 Taal veranderen
Taal veranderenE-boek conversie¶
calibre heeft een conversiesysteem ontworpen voor gebruiksvriendelijkheid. Normaal voegt u gewoon een boek toe aan calibre, klikt op converteren en calibre zal hard proberen een uitvoer te genereren zo dicht mogelijk bij de invoer. calibre accepteert echter een groot aantal invoerformaten, niet allemaal even geschikt voor conversie naar e-boeken. In het geval van zo’n invoerformaten, of als u gewoon meer controle over het conversiesysteem wilt, heeft calibre veel opties om het conversieproces te verfijnen. Merk op dat het conversiesysteem van calibre geen vervanging is voor een volledige e-boek bewerker. Om e-boeken te bewerken raad ik aan ze eerst te converteren naar EPUB of AZW3 via calibre en dan de Boek bewerken functie te gebruiken om ze in perfecte vorm te krijgen. U kunt dan het bewerkte e-boek gebruiken als invoer voor conversie naar andere formaten in calibre.
Dit document behandelt hoofdzakelijk de conversie-instellingen zoals gevonden in het conversie dialoogvenster, onder afgebeeld. Al deze instellingen zijn ook beschikbaar via de opdrachtregel, zie ook ebook-convert. In calibre kunt u hulp krijgen bij elke individuele instelling door er met uw muis over te gaan waarna een tooltip verschijnt met de beschrijving.
Inleiding¶
Wat u als eerste moet weten over het systeem van conversie is dat het ontworpen is als een pijplijn. Schematisch ziet het er als volgt uit:
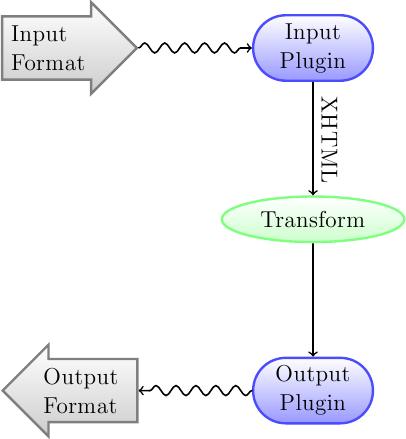
Het invoerformaat wordt eerst geconverteerd naar XHTML door de gepaste Input plugin. Deze HTML wordt vervolgens getransformeerd. In de laatste stap wordt de verwerkte XHTML geconverteerd naar het opgegeven uitvoerformaat door de juiste Uitvoer plugin. De resultaten van de conversie kunnen sterk variëren, op basis van het invoerformaat. Sommige formaten converteren beter dan andere. Een lijst met de beste bronformaten voor conversie is beschikbaar: ref:hier <best-source-formats>.
De transformaties uitgevoerd op de XHTML-uitvoer zijn waar alles gebeurt. Er zijn verschillende transformaties, bijvoorbeeld om boek metadata in te voegen als een pagina aan het begin van het boek, om hoofdstukkoppen te detecteren en automatisch een Inhoudsopgave te maken, om de lettergroottes proportioneel aan te passen, enz. Het is belangrijk om te onthouden dat alle transformaties op de XHTML-uitvoer van de Invoer plug-in werken, niet op het invoerbestand zelf. Dus als u bijvoorbeeld calibre vraagt om een RTF-bestand naar EPUB te converteren, wordt het eerst intern naar XHTML geconverteerd, de verschillende transformaties worden op de XHTML toegepast en vervolgens maakt de Uitvoer plug-in het EPUB-bestand, automatisch alle metadata, inhoudsopgave, enz genererend.
U kunt dit proces in actie zien door de debug optie  te gebruiken. Geef het pad op naar een map voor de uitvoer van de foutenopsporing. Tijdens conversie zal calibre de XHTML gegenereerd door de diverse stadia van de conversie pijplijn in verschillende sub-mappen plaatsen. De vier sub-mappen zijn:
te gebruiken. Geef het pad op naar een map voor de uitvoer van de foutenopsporing. Tijdens conversie zal calibre de XHTML gegenereerd door de diverse stadia van de conversie pijplijn in verschillende sub-mappen plaatsen. De vier sub-mappen zijn:
Map |
Omschrijving |
|---|---|
invoer |
Dit bevat de HTML-uitvoer door de invoer plug-in. Gebruik dit om de invoer plug-in te debuggen. |
doorlopen |
Het resultaat van voorbewerking en converteren naar XHTML van de uitvoer van de Invoer plug-in. Gebruik voor foutopsporing in de structuurdetectie. |
structuur |
Na structuurdetectie maar voor CSS afvlakken en lettergrootte conversie. Gebruik voor foutopsporing in lettergrootte conversie en CSS transformaties. |
verwerkt |
Net voor het e-boek wordt doorgegeven aan de uitvoer plug-in. Gebruik voor foutopsporing in de Uitvoer plug-in. |
Als u het invoerdocument wilt bewerken voor calibre het converteert, kan u dit best in de input submap doen, dan inpakken als ZIP bestand en dit gebruiken als invoerformaat voor volgende conversies. Om dit te doen, gebruik de Meta informatie bewerken dialoog om het ZIP bestand toe te voegen als formaat voor het boek en selecteer dan, linksboven in het dialoogvenster, ZIP als invoerformaat.
Dit document behandelt hoofdzakelijk de verschillende transformaties op de tussenliggende XHTML en hoe ze te controleren. Op het einde zijn er tips specifiek voor elk type invoer/uitvoer formaat.
Uitstraling & gevoel¶
Deze groep opties controleert verschillende aspecten van het uitzicht van het geconverteerde e-boek.
Lettertypen¶
Een van de fijnste functies van de e-leeservaring is de mogelijkheid om makkelijk de lettergrootte in te stellen voor individuele behoeftes en lichtomstandigheden. calibre heeft gesofisticeerde algoritmes om ervoor te zorgen dat het boeken in een uniforme lettergrootte presenteert, ongeacht wat is gespecificeerd in het invoerdocument.
De basis lettergrootte van een document is de algemene lettergrootte in dat document, d.i. de grootte van de meeste tekst in dat document. Als u een Basis lettergrootte specificeert, zal calibre automatisch de lettergrootte proportioneel aanpassen, zodat de meest voorkomende grootte de gespecificeerde basis lettergrootte wordt en andere lettergroottes gepast geschaald worden. Door een grotere basis lettergrootte te kiezen, kunt u de letters in het document groter maken en omgekeerd. Wanneer u de basis lettergrootte instelt, moet u voor het beste resultaat ook de lettergrootte-sleutel instellen.
