பார்க்கும்போது (அச்சு பதிப்பு), அவற்றில் ஒரு பயனுள்ள தகவல்கள் இல்லை, அதில் ஒரு பயனுள்ள தகவல்கள் இல்லை என்பதைக் காண்கிறோம்
<div class="footer">
...
</div>
சேர்ப்பதன் மூலம் இதை அகற்றலாம்
remove_tags = [dict(name='div', attrs={'class':'footer'})]
செய்முறைக்கு. இறுதியாக, சில: கால: css ஐ மாற்றலாம், நாங்கள் முன்னர் முடக்கியுள்ளோம், நம்முடைய சொந்தத்துடன்: கால:` css` இது ஒரு மின் புத்தகத்திற்கு மாற்றுவதற்கு ஏற்றது
extra_css = '.headline {font-size: x-large;} \n .fact { padding-top: 10pt }'
இந்த சேர்த்தல்களுடன், எங்கள் செய்முறை "உற்பத்தித் தரம்" ஆகிவிட்டது.
இது: கால: ரெசிபி பனிப்பாறையின் நுனியை மட்டுமே ஆராய்கிறது. திறமையின் பல திறன்களை ஆராய, அடுத்த பகுதியில் மிகவும் சிக்கலான நிஜ வாழ்க்கை உதாரணத்தை ஆராய்வோம்.
உண்மையான வாழ்க்கை உதாரணம்¶
ஒரு நியாயமான சிக்கலான நிஜ வாழ்க்கை எடுத்துக்காட்டு: கால: `` API` இன் `` BasicNewsRecipe`` இன்: கால: ரெசிபி *தி நியூயார்க் டைம்ஸின் *செய்முறை *
import string, re
from calibre import strftime
from calibre.web.feeds.recipes import BasicNewsRecipe
from calibre.ebooks.BeautifulSoup import BeautifulSoup
class NYTimes(BasicNewsRecipe):
title = 'The New York Times'
__author__ = 'Kovid Goyal'
description = 'Daily news from the New York Times'
timefmt = ' [%a, %d %b, %Y]'
needs_subscription = True
remove_tags_before = dict(id='article')
remove_tags_after = dict(id='article')
remove_tags = [dict(attrs={'class':['articleTools', 'post-tools', 'side_tool', 'nextArticleLink clearfix']}),
dict(id=['footer', 'toolsRight', 'articleInline', 'navigation', 'archive', 'side_search', 'blog_sidebar', 'side_tool', 'side_index']),
dict(name=['script', 'noscript', 'style'])]
encoding = 'cp1252'
no_stylesheets = True
extra_css = 'h1 {font: sans-serif large;}\n.byline {font:monospace;}'
def get_browser(self):
br = BasicNewsRecipe.get_browser(self)
if self.username is not None and self.password is not None:
br.open('https://www.nytimes.com/auth/login')
br.select_form(name='login')
br['USERID'] = self.username
br['PASSWORD'] = self.password
br.submit()
return br
def parse_index(self):
soup = self.index_to_soup('https://www.nytimes.com/pages/todayspaper/index.html')
def feed_title(div):
return ''.join(div.findAll(text=True, recursive=False)).strip()
articles = {}
key = None
ans = []
for div in soup.findAll(True,
attrs={'class':['section-headline', 'story', 'story headline']}):
if ''.join(div['class']) == 'section-headline':
key = string.capwords(feed_title(div))
articles[key] = []
ans.append(key)
elif ''.join(div['class']) in ['story', 'story headline']:
a = div.find('a', href=True)
if not a:
continue
url = re.sub(r'\?.*', '', a['href'])
url += '?pagewanted=all'
title = self.tag_to_string(a, use_alt=True).strip()
description = ''
pubdate = strftime('%a, %d %b')
summary = div.find(True, attrs={'class':'summary'})
if summary:
description = self.tag_to_string(summary, use_alt=False)
feed = key if key is not None else 'Uncategorized'
if feed not in articles:
articles[feed] = []
if not 'podcasts' in url:
articles[feed].append(
dict(title=title, url=url, date=pubdate,
description=description,
content=''))
ans = self.sort_index_by(ans, {'The Front Page':-1, 'Dining In, Dining Out':1, 'Obituaries':2})
ans = [(key, articles[key]) for key in ans if key in articles]
return ans
def preprocess_html(self, soup):
refresh = soup.find('meta', {'http-equiv':'refresh'})
if refresh is None:
return soup
content = refresh.get('content').partition('=')[2]
raw = self.browser.open('https://www.nytimes.com'+content).read()
return BeautifulSoup(raw.decode('cp1252', 'replace'))
இதில் பல புதிய அம்சங்களை நாங்கள் காண்கிறோம்: சொல்: செய்முறை. முதலில், எங்களிடம்
timefmt = ' [%a, %d %b, %Y]'
இது உருவாக்கப்பட்ட மின் புத்தகத்தின் முதல் பக்கத்தில் காண்பிக்கப்படும் நேரத்தை வடிவத்தில் அமைக்கிறது, `` நாள், நாள்_நம்பர் மாதம், ஆண்டு`. காண்க: attr: timefmt <calibre.web.feeds.news.basicnewsrecipe.timefmt>.