Normaal zal calibre automatisch een basis fontgrootte kiezen, gepast voor het uitvoerprofiel dat u gekozen hebt (zie Pagina opmaak). U kan dit echter hier negeren indien de standaard niet geschikt is voor u.
Met de optie Lettergrootte-sleutel controleert u hoe niet-basis lettergroottes worden geschaald. Het lettertype schaal algoritme werkt met een lettergrootte sleutel, eenvoudig een komma gescheiden lijst van lettergroottes. Deze sleutel vertelt calibre hoeveel “stappen” groter of kleiner een bepaalde grootte moet zijn vergeleken met de basisgrootte. Het idee is dat er een begrensd aantal lettergroottes in een document mag voorkomen. Bv: een grootte voor de tekst, een paar groottes voor verschillende titels en een paar voor super/subscripten en voetnoten. De lettergrootte-sleutel laat calibre de groottes in het invoerdocument scheiden in separate “bakken” overeenkomend met verschillende logische lettergroottes.
Ter illustratie een voorbeeld. Stel dat het brondocument dat we converteren gemaakt is door iemand met uitstekend gezichtsvermogen met een basis lettergrootte van 8pt. Dat betekent dat de meeste tekst in het document in 8pt is gezet, met de titels een beetje groter (bv 10 of 12pt) en voetnoten iets kleiner op 6pt. Als we nu de volgende instellingen gebruiken:
Base font size : 12pt
Font size key : 7, 8, 10, 12, 14, 16, 18, 20
Het uitvoerdocument krijgt een basis lettergrootte van 12pt, titels 14 en 16pt en voetnoten 8pt. Aangenomen dat we de grootste titels meer willen laten opvallen en de voetnoten ook. Om dit te bereiken zal de lettergrootte-sleutel gewijzigd moeten worden naar:
New font size key : 7, 9, 12, 14, 18, 20, 22
De grootste titels worden nu 18pt, terwijl de voetnoten 9pt worden. U kunt met deze instellingen spelen en proberen uit te vinden wat voor u de optimale waarden zijn met behulp van de wizard die u kunt openen door op de kleine knop naast de Lettergrootte-sleutel klikt.
Het schalen van lettergrootte in de conversie kunt u hier ook uitschakelen indien u de lettergroottes van het invoerdocument wilt behouden.
Een verwante instelling is Lijnhoogte. Lijnhoogte bepaalt de verticale hoogte van lijnen. Standaard (regelhoogte 0) is er geen manipulatie van lijnhoogten . Als u een niet-standaardwaarde opgeeft, worden regelhoogten ingesteld op alle plaatsen zonder eigen lijnhoogten. Dit is echter eerder een botte bijl en moet spaarzaam worden gebruikt. Als u de lijnhoogten voor een deel van de invoer wilt aanpassen, is het beter om de Extra CSS te gebruiken.
Hier kunt u calibre ook laten weten referenced lettertypen in het boek in te sluiten. Dit laat de lettertypen werken op toestellen, zelfs als ze niet beschikbaar zijn op het toestel.
Tekst¶
Tekst kan worden uitgevuld of niet. Uitgevulde tekst heeft extra spaties tussen woorden voor een nette rechtermarge. Sommige mensen verkiezen aan uitgevulde tekst, anderen niet. Normaal gesproken bewaart calibre de uitvulling van het originele document. Als u dit wilt negeren, gebruik de optie Text justification in dit gedeelte.
U kunt calibre ook laten Interpunctie verslimmen, dit vervangt gewone aanhalingstekens, streepjes en ellipsen door hun typografisch correcte alternatieven. Merk op dat dit algoritme niet perfect is, dus het loont om de resultaten te beoordelen. Het omgekeerde, namelijk: guilabel: Interpunctie verdommen is ook beschikbaar.
Tenslotte is er: guilabel: Invoer karakter encodering. Oudere documenten specificeren soms hun karaktercodering niet. Bij conversie kunnen hierdoor niet-Engelse of speciale karakters, zoals slimme aanhalingstekens, beschadigd zijn. calibre probeert de karaktercodering van het brondocument te auto-detecteren, maar dat lukt niet altijd. U kunt het dwingen een bepaalde codering aan te nemen met deze instelling. cp1252 is een algemene codering voor documenten geproduceerd met Windows software. U leest best ook Hoe converteer ik mijn bestand met niet-Engelse karakters of smart quotes? voor meer informatie over coderingsproblemen.
Opmaak¶
Normaal worden alinea’s in XHTML gerenderd met een lege regel tussen alinea’s en zonder inspringen. In calibre kunt u dit beïnvloeden met een paar opties. Verwijder ruimte tussen alinea’s verwijdert de lege regels tussen alinea’s. Het stelt het tekst inspringen ook in op 1.5em (kan gewijzigd worden) om een nieuwe alinea te markeren. Invoegen lege regel doet het tegenovergestelde door precies één lege regel in te voegen tussen twee alinea’s. Beide opties zijn veelomvattend, verwijderen van lege regels of juist het invoegen voor alle alinea’s (technisch <p> en <div> tags).U stelt gewoon de optie in en deze zal worden uitgevoerd ongeacht hoe rommelig het invoerbestand is. Er is een uitzondering: wanneer het invoerbestand harde regeleindes gebruikt voor alinea scheiding.
Als u de spatiëring tussen alle alinea’s wilt verwijderen, behalve een select aantal, gebruik dan deze opties niet. Voeg in plaats daarvan de volgende CSS-code toe aan Extra CSS 1:
p, div { margin: 0pt; border: 0pt; text-indent: 1.5em }
.spacious { margin-bottom: 1em; text-indent: 0pt; }
Vervolgens, in uw bron-document, markeer de alinea’s die afstand nodig hebben met class=”spacious”. Indien uw invoerdocument niet in HTML is, gebruik de optie Foutopsporing beschreven in de Inleiding om HTML te krijgen (gebruik de input submap).
Een andere handige optie is: guilabel: Lineariseer tabellen. Sommige slecht ontworpen documenten gebruiken tabellen om de lay-out van tekst op de pagina te regelen. Bij het converteren bevatten deze documenten vaak tekst die van de pagina afloopt en andere artefacten. Met deze optie wordt de inhoud uit de tabellen gehaald en lineair gepresenteerd. Merk op dat deze optie alle tabellen lineariseert, dus gebruik het alleen als u zeker weet dat het invoerdocument geen tabellen gebruikt voor legitieme doeleinden, zoals het presenteren van tabelinformatie.
Stijlen¶
De Extra CSS optie laat u willekeurige CSS specificeren, toe te passen op alle HTML bestanden in de invoer. Deze CSS wordt met hoge prioriteit toegepast en negeert dus de meeste CSS in het invoerdocument. Gebruik deze instelling om de presentatie/opmaak van uw document aan te passen. Wilt u bijvoorbeeld dat alle alinea’s met class eindnotitie rechts zijn uitgelijnd, voegt u gewoon toe:
.endnote { text-align: right }
of als u de insprong van alle paragrafen wilt aanpassen:
p { text-indent: 5mm; }
Extra CSS is een zeer krachtige optie, maar u moet wel enige kennis hebben over hoe CSS werkt om het potentieel volledig te benutten. U kunt de optie Foutenopsporing pijplijn gebruiken zoals boven beschreven om te zien welke CSS in opgenomen in het invoerdocument.
Een eenvoudigere optie is gebruik van: guilabel: Filter stijlinformatie. Hiermee verwijdert u alle CSS eigenschappen van de opgegeven types uit het document. Bv: u kunt het gebruiken om alle kleuren of lettertypen te verwijderen.
Transformeer stijlen¶
Dit is de krachtigste styling gerelateerde functie. U kunt er regels mee definiëren die stijlen veranderen op basis van verschillende omstandigheden. Bv: u kunt het gebruiken om alle groene kleuren in blauw te veranderen, of om alle vetgedrukte stijlen uit de tekst te verwijderen of om alle koppen in een bepaalde kleur te kleuren, enz.
Transformeer HTML¶
Lijkt op stijlen transformeren maar laat u de HTML inhoud van het boek aanpassen. U kan een tag vervangen door een andere, classes en andere attributen aan tags toevoegen gebaseerd op hun inhoud, enz.
Pagina opmaak¶
De Pagina instelling opties zijn er om schermindeling zoals marges en schermafmeting te controleren. Er zijn opties om marges in te stellen die gebruikt worden door de Uitvoer plug-in indien het geselecteerde Uitvoerformaat marges ondersteunt. Daarnaast moet u een Invoerprofiel kiezen en een Uitvoerprofiel. Beide profielsets zijn in principe verantwoordelijk voor interpretatie van de afmetingen in invoer/uitvoer documenten, schermafmetingen en standaard lettergrootte-sleutels.
Als u weet dat het bestand dat u converteert, bedoeld is voor gebruik op een specifiek toestel/software platform, kies dan het overeenkomend invoerprofiel, of neem gewoon het standaard profiel. Als uw weet dat de bestanden die u maakt voor een bepaald toesteltype zijn, kies het overeenkomende uitvoerprofiel, of neem een van de Generieke uitvoerprofielen. Als u converteert naar MOBI of AZW3 zal u meestal één van de Kindle uitvoerprofielen kiezen. Anders is uw beste keuze voor een moderne E-boek reader het Generiek e-inkt HD uitvoerprofiel.
Het Uitvoerprofiel controleert ook de schermafmeting. Dit zorgt er bijvoorbeeld voor dat afbeeldingen auto-schalen om op het scherm te passen in sommige uitvoerformaten. Kies dus een profiel van een toestel dat lijkt op de schermafmeting van uw apparaat.
Heuristische verwerking¶
Heuristische verwerking biedt een hoop functies om veelvoorkomende problemen in slecht opgemaakte invoerdocumenten te proberen detecteren en corrigeren. Gebruik deze functies als uw invoerdocument slecht is geformatteerd. Deze functies zijn afhankelijk van algemene patronen, houdt er rekening mee dat een optie soms tot slechtere resultaten kan leiden, dus wees voorzichtig. Een aantal van deze opties verwijdert bijvoorbeeld alle niet-brekende spatie-entiteiten, of kan vals-positieve overeenkomsten met betrekking tot de functie bevatten.
- Activeer heuristische verwerking
Deze optie activeert calibre’s Heuristische verwerking stap in de conversiepijplijn. Dit moet ingeschakeld zijn om diverse sub-functies toe te passen.
- Harde regeleinden verwijderen
Deze optie activeren laat calibre proberen harde regeleinden te detecteren en corrigeren in het document via interpunctie en regellengte. calibre zal eerst proberen of harde regeleinden voorkomen, als het erop lijkt dat ze niet bestaan, zal calibre niet proberen deze te verwijderen. De regelterugloop factor kunt u verlagen om calibre te ‘dwingen’ de harde regeleinden te verwijderen.
- Regelterugloop factor
Deze optie controleert het algoritme dat calibre toepast om harde regeleinden te verwijderen. Bijvoorbeeld: Als de waarde voor deze optie 0.4 is, betekent dit dat calibre harde regeleinden verwijdert van regeleinden waarvan de lengte minder dan 40% van alle regels in het document zijn. Als uw document maar een paar regeleinden heeft die gecorrigeerd moeten worden dan zou deze waarde gereduceerd moeten worden naar iets tussen 0.1 en 0.2.
- Bepaal en markeer ongeformateerde hoofdstuktitels en sub-hoofdstuktitels
Indien uw document geen hoofdstuktitels en ondertitels heeft die anders zijn geformatteerd dan de rest van de tekst kan calibre met deze optie proberen om deze te bepalen en ze omvatten met kop-labels. <h2> labels voor hoofdstuktitels; <h3> labels voor alle gevonden titels.
Deze functie zal geen inhoudsopgave creëren, maar vaak kan dit helpen om standaard de hoofdstukken te herkennen en een inhoudsopgave op te bouwen. Stel de XPath bij onder Structuurdetectie als een inhoudsopgave niet automatisch wordt gemaakt. Als er geen andere titels in het document zijn, zal de instelling “//h:h2” onder Structuurdetectie de makkelijkste manier zijn om een inhoudsopgave voor het document te maken.
De ingevoegde titels worden niet geformatteerd; om titels op te maken gebruik de optie Extra CSS onder de Uiterlijk en gedrag conversie-instellingen. Bijvoorbeeld: Om titel-labels te centreren, gebruik onderstaande:
h2, h3 { text-align: center }
- Hernummer sequenties van <h1> of <h2> labels
Sommige uitgevers formatteren hoofdstuktitels met meerdere <h1> of <h2> tags opeenvolgend. Met de standaard conversie-instellingen zal calibre deze titels opsplitsen in twee titels. Deze optie zal de titel-labels hernummeren om opsplitsing te voorkomen.