பதிவிறக்கம் செய்யப்பட்டதை சுத்தம் செய்வதற்கான ஒரு குழுவைக் காண்கிறோம்: சொல்: html
remove_tags_before = dict(name='h1')
remove_tags_after = dict(id='footer')
remove_tags = ...
இவை முதல் `` <H1> `` குறிச்சொல் மற்றும் முதல் குறிச்சொல்லுக்குப் பிறகு எல்லாவற்றையும் அகற்றுவதற்கு முன்பு எல்லாவற்றையும் அகற்றுகின்றன. காண்க: attr: remove_tags <calibre.web.feeds.news.basicnewsrecipe.remove_tags>,: attr: `remove_tags_before <calibre.web.feeds.news.basicnewsrecipe. .feeds.news.basicnewsRecipe.remove_tags_after> `.
அடுத்த சுவாரஸ்யமான அம்சம்
needs_subscription = True
...
def get_browser(self):
...
`` தேவைகள்_சப்ஸ்கிரிப்ஷன் = உண்மை` உள்ளடக்கத்தை அணுக இந்த செய்முறைக்கு பயனர்பெயர் மற்றும் கடவுச்சொல் தேவை என்று காலிபருக்கு சொல்கிறது. இந்த செய்முறையைப் பயன்படுத்த முயற்சிக்கும்போதெல்லாம் பயனர்பெயர் மற்றும் கடவுச்சொல்லைக் கேட்பதற்கு இது காரணமாகிறது. குறியீடு: மெத்: `calibre.web.feeds.news.basicnewsrecipe.get_browser உண்மையில் NYT இணையதளத்தில் உள்நுழைகிறது. உள்நுழைந்ததும், காலிபர் எல்லா உள்ளடக்கத்தையும் பெறுவதற்கு அதே, உள்நுழைந்த, உலாவி உதாரணத்தைப் பயன்படுத்தும். `` Get_browser`` இல் உள்ள குறியீட்டைப் புரிந்து கொள்ள `இயந்திரமயமாக்கல் <https://mechanize.readthedocs.io/en/latest/> _ _ _ _ _.
அடுத்த புதிய அம்சம்: meth: calibre.web.feeds.news.basicnewsrecipe.parse_index முறை. அதன் வேலை https://www.nytimes.com/pages/todayspaper/index.html க்குச் சென்று * இன்றைய * காகிதத்தில் தோன்றும் கட்டுரைகளின் பட்டியலைப் பெறுவதாகும். வெறுமனே பயன்படுத்துவதை விட மிகவும் சிக்கலானது: கால: rss, செய்முறையானது ஒரு மின் புத்தகத்தை உருவாக்குகிறது, இது டேஸ் பேப்பருக்கு மிக நெருக்கமாக ஒத்திருக்கிறது. `` parse_index`` அழகான சப்பை <https://www.crummy.com/software/beautifulsoup/bs4/doc/> _ தினசரி காகித வலைப்பக்கத்தை பாகுபடுத்துகிறது. நீங்கள் அழகான சூப்பை விரும்பவில்லை என்றால் மற்ற, நவீன பாகுபடுத்தல்களையும் பயன்படுத்தலாம். காலிபர் lxml <https://lxml.de/> _ மற்றும் html5lib <https://github.com/html5lib/html5lib-python> _, பரிந்துரைக்கப்பட்ட பார்சர்கள். அவற்றைப் பயன்படுத்த, அழைப்பை `` index_to_soup () `` க்கு மாற்றவும்
raw = self.index_to_soup(url, raw=True)
# For html5lib
import html5lib
root = html5lib.parse(raw, namespaceHTMLElements=False, treebuilder='lxml')
# For the lxml html 4 parser
from lxml import html
root = html.fromstring(raw)
இறுதி புதிய அம்சம்: meth: calibre.web.feeds.news.basicnewsrecipe.preprocess_html முறை. பதிவிறக்கம் செய்யப்பட்ட ஒவ்வொரு HTML பக்கத்திலும் தன்னிச்சையான மாற்றங்களைச் செய்ய இதைப் பயன்படுத்தலாம். ஒவ்வொரு கட்டுரைக்கும் முன்னர் NYTIMES உங்களுக்குக் காண்பிக்கும் விளம்பரங்களைத் தவிர்ப்பதற்கு இங்கே இது பயன்படுத்தப்படுகிறது.