- Verwijder lege regels tussen alinea’s
Deze optie laat calibre lege regels binnen het document analyseren. Wanneer iedere alinea is gescheiden van de volgende door een lege regel zal calibre alle lege alinea’s verwijderen. Meerdere lege regels worden beschouwd als scenario-onderbreking en als een enkele alinea behouden. Deze optie verschilt van de Verwijder alinea-afstand optie onder ‘Uitstraling & Gevoel’ doordat deze de HTML-inhoud daadwerkelijk wijzigt, terwijl de andere optie de opmaak van het document wijzigt. Deze optie kan ook alinea’s verwijderen die ingevoegd werden met behulp van de Lege regel invoegen optie .
- Zorg ervoor dat scene-onderbrekingen altijd geformatteerd worden
Met deze optie probeert calibre om gewone scene-onderbrekingen markers te detecteren en ervoor te zorgen dat deze centraal worden uitgelijnd. ‘Zachte’ scene-onderbrekingen markers, d.i. scene-onderbrekingen bepaald door extra lege ruimte worden opgemaakt zodat ze niet getoond worden in combinatie met pagina-einden.
- Vervang scene-onderbrekingen
Als deze optie is geconfigureerd zal calibre de scene-onderbrekingen markers vervangen door vervangende tekst gespecificeerd door de gebruiker. Merk op aub dat sommige sierkarakters mogelijk niet worden ondersteund door alle lezers.
Normaal vermijdt u best het gebruik van HTML tags. calibre zal tags negeren en vooraf gedefinieerde mark-up gebruiken. <hr /> tags, d.i. horizontale lijn en <img> tags zijn uitzonderingen. Horizontale lijnen kunnen optioneel worden gespecificeerd met stijlen, voegt u uw eigen stijl toe, voorzie zeker de ‘width’-instelling, anders wordt de stijl genegeerd. Afbeelding tags kunnen gebruikt worden, maar calibre heeft geen mogelijkheid de afbeelding toe te voegen tijdens conversie, dit moet later gebeuren met de ‘Boek bewerken’ functie.
- Voorbeeld afbeeldingstag (plaats de afbeelding in een map ‘Afbeeldingen’ in de EPUB na conversie):
<img style=”width:10%” src=”../Images/scenebreak.png” />
- Voorbeeld horizontale lijn met opmaak:
<hr style=”width:20%;padding-top: 1px;border-top: 2px ridge black;border-bottom: 2px groove black;”/>
- Verwijder overbodige koppeltekens
calibre analyseert alle inhoud met koppeltekens wanneer deze optie geactiveerd is. Het document zelf dient als woordenboek in de analyse. Hiermee kan calibre nauwkeurig koppeltekens verwijderen in elk woord in het document in elke taal alsook verzonnen of rare wetenschappelijke begrippen. Grootste nadeel is dat woorden die maar één keer voorkomen niet worden gewijzigd. Analyse gebeurt in twee stappen, de eerste analyseert de regeleinden. Regeleinden worden alleen verwijderd als het woord bestaat in het document met of zonder een koppelteken. De tweede stap analyseert alle woorden met koppelteken, koppeltekens worden verwijderd indien het woord ergens anders bestaat zonder overeenstemming.
- Algemene woorden en patronen cursiveren
Wanneer geactiveerd zoekt calibre naar algemene woorden en patronen die cursieve schrijfwijze aangeven en ze cursiveren. Voorbeelden zijn algemene schrijfwijzen zoals ~word~ of uitspraken die algemeen cursief worden getoond, bijv. Latijnse uitdrukkingen zoals ‘etc.’ of ‘et cetera’.
- Vervang gegeven inspringing met CSS inspringing
Sommige documenten bepalen inspringende tekst met behulp van spaties. Wanneer deze optie is geactiveerd zal calibre proberen deze te detecteren en vervangen door een 3% tekst insprong met behulp van CSS.
Zoeken & vervangen¶
Deze opties zijn vooral nuttig voor conversie van PDF documenten of OCR conversies, hoewel ze ook helpen om vele document-specifieke problemen op te lossen. Zo plaatsen sommige conversies kop- en voetteksten in de tekst. Deze opties gebruiken reguliere expressies om deze of andere willekeurige teksten te proberen te detecteren en verwijderen of vervangen ze. Onthoud dat deze werken met de tussentijdse XHTML gemaakt in de conversie pijplijn. Er is een wizard om u te helpen de reguliere expressies aan te passen voor uw document. Klik op de toverstaf naast het expressievak en klik op de ‘Test’ knop na het samenstellen uw zoekuitdrukking. Gevonden overeenkomsten worden gemarkeerd in Geel.
Het zoeken werkt met een Python reguliere expressie. Overeenkomende tekst wordt eenvoudig verwijderd of vervangen met behulp van het vervangingspatroon. Het vervangingspatroon is optioneel, indien leeg, wordt overeenkomende tekst verwijderd uit het document. U komt meer te weten over reguliere expressies en hun syntax op Alles over het gebruik van reguliere expressies in calibre.
Structuurdetectie¶
Structuurdetectie houdt in dat calibre z’n best doet structurele elementen te detecteren in het invoerdocument wanneer deze niet netjes zijn gespecificeerd. Bijvoorbeeld: hoofdstukken, pagina-einden, kop- en voetteksten enz. Zoals u begrijpt, varieert dit sterk van boek tot boek. Gelukkig heeft calibre zeer krachtige opties om dit te controleren. Met kracht komt complexiteit, maar als u de tijd neemt om de complexiteit te leren kennen, zult u vinden dat het dit waard is.
Hoofdstukken en pagina-eindes¶
calibre heeft twee sets opties voor hoofdstukdetectie en pagina-einden invoegen. Dit kan soms verwarrend zijn omdat calibre standaard pagina-einden invoegt voor gevonden hoofdstukken en tevens op de plekken gevonden door de optie pagina-einden. De reden is dat vaak waar pagina-einden ingevoegd moeten worden geen markeringen zijn voor hoofdstukken. Tevens kunnen gevonden hoofdstukken optioneel ingevoegd worden in de automatisch gegenereerde Inhoudsopgaven.
calibre gebruikt XPath, een krachtige taal die de gebruiker markeringen voor hoofdstukken/pagina-einden laat bepalen. XPath kan een uitdaging zijn om te gebruiken maar gelukkig is er een XPath handleiding in de Gebruikershandleiding. Onthoud dat Structuurdetectie werkt met het tussentijdse XHTML bestand geproduceerd door de conversie-pijplijn. Gebruik de foutopsporingsoptie beschreven in de Inleiding om de passende instellingen voor uw boek te bepalen. Er is ook een knop voor een XPath-wizard om help te krijgen met het genereren van simpele XPath-expressies.
Standaard gebruikt calibre de volgende expressie voor hoofdstukdetectie:
//*[((name()='h1' or name()='h2') and re:test(., 'chapter|book|section|part\s+', 'i')) or @class = 'chapter']
Deze expressie is tamelijk ingewikkeld, ze probeert een aantal algemene zaken gelijktijdig af te handelen. Dit betekent dat calibre ervan uitgaat dat hoofdstukken beginnen met <h1> of <h2> tags die de woorden (hoofdstuk, boek, sectie of deel) bevatten of het attribuut class=”chapter” hebben.
Een verwante optie is Hoofdstuk markeren waarmee u controleert wat calibre doet bij detectie van een hoofdstuk. Standaard voegt het een pagina-einde in voor het hoofdstuk. U kunt een horizontale lijn laten invoegen in plaats van of met een pagina-einde. U kunt er ook voor kiezen om niets te doen.
De standaard instelling om pagina-einden te detecteren is:
//*[name()='h1' or name()='h2']
wat betekent dat calibre standaard een pagina-einde invoegt vóór iedere <h1> en <h2>-tag.
Notitie
De standaard expressie kan anders zijn afhankelijk van het invoerformaat dat u wilt converteren.
Diversen¶
Er zijn nog een paar opties in deze sectie.
- Metadata invoegen als pagina aan het begin
Een van de grote voordelen van calibre is dat u zeer uitgebreide metadata kunt bijhouden over al uw boeken, voor bijvoorbeeld een beoordeling, labels, commentaren etc. Deze optie voegt een enkele pagina in met alle metadata in het geconverteerde boek direct na de omslagfoto. Zie dit als u eigen gepersonaliseerde boekomslag.
- Verwijder eerste afbeelding
Soms is de omslagfoto opgenomen in het bron-document in plaats van een afzonderlijke omslagfoto. indien u ook een omslagfoto pecificeert in Calibre zal het geconverteerde boek twee omslagfoto’s hebben. Deze optie zal de eerste foto van het bron-document verwijderen en zo ervoor zorgen dat het geconverteerde boek maar een omslagfoto krijgt en wel degene die u specificeert in Calibre.
Inhoudsopgave¶
Wanneer het invoer-document een Inhoudopgave heeft in de metadata zal calibre deze gebruiken. Maar een aantal oudere formaten ondersteunen of een op metadata gebaseerde inhoudsopgave niet of individuele documenten hebben er geen. In deze gevallen kunnen de opties helpen om een inhoudsopgave automatisch te genereren in het geconverteerde boek gebaseerd op de inhoud van het invoer-document.
Notitie
Het kan een uitdaging zijn om de opties precies goed te krijgen. Indien u liever de inhoudsopgave handmatig wilt maken/bewerken, converteer in EPUB of AZW3 formaten en vink het keuzevakje aan onder aan de sectie Inhoudsopgave in de conversie-dialoog Handmatig verfijnen van inhoudsopgave na conversie. Hiermee opent u de editor na de conversie. Hiermee kunt u items maken in de Inhoudsopgave door eenvoudig te klikken op de plek in het boek waarheen moet worden verwezen. U kunt tevens de editor zelf gebruiken zonder een conversie te doen. Ga naar Voorkeuren → Werkbalken en voeg de inhoudsopgave-editor toe aan de hoofdwerkbalk. Darna selecteert u het boek dat u wilt bewerken en klik op de editor-knop.
De eerste optie is Forceer gebruik auto gegenereerde Inhoudsopgave. Door deze optie aan te vinken dwingt u calibre de in de metadata gevonden inhoudsopgave te overschrijven met de automatisch gegenereerde.
De standaard werkwijze van aanmaken van een automatisch gegenereerde Inhoudsopgave is dat Calibre eerst probeert om hoofdstukken te detecteren en deze gaat toevoegen aan de inhoudopgave. U kunt meer te weten komen hoe u de detectie van hoofdstukken kunt aanpassen in bovenstaande sectie Structuurdetectie. Indien u de gedetecteerde hoofdstukken niet wilt toevoegen aan de gegenereerde inhoudsopgave, vink de keuze aan Gedetecteerde hoofdstukken niet toevoegen.
Indien minder dan het Hoofdstuk drempel aantal hoofdstukken zijn gedetecteerd, zal calibre alle hyperlinks in het invoerdocument aan de inhoudsopgave toevoegen. Dit functioneert vaak prima: veel invoerdocumenten hebben een gelinkte inhoudsopgave aan het begin. De Aantal links optie kan gebruikt worden om dit gedrag te controleren. Indien nu, worden geen links toegevoegd. Indien groter dan nul wordt dat aantal links toegevoegd.
Calibre filtert automatisch duplicaten uit van de gegenereerde inhoudsopgave. Maar als er extra ongewenste items zijn kunt u deze uitfilteren met de optie Inhoudsopgave filteren. Dit is een reguliere expressie die de titel van items afstemt met de gegenereerde inhoudsopgave. Zodra een overeenkomst gevonden wordt, zal het verwijderd worden. Bijvoorbeeld om alle itels “Volgende” of “Vorige” te verwijderen, gebruik:
Next|Previous
Met de optie Niveau 1,2,3 inhoudsopgave kunt u een gevanceerde gelaagde inhoudsopgave maken. Dat zijn XPath-expressies die overeenkomende labels in het tussentijdse XHTML-bestand zoeken. Zie Inleiding hoe u dit XHTML-bestand kunt openen. Lees ook XPath handleiding om te leren hoe XPath-expressies samengesteld worden. Naast iedere optie is een knop die een wizard opent om te helpen met het maken van een basis XPath-expressie. Het volgende eenvoudige voorbeeld laat zien hoe deze opties gebruikt kunnen worden.
Aangenomen u heeft een invoer-document dat resulteert in XHTML dat er als volgt uitziet:
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<title>Sample document</title>
</head>
<body>
<h1>Chapter 1</h1>
...
<h2>Section 1.1</h2>
...