புதிய சமையல் குறிப்புகளை உருவாக்குவதற்கான உதவிக்குறிப்புகள்¶
புதிய சமையல் குறிப்புகளை உருவாக்குவதற்கான சிறந்த வழி கட்டளை வரி இடைமுகத்தைப் பயன்படுத்துவதாகும். உங்களுக்கு பிடித்த பைதான் எடிட்டரைப் பயன்படுத்தி செய்முறையை உருவாக்கி அதை ஒரு கோப்பில் சேமிக்கவும்: கோப்பு: myRecipe.recipe. .Recipe நீட்டிப்பு தேவை. இந்த செய்முறையை கட்டளையுடன் பயன்படுத்தி உள்ளடக்கத்தைப் பதிவிறக்கலாம்
ebook-convert myrecipe.recipe .epub --test -vv --debug-pipeline debug
கட்டளை: கட்டளை: மின்புத்தக-கான்வர்ட் அனைத்து வலைப்பக்கங்களையும் பதிவிறக்கம் செய்து அவற்றை எபப் கோப்பில் சேமிக்கும்: கோப்பு:` myRecipe.epub`. `` -VV`` விருப்பம் மின்புத்தக-மாற்றத்தை அது என்ன செய்கிறது என்பது பற்றிய பல தகவல்களைத் துப்புகிறது. THE: விருப்பம்: மின்புத்தக-கான்வர்ட்-ரெசிப்-இன்-இன்-டெஸ்ட் விருப்பம், பெரும்பாலான இரண்டு ஊட்டங்களிலிருந்து இரண்டு கட்டுரைகளை மட்டுமே பதிவிறக்குகிறது. கூடுதலாக, பதிவிறக்கம் செய்யப்பட்ட HTML ஐ `` பிழைத்திருத்த/உள்ளீடு` கோப்புறையில் வைக்கும், அங்கு பிழைத்திருத்தம்` என்பது நீங்கள் குறிப்பிட்ட கோப்புறையாகும்: விருப்பம்:` மின்புத்தக-கன்வெர்ட்--டெபக்-பிப்லைன்` விருப்பம்.
பதிவிறக்கம் முடிந்ததும், பதிவிறக்கம் செய்யப்பட்ட: கால: html கோப்பைத் திறப்பதன் மூலம் பார்க்கலாம்: கோப்பு:` பிழைத்திருத்த/உள்ளீடு/குறியீட்டு/குறியீட்டு. Html` ஒரு உலாவியில். பதிவிறக்கம் மற்றும் முன் செயலாக்கம் சரியாக நடக்கிறது என்று நீங்கள் திருப்தி அடைந்தவுடன், கீழே காட்டப்பட்டுள்ளபடி வெவ்வேறு வடிவங்களில் மின் புத்தகங்களை உருவாக்கலாம்
ebook-convert myrecipe.recipe myrecipe.epub
ebook-convert myrecipe.recipe myrecipe.mobi
...
உங்கள் செய்முறையில் நீங்கள் திருப்தி அடைந்தால், உள்ளமைக்கப்பட்ட சமையல் தொகுப்பில் சேர்ப்பதை நியாயப்படுத்த போதுமான தேவை இருப்பதாக நீங்கள் உணர்கிறீர்கள் என்றால், உங்கள் செய்முறையை காலிபர் ரெசிபிகள் மன்றத்தில் மற்ற காலிபர் பயனர்களுடன் பகிர்ந்து கொள்ள.
Note
MACOS இல், கட்டளை வரி கருவிகள் காலிபர் மூட்டைக்குள் உள்ளன, எடுத்துக்காட்டாக, நீங்கள் காலிபரை நிறுவியிருந்தால்: கோப்பு: /பயன்பாடுகள் கட்டளை வரி கருவிகள்:/பயன்பாடுகள்/calibre.app/பொருளடக்கம்/ .
See also
- : DOC: உருவாக்கப்பட்ட/EN/EBOOK-CONVERT
அனைத்து மின் புத்தக மாற்றத்திற்கும் கட்டளை வரி இடைமுகம்.
மேலும் படிக்க¶
`` BasicNewsRecipe`` இல் கிடைக்கும் சில வசதிகளைப் பயன்படுத்தி மேம்பட்ட சமையல் குறிப்புகளை எழுதுவது பற்றி மேலும் அறிய நீங்கள் பின்வரும் ஆதாரங்களை அணுக வேண்டும்:
- : ref: API ஆவணங்கள் <செய்திகள்_ரெசிப்>
`` BasicNewsRecipe`` வகுப்பின் ஆவணங்கள் மற்றும் அதன் அனைத்து முக்கியமான முறைகள் மற்றும் புலங்கள்.