<h2>Section 1.2</h2>
...
<h1>Chapter 2</h1>
...
<h2>Section 2.1</h2>
...
</body>
</html>
Hierna stellen we de opties als volgt in:
Level 1 TOC : //h:h1
Level 2 TOC : //h:h2
Dit zal resulteren in een automatisch gegenereerde twee traps inhoudsopgave die er als volgt uitziet:
Chapter 1
Section 1.1
Section 1.2
Chapter 2
Section 2.1
Waarschuwing
Niet alle uitvoer-formaten ondersteunen een gelaagde inhoudsopgave. Probeer het eerst met EPUB. Als dat werkt, probeer het dan met het formaat van uw keuze.
Gebruik afbeeldingen als hoofdstuktitels tijdens de conversie van HTML invoer-documenten¶
Aangenomen dat u een afbeelding wilt gebruiken als hoofdstuktitel, maar u wilt toch dat calibre automatisch een Inhoudsopgave genereert van de hoofdstuktitels. Gebruik de volgende HTML code om dit te bereiken:
<html>
<body>
<h2>Chapter 1</h2>
<p>chapter 1 text...</p>
<h2 title="Chapter 2"><img src="chapter2.jpg" /></h2>
<p>chapter 2 text...</p>
</body>
</html>
Stel de Niveau 1 Inhoudsopgave in als //h:h2. Voor hoofdstuk twee zal Calibre de titel ophalen van de waarde van het attribuut title uit de <h2> tag omdat deze geen tekst heeft.
Gebruik tag attributen om de tekst te halen t.b.v. Inhoudsopgave¶
Indien u bijzonder lange hoofdstuktitels heeft en kortere versies in de inhoudsopgave wilt hebben kunt u het “title”-attribuut gebruiken om dat te bereiken; bijvoorbeeld:
<html>
<body>
<h2 title="Chapter 1">Chapter 1: Some very long title</h2>
<p>chapter 1 text...</p>
<h2 title="Chapter 2">Chapter 2: Some other very long title</h2>
<p>chapter 2 text...</p>
</body>
</html>
Stel de Niveau 1 Inhoudsopgave in als //h:h2/@title. Calibre haalt nu de titel op van de waarde van het title-attribuut van de <h2> labels in plaats van de tekst binnen de labels. N.B.: Het aanhangsel /@title in de XPath-expressie kunt u in deze vorm gebruiken om Calibre te vertellen om de tekst te halen van ieder attribuut dat u wenst.
Hoe opties worden ingesteld/opgeslagen voor conversie¶
Er zijn twee plaatsen waar de opties voor conversie kunnen worden ingesteld in Calibre. De eerste is in Voorkeuren->Conversie. Deze instellingen zijn de standaards voor de conversie-opties. Wanneer u probeert om een nieuw boek te converteren worden deze instellingen standaard gebruikt.
U kunt ook instellingen wijzigen in een conversie-dialoog voor elke boek-conversie. Wanneer u een boek converteert zal Calibre onthouden welke instellingen u heeft gebruikt voor dat boek; op deze manier zullen de opgeslagen instellingen voor ieder individueel boek voorrang krijgen boven de standaards in Voorkeuren als u dit boek opnieuw wilt converteren. U kunt de individuele instellingen terugzetten naar de standaards met behulp van de knop Hertelen naar standaards in het individuele boek in de conversie-dialoog. U kunt de opgeslagen instellingen verwijderen voor meerdere boeken door alle betreffende boeken te selecteren en dan te klikken op de knop Metadata bewerken om het dialoogvenster Bulk metadata bewerken onderaan van het dialoogvenster is een optie om opgeslagen conversie-instellingen te verwijderen.
Wanneer u meerdere boeken in bulk converteerd worden de instellingen genomen in de onderstaande volgorde (de laatste overheerst):
Van de standaards ingesteld in Voorkeuren->Conversie
Van de opgeslagen conversie-instellingen voor elk boek dat wordt geconverteerd (indien aanwezig). Dit kan worden uitgeschakeld door de optie in de linkerbovenhoek van het dialoogvenster Bulkconversie.
Van de instellingen in het Bulk-conversie-dialoogvenster
N.B.: De laatste instellingen voor elk boek in een Bulk conversie worden opgeslagen en opnieuw gebruikt als dat boek opnieuw wordt geconverteerd. Aangezien de hoogste prioriteit in Bulkconversie wordt gegeven aan de instellingen in het dialoogvenster Bulkconversie, zullen deze alle boekspecifieke instellingen overschrijven. Daarom moet u alleen boeken in bulk converteren die soortgelijke instellingen nodig hebben. De uitzonderingen zijn metadata en invoer-formaat specifieke instellingen. Omdat het dialoogvenster voor Bulk Conversie geen instellingen heeft voor deze twee opties, worden deze gehaald uit de boek-specifieke instellingen (indien aanwezig) of de standaards.
Notitie
U kunt de actuele instellingen zien die tijdens conversie gebruikt worden door te klikken op te roterende pictogram in de rechter benedenhoek en dat dubbelklikken op de individuele conversietaak. Dit opent het logboek van de conversie en bevat de actuele instellingen bovenaan.
Formaat specifieke tips¶
Hier vindt u tips betreffende conversie van specifieke formaten. Opties voor specifieke formaten voor invoer of uitvoer die beschikbaar zijn in het converie-dialoogvenster onder hun eigen sectie, bijvoorbeeld TXT invoer of EPUB uitvoer.
Microsoft Word documenten omzetten¶
calibre kan “.docx” bestanden gemaakt in Microsoft Word 2007 of later automatisch converteren. Voeg het bestand toe aan Calibre en klik “converteren”.
Notitie
Er is een demo .docx-bestand dat de mogelijkheden van de Calibre-conversie-engine demonstreert. Download het gewoon en converteer het naar EPUB of AZW3 om te zien wat Calibre kan doen.
Calibre zal automatisch een Inhoudsopgave genereren gebaseerd op titels als u deze markeert met de stijlen Titel 1, Titel 2 etc. in Word. Open de uitvoer e-boek in de Calibre lezer en klik op de knop Inhoudsopgave om de gegenereerde Inhoudsopgave te bekijken.
Oudere .doc bestanden¶
Voor oudere .doc-bestanden kunt u in Microsoft Word ht document opslaan als HTML en het HTML-bestand converteren met Calibre. Bij het opslaan als HTML moet u wel erop letten dat u de optie “Opslaan als webpagina, gefilterd” gebruikt omdat dit zorgt voor een zuivere HTML-code dat zich goed laat converteren. N.B.: Word maakt werkelijk rommelige HTML en het converteren kan lange tijd duren, wees geduldig. Als u beschikt over een nieuwere versie van Word kunt u het ook meteen opslaan als docx.
Een ander alternatief is om het gratis LibreOffice te gebruiken. Open uw .doc-bestand in LibreOffice en sla het op als .docx, dat direct in Calibre kan worden geconverteerd.
TXT documenten omzetten¶
TXT documenten hebben geen formattering zoals vetgedrukt, cursief e.d. of documentstructuur zoals alinea’s, titels, secties e.d. maar er bestaan meerdere algemeen gebruikte conventies. Standaard probeert calibre automatische detectie van de correcte formattering en opmaak gebaseerd op deze conventies.
TXT invoer ondersteunt een aantal opties om onderscheid te maken hoe alinea’s worden gedetecteerd.
- Alinea stijl: Auto
Analyseert het tekstbestand en probeert automatisch te bepalen hoe alinea’s zijn gedefiniëerd.Deze optie zal prima functioneren; indien u ontevreden bent met de resultaten probeer een van de handmatige opties.
- Alinea stijl: Blok
Gaat ervan uit dat een of meer lege regels een alinea aangeven:
This is the first. This is the second paragraph.- Alinea stijl: Enkele
Gaat ervan uit dat elke regel een alinea is:
This is the first. This is the second. This is the third.- Alinea stijl: Print
Gaat ervan uit dat elke alinea begint met een inspringing (of een tab of 2+ spaties). Alinea eindigt wanneer de volgende regel die begint met een inspringing is bereikt:
This is the first. This is the second. This is the third.- Alinea stijl: Ongeformatteerd
Gaat ervan uit dat het document niet opgemaakt is maar wel harde regeleinden heeft. Leestekens en gemiddelde regellengtes worden gebruikt om alinea’s te herstellen.
- Alinea stijl: Auto
Tracht het type van formatering opmaak te dectecteren. Als er geen opmaak is gebruikt, zal de formatting heuristisch toegepast worden
- Activeer heuristische verwerking
Doorzoekt het document naar hoofdstuktitels, scene-onderbrekingen en cursief geschreven woorden en zal de passende HTML-code toepassen tijdens conversie.
- Formattering: Markdown
Calibre ondersteunt ook de invoer van TXT door een transformatie-preprocessor bekend als Markdown. Markdown voegt een basis-opmaak toe aan TXT-documenten zoals vetgedrukt, cursiev, sectie-titels, tabellen, lijsten, een Inhoudsopgave etc. Het markeren van hoofdstuktitels met een voorlopende # en hoofdstuk XPath detectie-expressie in te stellen als “//h:h1” is de makkelijkste manier om een nette inhoudsopgave te laten genereren van een TXT-document. U kunt meer lezen over de markdown-syntax op daringfireball.
- Alinea stijl: Ongeformatteerd
Past geen speciale opmaak toe op de tekst, het document wordt geconverteerd naar HTML zonder andere wijzigingen.
PDF-documenten omzetten¶
PDF-documenten zijn van de slechtste formaten om van te converteren. Ze hebben een vast pagina en tekstplaatsingsformaat . Heel moeilijk dus om te bepalen waar een alinea eindigt en een andere begint. calibre zal proberen paragrafen te ontwarren met een configureerbare Line un-wrapping factor. Deze schaal dient om de lengte te bepalen waarop een lijn wordt afgebroken. Geldige waarden zijn een decimaal tussen 0 en 1. Standaard: 0,45, net onder de mediaanlijnlengte. Verlaag deze waarde om meer tekst toe te voegen aan het ontwarren. Verhoog voor minder. U kunt deze waarde aanpassen in de conversie-instellingen onder PDF Input.
Ze hebben ook vaak kop- en voetteksten als onderdeel van het document dat bij de tekst wordt opgenomen. Gebruik het: guilabel: Zoeken en vervangen paneel om kop- en voetteksten te verwijderen om dit probleem te verhelpen. Als de kop- en voetteksten niet uit de tekst worden verwijderd, kan het uitpakken van de alinea weggooien. Lees: ref: regexptutorial om te leren hoe u de opties voor het verwijderen van kop- en voetteksten gebruikt.
Enkele beperkingen van PDF invoer zijn:
Ingewikkelde documenten met meerdere kolommen en afbeeldingen worden niet ondersteund.
Extraheren van vector fotobestanden en tabellen vanuit het document is ook niet ondersteund.
Sommige PDF’s gebruiken speciale hiërogliefen of symbolen om ll or ff or fi etc. weer te geven. Conversie van deze kan functioneren of ook niet afhankelijk van hoe deze intern worden weergegeven in het PDF.
Links en Inhoudopgaves worden niet ondersteund
PDF’s die ingesloten niet-Unicode-lettertypen gebruiken om niet-Engelse tekens weer te geven, zullen resulteren in onleesbare uitvoer voor die tekens
Sommige PDFs maken gebruik van foto’s met OCR tekst. In zulke gevallen zal Calibre de OCR tekst gebruiken, wat heel anders kan zijn van wat je ziet als je de PDF bekijkt
PDFs die gebruik maken van complexe tekst zoals recht naar links talen en wiskundige formules zullen niet juist worden geconverteerd.
Om te herhalen PDF is echt, echt slecht formaat om te gebruiken als input. Als je absoluut PDF wilt gebruiken, dan kan de output varieëren van uitstekend tot onbruikbaar, afhankelijk van de input PDF.
Stripboek collecties¶
Een comic boek collectie is een .cbc-bestand. Een .cbc-bestand in een gezipt bestand dat andere CBZ/CBR bestanden bevat. Daarnaast moet een .cbc-bestand een simepel tekstbestand bevatten genaamd comics.txt, in UTF-8 codering. Het comics.txt bestand moet een lijst bevatten van de comics-bestanden binnen het .cbc-bestand in de vorm van bestandsnaam:titel zoals hieronder:
one.cbz:Chapter One
two.cbz:Chapter Two
three.cbz:Chapter Three
Het .cbc bestand zal dan bevatten:
comics.txt
one.cbz
two.cbz
three.cbz
Calibre zal dit .cbc-bestand automatisch converteren in een e-boek met een Inhoudsopgave met links naar iedere ingave in comics.txt.