- `BasicNewsRecipe <https://github.com/kovidgoyal/calibre/blob/master/src/calibre/web/feeds/news.pie> _ _
`` BasicNewsRecipe`` இன் மூலக் குறியீடு
- உள்ளமைக்கப்பட்ட சமையல் குறிப்புகள் <https://github.com/kovidgoyal/calibre/tree/master/recipes> _
காலிபருடன் வரும் உள்ளமைக்கப்பட்ட சமையல் குறிப்புகளுக்கான மூலக் குறியீடு
- காலிபர் ரெசிபிகள் மன்றம் <https://www.mobileeread.com/forums/forumdisplay.php?f=228> _
நிறைய அறிவுள்ள காலிபர் செய்முறை எழுத்தாளர்கள் இங்கே ஹேங்கவுட் செய்கிறார்கள்.
ஏபிஐ ஆவணங்கள்¶
- சமையல் குறிப்புகளுக்கான ஏபிஐ ஆவணங்கள்
BasicNewsRecipeBasicNewsRecipe.abort_article()BasicNewsRecipe.abort_recipe_processing()BasicNewsRecipe.add_toc_thumbnail()BasicNewsRecipe.adeify_images()BasicNewsRecipe.canonicalize_internal_url()BasicNewsRecipe.cleanup()BasicNewsRecipe.clone_browser()BasicNewsRecipe.default_cover()BasicNewsRecipe.download()BasicNewsRecipe.extract_readable_article()BasicNewsRecipe.get_article_url()BasicNewsRecipe.get_browser()BasicNewsRecipe.get_cover_url()BasicNewsRecipe.get_extra_css()BasicNewsRecipe.get_feeds()BasicNewsRecipe.get_masthead_title()BasicNewsRecipe.get_masthead_url()BasicNewsRecipe.get_obfuscated_article()BasicNewsRecipe.get_url_specific_delay()BasicNewsRecipe.image_url_processor()BasicNewsRecipe.index_to_soup()BasicNewsRecipe.is_link_wanted()BasicNewsRecipe.parse_feeds()BasicNewsRecipe.parse_index()BasicNewsRecipe.populate_article_metadata()BasicNewsRecipe.postprocess_book()BasicNewsRecipe.postprocess_html()BasicNewsRecipe.preprocess_html()BasicNewsRecipe.preprocess_image()BasicNewsRecipe.preprocess_raw_html()BasicNewsRecipe.print_version()BasicNewsRecipe.publication_date()BasicNewsRecipe.skip_ad_pages()BasicNewsRecipe.sort_index_by()BasicNewsRecipe.tag_to_string()BasicNewsRecipe.articles_are_obfuscatedBasicNewsRecipe.auto_cleanupBasicNewsRecipe.auto_cleanup_keepBasicNewsRecipe.center_navbarBasicNewsRecipe.compress_news_imagesBasicNewsRecipe.compress_news_images_auto_sizeBasicNewsRecipe.compress_news_images_max_sizeBasicNewsRecipe.conversion_optionsBasicNewsRecipe.cover_marginsBasicNewsRecipe.delayBasicNewsRecipe.descriptionBasicNewsRecipe.encodingBasicNewsRecipe.extra_cssBasicNewsRecipe.feedsBasicNewsRecipe.filter_regexpsBasicNewsRecipe.handle_gzipBasicNewsRecipe.ignore_duplicate_articlesBasicNewsRecipe.keep_only_tagsBasicNewsRecipe.languageBasicNewsRecipe.masthead_urlBasicNewsRecipe.match_regexpsBasicNewsRecipe.max_articles_per_feedBasicNewsRecipe.needs_subscriptionBasicNewsRecipe.no_stylesheetsBasicNewsRecipe.oldest_articleBasicNewsRecipe.preprocess_regexpsBasicNewsRecipe.publication_typeBasicNewsRecipe.recipe_disabledBasicNewsRecipe.recursionsBasicNewsRecipe.remove_attributesBasicNewsRecipe.remove_empty_feedsBasicNewsRecipe.remove_javascriptBasicNewsRecipe.remove_tagsBasicNewsRecipe.remove_tags_afterBasicNewsRecipe.remove_tags_beforeBasicNewsRecipe.requires_versionBasicNewsRecipe.resolve_internal_linksBasicNewsRecipe.reverse_article_orderBasicNewsRecipe.scale_news_imagesBasicNewsRecipe.scale_news_images_to_deviceBasicNewsRecipe.simultaneous_downloadsBasicNewsRecipe.summary_lengthBasicNewsRecipe.template_cssBasicNewsRecipe.timefmtBasicNewsRecipe.timeoutBasicNewsRecipe.titleBasicNewsRecipe.use_embedded_content