EPUB geavanceerde opmaak demo¶
Verschillende geavanceerde opmaak voor EPUB-bestanden wordt gedemonstreerd in dit demobestand. Het bestand is gemaakt van met de hand gecodeerde HTML met Calibre en is bedoeld om te worden gebruikt als een sjabloon voor uw eigen inspanningen om EPUB te maken.
De bron-HTML waaruit het is gemaakt, is beschikbaar: download_file:demo.zip <demos/demo.zip>. De instellingen die worden gebruikt om de EPUB van het ZIP-bestand te maken, zijn:
ebook-convert demo.zip .epub -vv --authors "Kovid Goyal" --language en --level1-toc '//*[@class="title"]' --disable-font-rescaling --page-breaks-before / --no-default-epub-cover
N.B.: Omdat het bestand de mogelijkheden van EPUB verkent zullen de meeste geavanceerde opmaak niet werken op readers die minder kunnen dan de ingebouwde EPUB lezer van Calibre.
ODT documenten omzetten¶
Calibre kan direct ODT (OpenDocument Tekst) bestanden converteren. U moet stijlen gebruiken om uw document op te maken en zo min mogelijke interne opmaak gebruiken. Wanneer u afbeeldingen in uw document invoegt moet u deze verankeren aan een alinea. Afbeeldingen verankerd aan een pagina zullen aan het begin van de conversie eindigen.
Om automatische detectie van hoofdstukken te activeren, moet u deze markeren met de ingebouwde stijlen genaamd Kop 1, Kop 2, …, Kop 6 (Kop 1’ is gelijk aan de HTML tag <h1>, Kop 2 aan <h2> enz). Als u converteert in calibre kunt u opgeven welke stijl u gebruikte in het Detecteer hoofdstukken op vak . Voorbeeld:
Als u Hoofdstukken markeert met stijl Kop 2, moet u in het vak ‘Detecteer hoofdstukken op’
//h:h2invullenVoor een geneste Inhoudsopgave met Secties gemarkeerd met Kop 2 en de Hoofdstukken gemarkeerd met Kop 3 moet u
//h:h2|//h:h3invullen. Op de Conversie - Inhoudsopgave pagina vult u in het vak Niveau 1 Inhoudsopgave//h:h2in en in het vak Niveau 2 Inhoudsopgave vult u//h:h3in.
De bekende document-eigenschappen (Titel, sleutelwoorden, beschrijving, maker) worden herkent en Calibre gebruikt de eerste afbeelding (niet te klein en met de juiste aspect-ratio) als omslag-afbeelding.
Er is zelfs een geavanceerde eigenschappen conversie-modus, die geactiveerd wordt in de aangepaste eigenschap opf.metadata `` ('Ja of Nee') voor Ja te kiezen in uw ODT-document (Bestand->Eigenschappen->Gebruikergedefinieerde eigenschappen). Wanneer deze eigenschap door calibre wordt gedetecteerd worden de volgende aangepaste eigenschappen herkend (``opf.authors overschrijft de auteur van het document):
opf.titlesort
opf.authors
opf.authorsort
opf.publisher
opf.pubdate
opf.isbn
opf.language
opf.series
opf.seriesindex
Daarnaast kunt u de afbeelding specificeren de gebruikt wordt als omslag door deze te benoemen als opf.cover (rechts klikken, Afbeelding->Opties->Naam) in het ODT. Wanneer geen afbeelding met deze naam wordt gevonden, zal de ‘slimme’ methode toegepast. Omdat de omslag-detectie kan resulteren in dubbele omslagen in bepaalde uitvoer-formaten, zal het proces de alinea verwijderen (maar alleen indien de inhoud de omslag is!) van het document. Maar dit functioneert alleen met de benoemde afbeelding!
Om omslag-detectie uit te schakelen kunt u de gebruikersgedefineerde eigenschap opf.nocover (‘Ja of Nee’) instellen op Ja in geavanceerde modus.
Naar PDF omzetten¶
De eerste, belangrijkste instelling om te bepalen bij conversie naar PDF is het paginaformaat. Standaard gebruikt calibre “U.S. letter”. U kunt dit wijzigen naar een ander standaard formaat of een volledig aangepast in de PDF Output sectie van de conversie dialoog. Als u een PDF genereert om op een specifiek toestel te gebruiken, kunt u de optie inschakelen om het formaat te gebruiken van het :guilabel:’output profile`. Dus als uw uitvoerprofiel is ingesteld op Kindle, maakt calibre een PDF met een formaat geschikt om te bekijken op het kleine Kindle scherm.
Afdrukbare inhoudsopgave¶
U kunt ook een afdrukbare Inhoudsopgave invoegen aan het einde van het PDF dat de paginanummers voor elke sectie laat zien. Dit is zinvol als u het PDF op papier wilt afdrukken. Indien u het PDF op een electronisch apparaat wilt gebruiken, dan biedt de PDF samenvatting deze functionaiteit en wordt standaard gegenereerd.
U kunt het uiterlijk van de gegenereerde inhoudsopgave aanpassen door de instelling Extra CSS-conversie te gebruiken onder het Uiterlijk en Gevoel gedeelte van de conversiedialoog. De standaard gebruikte CSS wordt hieronder vermeld, kopieer deze gewoon en breng de gewenste wijzigingen aan.
.calibre-pdf-toc table { width: 100%% }
.calibre-pdf-toc table tr td:last-of-type { text-align: right }
.calibre-pdf-toc .level-0 {
font-size: larger;
}
.calibre-pdf-toc .level-1 td:first-of-type { padding-left: 1.4em }
.calibre-pdf-toc .level-2 td:first-of-type { padding-left: 2.8em }
Aangepaste paginamarges voor individuele HTML-bestanden¶
Als u een EPUB- of AZW3-bestand converteert met daarin meerdere afzonderlijke HTML-bestanden en u de paginamarges voor een bepaald HTML-bestand wilt wijzigen, kunt u het volgende stijlblok aan het HTML-bestand toevoegen met de calibre E-book editor:
<style>
@page {
margin-left: 10pt;
margin-right: 10pt;
margin-top: 10pt;
margin-bottom: 10pt;
}
</style>
Schakel vervolgens in het gedeelte PDF-uitvoer van het conversiedialoog de optie in: guilabel:Gebruik paginamarges van het document dat wordt geconverteerd. Nu hebben alle pagina’s die uit dit HTML-bestand zijn gegenereerd `` 10pt``-marges.